
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。
データ分析でよく直面する難題の1つは、目の前の状況を引き起こしている原因を特定することです。このブログでは、データセットの中で何が最大の影響要因であるかを、因果推論を使用して詳しく把握する方法について説明します。
Splunkは以前から、メトリクスXがメトリクスYに応じて上下する場合も、XとYが互いに影響し合う場合も、「相関関係」という言葉で説明しています。
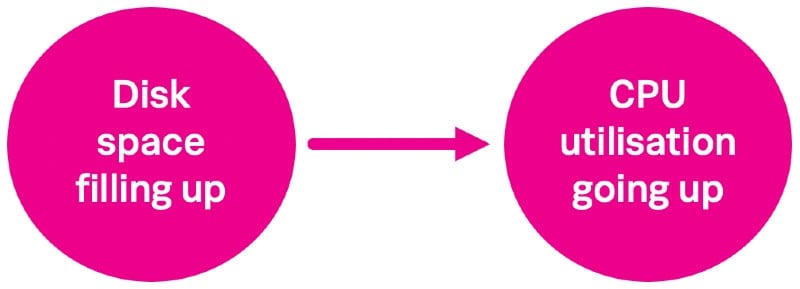
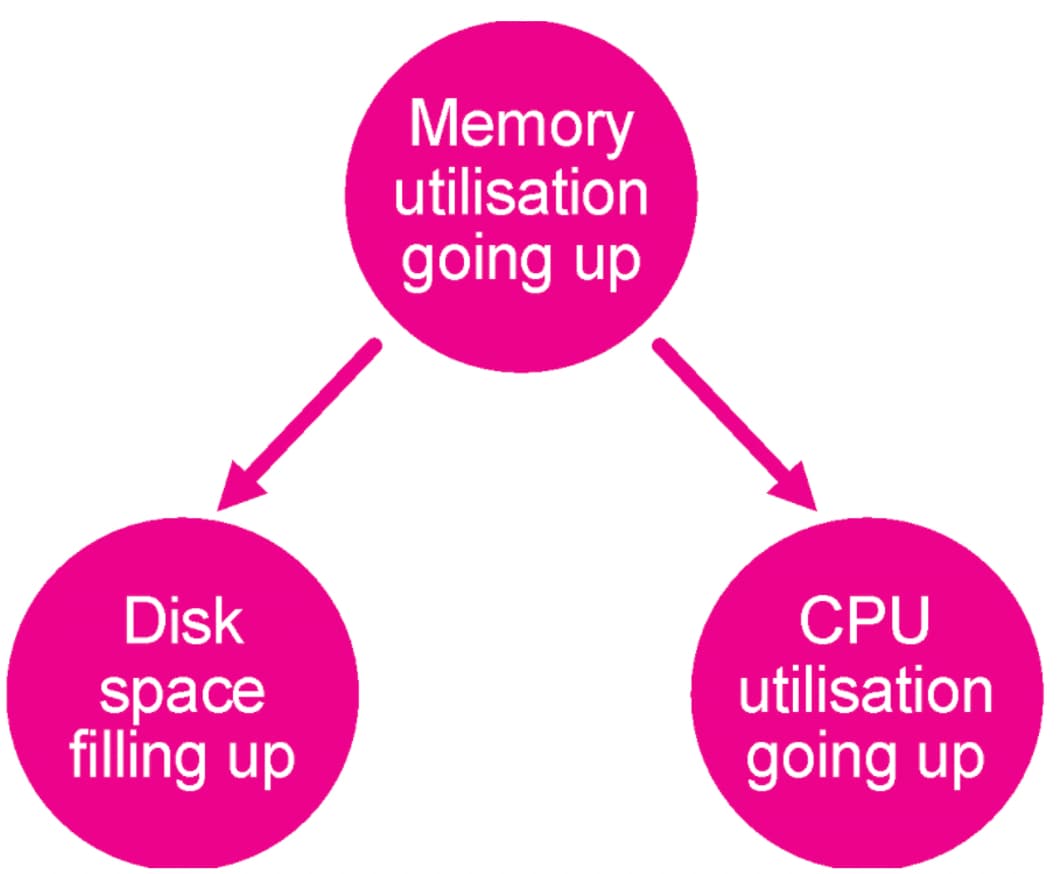
もちろん、相関関係と因果関係を同一とみなすことには問題があります。たとえば、CPU使用率が上昇した直接の原因がディスクの空き領域不足であっても、実際にはメモリー使用量の急増によってその両方が発生した場合、CPU使用率とディスク領域の因果関係は証明できません。
では、データの因果関係を証明するにはどうすればよいでしょうか。そこで使用するのが、Deep Learning Toolkit、SMLE、そして、データの因果関係を特定するためのPythonライブラリです。この種のライブラリはたくさんありますが、ここではQuantumBlack Labsの優秀なスタッフが共同開発したCausalNexライブラリを使用します。
CausalNexライブラリでは基本としてDAG (有向非巡回グラフ)が使用されます。DAGは、従来のグラフ分析と多くの類似点を持つ実用的なデータ構造です。従来のアプリで分析に使われ、ブログでも何度か取り上げてきたグラフとの主な違いは、DAGには2つのノード間の関係の向きに関する情報が多く含まれる点です。上記のメモリー使用量の図もその簡単な例の1つですが、このブログではより複雑なグラフを作成します。
