
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

Bienvenue dans la nouvelle série de Splunk : DATA Talks. Des experts de la donnée décryptent pour nous les nouvelles tendances autour de la data et du Big Data. Dans ce premier épisode, nous recevons un des spécialistes en France de la donnée, de l’IA, ou encore du sujet des fake news : Victor Baissait. Cette fois, il nous plonge dans les possibilités infinies de la dataviz (aussi appelée Data Visualization, Data Visualisation ou encore visualisation de données).

Pour faire simple, la dataviz, c’est la représentation visuelle de données pour en simplifier ou en améliorer la compréhension.
Lors de mes conférences sur la data, j’aime donner un exemple pour se mettre tout de suite dans le bain et comprendre facilement comment fonctionnne la Dataviz.
Le principe est simple : imaginez un petit tas de briques de lego, avec plein de couleurs et de formes différentes. Si on demande à quelqu’un « tu as trois secondes pour trouver la couleur dominante », il n’a pas le temps de fouiller et il ne pourra pas répondre. C’est impossible, sauf si évidemment il y a une couleur qui domine à plus de 80 %. Mais si on prend ces mêmes briques, qu’on les arrange par couleurs et qu’on lui demande de trouver la couleur dominante, la réponse s’impose à lui.
Ce qui est intéressant, c’est que dans les deux cas, on a exactement les mêmes données, exactement la même chose. Tout ce qu’on a fait, c’est les réarranger d’une certaine manière, pour qu’il puisse avoir accès plus facilement à la réponse, et qu’il ne perde pas de temps. Si on lui avait demandé de le faire en lui laissant un temps indéfini, il aurait peut-être pris 10 minutes à assembler les briques, alors que là, en trois secondes, il est capable de définir quelle est la couleur dominante.
Ce qui est également intéressant, c’est qu’on a choisi ici la couleur. On aurait pu choisir la taille de brique, parce qu’il y a des briques qui font 2 sur 2, d’autres 1 sur 3. Et pourquoi a-t-on choisi cet élément pour notre dataviz ? Parce que la couleur, c’est ce qui se voit le plus, ce qui est beaucoup plus percutant. Tout ça pour dire qu’il n’y a pas UN bon choix, mais qu’il y en a plusieurs, qui s’adaptent selon le contexte.
Oui. La première question que l’on doit se poser est vraiment toute bête. Comme dans n’importe quel projet, on doit se demander « qu’est-ce que l’on veut faire réellement ? », « Pourquoi on veut utiliser la dataviz », « Quel est le but de la dataviz ? », c’est-à-dire « Est-ce que je veux toucher plutôt le client, ou expliquer plus facilement quelque chose qui est complexe ? ». « Je suis dans un domaine qui a un peu d’avenir, mais c’est un peu compliqué à comprendre pour des clients, donc je vais faire un parcours interactif qui va leur permettre de comprendre les enjeux et la raison pour laquelle ils vont devoir choisir MA solution, qui leur fera économiser du temps ou de l’ argent par exemple. » Ils vont comprendre très simplement et c’est ce qu’il va leur permettre de se dire « Ah, la solution que je veux, c’est ça. » Ils auront vraiment la sensation d’avoir été emmenés par la main, sans être forcés, à travers un parcours qui permet de les accompagner sur ce thème, de les faire aller d’un point A à un point B, tout en les captivant.
Ce qui est important, c’est également de bien choisir la charte graphique, comme dans n’importe quel projet qui englobe du design, du graphisme ou du webdesign. Il faut choisir une charte, qui peut être adaptée à la charte déjà existante d’une entreprise ou d’une association s’il en existe une. Et il faut vérifier, comme sur n’importe quel projet web (puisque c’est généralement des choses qui vont être sur le web, même si ça peut être en print) le contraste des couleurs, l’accessibilité et que ça marche bien. Car on va parfois utiliser certains codes qui vont très bien fonctionner sur un navigateur, mais pas sur un autre. Il faut toujours vérifier à chaque étape que tout se passe bien.
