
Une feuille de route pour la résilience numérique des entreprises
George Washington, le premier président des États-Unis, en avait déjà conscience : « If it is on the internet, it must be true and you can’t question it », « Si c’est sur Internet, c’est que cela doit être vrai » (ou bien c’était Albert Einstein qui disait ça ?). Ce qui devait être seulement une blague, se rapproche toutefois trop souvent de la réalité. Les réseaux sociaux nous mettent en contact d’une manière sans précédent. Ils suscitent de grands mouvements et représentent pour beaucoup de personnes la source d’informations numéro 1. Et c’est précisément là que réside le danger.
Fake News, expression dont on entend beaucoup parler ces dernières années : ce qui autrefois était la réponse standard de Donald Trump aux vérités dérangeantes, est devenu (peut-être aussi à cause de Donald) un problème concret. En effet, les études montrent que les Fake News sont par exemple retweetées sur Twitter 70 % plus souvent et atteignent le public 6 fois plus vite que les messages sérieux et véridiques. Cela peut avoir des conséquences très graves, voire mortelles, lorsque par exemple, des fausses informations circulent concernant le COVID-19 ou lorsque la diffusion ciblée de Fake News met à mal les élections démocratiques.
Les bots, également connus sous le nom de comptes automatiques, qui imitent les comptes humains et envahissent les réseaux sociaux avec des fausses informations, jouent un grand rôle dans ce type d’utilisation abusive des réseaux sociaux. Rien que sur Twitter le nombre de bots est estimé à 48 millions, soit 15 % de l’ensemble des comptes ! Dans son livre (à lire absolument) « Das Internet muss weg » (Internet doit disparaître), le blogueur Schlecky Silberstein décrit les études menées par l’Université d’Oxford et l’Université Corvinus à Budapest concernant les tweets des anglais pendant la campagne électorale du Brexit. 1,8 millions de tweets avec des hashtags appropriés (par ex. #vote-leave ou #remain) ont été analysés : 15 % d’entre eux étaient contre le Brexit, 35 % ne se prononçaient pas et 50 % pouvaient être attribués au camp des pro-Brexit. Mais ce qui était vraiment intéressant c’est que 1 % des profils d’utilisation de Twitter analysés étaient à l’origine de 30 % de l’ensemble des tweets. Un farceur en quête de mal.
Une autre étude menée par sadbottrue.com note que 10 % des retweeters de Brexit très actifs étaient des personnes réelles (20 sur 200). Il est ainsi très important d’identifier ces bots et de comprendre comment ils agissent lors de la diffusion de fausses informations.
Les bots sont formés à l’aide du machine learning. On utilise à cet effet des algorithmes qui sont de plus en plus perfectionnés grâce au nombre croissant de données sur les réseaux sociaux. Les réseaux sociaux s’efforcent certes de contrer les bots avec des modérateurs et des fact checkers, mais le nombre de bots et leur rapidité rend cela quasiment impossible manuellement. Si l’on veut garder le rythme avec ces méthodes, il faut recourir soi-même au pouvoir des données et affronter les bots avec des algorithmes et des messages automatiques.
Avec sa plateforme Data-to-Everything qui exploite l’intelligence artificielle, Splunk peut aider les entreprises qui doivent modérer les réseaux sociaux, dans leur lutte contre les bots, en traitant en temps réel les données des réseaux sociaux et, dans le cas de Twitter, en utilisant les données fournies par les réseaux sociaux pour lutter contre les bots. Le Splunk Machine Learning Toolkit (MLTK) permet de créer des modèles qui détectent les bots. Une réaction automatique peut alors transmettre l’incident soit à un collaborateur soit à la plateforme elle-même.
