
Une feuille de route pour la résilience numérique des entreprises

Les prestataires de services financiers évoluent dans l’un des rares secteurs à devoir gérer autant de directives, de contraintes réglementaires et d’obligations de fournir des preuves. La criminalité financière, sous la forme d’actes frauduleux, reste néanmoins une problématique d’actualité, qu’il n’est possible de traiter qu’en exploitant les données disponibles de façon appropriée et holistique. Les évènements les plus récents ne sont d’ailleurs pas les seuls à le démontrer.
Exigences imposées par l’Autorité fédérale de supervision financière, exigences minimales en matière de gestion des risques, exigences informatiques pour la supervision des banques... Toutes ces exigences de conformité font partie intégrante des opérations quotidiennes des entreprises financières (et leur gestion est bien moins stressante lorsque l’on bénéficie de conseils d’initiés appropriés). Malgré ces mécanismes de sécurité et tous les autres qui ont été conçus pour protéger les banques elles-mêmes, mais également les investisseurs, les clients, les partenaires commerciaux et les collaborateurs, le monde de la finance fait toujours autant l’objet d’attaques criminelles.
Il suffit de penser à l’affaire Wirecard en plein été 2020, lorsque cette société de paiement allemande a fait les gros titres des journaux en raison de ses activités frauduleuses. Le monde entier découvre alors qu’en coulisses, ses bilans avaient été « gonflés » par l’intégration de recettes totalement inventées. Une pure affaire de fraude, d’abus de confiance et de manipulation de marché. Les pertes subies par les banques et les sociétés d’investissement à qui Wirecard avait emprunté de l’argent, par les investisseurs qui, impuissants, ont assisté à la chute du cours de leurs actions, ainsi que par la place financière allemande, dont les mécanismes de supervision sont aujourd’hui remis en cause, s’élèvent à plusieurs milliards d’euros. La criminalité financière coûte des sommes astronomiques à toutes les parties impliquées. Selon l’ACFE (Association of Certified Fraud Examiners), les dommages causés par la fraude s’élevaient à 3,6 milliards de dollars américains en 2020 à l’échelle mondiale. Sans compter la dégradation de l’image des entreprises et la perte de confiance des clients, une conséquence sans doute encore plus grave.
Même s’il n’est pas possible de trouver facilement la panacée pour lutter contre la fraude et la criminalité financière, les données jouent un rôle clé dans la mise en œuvre d’une solution pérenne. Et c’est précisément là que Splunk entre en jeu. Comme chacun le sait, Splunk Enterprise permet en effet d’enregistrer des données structurées et non structurées, qui peuvent ensuite être analysées et utilisées pour identifier les comportements frauduleux.
Les sources de données disponibles peuvent également contribuer à repérer les tentatives de fraude d’une autre façon, notamment en utilisant les données pour mettre en lumière les relations entre les différentes entités et faire ainsi émerger un nouveau type d’ensemble de données. Voyez cela comme les connexions au sein d’un réseau social. Qui est particulièrement populaire, où les informations se chevauchent-elles, avec qui peut-on éventuellement être ami en raison de relations et de centres d’intérêt communs ? Les algorithmes de graphes permettent d’identifier des relations entre les entités. Qui plus est, leur utilisation conjointe avec le nombre important de données hétérogènes hébergées dans Splunk offre la structure idéale pour mieux identifier les activités frauduleuses.
La solution présentée ici repose sur l’utilisation de Splunk Enterprise ou de Splunk Cloud conjointement avec quelques applications disponibles sur Splunkbase et avec lesquelles il est possible d’appliquer les algorithmes de graphes. Il s’agit notamment des applications suivantes :
L’application 3D Graph Network Topology propose des exemples tout à fait adaptés d’algorithmes de graphes, ainsi qu’une structure d’analyse de graphe permettant d’appliquer rapidement quelques algorithmes sur vos données dans Splunk.
Il s’agit, entre autres, des algorithmes suivants :
À partir de deux exemples, je souhaiterais vous montrer comment vous pouvez utiliser ces nouveaux outils pour détecter également la fraude. Nous devons tout d’abord nous intéresser au langage de recherche Splunk SPL (Search Processing Language) pour pouvoir analyser au mieux les données.