Oui, c’est souvent le grand classique avec les choses qui deviennent à la mode, même si être à la mode n’est pas un mal en soi. Par exemple, il y a quelques années, tout le monde voulait faire des chatbots, sans comprendre ce que c’était et sans en comprendre l’intérêt. Certaines start-ups ajoutaient juste un chatbot pour faire plaisir aux gens. Mais cela n’avait aucune valeur ajoutée et ils perdaient leur temps. Là c’est la même dynamique : il y a des gens qui vont vouloir faire de la dataviz juste parce que « c’est cool ». Si la première réflexion est « je veux faire de la dataviz », on se trompe, c’est « j’ai un besoin, et la ou l’une des solutions à ce besoin, c’est la dataviz. Elle va me permettre d’arriver à mon objectif comme faire augmenter les ventes ou mieux faire comprendre un enjeu écologique par exemple.»
C’est souvent la question qu’on me pose au cours de conférences. Quand les gens ont bien compris les enjeux de la dataviz (faire quelque chose d’assez simple, immersif et qui permet d’être concret), la question est alors « où trouve-t-on ces données ? »
Il y a plusieurs moyens. Cela dépend de ce qu’on représente – est-ce que ce sont des données internes ou est-ce que ce sont des données publiques ?
Je vais prendre un exemple récent : les Jeux olympiques. Si l’on devait faire une dataviz sur les Jeux olympiques en général, les données seront trouvables en ligne, on ne va pas s’amuser à aller sur Wikipedia pour tout retaper. Comme on sait que c’est un événement suivi par des milliards de gens, il y a forcément déjà quelqu’un qui a déjà pris ces données un jour et qui les a datavizifiées (j’utilise ce terme qui est un affreux barbarisme, j’expliquerai après comment) qui les a déjà préparées pour être mis dans une dataviz.
Ces fichiers-là – qui sont généralement des CSV – peuvent s’ouvrir sous Excel. Ils ressemblent un peu à des tableurs, mais les séparations ne se font pas par colonnes, mais par virgule, qui viendront séparer les différentes données. Cela peut être dans notre cas des Jeux olympiques :
À partir de là, on peut avec du code décider d’afficher uniquement tous les athlètes qui ont eu la médaille d’or en voile ou en boxe. Il ne sert à rien de refaire ces données-là : il suffit d’aller rechercher dans Google ou dans n’importe quel moteur de recherche « CSV + le nom de ce que l’on recherche » en français ou en anglais, si on pense avoir plus de résultats dans cette langue.
J’ai revérifié ce processus ce matin et on trouve tout de suite nos informations, on trouve un effet un fichier CSV qui est déjà tout prêt, ce qui évite de devoir tout retaper et est extrêmement utile.
On peut également miser sur l’Open Data, c’est-à-dire quand les États ou entreprises privées mettent à disposition des données, par exemple des informations sur le transport. Certaines régies de transport offrent aux gens des données de manière gratuite et, plus rarement, de manière payante (les gens ont tendance à être mécontents quand on leur fait payer l’accès à des données ouvertes). Ce qui nous permet d’avoir accès à des données en temps réel, qui nous indiquent par exemple où se trouve tel bus ou tel métro. Ces données pourront ensuite être intégrées à des applications de tourisme par exemple.
Ces datas sont accessibles, pour les chercher, il faut se demander qui est la personne, le groupe qui pourraient les proposer ou si elles sont disponibles sur le site de l’état (sur opendata.gouv) qui vont nous permettre d’aller récupérer ces données.
Mais que se passe-t-il quand on est face à des données introuvables en ligne ? Soit ce sont des données en interne, soit elles ne sont pas trouvables.
Dans le premier cas, il faut se demander ce qu’on veut faire et de quelles données on a besoin en amont. Car maintenant, avec le RGPD (Règlement Général sur la Protection des Données), on ne peut pas récolter n’importe quelle donnée : il faut préciser exactement aux utilisateurs quelle donnée on veut et quelle donnée on ne veut pas. Ce serait trop bête de se rendre compte 3 mois après le début du projet qu’on a oublié de demander telle donnée et de devoir tout refaire.
Il faut vraiment réfléchir en amont à quelles données on a besoin en fonction de l’objectif. Cette dataviz, on va la publier dans plus d’un an, mais on va récolter des données pendant toute une année pour être capable de dire « nos investisseurs, nos partenaires ou nos clients ont fait telle chose, ce qui permet de montrer que notre entreprise est performante sur ce sujet et que les gens sont extrêmement satisfaits ». Voilà, ça a permis de créer de nouveaux usages.
