
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.
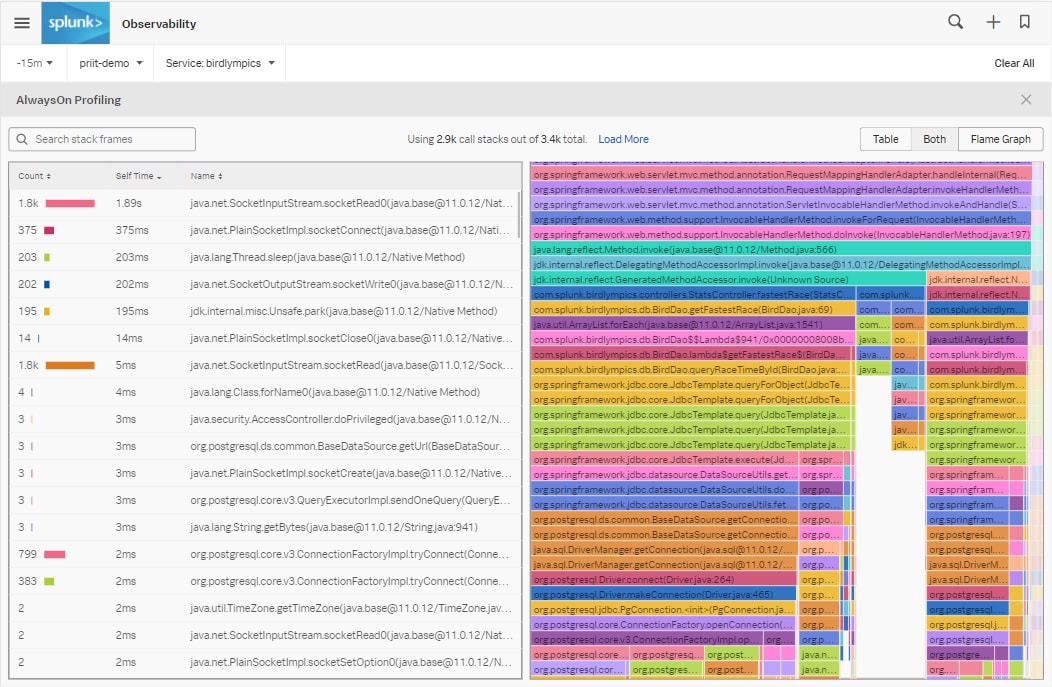
Pour les développeurs d’applications et les responsables de services qui créent et dépannent des logiciels d’entreprise modernes, la résolution des problèmes en production nécessite l’identification des mauvaises performances sur de multiples réseaux, systèmes d’exploitation, serveurs, configurations et dépendances externes. Lorsque le problème se trouve dans le code lui-même, le profilage du code permet d’identifier les goulots d’étranglement du service en capturant à intervalles réguliers des instantanés du processeur, ou piles d’exécution, à partir d’un environnement d’exécution. Les informations des piles d’exécution apportent un complément de contexte aux unités logiques lentes issues des traces de transaction et aident à visualiser les goulots d’étranglement sous la forme de flamegraphs qui représentent les performances du service au fil du temps. Ces avantages parlent d’eux-mêmes, mais la plupart des autres produits de profilage de code entraînent une surcharge de performances notable qui oblige les ingénieurs à les activer ou désactiver manuellement, et les contraint donc à faire un compromis entre les performances de l’application et la disponibilité des données.
Aujourd’hui, nous sommes fiers d’annoncer la version bêta d’AlwaysOn Profiling, qui fait partie de Splunk APM. Disponible initialement pour les applications Java, AlwaysOn offre une visibilité continue des performances à l’échelle du code et les relie à des données de trace sans échantillonnage avec une surcharge minimale. Combiné à Splunk Synthetic Monitoring, Splunk RUM, Infrastructure Monitoring, Log Observer et Splunk On-Call, AlwaysOn Profiling offre aux ingénieurs davantage de contexte pour identifier les problèmes de performance et les résoudre plus rapidement dans les environnements de production.