Supposons que vous ayez déjà enregistré vos données dans Splunk et que vous souhaitiez maintenant les analyser avec des algorithmes de graphes. Vous devez tout d’abord définir les sources de données à lier et les champs à utiliser pour cela. Généralement, vous définissez et extrayez les champs dont vous avez besoin à partir des données de journalisation brutes (ou ceux-ci sont extraits automatiquement s’il existe une source connue). Supposons que vous disposiez d’une source de données contenant des enregistrements de transactions d’un certain montant transféré entre deux entités (user_id_from, user_id_to) à un moment donné (_time) :
Nous pouvons maintenant interroger ce que l’on appelle une liste d’adjacence, qui contient toutes les liaisons souhaitées. Le langage SPL propose un modèle de recherche simple qui permet, par exemple, d’agréger le nombre de transactions entre les entités au cours d’une période choisie.
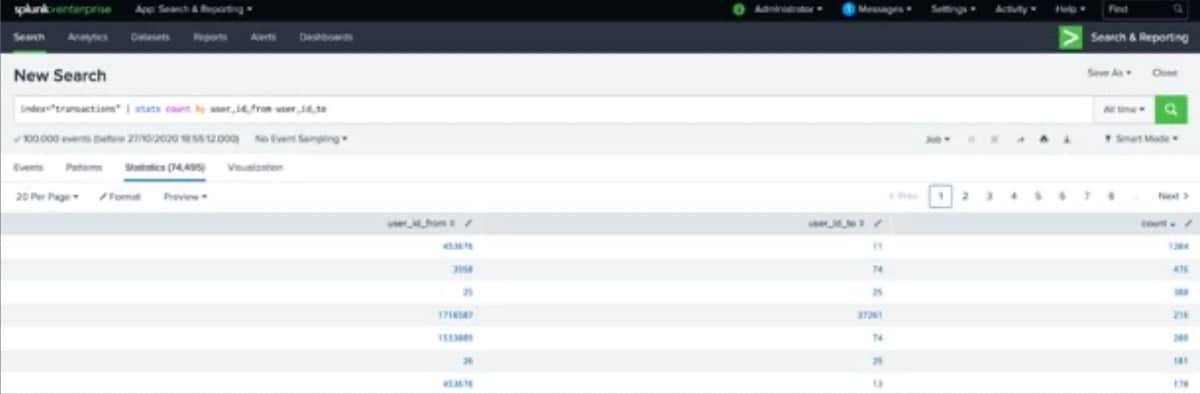
... | stats count by user_id_from user_id_to
Une fois calculés, les résultats apparaissent dans l’onglet « Statistics » (Statistiques).
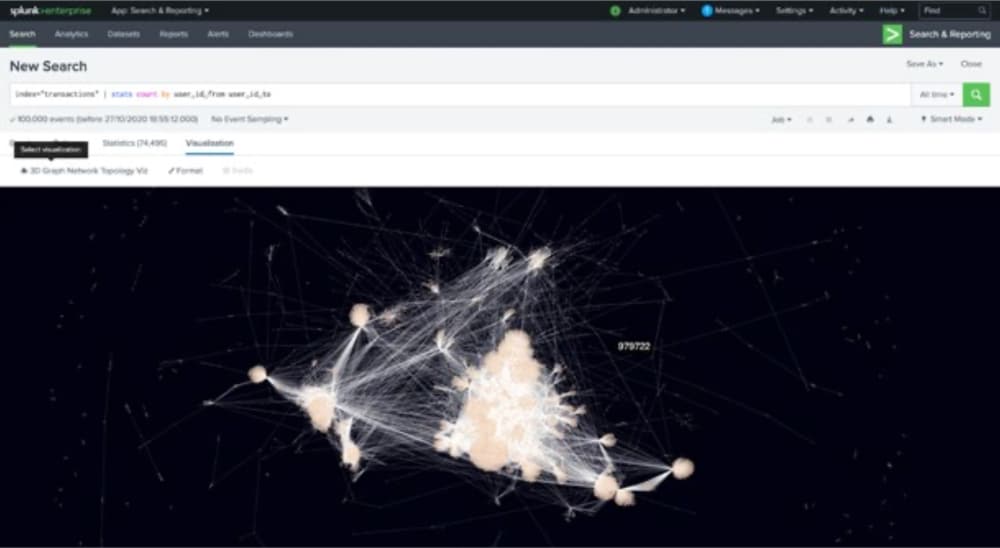
L’onglet « Visualization » (Visualisation) permet de représenter l’ensemble de données sous la forme d’un graphe au moyen de l’application 3D Graph Network Topology.
