可观测性
Splunk On-Call
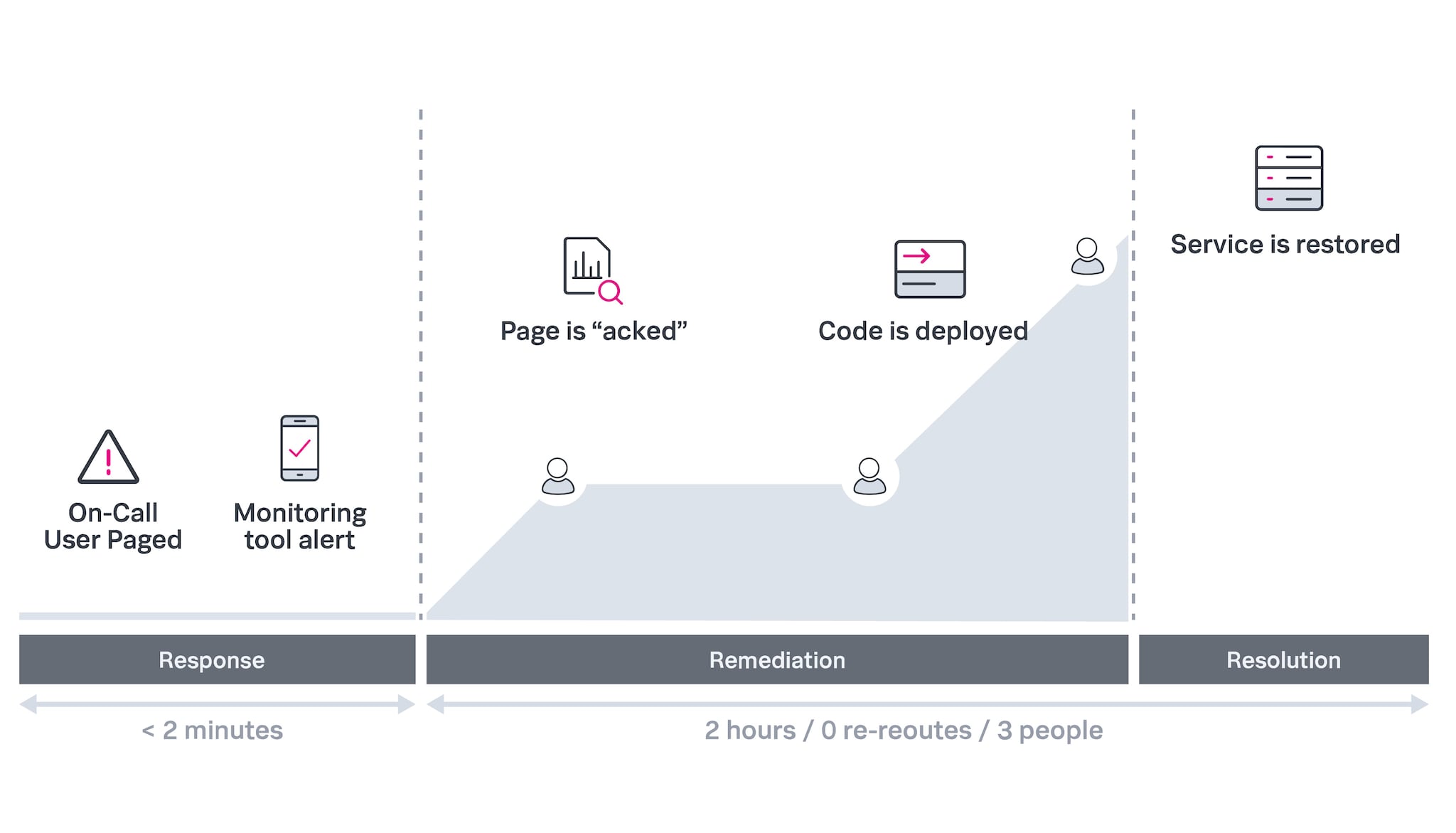
减少待命问题。更快地进行补救,减少疲劳,让昂贵的服务中断成为过去。
功能
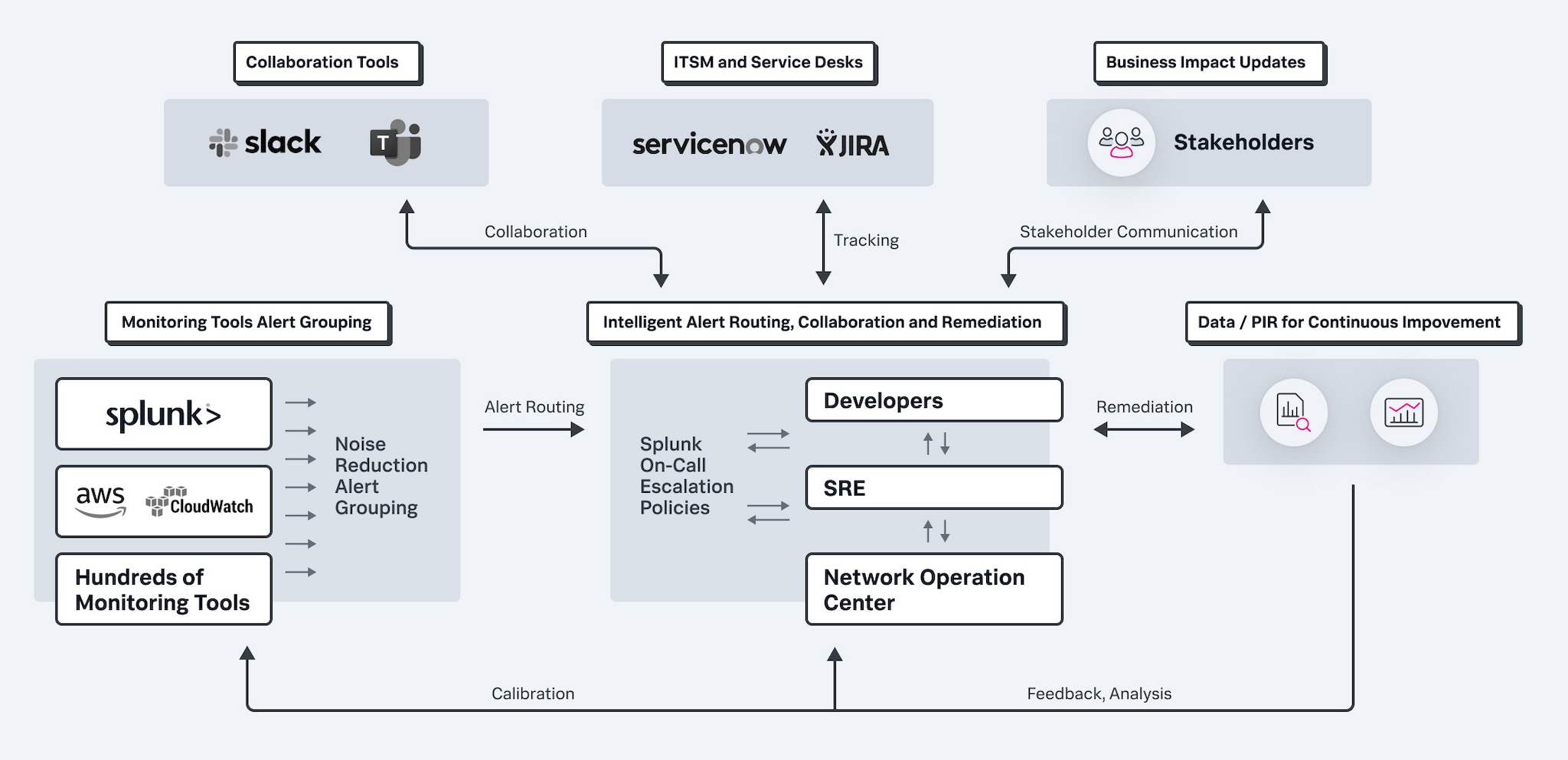
自动化关键流程以加快解决问题