On peut aussi tricher – et ce n’est absolument pas une mauvaise chose ici. Voilà un exemple que j’aime bien donner : celui d’une dataviz qui représente les odeurs et les bruits dans les rues. On peut se demander comment c’est possible, car ce sont des données qu’il est matériellement impossible de récolter ; même en imaginant l’intervention de robots humanoïdes, il va donc falloir ruser.
Cette technique est utilisée par un site qui présente des dataviz représentant plusieurs villes – Londres, Barcelone, New York, etc. Et quand on voit la carte, on voit déjà que c’est assez fiable : tous les parcs sont en vert, par exemple pour les bruits de nature. Il n’y a pas d’erreur, puisqu’on voit des bruits de bâtiments en plein milieu. Et le zoo de Londres est tout est en orange, ce qui correspond aux odeurs d’animaux, donc on voit que c’est correct.
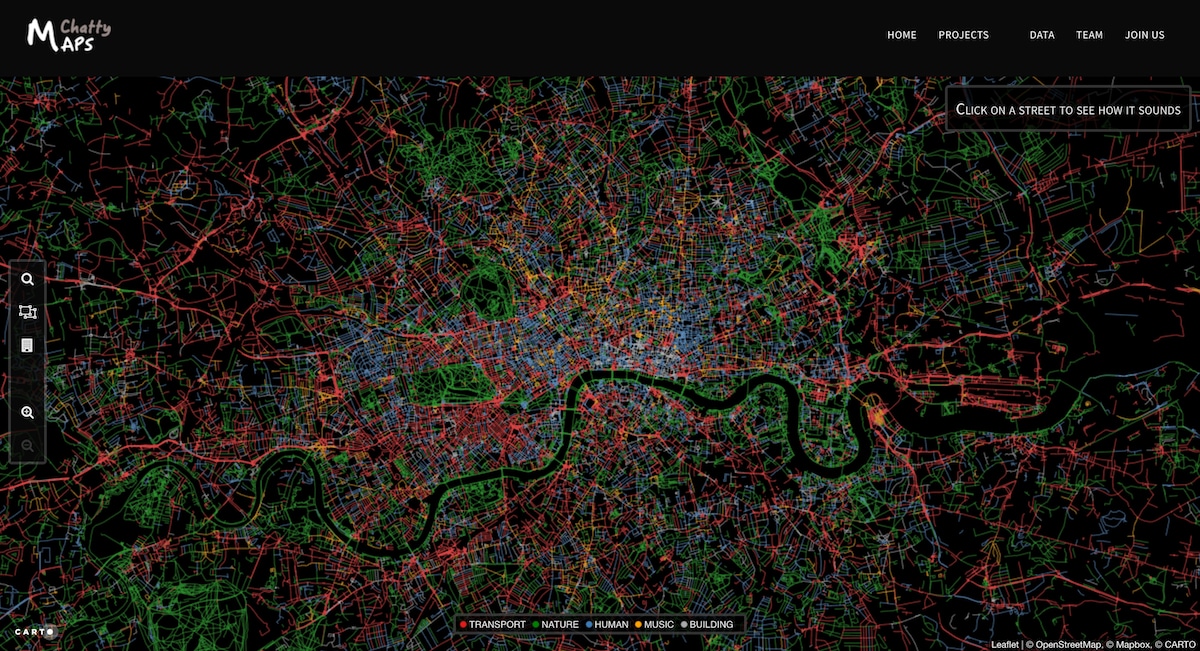
La méthode est un peu ancienne, ils utilisaient Flickr, qui était la plus grosse base de données de photos. Ils regardaient sur chaque photo si elle était géo-localisée et ils découpaient chaque rue en petites sections parce que certaines rues sont longues. Il n’y avait pas Paris sur leur site, mais pour tous ceux qui connaissent la rue Vaugirard, qui est extrêmement longue, ils l’auraient divisée en plein de petits segments. Et pour chaque segment, ils regardent combien ils ont de photos et regardent quels sont les hashtags associés. Ils ont des dictionnaires qui leur disent « ça c’est un mot qui correspond aux animaux », par exemple, et ils font ensuite un calcul en pourcentage qui permet d’avoir quelques taux.
Après ça vaut ce que ça vaut. Aujourd’hui on utiliserait peut-être Instagram, mais ça permet d’aller détourner certaines données pour donner quelque chose qui est certes approximatif, mais qui offre tout de même une bonne vision des choses.
