Splunk AI Toolkit
カスタマイズされたAIモデルおよびワークフローを構築してデプロイ
データを活用してカスタムAIモデルを構築し、実用的なインサイトを得ることが迅速かつ的確な意思決定につながります。
ガイドに沿ったAI開発
詳細な手順を示したガイド付きワークフローで、ビジネスの課題に対応するモデルを構築してデプロイでき、時間を短縮できます。
実用的なインテリジェンス
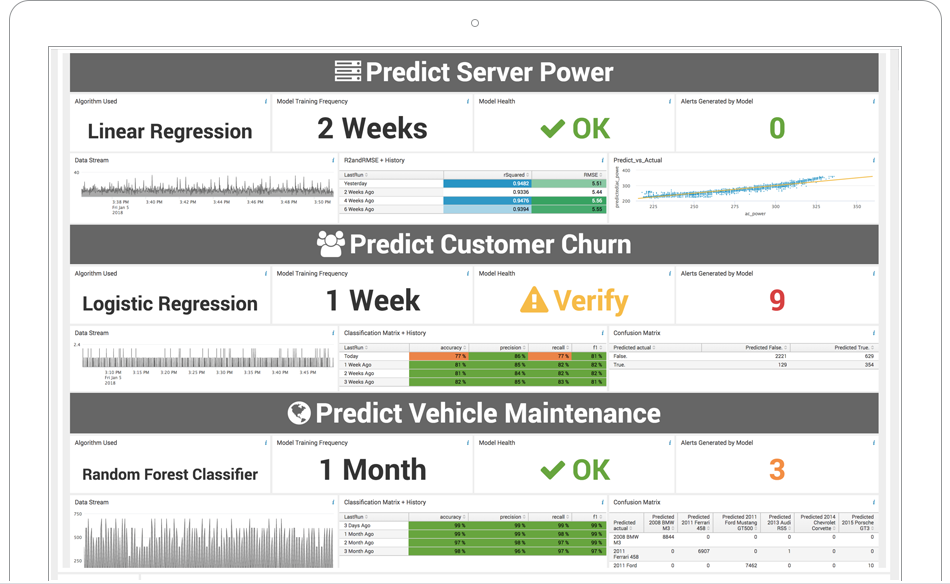
AIワークフローを運用化して、データの収集と分析、モデルの反復的なトレーニング、アラートの設定をリアルタイムで実行できます。
カスタムユースケースの迅速な構築
外れ値や異常の検出、予測分析、クラスタリングに向けた本番モデルの開発が可能です。
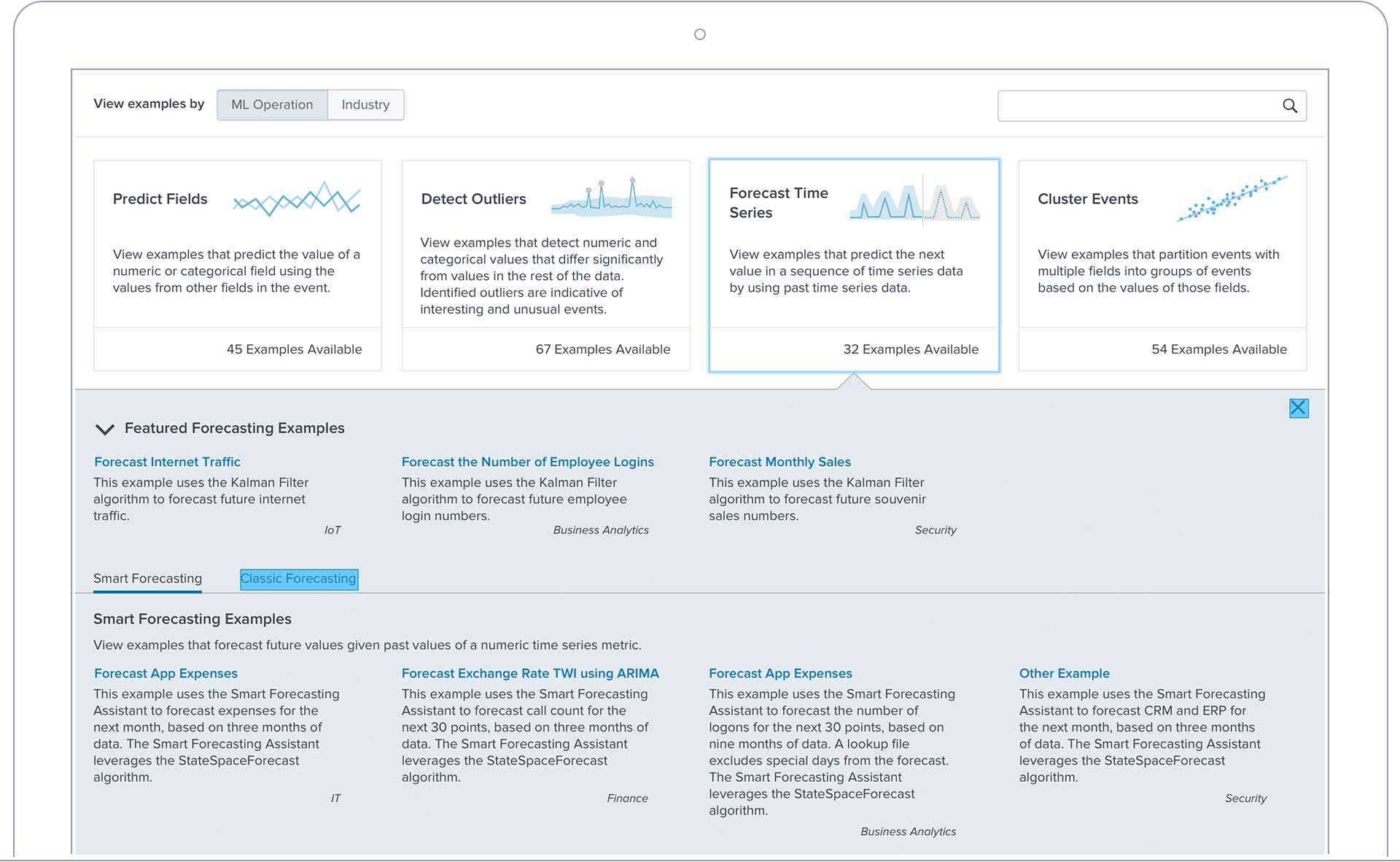
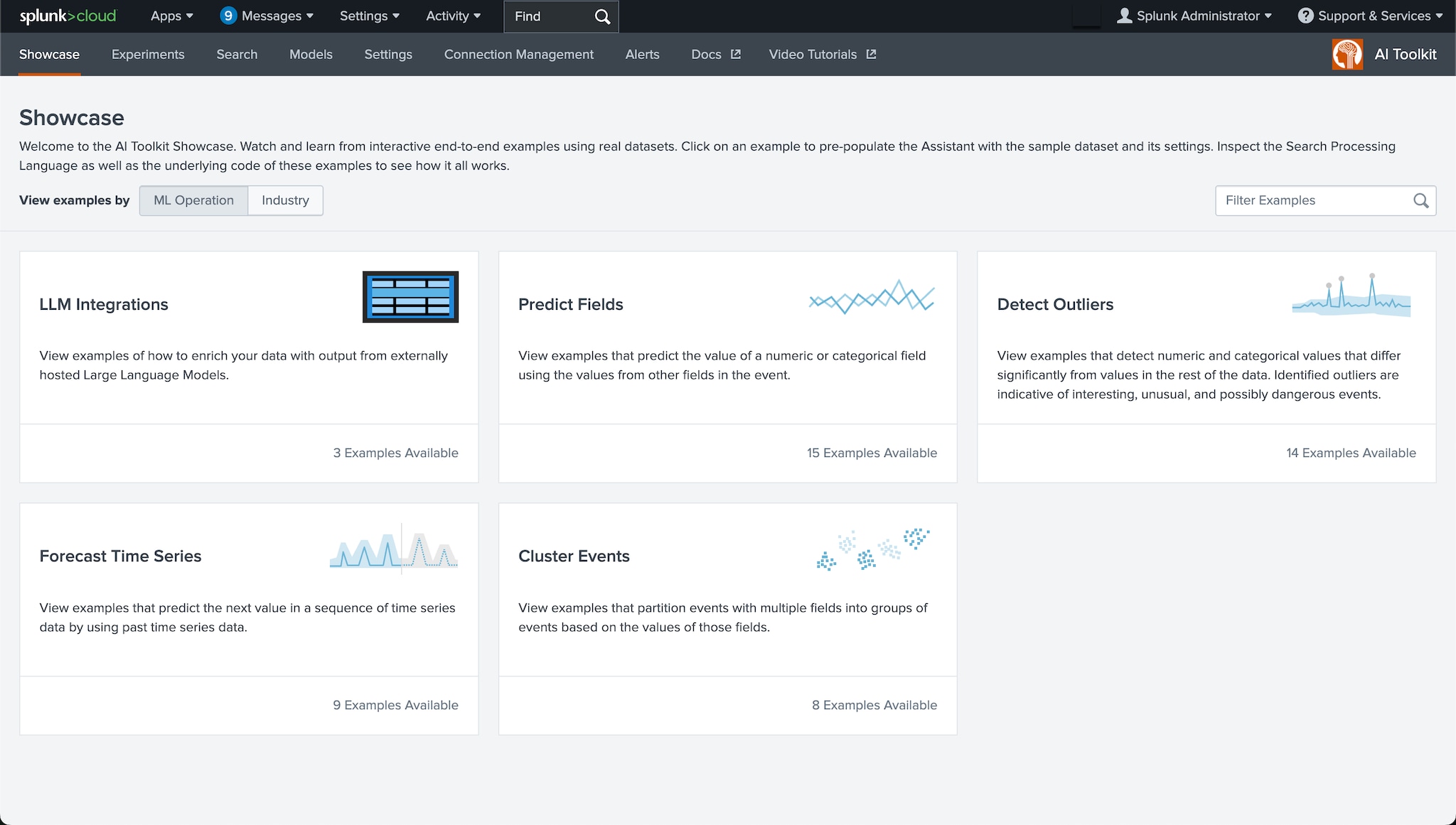
AI Toolkitでできること
SPLとオープンソースライブラリの統合