AlwaysOn Profiling de Splunk APM supervise en permanence les performances du code pour vous donner un contexte immédiat sur les goulots d’étranglement. Voici deux exemples de la façon dont AlwaysOn peut aider à identifier les problèmes de production :
Flux de travail 1 : affichage du code commun dans vos traces les plus lentes
Les ingénieurs qui tentent de résoudre les problèmes en production trient souvent des exemples de traces à la recherche d’attributs communs aux unités logiques les plus lentes. Les piles d’exécution d’AlwaysOn sont reliées aux données de trace pour préciser le contexte dans lequel le code est exécuté lors de chaque trace.
Dans APM, vous pouvez facilement visualiser la latence dans votre environnement de production.
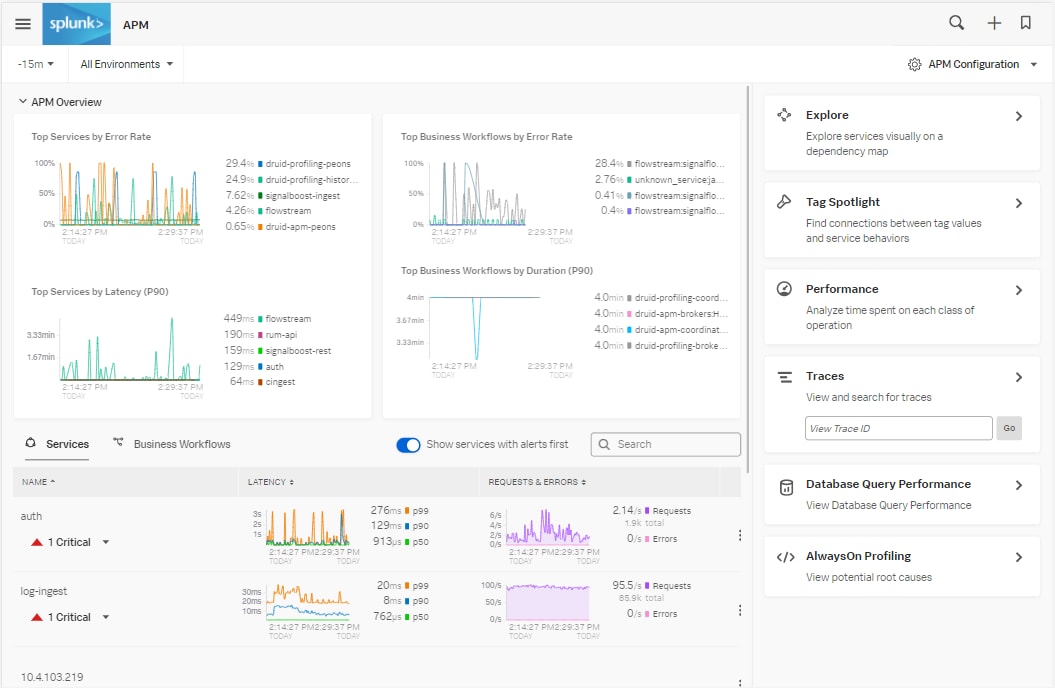
En cliquant sur un service, vous accédez à des cartes qui fournissent un contexte supplémentaire sur les goulots d’étranglement au sein de ce service et de ses dépendances.