Bien sûr ! Ce qui peut être intéressant pour les entreprises en interne, c’est que ça peut permettre de démontrer la puissance d’un produit. On peut poser des points clés dans le logiciel, pour déterminer par exemple quand une personne clique et combien de fois elle clique sur tel bouton - ce qu’on peut faire dans Google Analytics – et, grâce à ces données, améliorer le site.
Parce qu’on peut penser qu’on a fait quelque chose de bien, mais on va voir que les gens, par habitude, vont cliquer ailleurs et vont avoir un chemin différent de celui qu’on avait prévu. Cela va permettre de retravailler entièrement le site, grâce à ces données, et d’avoir ainsi une conversion beaucoup plus forte.
Ça peut aussi être utilisé pour faire de l’A/B-Testing, c’est-à-dire tester deux pages différentes et déterminer quelle page est la plus performante. On peut essayer de savoir où la personne a cliqué, où elle a regardé, ce qui permet d’avoir des retours bien plus performants qu’en demandant directement à l’utilisateur via un formulaire ce qu’il a pensé du site. Dans ce cas, les questions ne seront pas forcément bien posées et elles vont ennuyer l’utilisateur. Même s’il est annoncé que le questionnaire ne prend que 2 ou 3 minutes à remplir, l’utilisateur va en avoir marre au bout de la première minute. Cette méthode permet ainsi de manière simple de récolter des données : grâce au règlement RGPD, l’utilisateur sait que les données vont être récoltées et on n’aura donc aucun problème de transparence. Cela permet d’améliorer l’expérience utilisateur et aussi d’augmenter les ventes, la visibilité et les conversions.
Je n’ai pas tout de suite d’exemple en tête, mais on peut parfois avoir des surprises : on n’est pas dans la tête de son client. On a beau l’interroger, si on mène une enquête, de manière consciente ou inconsciente, les questions seront biaisées et on peut manipuler les gens sans le vouloir, sans que ce soit malveillant.
L’exemple le plus concret : quand les utilisateurs vont naviguer sur le site, ils n’ont pas l’impression d’être espionnés ou qu’on leur pose des questions et vont réagir de manière naturelle, donc la donnée va être beaucoup plus fiable. L’exemple, c’est le syndrome de Bugs Bunny : on donne un questionnaire à des gens portant sur leur visite à Disneyland. On leur demande ce qu’ils ont vu, ce qu’ils ont aimé, et à la fin, on récupère les questionnaires. L’une des questions est « Quel est votre souvenir avec Bugs Bunny ? » Les gens racontent en détail qu’ils ont vu Bugs Bunny, qu’il a dit « Quoi de neuf Docteur ? », etc. Sauf que c’est impossible, car Bugs Bunny est un personnage de la Warner, qui n’appartient pas à Disney : on est donc capable de raconter des souvenirs qui n’existent pas. Il faut donc faire attention à ça.
C’est un exemple un peu extrême qui montre que même avec la meilleure volonté du monde, on peut biaiser les informations et la donnée.
J’en ai choisi deux.
Le premier dont je vous avais parlé, c’est le principe des briques. C’est la première chose que je montre à mes étudiants lors de conférences et tout de suite ils comprennent la dataviz, je leur dis « Si vous avez compris ça, vous avez tout compris. ». C’est déjà bien d’avoir quelque chose qui résume et permet de tout comprendre. Et après, on explore petit à petit l’univers des dataviz.
Il y a énormément de dataviz qui sont extrêmement pertinentes et assez étonnantes et l’une de celles que je montre à mes étudiants – c’est sans doute avec eux que ça marche le plus, car même si c’est un cliché, ce sont sans doute ceux qui sont le plus à même de regarder énormément de séries. Ce que je leur montrais – et je parle au passé, car le site n’existe plus, même si quelqu’un en a refait un autre - c’est une dataviz sur les séries. Pour faire simple, il y a l’IMDB (Internet Movie DataBase), une des plus grosses bases de données sur les films et les séries, et qui permet de les noter. On peut ainsi noter chaque épisode de série et sur certains épisodes, on a jusqu’à 10 000 personnes qui ont voté. On récupère ces données et on en fait des graphes dans lesquels chaque saison a une couleur différente.
