
データ管理の新たなルール
データ管理の新たなルールを取り入れて、データの複雑さを軽減し、サイバーセキュリティとオブザーバビリティを向上させる方法をご紹介します。

Splunk App for Data Science and Deep Learning (DSDL)に2つの新しいアシスタント機能が追加されました。DSDLはこれまでspaCyライブラリを使った初歩的な自然言語処理(NLP)を提供してきました。新しい機能では、深層ニューラルネットワークを活用したTransformersライブラリを使うことで、テキストの分類および要約をこれまでとは全く違う内容と精度で実現することができます。また、DSDLアシスタントは、全てのユーザーに対してPythonコードや複雑なSPLを記述することなくディープラーニングモデルを開発できるインターフェースを提供します。新しいDSDLアシスタントを使って、ビジネス課題解決のために最先端のNLP処理をご活用ください。
従来の機械学習の手法では、TFIDF、PCA、ランダムフォレスト分類などを使用してテキストを分類します。新しいAssistant for Deep Learning Text Classificationは、Transformers BERTモデルを使用して、これまでにないテキスト分類を実現します。それにより、従来の機械学習テキスト分類に勝るビジネスの課題を解決する上で役に立つ5つの利点を提供します。約150の英単語からなるテキスト データをカテゴリに分類するDLアプローチの結果を比較しながらそれぞれを紹介します。トレーニングは7,352のテキストを使って10エポックで、テストは別のテキスト100件を使って行いました。
| Accuracy | Precision | Recall | F1 |
|---|---|---|---|
| 0.29 | 0.23 | 0.26 | 0.23 |
| Accuracy | Precision | Recall | F1 |
|---|---|---|---|
| 0.72 | 0.66 | 0.57 | 0.60 |
精度はディープラーニングによるテキスト分類の最初の利点です。学習を繰り返すことでより精度を高めることができます。しかも、この精度を実現するためにテキスト中のどの値が分類を行う上で特徴量として役に立つのかを検討する必要がありません。必要なことはアシスタントのインタフェースをを使ってテキストとその分類を指定するだけです。