DAGのユースケースはたくさんあります。皆様がよくご存じなのは家系図でしょう。このブログでは、DAGを使って、監視対象の環境に最も影響を与えているデータポイント、つまり最も注視すべきデータポイントを特定する方法について説明します。今後のブログでは、根本原因分析に役立つDAGの使い方もご紹介する予定です。
まずは、DLTKとその実行に必要なコンポーネントをインストールし、Dockerが稼働する環境を用意します。インストールとコンテナの準備に関する詳しい手順は、こちらのブログを参照してください。
SplunkインスタンスにDLTKをインストールして起動したら、CausalNexをインストールします。[Configuration (構成)]の下にある[Containers (コンテナ)]ダッシュボードに移動し、ゴールデンイメージを使ってコンテナを起動します。起動後、DLTKによって起動されたDockerコンテナの名前を確認する必要があります。Dockerを実行している環境のシェルで次のコマンドを実行します。
docker ps
これにより、環境内で稼働しているコンテナのリストが表示されます。実行しているゴールデンイメージの名前「phdrieger/mltk-container-golden-image-gpu:3.3.2」を含むコンテナを探して、その名前をメモします。その後、次のコマンドを実行してコンテナに接続します。
docker exec -it --user="root"/bin/bash
接続時は、Splunkでインストールが認識されるように、rootユーザーとして操作する必要があります。コンテナに接続したら、次のコマンドを実行してCausalNexライブラリをインストールします。
pip install causalnex
簡単ですね!