Je montrais à mes étudiants des dataviz représentant les notes d’une série sans leur en donner le nom, je leur demandais de me trouver la série et ils la trouvaient immédiatement, surtout quand je prenais des grands classiques, comme Game of Thrones. À l’époque, la série n’était pas encore finie, je ne l’ai jamais vue, mais les étudiants en parlaient tant à l’époque, qu’en deux secondes, ils savaient qu’il s’agissait de celle-ci.
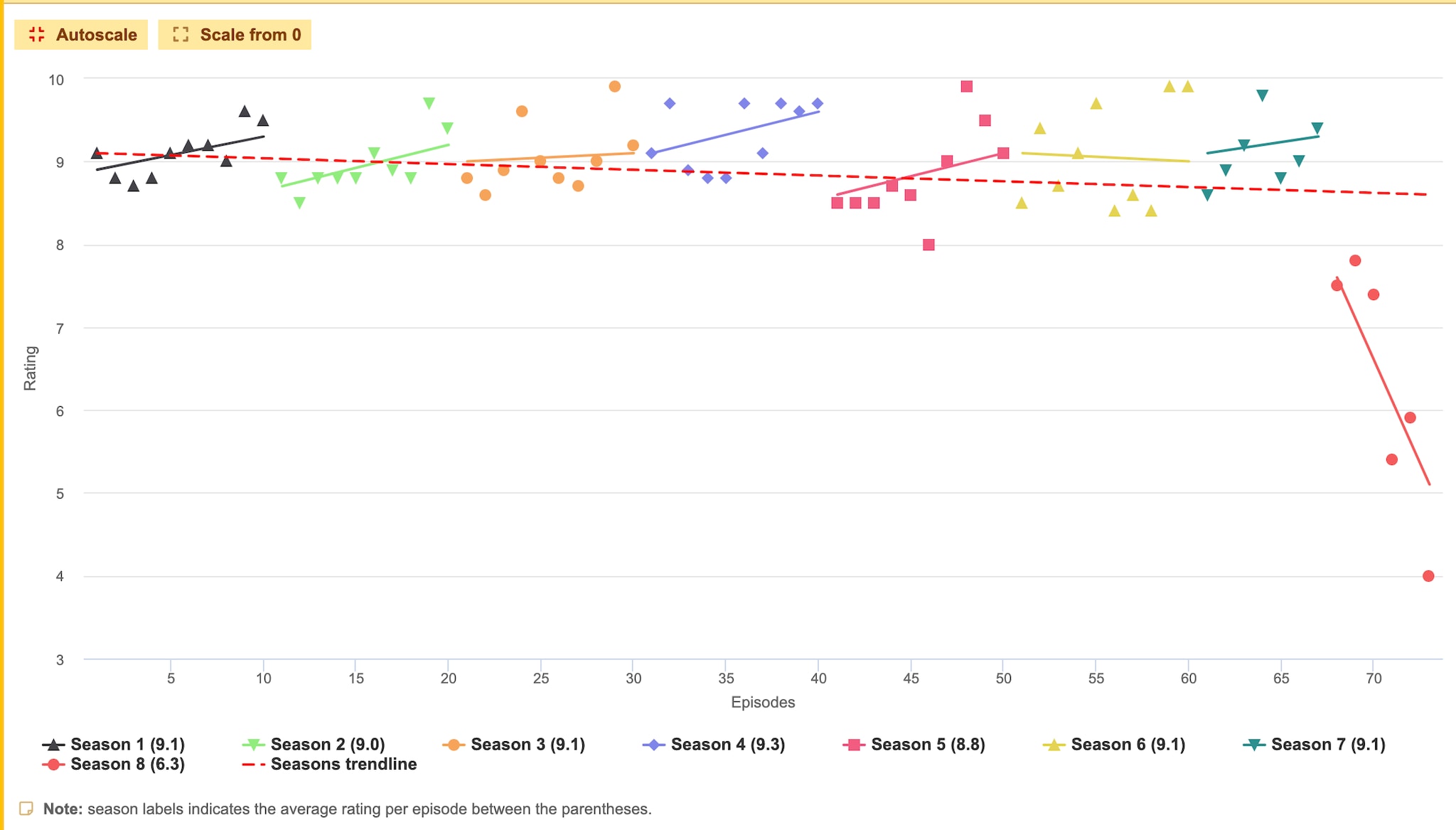
Je leur ai également montré la dataviz d’une série un peu moins connue, mais ça n’a pas empêché quelqu’un de trouver son nom en deux secondes, c’était Mon Oncle Charlie (Two and a Half Men), où l’acteur Charlie Sheen s’est fait virer pour avoir tenu des propos antisémites envers le producteur. Et on voit lors de son licenciement un krach dans la dataviz, les notes remontent ensuite peu à peu avant de s’écrouler à nouveau.