アシスタントはファインチューニング用のSPLを生成し、バックグラウンドで実行します。ディープラーニングと従来の機械学習の大きな違いは、ディープラーニングではモデルの学習にとても長い時間を要するという点です。アシスタントはファインチューニングにどの程度時間がかかるかを見積もるので、ファインチューニングが終わるまで画面の前で待っている必要もありません。
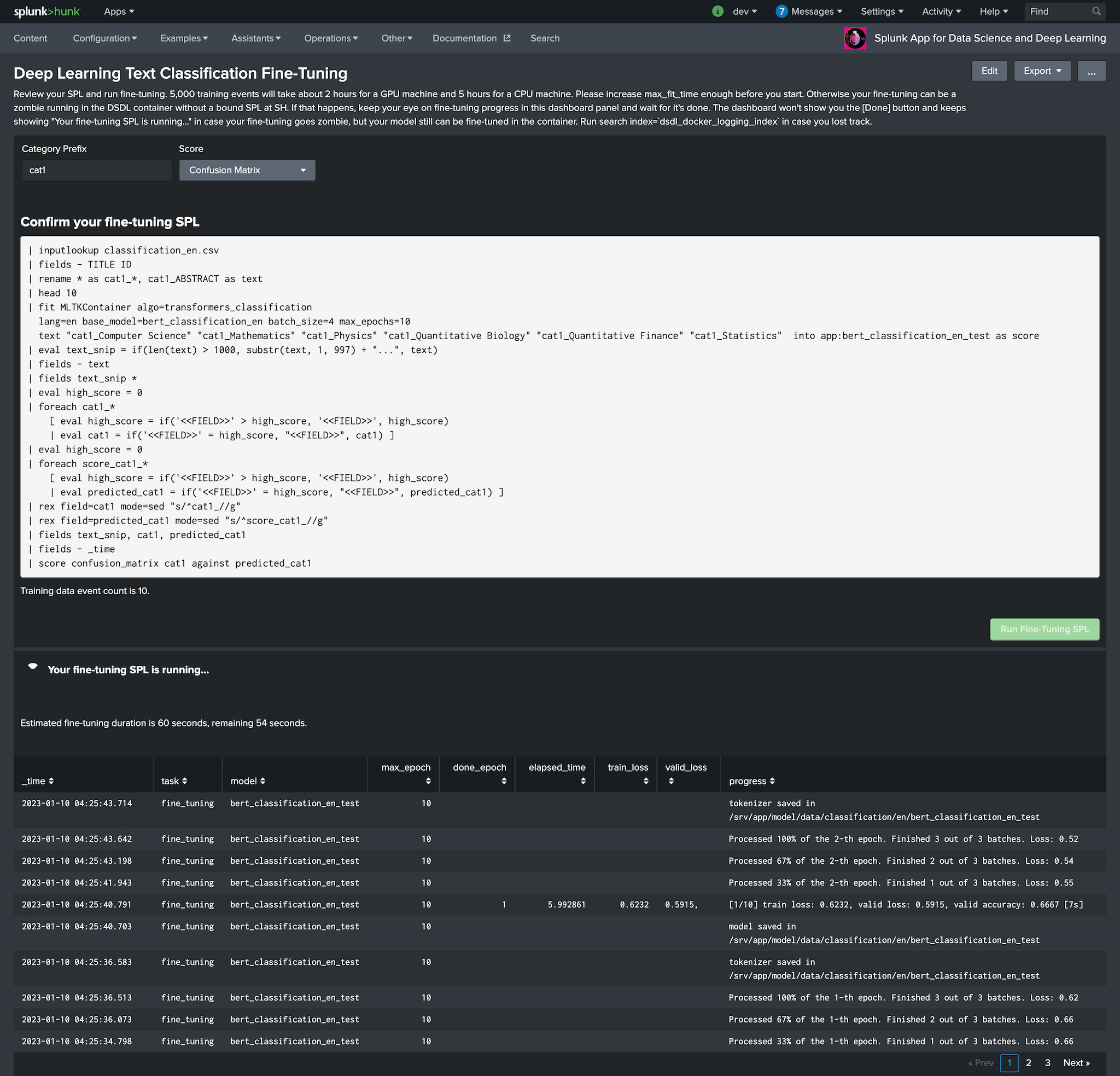
ディープラーニングモデルのフィッティングには時間がかかります。しかし、テキスト分類の特性から、それほど頻繁にファインチューニングを行う必要はおそらくないでしょう。ビジネス要件によっては週もしくは月に一度で十分です。そして、二番目の利点を知ることでフィッティングに時間がかかる点にも納得するでしょう。それは、予測がどの程度ポジティブになるかをprobabilityフィールドから知ることができるという点です。
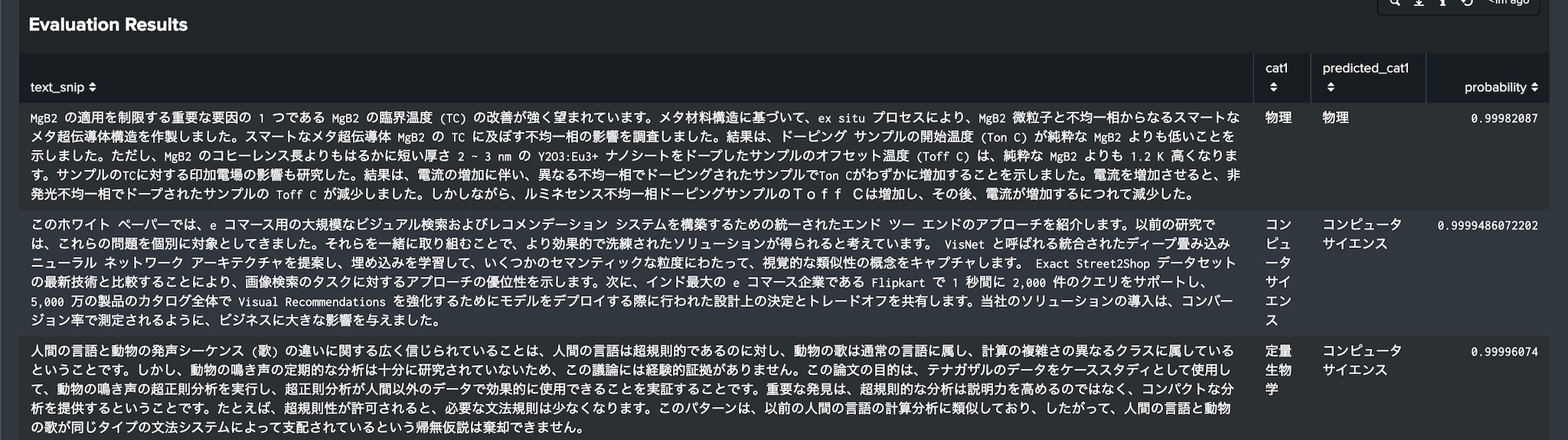
フォールスポジティブは多くの機械学習において重大な問題です。ディープラーニングによるテキスト分類は高精度に加えてフォールスポジティブを軽減する仕組みも提供します。probabilityの値が低い予測を結果から除外することでフォールスポジティブを減らすことができます。以下はprobabilityが90%以下の予測を除外することでどれだけスコアが改善するかを示した例です。
| Accuracy | Precision | Recall | F1 |
|---|---|---|---|
| 0.77 | 0.71 | 0.58 | 0.61 |
probabilityが低い予測については人の目で確認する必要があるでしょう。ディープラーニングによるテキスト分類の三番目の利点はこの過程で役に立ちます。probabilityが低い予測は通常2つ以上のクラスにおいて高い予測スコアになっています。アシスタントが生成したSPLを調整すれば、スコアの高いクラスを簡単に比較してモデルが予測に失敗した理由を確認できます。

