
Guide pratique de l’observabilité
Téléchargez cet e-book pour une introduction complète à l’observabilité.

Quand l’ensemble de vos systèmes IT, de vos applications, de vos logiciels et de vos équipes sont dispersés, il vous faut de la visibilité sur chacune des interactions qui s’y déroulent. C’est précisément ce que permet le traçage distribué.
Le traçage distribué est un moyen de suivre les requêtes dans les applications, ainsi que leur parcours depuis l’utilisateur et les dispositifs front-end, jusqu’aux services de back-end et aux bases de données.
Le traçage distribué vous permet de suivre des requêtes et des transactions à travers toute application supervisée. Il fournit des informations cruciales pour l’amélioration de la disponibilité, la résolution des problèmes et des incidents, l’optimisation continue et, en fin de compte, la création d’expériences irréprochables pour les utilisateurs et les clients.
Dans cet article, nous allons nous pencher sur le traçage distribué et les technologies utilisées pour le mettre en place dans votre entreprise.
La gestion des environnements logiciels modernes repose sur les trois « piliers de l’observabilité » : les logs, les métriques et les traces. On ajoute parfois les événements à ce triptyque, auquel cas, on parle alors des MELT. Chacune de ces sources de données apporte une visibilité cruciale sur les applications et l’infrastructure qui les accueille. Cette pratique est souvent appelée Supervision des performances des applications (application performance monitoring, APM), qui est une discipline de la supervision informatique.
Pour beaucoup d’équipes des opérations IT et d’ingénierie de fiabilité des sites (site reliability engineering, SRE), deux de ces piliers, logs et métriques, sont déjà bien connus. Cela fait des dizaines d’années que les équipes analysent les logs et les métriques pour :
En revanche, elles connaissent plus rarement les traces, le troisième pilier de l’observabilité.
La traçabilité n’est pas un concept nouveau. Une trace est une collection d’unités logiques qui représentent une transaction d’utilisateur ou d’API unique, traitée par une application et les services qui la composent.
La création de la trace commence à l’instant où un utilisateur interagit avec une application. Vous envoyez une première requête, en ajoutant un article à votre panier, par exemple, et cette requête reçoit un identifiant de trace unique. Une trace représente une interaction utilisateur. Quand la requête parcourt le système hôte, toutes les opérations qui s’y rapportent (les unités logiques) sont étiquetées.
La trace est un ensemble d’unités logiques, et chaque unité logique représente une opération unique qui contient :
Chaque unité logique représente un segment du parcours de la requête. Elle contient donc des informations utiles au sujet du service qui a effectué l’opération, notamment :
Les équipes qui développent et gèrent des applications monolithiques utilisent depuis longtemps les traces pour répondre à des questions clés sur leurs performances :
L’objectif fondamental du traçage est toujours le même : il s’agit de comprendre les transactions. Mais les méthodes employées, quant à elles, évoluent. Les anciennes pratiques ne fonctionnent pas avec les applications qui reposent sur une architecture logicielle distribuée, comme c’est le cas avec les microservices par exemple.
Examinons d’abord le traçage traditionnel et la façon dont il fonctionnait auparavant pour comprendre en quoi il n’est plus adapté.
Dans les anciennes applications monolithiques, le traçage était possible, mais il était moins crucial de comprendre chaque transaction : les requêtes parcouraient moins de composants au cours du traitement. Il y avait donc moins à tracer.
Les outils de traçage de l’époque s’appuyaient sur un échantillonnage probabiliste. Autrement dit, ils ne capturaient qu’une portion réduite et arbitraire de l’ensemble des transactions. L’échantillonnage probabiliste donne quelques informations sur l’activité de l’environnement. Mais comme il ne prélève qu’une partie des transactions au lieu de toutes les examiner, il ne donne pas une visibilité complète. Au mieux, cette approche permet aux équipes IT et SRE de :
Mais elle ne met pas en évidence les évolutions plus subtiles des performances. Surtout, elle est incapable de mesurer les milliers de services distribués d’un environnement en conteneurs éphémères. Par exemple :
Vous comprenez bien pourquoi cette méthode ne fonctionnera pas non plus avec les systèmes distribués et éphémères, sources d’alertes déconnectées les unes des autres qui complexifient le dépannage. Prenons l’exemple d’un nœud EC2 remplacé par un autre suite à une défaillance. Si cela n’affecte qu’une seule requête, faut-il vraiment émettre une alerte ? Avec cette approche, l’équipe n’identifiera pas le problème tant qu’il n’entraînera pas de graves perturbations.
Si vous travaillez dans un environnement statique et monolithique, tout va bien. Mais il est fort probable que le vôtre soit bien plus complexe et dynamique.