機械学習SPL (Search Processing Language)コマンドを使用して、教師あり/教師なしモデルを直接構築、テスト、運用化します。また、Splunk AI Toolkit Container for TensorFlow™ではTensorFlow™ライブラリを使用できます。このライブラリはSplunk認定プロフェッショナルサービスを通じて利用可能です。あらかじめパッケージ化されたPythonのアルゴリズムを使用するか、300種類以上のオープンソースのアルゴリズムをインポートできます。
大規模なデータセットに対応した高速パフォーマンス
Apache Spark™の信頼できるアルゴリズムによって容易な拡張、高い柔軟性、高速なコンピューティングを実現し、大規模なデータセットにも機械学習モデルを直感的かつ容易に適用できます。また、TensorFlow™ライブラリはSplunk MLTK Container for TensorFlow™からアクセスできます。
数値やカテゴリの外れ値を検出
Webサイトへのアクセスの変動を容易に特定し、通常と異なるトランザクションをタグ付けします。アクセスの急増や異常な値の組み合わせを含むイベントを検出します。以前の値と大きく異なる値を検出し、異常な値の組み合わせが含まれるイベントを見つけます。
時系列予測
履歴データに合わせたモデルを作成して将来の数値を予測します。正確な予測に基づくことで、組織のプランニングの精度が向上します。需要に応えるにはハードウェアのアップグレードにどれだけ支出すればよいか、地域の人口増加に対応するために携帯電話基地局の帯域幅をどれぐらい広げればよいかなど、焦点を正確に絞ることができます。
数値イベントのクラスタリング
クラスタリングアルゴリズムを使用してデータのパーティショニングを行い、挙動が似ているホストを突き止めたり、隠れたパターンを見つけ出したりすることができます。たとえばオンライン購入での未知の傾向やセキュリティ環境における異常、リソース使用の急増などを明らかにすることができます。
数値やカテゴリのフィールドを予測
ビジネスにとって重要な意味を持つ数値やカテゴリのイベントに関する予測モデルを構築します。これらの予測モデルをプランニングに使用したり、収益、コスト、需要、使用量、容量などに関する異常の発見に役立てることができます。