上の例はコンピュータサイエンスと統計学の分類においてスコアが極めて近いものを示しています。高いスコアになっているクラスを比べることで、予測のprobabilityが低かったのかを理解することができます。人間の目で見てもどちらが正解なのか判断が難しいものもあります。これらのデータを使ってモデルを強化することができます。
同じデータまたは新しいデータを使用してモデルを再トレーニングできます。それは人間が言語を学ぶ方法に似ています。最新のトレーニング データ セットが予測に最も影響を与え、古いデータは忘れられていきますが、トレーニング結果はモデルが既に学習したデータに蓄積されます。モデルが予測に失敗したデータセットを使用することでモデルを効果的に強化できます。
スクリーンショットのSPLがちょっとややこしそうなことに気づいたかもしれません。その通りなのですが心配はいりません。それほど難しいものではありません。ディープラーニングによるテキスト分類では、テキストのクラスを示すために0または1を保持するクラスフィールドが必要です。したがって、以下に示す2つの異なる形式間でデータを変換しなければなりません。
| テキスト | クラス |
|---|---|
| 各チーム11名でプレイしてボールを蹴ります。 | サッカー |
| 各チーム9名でプレイしてボールをバットで打ちます。 | 野球 |
| テキスト | サッカー | 野球 |
|---|---|---|
| 各チーム11名でプレイしてボールを蹴ります。 | 1 | 0 |
| 各チーム9名でプレイしてボールをバットで打ちます。 | 0 | 1 |
アシスタントはパターンBからパターンAへの変換を行うSPLを生成します。
| eval high_score = 0
| foreach cat1_*
[ eval high_score = if('<<FIELD>>' > high_score, '<<FIELD>>', high_score)
| eval cat1 = if('<<FIELD>>' = high_score, "<<FIELD>>", cat1) ]
このSPLに適合するには、ファインチューニングまたは評価の前に、すべてのクラスフィールドの名前をプレフィックス「cat1_」で始まるように名前を変更します。
パターンAからパターンBへの変換はもっと簡単なSPLでできます。
| eval {category} = 1
| fillnull value=0