Une seule transaction utilisateur interagit avec des dizaines, voire des centaines de microservices, et chacun d’eux interroge des dépôts de données en back-end, interagit avec d’autres via des API ou échange avec d’autres parties de votre infrastructure. Autrement dit, des logiciels utilisent d’autres logiciels.
Les microservices sont faits pour être redimensionnés indépendamment les uns des autres. Il est tout à fait normal que plusieurs instances d’un même service s’exécutent simultanément sur différents serveurs, emplacements et environnements. Et chaque microservice peut s’exécuter sur des piles comprenant :
La supervision traditionnelle, qui consiste à examiner des échantillons ou un bloc de code spécifique, ne suffit plus. Pour comprendre la circulation des requêtes dans un réseau de microservices, il vous faut des données supplémentaires :
Comme les traces sont réparties sur différents services, le processus visant à baliser les unités logiques et à les corréler est appelé « traçage distribué ».
Imaginez un jeu vidéo en ligne populaire, comptant des millions d’utilisateurs. Ce jeu doit suivre l’emplacement de chaque utilisateur final, chaque interaction avec les autres joueurs, chaque objet acquis et une foule d’autres données de jeu. Maintenir le bon fonctionnement du jeu serait impensable avec les méthodes de traçage traditionnelles. Mais c’est possible grâce au traçage des requêtes distribué.
Le traçage distribué suit le parcours d’une requête (transaction) entre différents services d’une architecture en microservices. Vous pouvez ainsi connaître l’origine de la requête (application front-end côté utilisateur) et la suivre tout au long de ses échanges avec d’autres services.
Prenons l’exemple d’une collection de microservices dans une application moderne classique :
Dans cet environnement, la trace distribuée de la requête de l’utilisateur commence par enregistrer des informations sur l’état de la requête au niveau du premier service de front-end : les données saisies par l’utilisateur et le temps nécessaire pour les transmettre à d’autres services.
Le point de contact suivant de la trace se situe au niveau des services de back-end qui acceptent les données et effectuent les opérations de traitement nécessaires, comme l’ETL ou, de plus en plus souvent, l’ELT. Dernière étape, les services de back-end transfèrent les données traitées au service de base de données qui les stocke.
Prenons une simple application client-serveur :
Dans le contexte du client, une seule opération a eu lieu. Le client a envoyé une requête et reçu une réponse. Mais nous pouvons voir chaque requête de serveur générée suite à cette demande dans une unité logique. Chaque fois que le client effectue des transactions avec le serveur dans le contexte de l’application, d’autres unités logiques sont générées. Nous pouvons les corréler dans le contexte de trace.
Le contexte de trace est le liant qui rassemble les unités logiques. Penchons-nous sur le détail :
Vous remarquerez que le contexte de trace reste le même et relie chaque unité logique à la même transaction pour en informer l’infrastructure.
Un outil de traçage distribué commence par corréler les données de toutes les unités logiques, puis les convertit en visualisations qui sont :
Pour que vous puissiez collecter des traces, il faut d’abord que vos applications soient instrumentées. L’instrumentation d’une application se fait à l’aide d’un framework comme OpenTelemetry. C’est ce qui permet de générer des traces puis de mesurer les performances des applications. Ces informations sont extrêmement utiles : vous pouvez maintenant localiser sans problèmes les bottlenecks, sans perdre de temps.
Et si vous optez pour un framework indépendant des fournisseurs, comme OTel, vous n’aurez à réaliser le travail d’instrumentation qu’une seule fois.
Une fois votre application instrumentée, vous allez récolter les données de télémétrie à l’aide d’un collecteur.
Le Splunk OpenTelemetry Collector en est un excellent exemple. Il offre un moyen universel de recevoir, traiter et exporter les données de télémétrie des applications dans un outil d’analyse comme Splunk APM, où vous pouvez ensuite :
Saurez-vous identifier le microservice à l’origine des erreurs survenant dans l’application ? Avec Splunk, vous pouvez même aller plus loin et déterminer quelle version de paymentService est en cause.
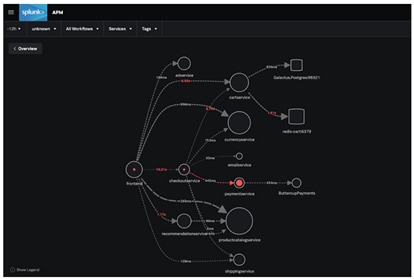
Le principal avantage du traçage distribué réside dans la visibilité centralisée qu’il apporte sur les transactions utilisateur réelles. La complexité n’est pas un problème. Cette approche plus holistique a plusieurs effets positifs :
En supervisant l’état des requêtes et ses caractéristiques de performance sur l’ensemble des services, les équipes SRE et IT peuvent localiser la source des dégradations. Elles peuvent également suivre des détails spécifiques pour connaître la réactivité de chaque service, afin de découvrir, par exemple, que :
Fragmentées par nature, les architectures de microservice compliquent la supervision des performances des applications, et en particulier la localisation et la correction des problèmes de performance. Il est beaucoup plus long et coûteux de superviser ces architectures que les applications monolithiques.