Il est possible de décrire les modèles de comportement suspect au moyen notamment de la pertinence de l’attaquant, c’est-à-dire sur la base de son importance ou de sa dangerosité au sein du réseau. Les mesures de centralité des graphes permettent de faire apparaître cette information.
Vous pouvez ainsi calculer la centralité de vecteur propre de chaque entité au niveau du graphe et identifier les entités les plus influentes et les plus importantes au sein du réseau. La centralité « intermédiaire » est un autre indicateur de mesure et tient compte du rôle central d’une entité par rapport aux transactions qui transitent par son intermédiaire. L’entité joue ainsi un rôle que l’on pourrait qualifier de médiateur et qu’il est possible d’analyser spécifiquement.
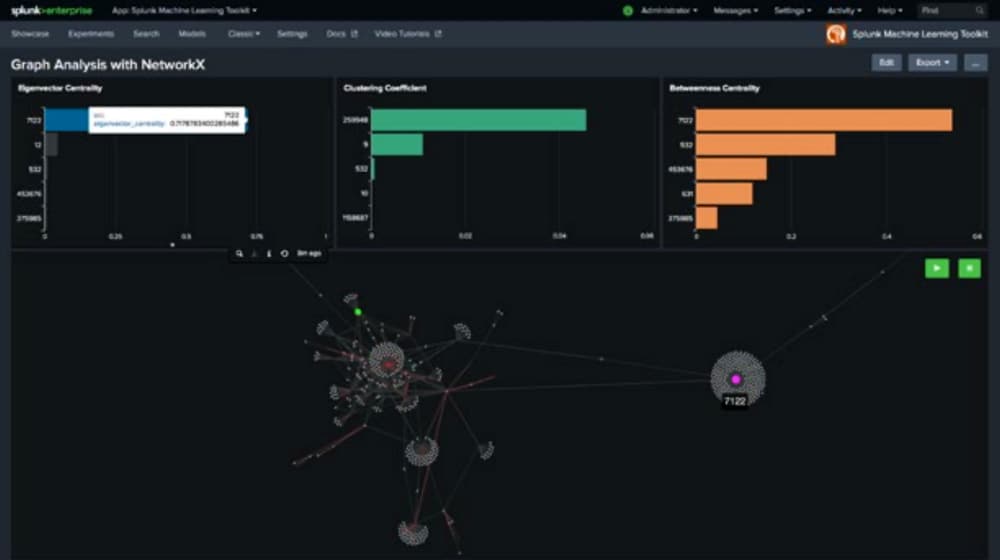
Dans l’exemple présenté ci-dessus, le tableau de bord Splunk affiche des transactions en bitcoins, dont le nœud 7122 mis en évidence en rose attire l’attention en raison de son degré élevé de centralité de vecteur propre, de son importante centralité « intermédiaire » et de la liaison majeure qu’il représente entre les moitiés droite et gauche. Les résultats révèlent des modèles significatifs dans des ensembles de données volumineux, qui facilitent la détection de la fraude et invitent à poursuivre les recherches.
Il est peu probable que des attaquants isolés agissent en tant qu’intermédiaires ou en tant que courtiers auprès de nombreux autres attaquants. Dans ce cas, la centralité « intermédiaire » que nous avons déjà évoquée entre de nouveau en jeu. Lorsqu’un attaquant isolé a été identifié, il convient ensuite de découvrir avec qui il est ou a été en contact au cours d’une période donnée, et dans quelle mesure toutes ces entités sont liées les unes aux autres. On parle alors de « réseau de fraude ».