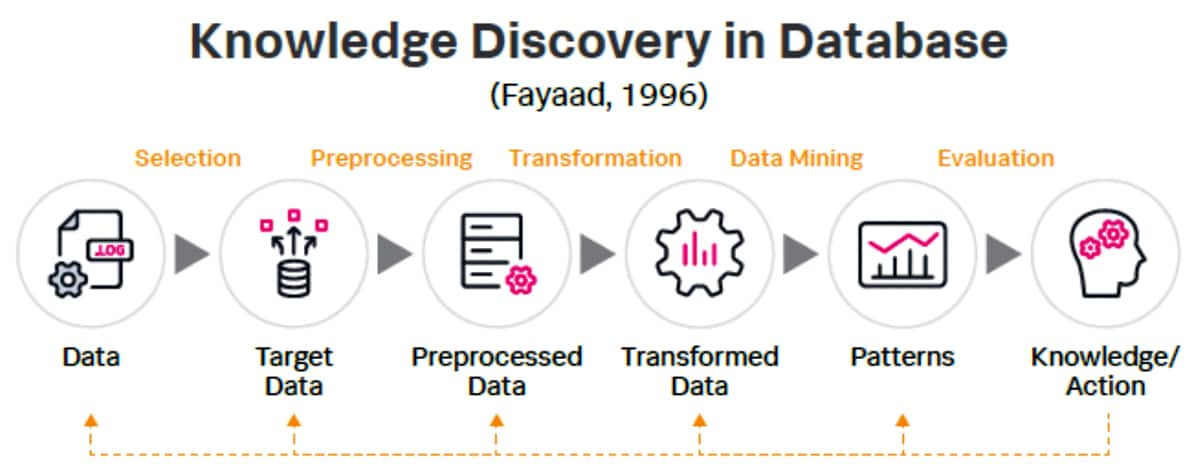
La méthode de Splunk se base sur le principe « Knowledge Discovery in Database » de Fayaad (1996).
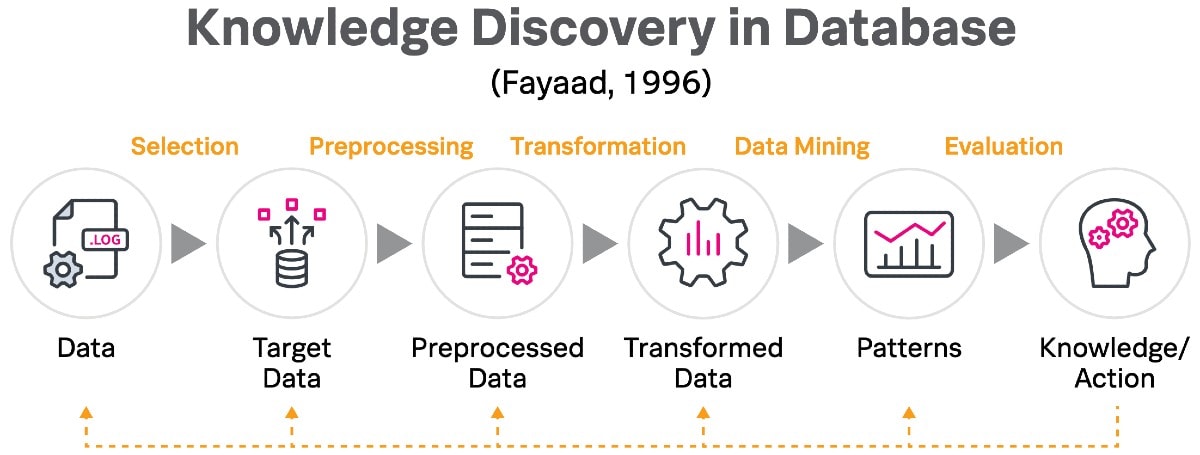
Une telle déconstruction de la solution permet une mise en œuvre logique, étape par étape, et montre comment Splunk agit de manière unique comme plateforme de bout en bout pour l’extraction et l’application des connaissances pendant le processus d’exploration de données ou « data mining ».