Quand je montre ça aux étudiants, je leur demande « Qu’est-ce qui s’est passé, qu’est-ce que vous comprenez ? », petit à petit, certains qui connaissent la série disent « oui, il s’est passé telle chose » et l’un d’entre eux en voyant la dataviz n’a mis que deux secondes pour trouver que c’était Mon Oncle Charlie. Il a tout de suite compris.
Une force de la dataviz, c’est qu’avec juste quelques traits, les gens arrivent à deviner de quelle série il s’agit. Même si c’est un peu difficile à trouver, parce qu’on sait qu’à un moment il s’est passé quelque chose, on fait des déductions et le cerveau peut très rapidement faire des connexions.
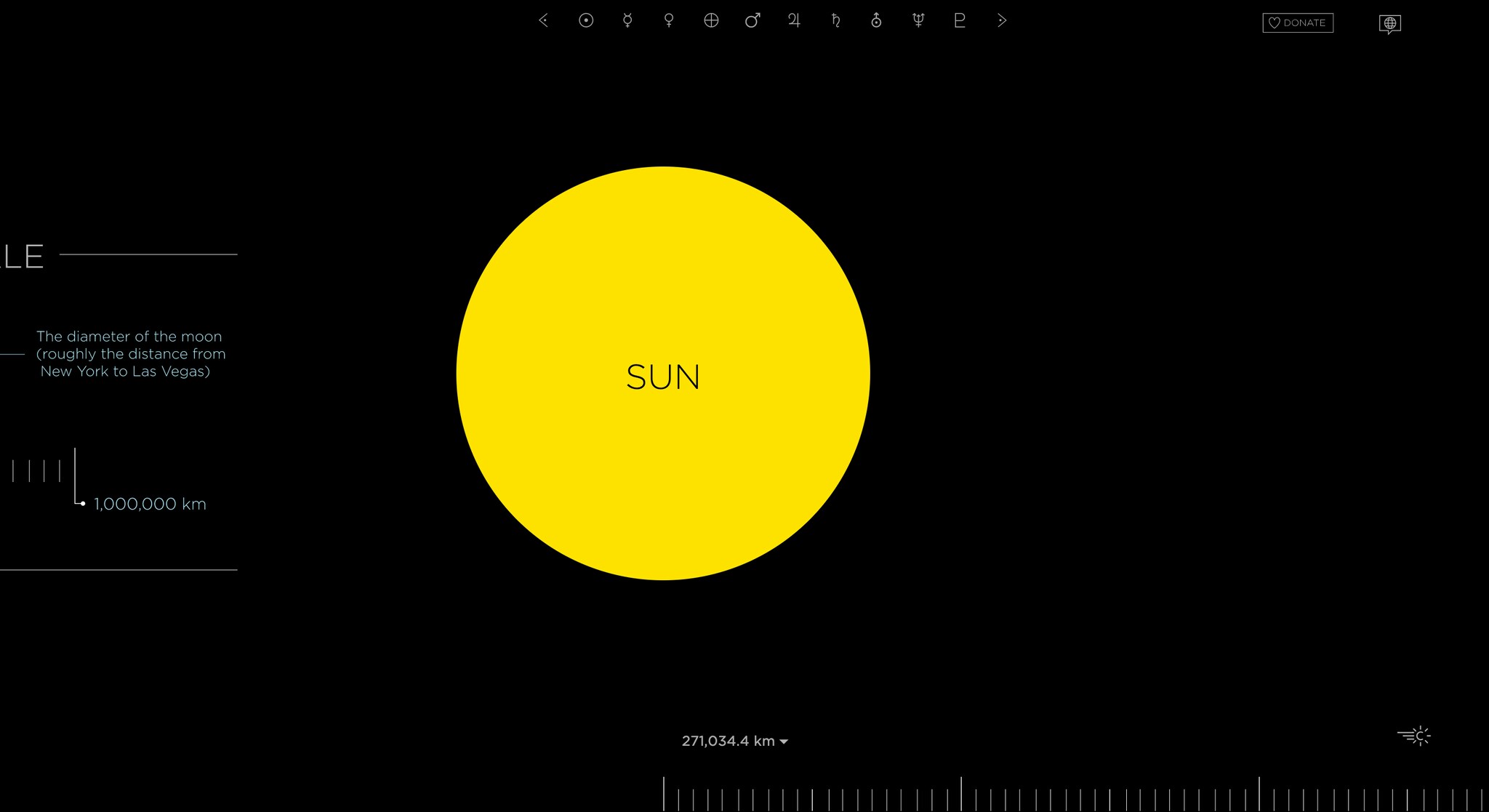
Je pense maintenant à un autre exemple de dataviz incroyable qui partait du postulat « si la Lune était un pixel ». On pouvait scroller horizontalement pour naviguer d’une planète à l’autre et, pour scroller de Mars à Jupiter et en le faisant rapidement, on mettait au moins 3 minutes. Ça mettait en évidence l’immensité du système solaire : avec une idée toute simple, on peut arriver à produire quelque chose d’extrêmement fort qui parle aux gens.
