
オブザーバビリティの現状
グローバル調査で明らかになった、AI導入、セキュリティチームとのコラボレーション、ビジネス収益の促進要因に関する現状をご紹介します。

大規模な分散環境でマイクロサービスを使用している組織では、監視を徹底しながらログにも目を光らせていることでしょう。また、APMを適切に設定した分散トレーシング環境でコンシューマーコールをトレースしている組織も少なくないはずです。しかし、オブザーバビリティの観点からはこれでもまだ不十分である可能性があります。
調査に何時間もかけた末に、結局いずれかのチームがデプロイをロールバックすることになった、というようなインシデントを何度経験したことがあるでしょうか。こういったケースは思っている以上に多いものです。
過去のブログ記事「CI/CDツールとDevOpsの関係とは?Jenkinsの導入まで解説します」でも触れたように、イベントとアラートの潜在能力を最大限に活用できていなければ、ソフトウェアのライフサイクルとCI/CDプロセスの重要な要素を見逃している可能性があります。イベントベースのCI/CDデータを有効活用できれば、MTTD/MTTRを数時間から数分に短縮できるかもしれません。
Splunkの新たなAzure DevOpsインテグレーションを使用してSplunk Observabilityへのイベント送信とアラートベースのリリース制御を行うことにより、CI/CDのコンテキスト情報を監視プラクティスに取り入れることができます。
ここで、以下の問いについて考えてみてください。
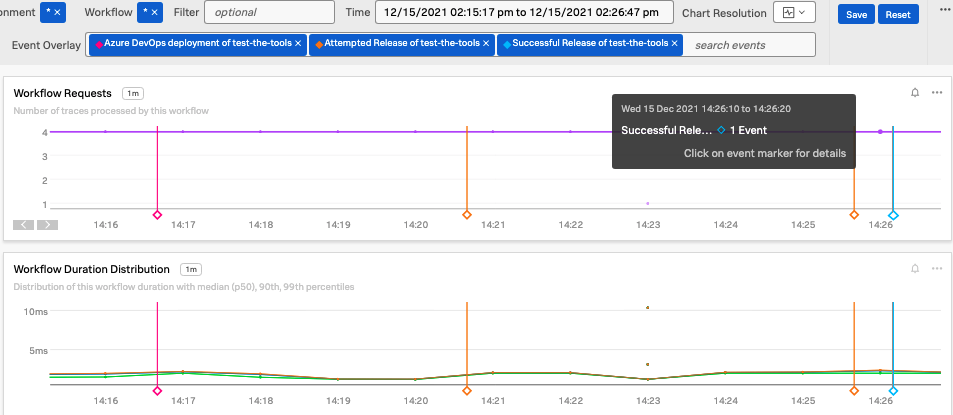
Splunk Observabilityはイベントの可視化に優れています。イベントマーカーやラインを使ってダッシュボード上に重ねて見やすく表示できるうえ、これらの機能は基本的に無料で提供されています。デプロイの開始、成功、失敗など、豊富なコンテキスト情報をイベントマーカーを使ってダッシュボードに表示することができるほか、自身の管理するサービスだけでなく依存している上流サービスも表示できます。
図1-1. Azure DevOpsのCI/CDイベントをダッシュボードのグラフに重ねて表示することで簡単に確認できます
適切な監視(およびそれにともなうインシデント管理)を行う際に重要なのは、コンテキストとコミュニケーションです。チームが提供するサービスや別のサービスのパフォーマンスに、デプロイが影響を与えているかどうかを迅速に確認できるようにすれば、ソフトウェアチームはMTTD (平均検出時間)とMTTR (平均修復時間)を短縮できます。
重要なのは、ツールの切り替えを減らし、単一のUIで利用できるコンテキスト情報を増やすことです。一方、Azure DevOpsインテグレーションには他にもメリットが複数あります。
Microsoft Marketplaceから入手できるSplunk Observability Cloud Eventsインテグレーションをぜひお試しください。
前述のように、ソフトウェアのデプロイに関連するアラートやイベントを作成することには大きな意味があります。自身が管理するサービスや上流のサービスがいつデプロイされたかという情報は、開発、SRE、CI/CD、DevOpsの各チームにとって極めて重要なシグナルです。次にとるべきステップは、Splunk Observabilityのアラートに基づいてリリースをプロアクティブに制御することです。
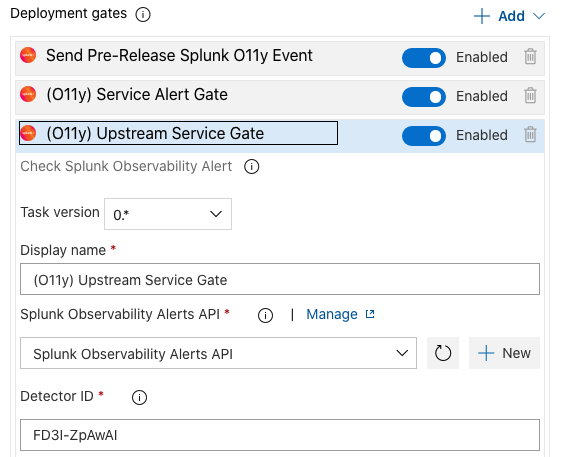