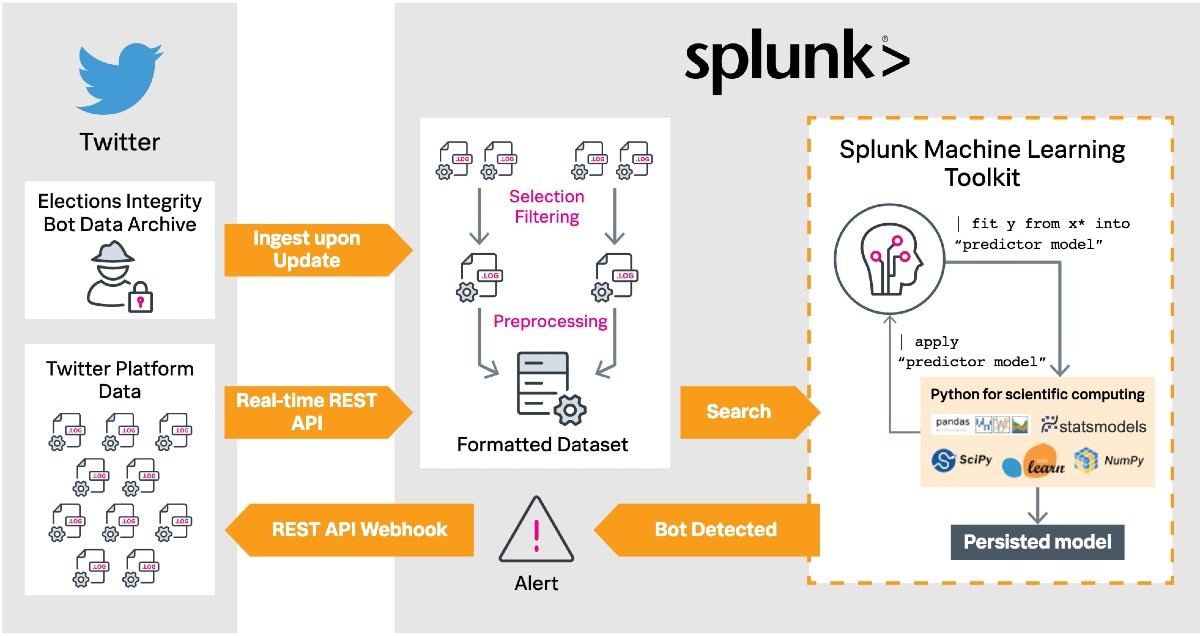
Il est question, dans un premier temps, de sélectionner le jeu de données à l’aide duquel sera développé un modèle de détection des bots. Comme nous nous concentrons sur Twitter dans cet exemple, nous utilisons l’enregistrement des données en temps réel. Les principaux posts sur Twitter ne sont pas protégés et sont visibles en public, c’est pourquoi ils peuvent être enregistrés par différentes interfaces. On distingue à cet effet l’enregistrement d’une sélection de tous les tweets (Sample API) et les tweets filtrés par mot-clé (Filter API). La procédure reste la même. Vous devez demander un compte développeur (developer.twitter.com) et vous pourrez ensuite créer des applications via le portail des développeurs. Le Splunk Add-On Builder est le moyen le plus simple d’enregistrer des données avec l’API REST (Representational State Transfer). L’application est disponible entre autres sur Splunkbase.
L’application vous permet de créer un add-on avant de devoir configurer une nouvelle entrée de données API REST. Sous « Inputs & Parameters », il est possible de définir le type source (Source Type) ainsi que le nom d’affichage et de saisie souhaité, ainsi que la fréquence de l’appel de l’entrée API. Un flux de données en temps réel est ainsi généré dans Splunk. L’appel REST ou REST-Call est également défini ici en entrant l’URL de l’API souhaitée avec les paramètres et en-têtes sélectionnés. L’exemple suivant utilise le Sample-API, de manière à ce que seul l’en-tête d’autorisation avec une valeur pour « Bearer » soit nécessaire, avec le Bearer-Token pour « Keys and Tokens » dans le portail des développeurs de Twitter.