Une telle structure peut être repérée avec un simple graphe. L’algorithme des composantes connectées attribue un numéro à chacun des groupes des entités liées, c’est-à-dire une sorte d’étiquette. Le graphe suivant affiche le résultat de l’application de l’algorithme sur un ensemble de données propres aux transactions financières.
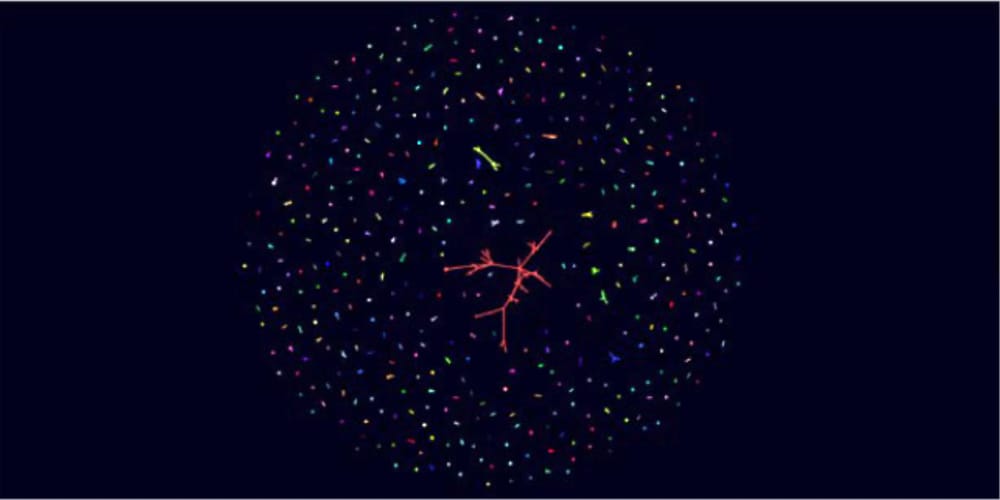
Chaque couleur représente une composante de corrélation d’une transaction monétaire entre plusieurs individus. L’élément rouge le plus important, au centre, indique un réseau de fraude et peut être utilisé comme point de départ pour des recherches supplémentaires. Avec les fonctions d’investigation de Splunk, il est possible d’identifier d’autres données en toute simplicité à partir de ce graphe. Nous pouvons même réutiliser les données des autres groupes appartenant aux entités liées pour optimiser l’évaluation des risques ou créer des modèles de risques. Bien entendu, ces données peuvent également être combinées avec les mesures de centralité présentées dans le premier exemple.
Ceci dit, cette approche n’est pas efficace si toutes les entités sont liées entre elles. Dans ce cas, il est possible d’appliquer, par exemple, la méthode de propagation des étiquettes ou de Louvain. L’algorithme de machine learning semi-supervisé identifie les points de données jusqu’ici non marqués et diffuse les étiquettes auprès d’un sous-ensemble de données dans l’intégralité du graphe. Découvrons comment cela fonctionne pour un sous-ensemble de transactions impliquant des bitcoins :
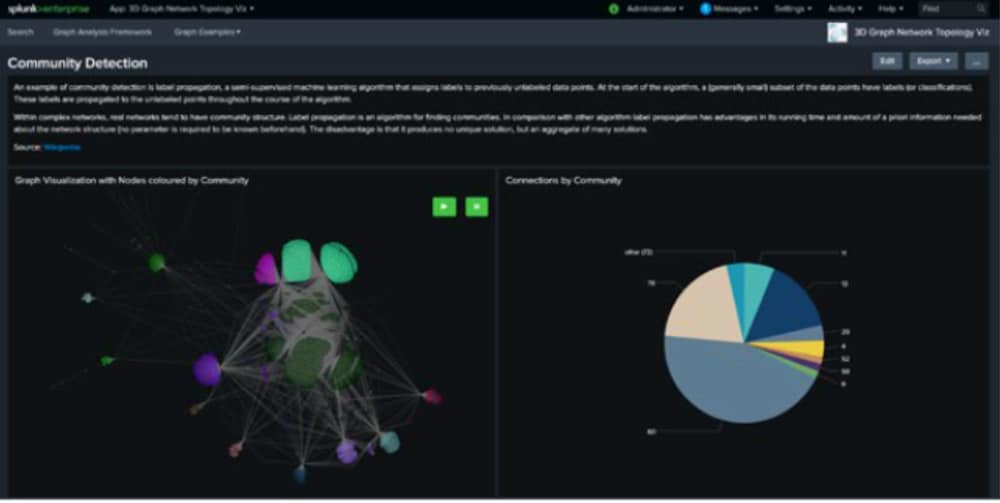
Nous pouvons voir que les différentes parties du graphe sont identifiées en tant que groupe (communauté) au moyen de la même couleur et qu’elles sont manifestement étroitement liées les unes aux autres. L’algorithme des composantes connectées offre là encore une autre perspective, qu’il est possible de découvrir dans la structure sous-jacente du graphe. Cela permet de repérer de nouveau des structures capables de suggérer la nécessité d’approfondir les recherches.