たとえば、下の図1-2には3段階のステップが示されています。まず、パイプラインの開始時にSplunk Observabilityにイベントを送信し、イベントを監視対象としてマークします。次に、サービスのアラートが生成されていないことを確認した後、上流サービスのアラートが生成されていないことを確認してから、最終的にリリースプロセスの残り部分を実行します。
図1-2. Splunk Observabilityのアラートに基づくデプロイ制御の設定
通常は、自身のチームが管理するサービスのアラートに基づいてリリースを制御することから開始します。ただし、そのサービスが関与するインシデントが発生した際には、これが対応作業の妨げになることもあります。一刻を争うインシデント対応においては、修正プログラムのデプロイが妨げられるようなことがあってはなりません。このような場合、インターフェイスからクリックひとつで簡単にAzure DevOpsのパイプライン制御機能を無効にすることができます。
また、多くの場合にさらに便利なのが、自身が管理するサービスに影響を与える上流サービスの健全性に基づいてデプロイやリリースを制御する機能です。以下に、より効果的なリリース制御を行うための例をご紹介します。
リリース制御は、ソフトウェア環境全般の整合性を確保するための重要なツールです。インシデントの発生中に変更が追加されるのを防止できれば、サービスの可用性に関するKPIが低下するのを防ぐことができます。トラブル発生時に不適切なデプロイを行わないようにプロアクティブな対応を行えば、インシデント管理担当者を不機嫌にさせることもありません。
Microsoft Marketplaceから入手できるSplunk Observability Alert Gatesインテグレーションをぜひお試しください。
既に述べたとおり、Splunk Observabilityのイベントとアラートは、取り込み、保存、利用のいずれに関してもコストは発生しません。こういった「無償サービス」は多くの企業で活用されないままになっているのが現状ですが、これがソフトウェアチーム、インシデント管理、CI/CDプロセスにもたらす価値は計り知れません。
デプロイ、リリース、インフラ変更を示すイベントは、監視にとって極めて重要なコンテキスト情報を提供します。
アラートは、サービスの健全性に関する警告を発したり、オンコール対応要員への通知を行ったりするために使用されるのが一般的ですが、アラートが把握するソフトウェア環境のコンテキスト情報をデプロイパイプラインへと応用することも可能です。
また、アラートとイベントの利用は内部の情報に限定されるものではありません。Splunkの他のオブザーバビリティ製品によるアラートとイベントのレポートを利用すれば、たとえば以下のような埋もれていたコンテキスト情報をさらに活用できるようになります。
内部だけでなく外部にも目を向け、SaaS、ベンダー設定、外部プロセスへの何らかの変更が自身のソフトウェアに及ぼす影響を把握できるようにしましょう。
コンテキスト情報の収集に興味を持っていただけたでしょうか。単一の画面でより多くの監視情報を取得し、組織全体でDevOps (またはDevSecOps) Magic™を最大限に引き出しましょう。Splunkのオブザーバビリティソリューションをぜひお試しください。
Splunk Observability Cloud製品スイートの無料トライアルをぜひお試しください。
このブログ記事はSplunkのオブザーバビリティフィールドソリューションエンジニアであるJeremy Hicksが執筆しました。ご協力いただいた以下の同僚に感謝申し上げます(敬称略):Doug Erkkila、Adam Schalock、Todd DeCapua、Joel Schoenberg

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