C’est vraiment quelque chose qui est en ce moment à la mode – et je ne dis pas ça dans le mauvais sens du terme – c’est quelque chose qui est de plus en plus utilisé et nous avons des ordinateurs de plus en plus puissants donc on va pouvoir faire tourner des dataviz incluant de la 3D, des choses comme ça, sans que l’ordinateur de celui qui la consulte ne freeze. On va avoir dans le futur de plus en plus de puissance, et notamment de puissance de calcul, ce qui va être très utile pour des questions d’IA. Les ordinateurs vont avoir plus de stockage, plus de puissance de calcul qui vont forcément nous amener de meilleurs résultats et des choses plus spectaculaires. Mais pas spectaculaires pour être spectaculaires : qui vont être plus immersifs.
On va peut-être même pouvoir faire de la dataviz avec des casques de réalité virtuelle pour des choses qui sont vraiment utiles, pas simplement des gadgets, mais des choses pertinentes qui peuvent nous aider. Et pourquoi pas utiliser des données pour aider des personnes qui ont un certain trouble et combiner ça avec de la réalité virtuelle. C’est vraiment quelque chose qui va être présent pendant un bon nombre d’années, car c’est tellement génial à faire et tellement utile, et ce n’est pas une tendance qui dépend d’une technologie précise. Certaines technologies, lorsqu’elles disparaissent, entraînent avec elles les tendances qui leur sont liées, ce n’est pas le cas ici.
Bien sûr oui, ça se fait déjà. Le problème des fake news, c’est qu’on a toutes sortes de fake news et on en a de plus en plus. Il faut bien comprendre que ce n’est pas quelque chose de totalement nouveau : j’entends certaines personnes dire qu’il y a une recrudescence de fake news aujourd’hui. Oui il y en a plus, mais on y est surtout plus exposé, sur internet notamment, et on en entend plus parler.
Au 20e siècle, il y en avait déjà beaucoup. Pour donner deux exemples : des gens étaient persuadés que l’homme n’était pas allé sur la Lune, c’est une des plus grandes fake news de l’histoire et elle vient du 20e siècle. Les gens étaient également persuadés que Paul McCartney, le bassiste des Beatles, était mort dans un accident de voiture et qu’il avait été remplacé par un sosie. Je connais un peu ça, car je cogère un fan club de McCartney, donc forcément, j’en entends parler et c’est intéressant de comprendre comment les gens sont capables de croire certaines théories et d’étudier ces mécanismes-là. Certaines fake news aujourd’hui nous paraissent totalement ahurissantes : certains sont persuadés que le président actuel des États-Unis est Trump et qu’il enfile tous les jours un masque de Biden. Ça prête à sourire, mais certaines personnes y croient. Il est parfois compliqué de distinguer une fake news – que les gens vont croire –des désinformations diffusées par des médias du type Gorafi, qui vont justement se moquer des gens qui croient à ces fake news.