CausalNexライブラリに含まれるグラフを使用したい場合は、Pygraphviz、Graphviz、Pydotを追加でインストールする必要があります。これらをインストールするには、次のコマンドを次の順序どおりに実行します。
apt-get install graphviz pip install graphviz pip install pydot pip install pygraphviz
これでDLTKでコードを記述する準備ができました。
CausalNexドキュメントのDAGRegressorの例に従って独自のノートブックを作成します。まずは、barebone.ipynbノートブックをコピーして、名前を「causalnex.ipynb」に変更します。
ステージ0では、次のコマンドを実行してライブラリをインポートします。
apt-get install graphviz pip install graphviz pip install pydot pip install pygraphviz
ステージ1では、MLTKContainerのfitコマンドでmode=stageオプションを指定して、ノートブックでの実験に使用するサンプルデータをSplunkから取り込みます。このブログでは省略します。ステージ2では、コードでモデルを定義します。
def init(df,param):
model = DAGRegressor(
alpha=0.1,
beta=0.9,
fit_intercept=True,
hidden_layer_units=None,
dependent_target=True,
enforce_dag=True,
)
return model
ステージ3では、モデルをフィッティングするためのコードを記述します。ここでは、DAGRegressorのフィッティング前に、データにスケーリングアルゴリズムを適用します
def fit(model,df,param):
target=param['target_variables'][0]
#Data prep for processing
y_p = df[target]
y = y_p.values
X_p = df[param['feature_variables']]
X = X_p.to_numpy()
X_col = list(X_p.columns)
#Scale the data
ss = StandardScaler()
X_ss = ss.fit_transform(X)
y_ss = (y - y.mean()) / y.std()
scores = cross_val_score(model, X_ss, y_ss, cv=KFold(shuffle=True, random_state=42))
print(f'MEAN R2: {np.mean(scores).mean():.3f}')
X_pd = pd.DataFrame(X_ss, columns=X_col)
y_pd = pd.Series(y_ss, name=target)
model.fit(X_pd, y_pd)
info = pd.Series(model.coef_, index=X_col)