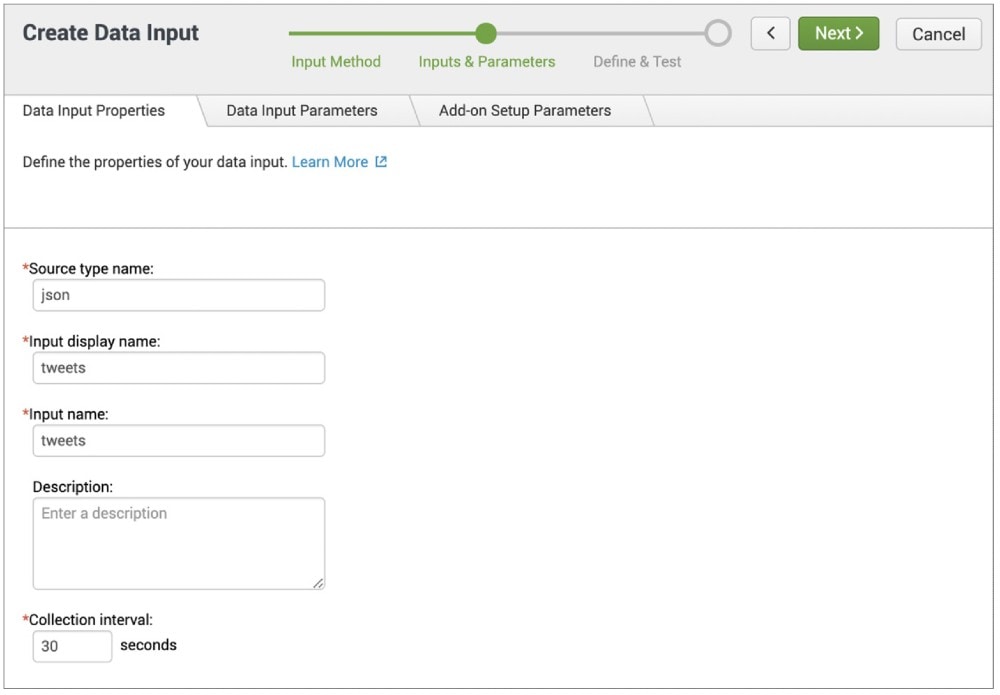
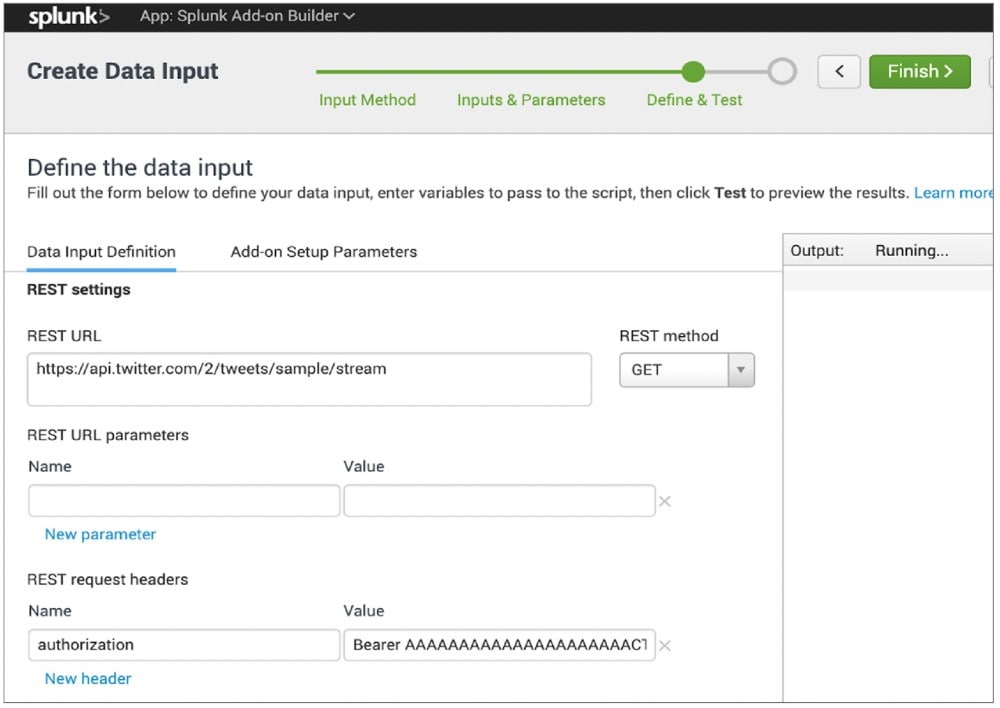
Puis, l’add-on créé est appelé à partir de l’écran d’accueil de Splunk, une entrée est configurée et il est défini dans quel index doivent se trouver les données et à quelle fréquence l’entrée doit consulter les données collectées. Les données des réseaux sociaux sont ensuite transférées en temps réel à Splunk au format JSON avec le contenu du post et avec les informations du compte.