これにより、MLアプローチを使用して達成するのが難しいテキスト分類にさらに別の機能がもたらされることに気付かれたかと思います。これにより以下のようなマルチラベル分類を取り扱うことが可能になります。
| テキスト | サッカー | 野球 |
|---|---|---|
| ボールを使ったチームスポーツ。 | 1 | 1 |
評価は以下のスコアで行います。
すべてのスコアは0から1の範囲をとります。0が最低で、1が最高です。データセット内で分類のバランスが取れている場合は、精度を使用してモデルを評価できます。データセット内の分類が不均衡な場合は、F1を使用してモデルを評価します。
テキストの要約は、DSDLアシスタントのもう1つの新機能です。Transformers T5モデルを使用し、トレーニングデータの形式に従ってテキストから要約を抽出することができます。
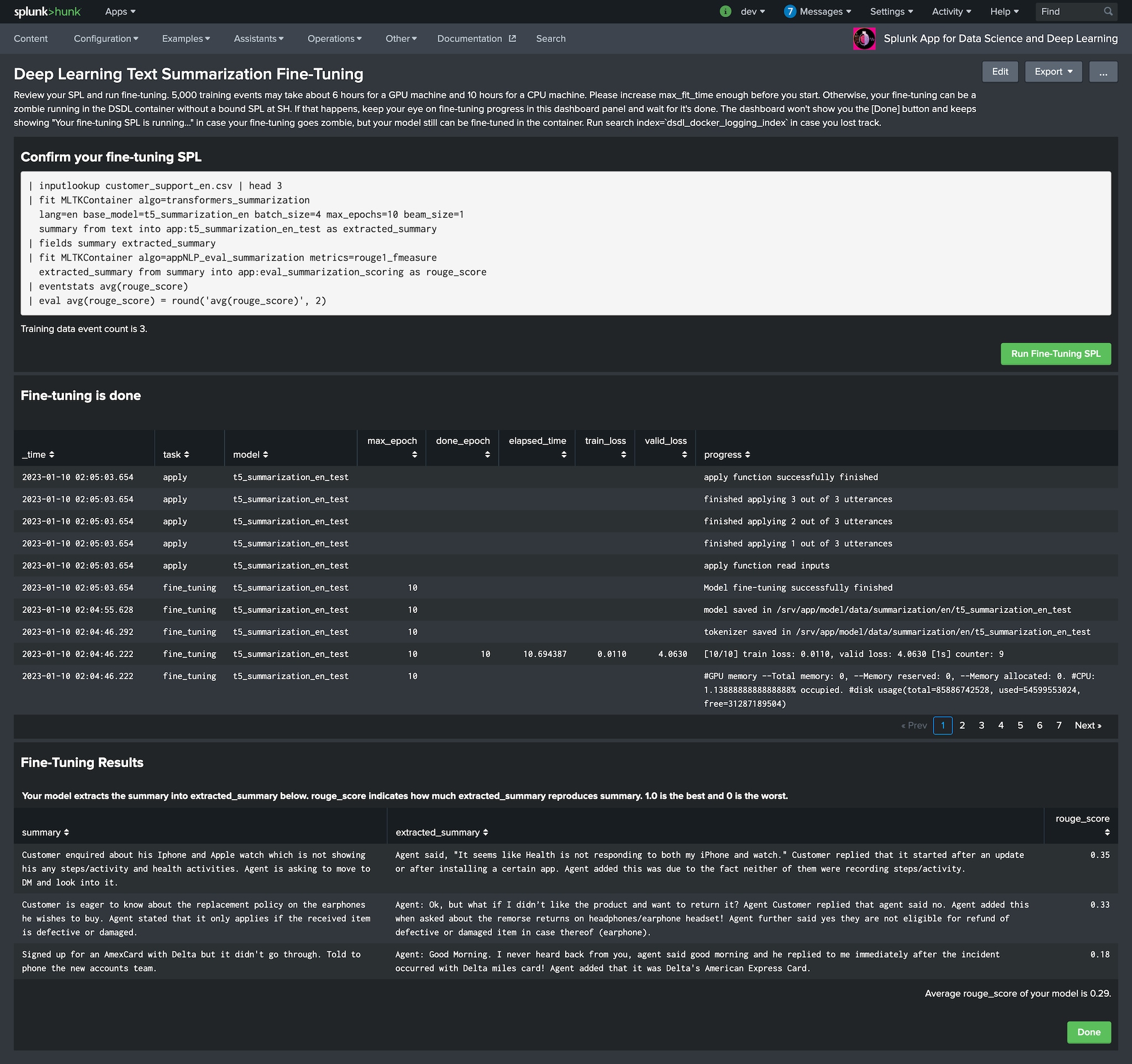
以下、テキストから顧客が何を欲しがっているのかを要約する例を紹介します。
| テキスト | 要約 |
|---|---|
| テレビがほしいです。 | お客様のニーズはテレビです。 |
| ラジオを持っていてラジオが好きですが、今はテレビがほしいです。 | お客様のニーズはテレビです。 |
| かわいい犬をテレビで観ました。犬がいたらなぁ。 | お客様のニーズは犬です。 |
十分な量の「お客様のニーズは <...> です。」という要約トレーニング データを使用して、適切にモデルがトレーニングされている場合、人間がテキストを理解するように、モデルはテキストから顧客が望んでいるものを抽出します。分類には事前定義されたクラスが必要ですが、要約はその必要がありません。従来の機械学習では対応できなかった、テキスト データから値を抽出する際にクラスを事前に定義できないユースケースに対してソリューションを提供することができます。
どれだけ人間が作成した要約を再現できているかを示すRougeスコアを使って評価を行います。0が最低で、1が最高です。
ディープラーニングによるテキストの分類と要約は幅広いユースケースに対応できますが、当初この機能セットはトランスクリプトデータから3つの基本的な値を抽出するというコール センター要件のために設計されました。