#info = pd.Series(model.coef_,
index=list(df.drop(['_time'],axis=1).columns))
return info
最後のステージ4では、モデルを適用して結果を生成するためのコードを記述します。
def apply(model,df,param):
data = []
for col in list(df.columns):
s = model.get_edges_to_node(col)
for i in s.index:
data.append([i,col,s[i]]);
graph = pd.DataFrame(data, columns=['src','dest','weight'])
#results to send back to Splunk
graph_output=graph[graph['weight']>0]
return graph_output
このコードでは最後に、DAGRegressorモデルを適用してから、その結果をSplunkで詳しく分析および可視化できるように、Splunkインスタンスに返すためのデータフレームに変換しています。
ここではモデルの保存、再読み込み、サマリー生成は行わないため、以降の数ステージは省略します。
コードの準備ができたので、動作を確認しましょう。
まずは、作成したノートブックでCausalNexライブラリを使って生成できるグラフのタイプを確認します。Splunkで次のサーチを実行して、不動産データをコンテナ環境に取り込みます。
| inputlookup housing.csv | fit MLTKContainer mode=stage algo=causalnex "median_house_value" from *
Jupyter Labの/notebooks/data/フォルダーからこのデータにアクセスできるようした後、ノートブックの最後で次のコマンドを実行してグラフを生成します。
df, param = stage("causalnex")
model = init(df,param)
fit(model,df,param)
apply(model,df,param)
model.plot_dag(True)

この時点で、グラフをSplunkに返して、こちらのブログ「Deep Learning Toolkit 3.2 - グラフィック、RAPIDS、Sparkなど」に示すように可視化することも、またはfitコマンドを実行して、その結果データをSplunkに返し、次のサーチを使って可視化することもできます。
| inputlookup housing.csv | fit MLTKContainer algo=causalnex "median_house_value" from * | rename "predicted_median_house_value" as src | table dest src weight
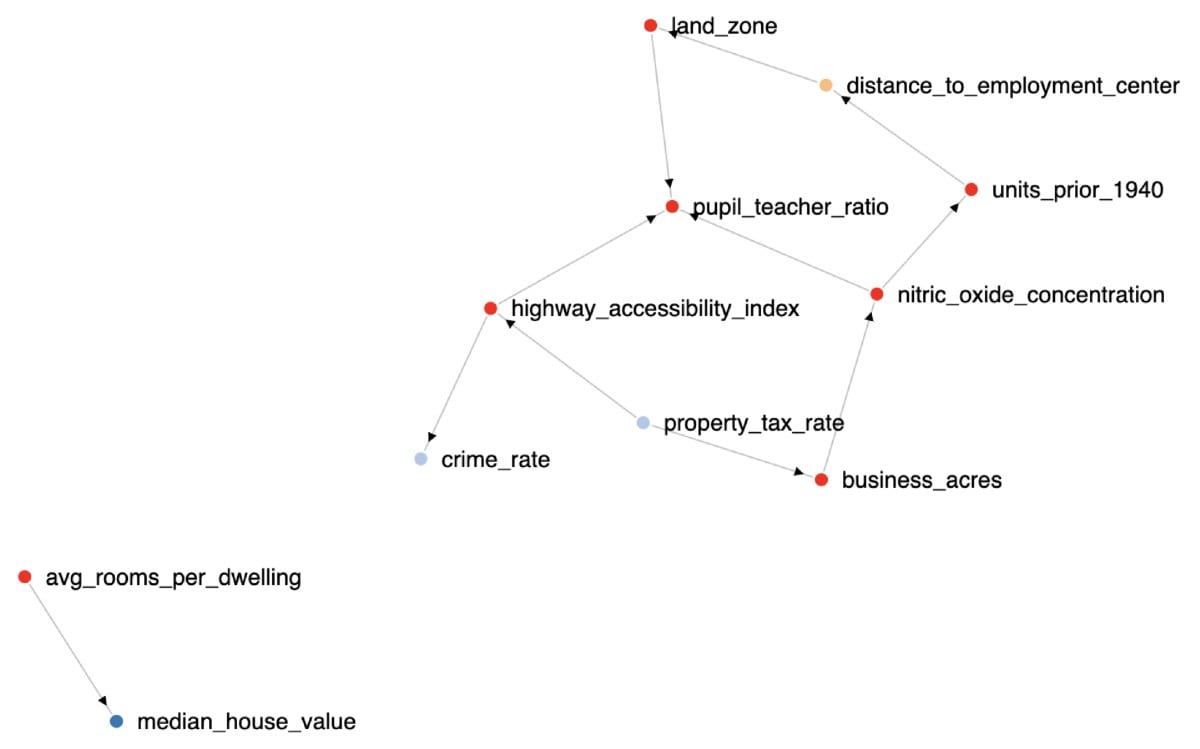
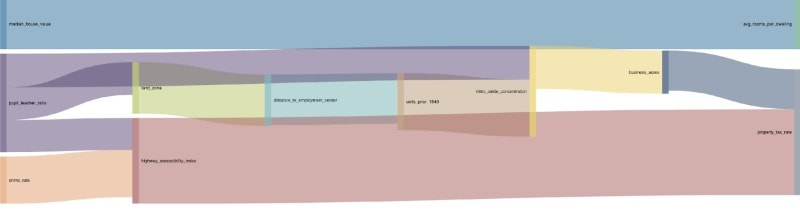
このサーチの結果を力指向グラフまたはサンキーダイアグラムを使って可視化すれば、どの変数が他の変数に対して最も大きな影響を与えるかを把握できます。