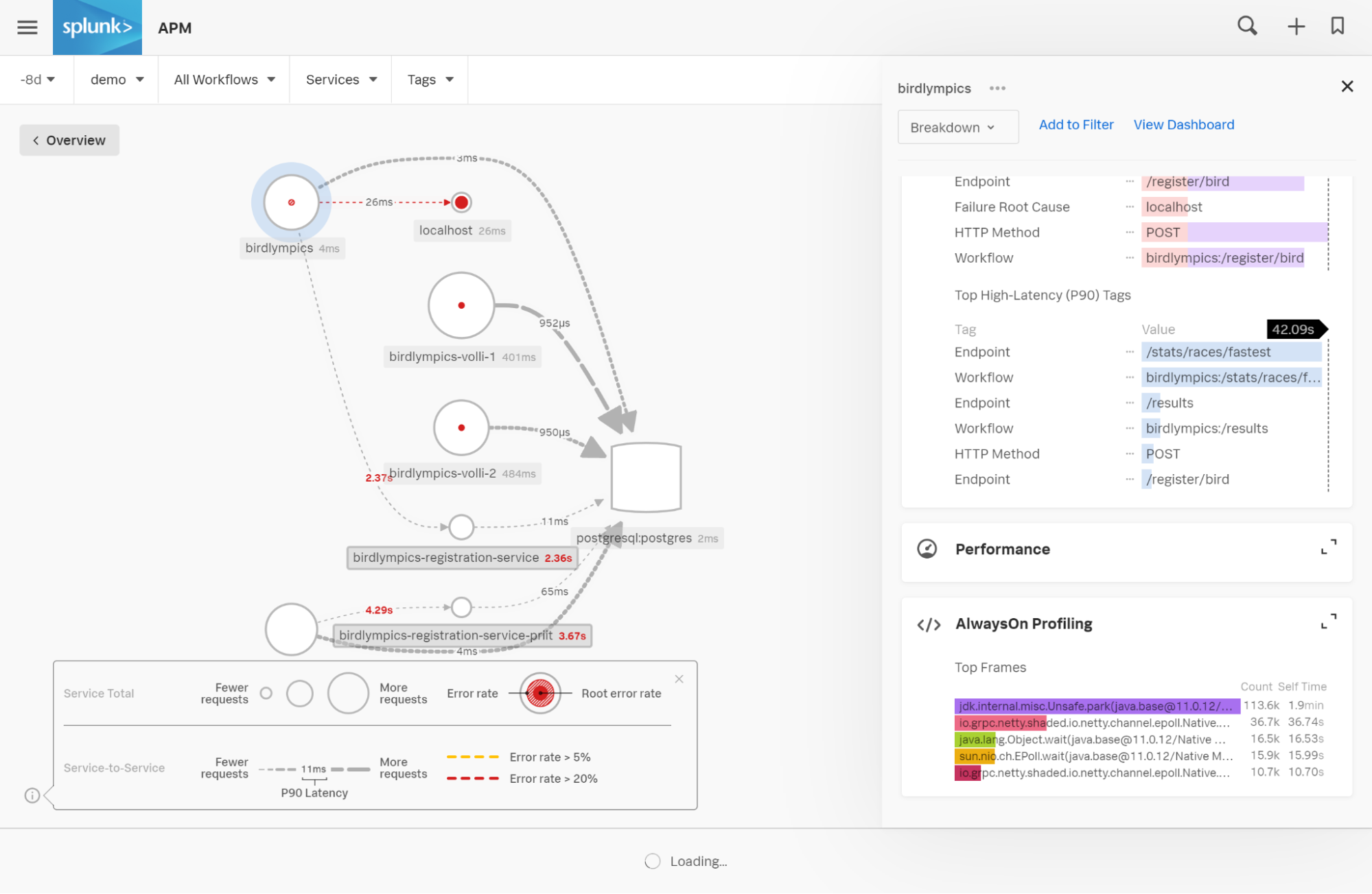
À partir de là, nous pouvons analyser des exemples de traces.
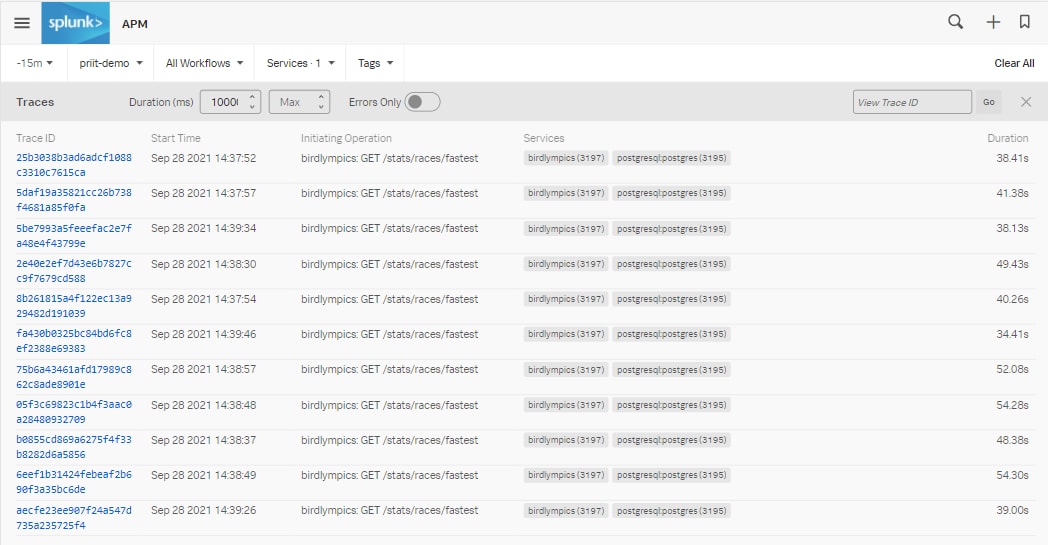
Remarque : nous avons appliqué le filtre 10 000 à « min », soit 10 secondes, pour nous concentrer spécifiquement sur les traces les plus lentes. Nous voyons que les requêtes adressées à /stats/races/fastest répondent à plusieurs reprises en 40 secondes environ.