En guise de conclusion, voici maintenant un exemple d’analyse qui combine les deux méthodes au moyen du langage SPL :
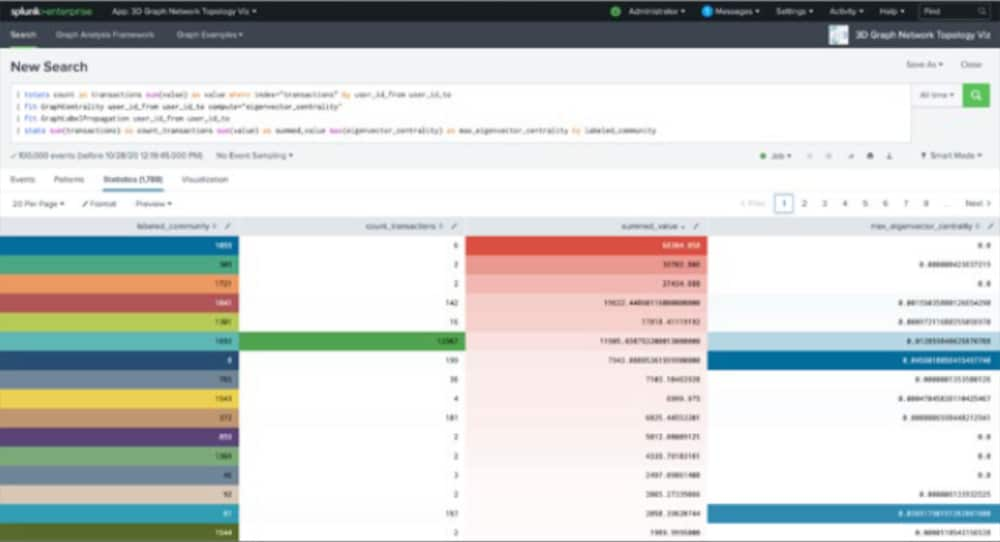
Les résultats d’analyse permettent de basculer entre le nombre total de transactions, le volume total de transferts et la centralité de vecteur propre maximale en fonction du groupe. Dans l’exemple ci-dessus, la valeur totale est triée dans l’ordre décroissant, ce qui nous permet de constater que les cinq premiers groupes ont transféré de grosses sommes d’argent pour un volume de transactions assez faible. Dans un premier temps, cela ne signifie pas grand-chose, mais en y regardant d’un peu plus près, nous constatons que les sixième et septième lignes portant les étiquettes 1692 et 8 ou 61 affichent une forte centralité de vecteur propre et/ou des volumes de transactions élevés. À cette occasion, des recherches approfondies peuvent être entreprises.
J’espère que cet article vous aura donné un bon aperçu de la situation et quelques conseils pratiques sur la façon d’identifier et d’empêcher les activités criminelles et frauduleuses dans le secteur financier au moyen d’algorithmes de graphes. N’hésitez pas à nous contacter directement pour toute demande d’éclaircissement ou toute question.
Bon Splunking !
Philipp
Remarque : cet article de blog s’inspire de l’article « Detecting and Preventing Financial Crimes With Graph Algorithms » rédigé par Philipp Drieger dans l’e-book « Bringing the Future Forward Real-world ways data can solve some of today’s biggest challenges ».
*Cet article est une traduction de celui initialement publié sur le blog Splunk allemand.

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.