Pour détecter les bots malveillants, les données doivent être comparées avec les bots déjà validés. Sous Add Data > Upload workflow, il est possible d’ajouter directement les données de Twitter qui sont mises à disposition par l’entreprise dans le cadre de l’initiative visant à préserver l’intégrité des élections (Election-Integrity-Initiative).
Toute personne qui a déjà réalisé une étude sur les données sait que la majeure partie du travail réside dans l’organisation des données collectées. Splunk simplifie et accélère considérablement cette partie du processus.
À commencer par la recherche de similitudes dans le contenu des champs (Fields) des jeux de données. Les noms des champs peuvent être différents, mais ils contiennent tous les deux le texte du tweet ainsi que les métadonnées sur le compte. Les informations qui ne sont pas couvertes par un des jeux de données ou qui peuvent être créées à partir d’un des jeux de données, sont ainsi éliminées efficacement et vous pouvez réduire le jeu de données avec l’instruction « outputlookup » dans Lookups.
Vous pouvez également créer de nouveaux champs à l’aide des champs calculés (Calculated Fields), champs qui sont ajoutés à des événements pendant la recherche et exécutent des calculs avec les valeurs de deux champs ou plus, disponibles dans ces événements. Il est ainsi possible d’analyser les aspects d’un champ individuel, par exemple, le nombre de hashtags, ainsi que les paramètres qui mettent en valeur la relation entre plusieurs champs, par exemple, la relation des followers avec les comptes qu’ils suivent.
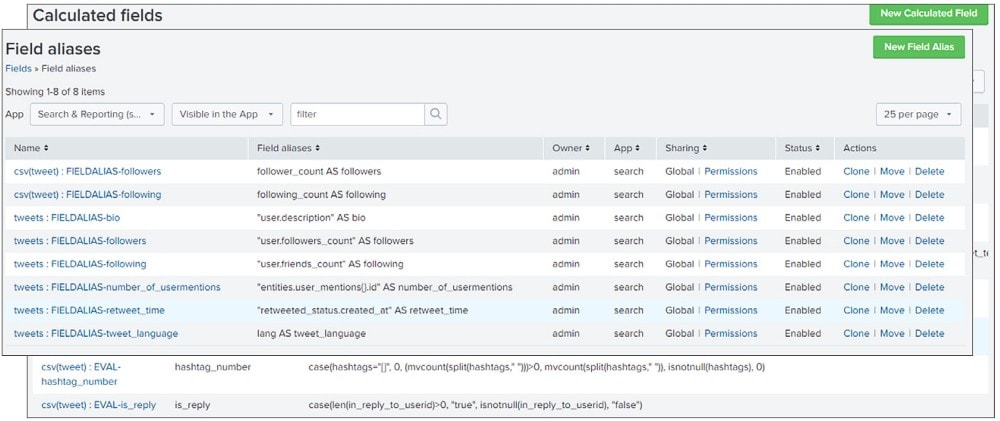
Vous devez ensuite transformer les deux jeux de données dans un jeu de données d’apprentissage cohérent et universel. Pour cela, vous devez utiliser vos alias/tags de champs (Field Aliases/Tags) pour créer des noms standardisés et durablement référençables pour les champs, et/ou renommer vos champs avec la commande SPL « rename » et afficher les résultats dans un Lookup actualisé, qui couvre les deux jeux de données.
Machine learning et data mining se partagent le processus en cours et le résultat souhaité. Alors que le machine learning se caractérise par l’automatisation, le data mining désigne le processus d’analyse d’un jeu de données pour identifier les modèles cachés. Il faut ainsi d’abord déterminer la méthode de data mining (ou de machine learning) qui est appropriée. Lorsque nous voulons définir si une contribution provient d’un bot ou d’une personne, nous avons besoin d’une classification binaire.