Si nous cliquons sur l’une de ces traces longues, l’écran suivant s’ouvre :
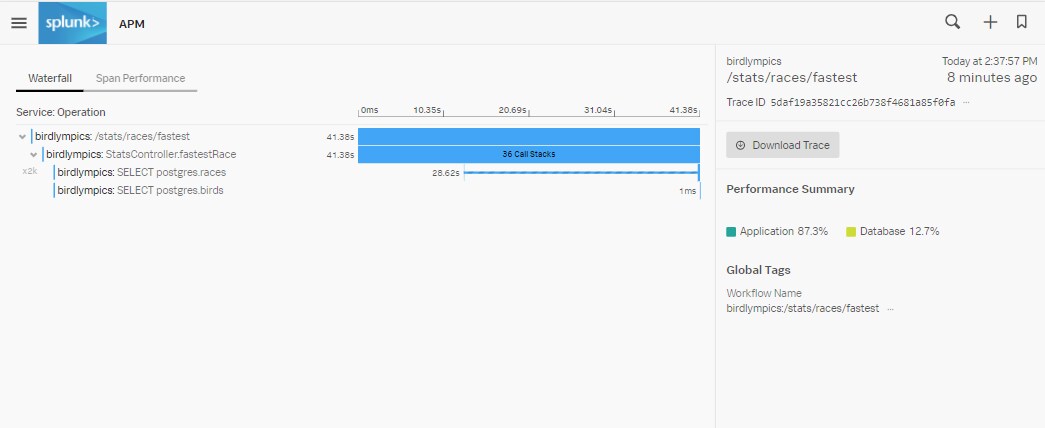
Nous voyons que pendant l’exécution de l’opération StatsController.fastestRace, nous avons collecté 36 piles d’exécution. Comme l’agent Java collecte les piles d’exécution en continu, plus les unités logiques sont longues, plus elles contiendront de piles d’exécution. Lorsque j’ouvre cette unité logique, je vois les métadonnées sur la gauche et les piles d’exécution que l’agent a collectées sur la droite. Les boutons « Précédent » et « Suivant » nous permettent de parcourir toutes les piles d’exécution :
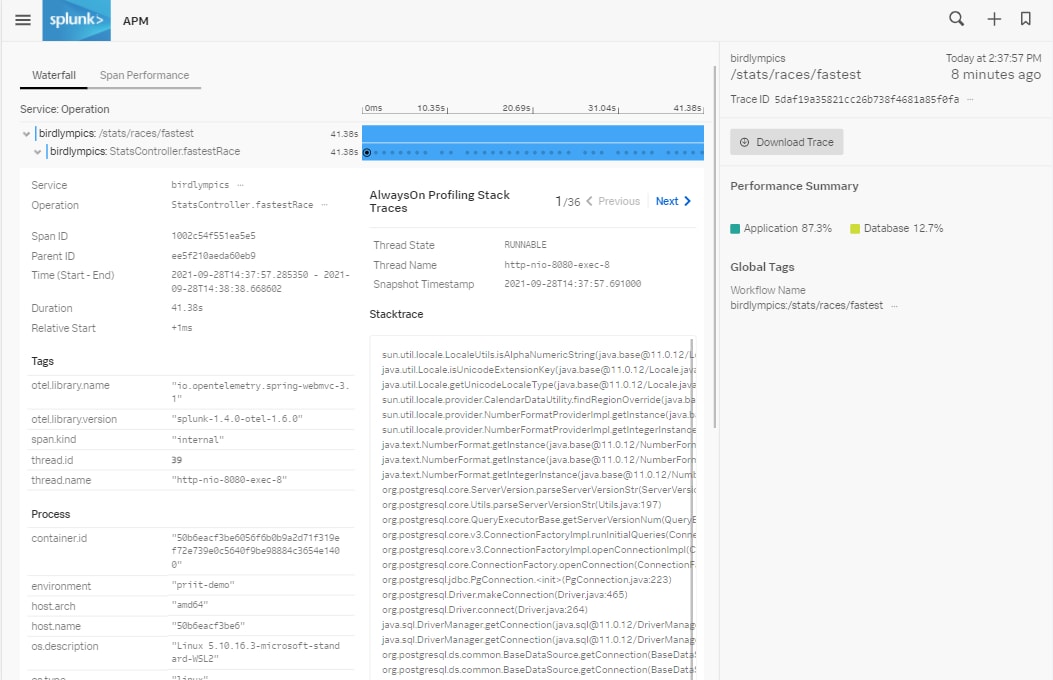
Si vous voyez plusieurs piles d’exécution consécutives pointant vers la même ligne de code, cela signifie que ces lignes mettent beaucoup de temps à s’exécuter, ou s’exécutent plusieurs fois de suite. C’est souvent le signe révélateur d’un goulot d’étranglement.
Flux de travail 2 : affichage des performances agrégées des services au fil du temps
Avant de commencer à optimiser le code, il est toujours utile de comprendre quelle partie de votre code source a le plus d’impact sur les performances. Comment savoir quelle partie freine le plus les performances ? L’agrégation des piles d’exécution collectées, sous la forme de flamegraphs, s’avère très précieuse à cet égard.