.conf20またはその後の発表ですでにご存じの方もいらっしゃるかもしれませんが、SplunkはSplunk Machine Learning Environment (SMLE)のクローズドベータ版をリリースしました。SMLEは、Splunkプラットフォームでの機械学習モデルの大規模な作成と展開を支援する新しいソリューションです。Jupyter Notebookの操作性を継承したSMLEでは、SPL、R、Python、Scala言語を組み合わせて、データサイエンティストと従来のSplunkユーザーが協力しながら、アルゴリズム、データ、モデルを開発、運用できます。
ベータ版を使用している幸運なお客様のために、SMLEで同じように因果推論を行う方法を簡単にご説明します。SMLE環境にアクセスしたら、「causalnex」という名前の新しいノートブックを作成し、次のスクリプトを実行して、必要なすべてのライブラリをインポートします。
import sys
!{sys.executable} -m pip install causalnex
import causalnex as cn
import numpy as np
import pandas as pd
ライブラリをすべてインポートしたら、CausalNexチュートリアルから、下の図に示すDAGRegressorのコードをノートブックにコピーします。
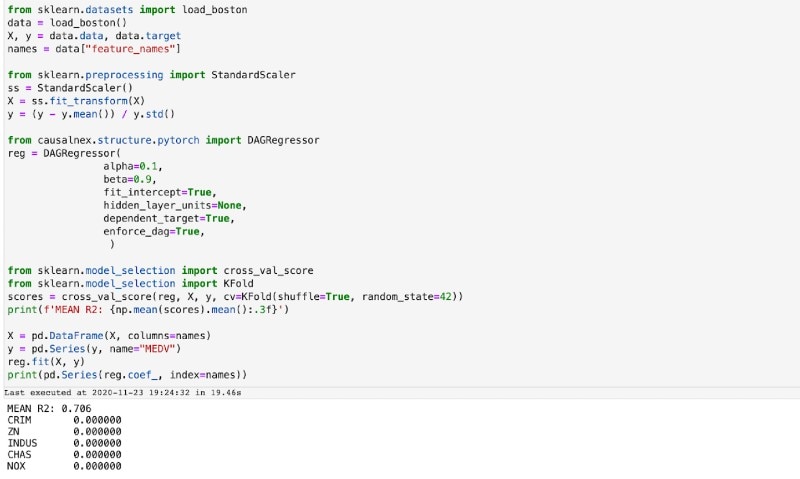
このコードを実行したら、DAGRegressorアルゴリズムによって生成されたモデルと、Networkxライブラリを使って、DAGを作成します。その後、Networkxの組み込み関数を使って、作成したDAGを可視化します。
import networkx as nx
dag = nx.DiGraph()
for col in list(names):
s = reg.get_edges_to_node(col)
for i in s.index:
if s[i]>0:
dag.add_edge(i, col, weight=s[i]);
s = reg.get_edges_to_node("MEDV")
for i in s.index:
if s[i]>0:
dag.add_edge(i, "MEDV", weight=s[i]);
from matplotlib import pyplot as plt
nx.draw(dag, arrows=True, with_labels=True)
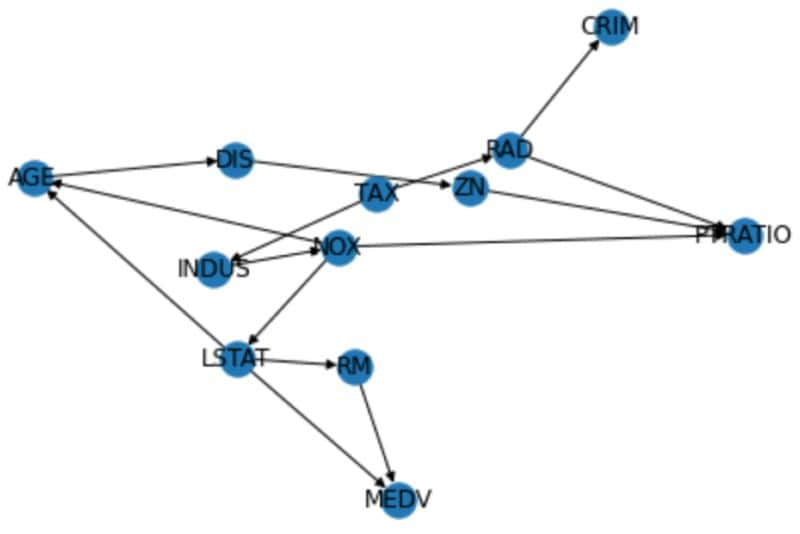
このブログでは、SplunkとDLTKまたはSMLEを組み合わせて因果関係を特定する方法をご紹介しました。この因果推論を活用したユースケースをぜひご自身で考えてみてください。今後のブログでは、ITSIでの分析時に根本原因を特定するための因果推論の使い方をご紹介する予定です。
Splunkのメリットをどうぞお試しください。
このブログはこちらの英語ブログの翻訳、沼本 尚明によるレビューです。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