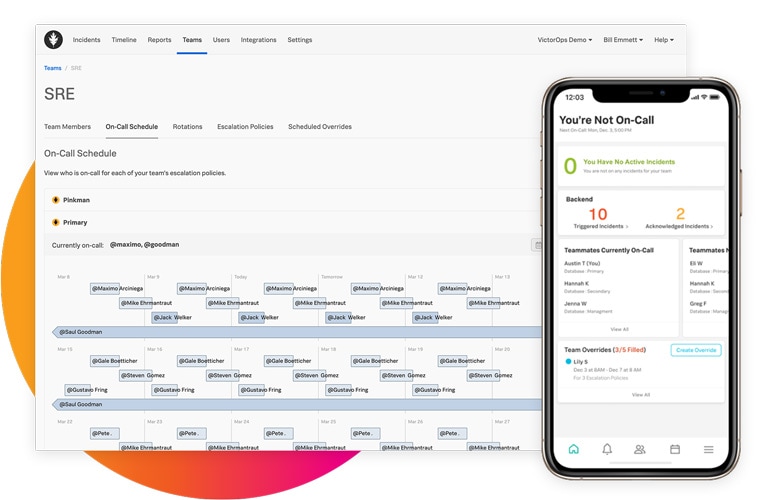
确定具有适当经验和专业知识的人员来处理任何事件。此外,简化待命时间表和上报流程。
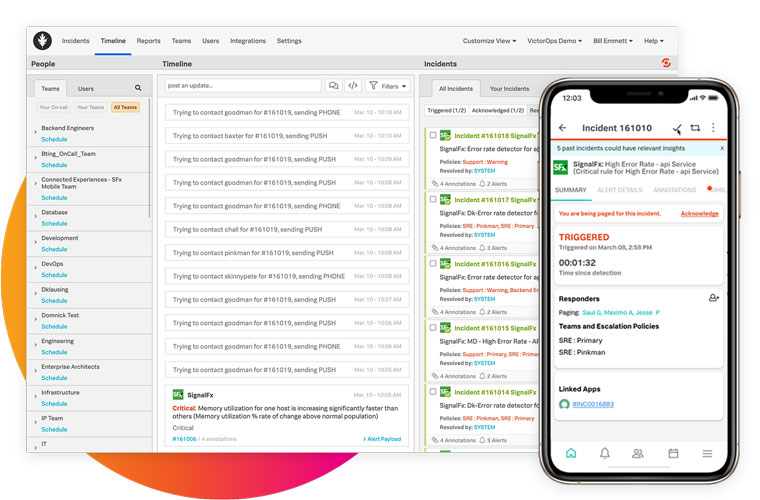
iOS 和 Android 应用程序
团队成员只需使用手机即可获得完整的事件响应功能。因此,他们可以在自己想要的任何地方工作。