Le Splunk Machine Learning Toolkit offre les algorithmes nécessaires pour ce processus. Des algorithmes sci-kit learn sont pré-installés et permettent d’importer des algorithmes définis par l’utilisateur qui utilisent la bibliothèque Python for Scientific Computing et offrent des commandes supplémentaires spécifiques au ML qui étendent la base de commandes SPL, ainsi qu’un Experiment Management Framework qui représente une interface pour le contrôle et le suivi des versions des modèles.
Grâce au Toolkit et à des analyses et autres filtres, il est possible de créer un jeu de données optimisé pour la modélisation. Le workflow « Predict Categorial Fields » offre une interface utilisateur permettant d’exécuter les processus de pré-traitement, cela inclut l’amélioration de la qualité des données avec la mise à l’échelle des valeurs numériques ou la réduction des champs à un nombre donné de dimensions non corrélées via la Principal Component Analysis. La fonction la plus utile est toutefois l’algorithme FieldSelector qui utilise scikit-learn GenericUnivariateSelect pour sélectionner les meilleurs champs de prédiction (Predictor Fields) et réduit les moins utiles qui entraînent une suradaptation et peuvent altérer la qualité du modèle.
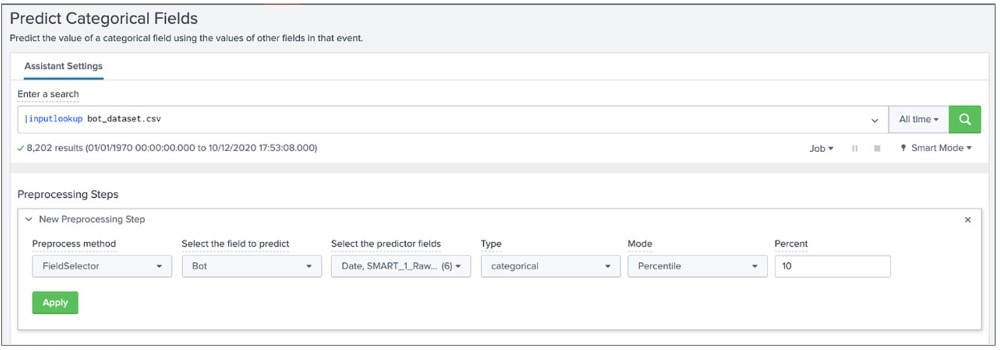
Une autre option à ce stade serait d’utiliser NLP Text Analytics, une application de Splunkbase qui confère à MLTK les fonctions du traitement du langage naturel (NLP). Vous pouvez ainsi trouver votre modèle dans le jeu de données, par exemple, la fréquence de certaines expressions linguistiques et opinions affichées, qui peuvent ainsi aider à différencier un robot et une personne et à programmer le modèle de détection.
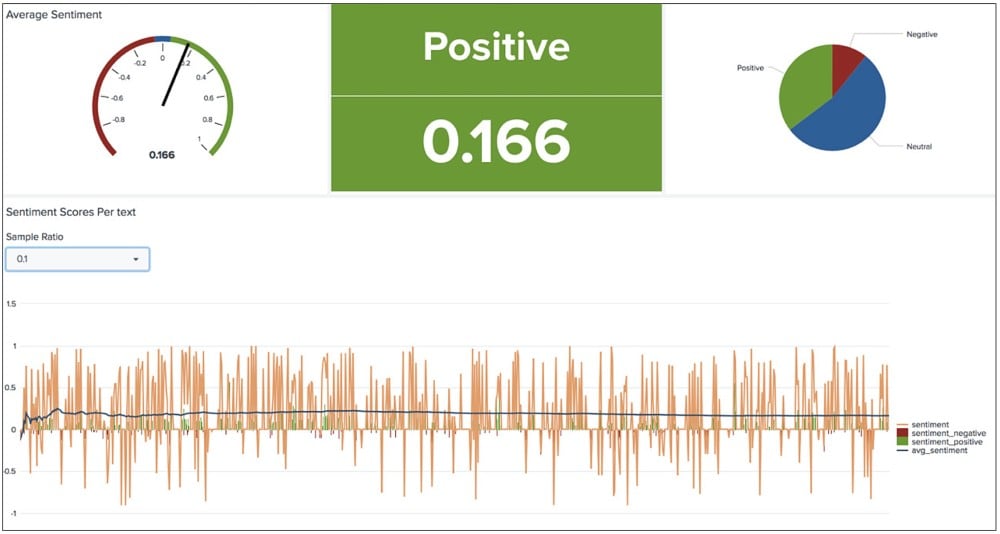
Les algorithmes de machine learning sélectionnés doivent ensuite être appliqués aux données pré-traitées. Le MLTK offre à cet effet un ensemble d’algorithmes de classification applicables immédiatement, par exemple, pour la régression logistique (Logistic Regression), l’algorithme Random Forest et les machines à vecteur de support (Support Vector Machines). Il suffit de sélectionner un algorithme et un champ de prédiction.