これらをデータから抽出できればコールセンターにとって大きな価値があります。実際にお客様のデータでテストする機会がありましたが、その精度は非常に高く、そのお客様はディープラーニングを使ってナレッジベースを構築することを検討されています。
音声テキスト化ソリューションの導入価格は現在でも決して安くはありませんが、SplunkにDeep Learning NLPを導入するコスト自体は比較的安価です。コールセンターのコミュニケーション手段は電話からテキストベースのデバイスに移行しています。このソリューションは、コールセンターのユーザーにとってより受け入れやすくなっていくでしょう。
しかし、コールセンターは数あるユースケースのうちの一つに過ぎません。テキストから値を抽出したいユースケースであれば、どのようなものにもディープラーニング NLPを適用できます。
例えば、ITチケッティングシステムでは、ディープラーニングを使ったテキスト分類によって、チケットを最適なチームや担当者に転送したり、カテゴリを追加してより良いあるいは自動的なチケットルーティングを行ったりすることができます。より高度な使用例では、チケットの重症度を予測し最初に見るべき障害の被疑箇所を特定してチケットに対する初動を高度化することができます。そして、レトロスペクションにおいては要約を使ってソリューションノートを自動生成することができます。
セキュリティの分野では、フィッシングメール検知に適用するのが最も分かりやすいアイデアでしょう。この分野ではすでにトラディショナルな機械学習ベースのソリューションが存在しますが、もしその結果に満足できないのであれば、ディープラーニングベースのソリューションを試してみるのもよいでしょう。

DSDLアシスタントを使う必要はありません。Transformersコンテナ内のJupyter Lab内の以下の2つのノートブックを参照して、あなたのユースケースにより適合させてください。
Deep Learning NLP Assistant for DSDLはデモデータと一緒に実装されています。データを適用する前にでもデータを使ってどのように動作するかを確認することができます。お客様のビジネスにどのように役立つのかを知りたい。DL NLPソリューションにご興味のある方は、DSDL 5.1をダウンロードの上、ユースケースをお知らせください。

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