Il faut savoir également que les données sur les défaillances dans les microservices sont rarement claires, et les développeurs doivent souvent déchiffrer des messages d’erreur et des codes d’état sibyllins. Le traçage distribué offre une image plus globale des systèmes distribués, ce qui :
Tout cela a pour effet d’améliorer le temps moyen de rétablissement/réparation (MTTR).
Dans un environnement en microservices, chaque processus est généralement placé sous la responsabilité d’une équipe spécifique. Et cela peut s’avérer problématique au moment de comprendre les erreurs et de savoir qui doit se charger de les corriger. Dans ce contexte, le traçage distribué aide à :
Les outils de traçage distribués fonctionnent avec une grande variété d’applications et de langages de programmation, si bien que les développeurs peuvent les incorporer dans tous les systèmes ou presque et afficher les données via une même application de traçage.
Le traçage du code désigne l’interprétation, par un programmeur, des résultats de chaque ligne de code d’une application et l’enregistrement de son effet à la main plutôt qu’à l’aide d’un outil de débogage automatisé, dans le but de tracer l’exécution d’un programme.
Le traçage manuel de petits blocs de code peut être plus efficace car le programmeur n’a pas besoin d’exécuter l’intégralité du programme pour identifier les effets de modifications mineures.
Le traçage des données permet de vérifier l’exactitude et la qualité des données des éléments de données critiques (CDE), de remonter leur trace jusqu’à leurs systèmes sources, et de les superviser et les gérer à l’aide de méthodes statistiques. En règle générale, la meilleure façon d’effectuer des contrôles d’exactitude consiste à retracer les opérations jusqu’à leur origine et à les comparer aux données sources.
Une trace de programme, ou trace de pile, est un index des instructions exécutées et des données référencées lors de l’exécution d’une application. Les informations contenues dans une trace de programme incluent le nom du programme, le langage et l’instruction source qui a été exécutée, entre autres données, et sont utilisées dans le processus de débogage.
Quand les applications combinent différents langages de programmation, sont réparties sur des microservices distribués et développées par des équipes dispersées dans le monde entier, il est très utile de pouvoir instrumenter ses applications à l’aide d’un framework indépendant et ouvert.
OpenTelemetry permet l’instrumentation automatique des applications pour de nombreux langages de programmation, tandis que d’autres requièrent une instrumentation manuelle.
Jaeger et Zipkin sont deux outils open source populaires pour le traçage des requêtes, chacun avec des composants similaires : un collecteur, une banque de données, une API de requête et une interface utilisateur web.
Les deux fonctionnent de la même façon : les requêtes sortantes sont tracées tout au long de l’application. Le collecteur enregistre puis corrèle les données entre différentes traces et les envoie à une base de données où elles peuvent être interrogées et analysées via l’interface utilisateur.
Jaeger et Zipkin se différencient par leur architecture et les langages de programmation qu’ils prennent en charge : Jaeger est implémenté en Go et Zipkin en Java. Zipkin prend en charge pratiquement tous les langages de programmation avec des bibliothèques dédiées pour Java, Javascript, C, C++, C#, Python, Go, Scala et autres. La liste des langages pris en charge par Jaeger est plus courte : C#, Java, Node.js, Python et Go.
Kafka est une plateforme de diffusion distribuée à haut débit et à faible latence pour la gestion des flux de données en temps réel, souvent employée dans les architectures de microservices. Elle sert à :
Kafka utilise des « rubriques » (des catégories ou noms de flux sous lesquels les enregistrements sont publiés) pour abstraire les flux d’enregistrements. Pour chaque rubrique, Kafka gère un log partitionné, une séquence d’enregistrements ordonnée et augmentée en continu qui peut servir de log de validation externe pour un système distribué.
Aujourd’hui, les microservices sont la norme pour les applications basées dans le cloud. Le traçage des requêtes distribué offre un énorme avantage par rapport à l’approche traditionnelle consistant à chercher les problèmes potentiels comme une aiguille dans une botte de foin.
Si vous êtes responsable d’un système basé sur des microservices, vous pouvez transformer vos méthodes de travail en équipant votre entreprise de ce puissant outil. Découvrez le traçage distribué avec Splunk Observability. Essayez gratuitement pour obtenir une vue en temps réel de vos données de télémétrie et commencer dès maintenant à résoudre plus rapidement les problèmes.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.