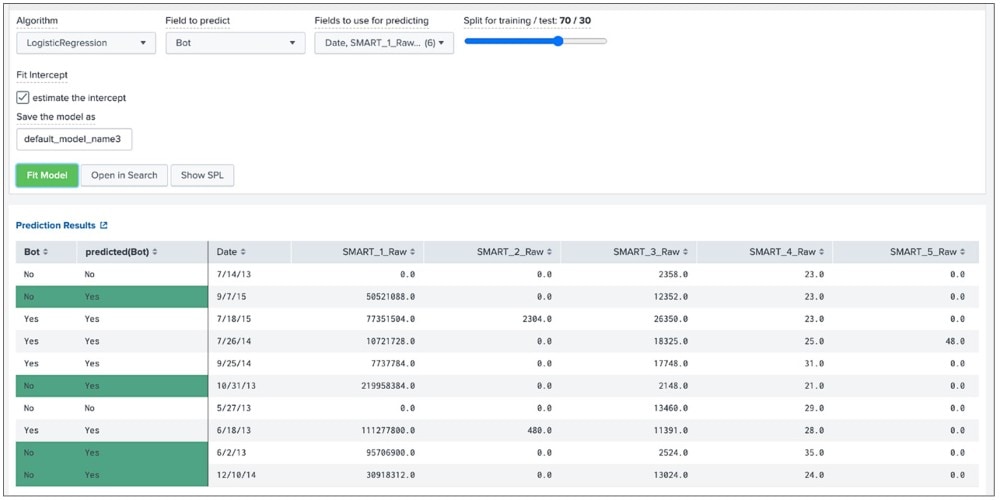
Les valeurs Exactitude (Accuracy), Recall et Précision (Precision) changent avec l’adaptation des modèles. Dans l’illustration ci-dessous, la valeur est de 0,84. Cela signifie que 84 % des prévisions de classification sont correctes. Approcher les 100 % serait théoriquement possible mais cela génère parfois une suradaptation avec le jeu de données d’apprentissage. L’exécution est alors défectueuse pour les nouvelles données inconnues.

L’optimisation de ces modèles est un processus continu qui progresse avec la quantité de données croissante qui est traitée dans Splunk.
Nous pouvons utiliser à cet effet les commandes MLTK qui étendent la base Splunk Processing Language (SPL), notamment « |apply », pour appliquer le modèle actuel aux nouvelles données. Les recherches pré-enregistrées peuvent être effectuées selon un planning donné. En cas de bot suspect, un message d’erreur est généré, par exemple, via Splunk On-Call.
La menace massive des bots automatiques qui diffusent des informations fausses sur les réseaux sociaux, peut sembler impressionnante. Nous espérons que ce blog sur la lutte contre les bots vous aidera un peu à appliquer cette solution et contribuera à lutter contre les fausses informations dangereuses en utilisant la technologie qui permet de contrer de tels bots.
Bon Splunking,
Philipp
Remarque : cet article de blog est basé sur « Real-Time Social Media Bot Moderation Solutions That Could Save Democracy » de Rupert Truman de l’e-book « Bringing the Future Forward Real-world ways data can solve some of today’s biggest challenges ».

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.