Lorsque vous affichez votre carte des services, remarquez l’ajout de profilage de code dans le volet de droite : il vous montre automatiquement les cinq premières captures des piles d’exécution que nous avons collectées pour la période sélectionnée, et qui signalent déjà des goulots d’étranglement dans le code.
En cliquant sur la fonctionnalité, vous êtes redirigé vers un flamegraph, qui est une agrégation visuelle des piles d’exécution collectées sur la période que vous avez spécifiée. Les flamegraphs représentent les piles d’exécution sur une période : plus la barre horizontale est grande, plus cette ligne de code apparaît souvent dans les piles d’exécution collectées.
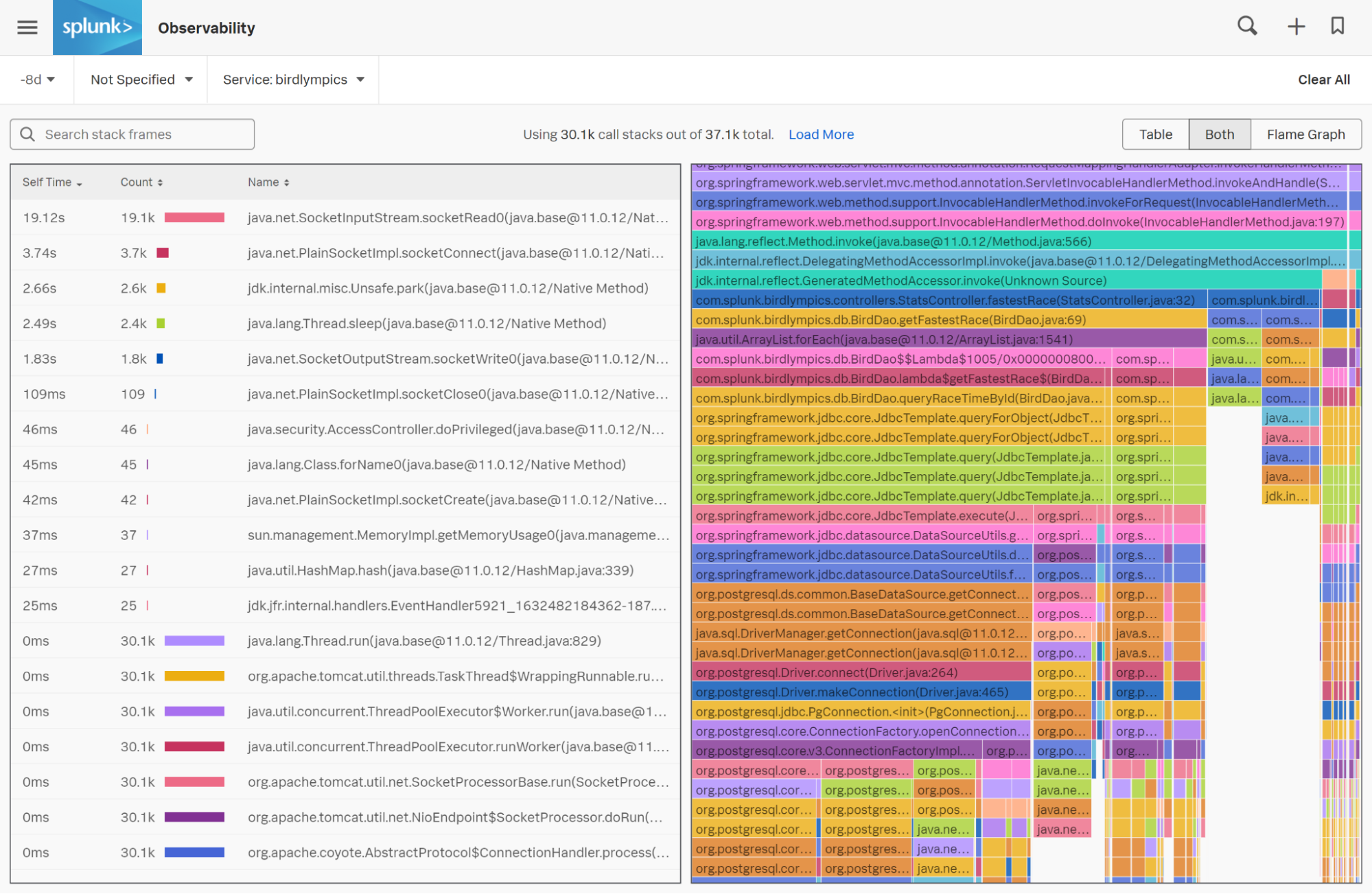
Lorsque vous regardez le flamegraph, concentrez-vous sur les plus grandes « colonnes » descendantes, qui indiquent les lignes de code utilisant le plus le processeur. Si vous souhaitez mettre en évidence vos propres classes de code dans le flamegraph, utilisez le filtre en haut à gauche.
Dans chaque barre horizontale du flamegraph figurent des noms de classe et des numéros de ligne de votre code. Les flamegraphs vous indiquent le goulot d’étranglement à l’origine du ralentissement, et la dernière étape du dépannage consiste à revenir à votre code source lui-même pour résoudre le problème.
Contrairement aux solutions de profilage de code dédiées, AlwaysOn Profiler de Splunk relie les piles d’exécution collectées aux unités logiques en cours d’exécution au moment de la collecte de la pile. Cela permet de séparer les données sur les threads d’arrière-plan des threads actifs qui traitent les requêtes entrantes, ce qui réduit considérablement le temps nécessaire pour analyser les données de profilage.
De plus, avec AlwaysOn Profiling de Splunk, la collecte des données est entièrement automatique et n’augmente que faiblement la charge. Au lieu d’avoir à activer le profileur pendant les incidents de production, les utilisateurs n’ont qu’à déployer l’agent OpenTelemetry de Splunk pour qu’il collecte les données en continu en arrière-plan.
Avec le profilage « Always On », les équipes qui utilisent Splunk APM peuvent désormais analyser et améliorer aussi bien les performances intra-service des grands monolithes de code que les performances interservices des architectures en microservices, pour corriger les goulots d’étranglement et optimiser les performances des services à n’importe quelle étape de la migration vers le cloud.
Inscrivez-vous pour recevoir la version anticipée et commencer dès aujourd’hui.
Suivez toute l’actualité de #splunkconf21 !!
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.
----------------------------------------------------
Thanks!
Splunk

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.