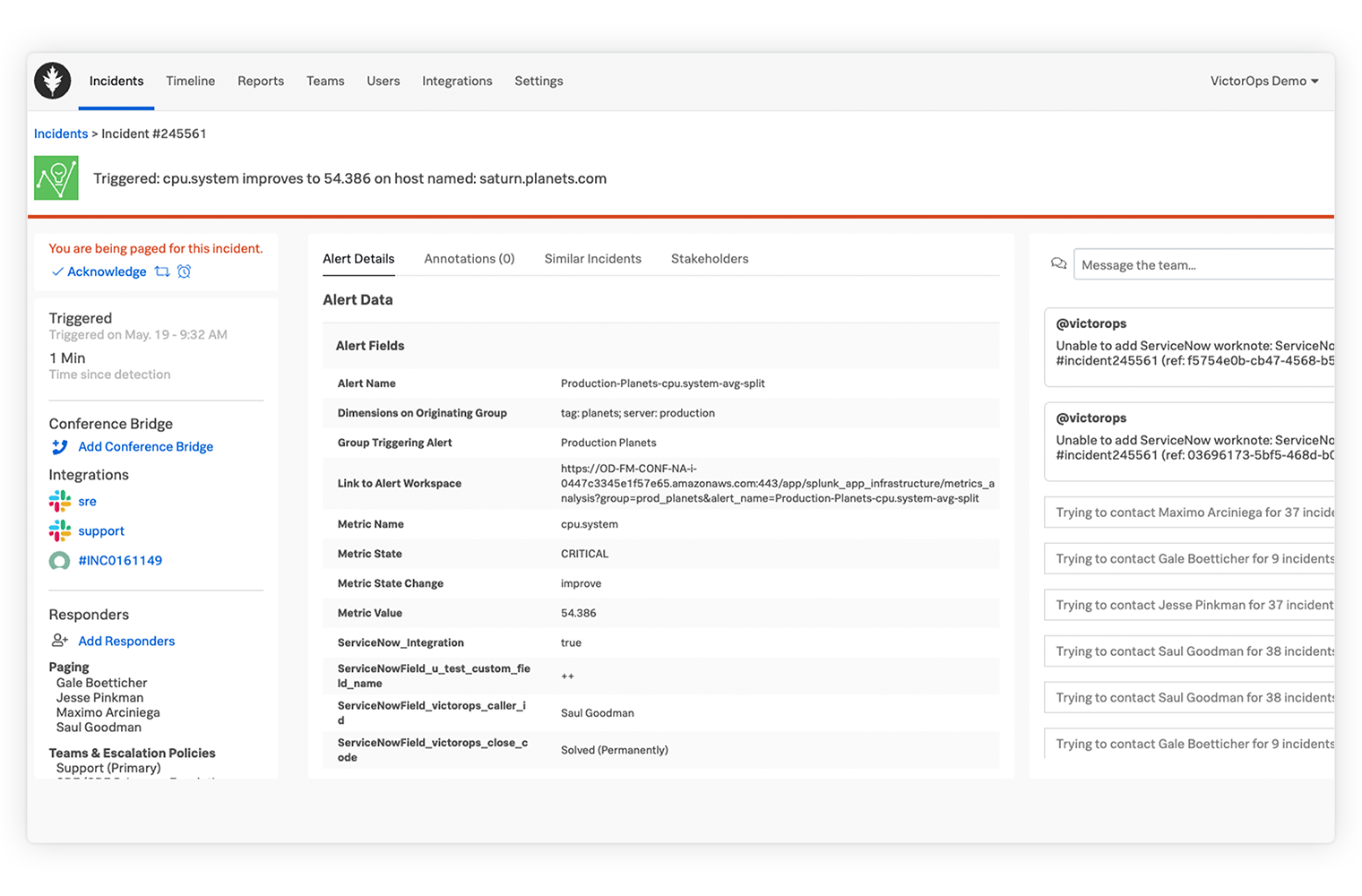
事件背景和审计跟踪
使用历史见解和审计跟踪来识别类似事件,以便更好地主动解决事件。
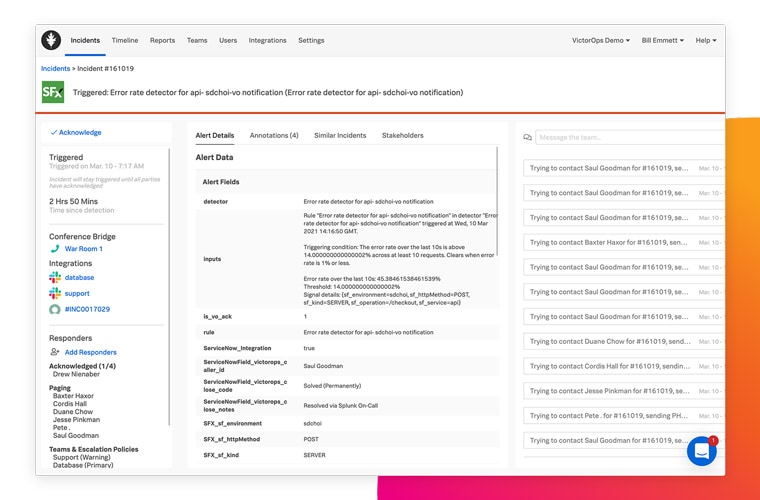
规则引擎
为事件添加背景信息,并使用操作手册、文章和仪表板等资源来帮助响应人员更快地对事件进行分类和解决。
基于机器学习的响应人员推荐
选择具有适当专业知识的响应人员,并提供类似事件的信息,以便更有效地解决问题。

客户案例
PSCU 通过 Splunk 平台保护可靠性和安全性
无论你做什么,你都会经历失败。越早知道,越早修复,就能更好地保护你的用户体验。