La dataviz peut aider à mieux comprendre et donner du sens. Si je prends par exemple les antivax, avec les données que nous fournissent les états sur les vaccins, on peut faire des graphes, ce que fait par exemple Guillaume Rozier qui a fondé Covid Tracker. Avec ces outils, on peut avoir des graphes et mieux étudier la situation, faire des prévisions et démystifier ce que vont dire certaines personnes en leur disant « Non, avec ce qui s’est passé dans certains pays, c’est faux, parce que regardez, voilà la data, on vous explique » et donc tout de suite on peut plus facilement démystifier.
Parce que si on fait un texte dans lequel on explique qu’il y a des statistiques, des pourcentages, les gens ne vont pas forcément le lire. Un graphique, une image, ça vaut mille mots. C’est forcément plus pertinent et ça va aider les gens à comprendre. Après, je ne dis pas que la personne qui est endoctrinée par tout ça va y croire, mais la personne qui est indécise, si elle voit ce graphe, elle peut d’un coup éviter de basculer, parce qu’elle a vu un article qui lui permet de mieux comprendre la situation ; ça va être plutôt là pour sauver ces gens qui sont sur le point de basculer. Les gens qui ont déjà basculé, ça va être beaucoup plus dur, ce n’est pas un graphique qui va leur rendre la raison.
Bien sûr ! Et dans l’avenir il sera encore plus important. En ce moment on amasse de plus en plus de données : si on regarde en termes de Térabits, c’est de plus en plus impressionnant. Quelqu’un me disait que le nombre de photos que l’on trouve aujourd’hui est égal au nombre de photos qu’on a pu prendre au cours de 50 ans au cours du précédent siècle.
On produit de plus en plus de données, et il va y avoir de plus en plus d’entreprises qui vont se retrouver face à des millions, voire face à des milliards, de données. Même si les trier est assez simple à faire, humainement ça ne sera pas possible de le faire au vu du volume : il faudra faire appel à une IA pour cette tâche.
Face à ces millions ou milliards de données, on ne sait pas non plus quel sens on pourrait leur donner, on peut essayer d’utiliser une IA pour le faire.
Cependant, on ne peut pas non plus tout attendre d’une IA : comme je dis « l’IA, c’est avant tout des humains qui l’ont programmée », il ne faut donc pas croire que ça va tout résoudre par miracle.
Il peut y avoir des erreurs et des biais et on a pu le voir avec les biais racistes que certaines IA ont, notamment les IA entraînées à reconnaître des visages qui n’ont été entraînées à reconnaître que des visages blancs. Cela n’a pas été fait par pur racisme, la base de données était simplement comme ça, mais on se retrouve à avoir des personnes noires non reconnues ou assimilées à la première autre personne noire trouvée dans la base de données, car l’IA est incapable de distinguer deux personnes noires, ce qui peut avoir des conséquences assez catastrophiques, notamment dans un contexte d’enquête criminelle.
Il faut avoir ça en tête quand on utilise une IA et faire attention. Il y a un autre exemple plus léger : Amazon a fait des coques de téléphone et a nourri une IA en lui donnant des consignes très simples. Le principe était d’aller récupérer ce que les gens recherchaient le plus sur internet, de trouver des photos libres de droits correspondant à ces recherches et les imprimer sur des coques de téléphones.
Ce que les gens cherchent sur internet, c’est ce qu’on appelle les trois P magiques : Porn, Pilules (la drogue) et Poker (tout ce qui est lié au jeu). Forcément, on voyait sur les coques des gens qui se droguaient, préparaient leur drogue, des gens qui posaient du carrelage, et ça a été un énorme échec. Le problème ici n’est pas l’IA, mais ce qui s’est passé en amont : comment des personnes dans une réunion se sont dit que c’était une bonne idée en étant conscient des recherches que faisaient les internautes ? Ils savaient ce qui allait se passer et auraient dû arrêter. Après ils ont pu le faire consciemment pour faire le buzz, car certaines coques se sont arrachées et se sont revendues très cher. L’IA peut en tout cas être une solution.
Il y a aussi la solution collaborative, c’est-à-dire de demander à des gens de participer. Il y a notamment des associations qui font ça, comme Chimp&See qui demandait à des internautes bénévoles d’analyser des images pour déterminer si des chimpanzés ou d’autres espèces d’animaux se trouvaient dessus et de décrire leur comportement. Il y avait tout un guide qui aidait les gens à aller au bout et ça permettait vraiment un travail collaboratif. Avec le collaboratif, il faut cependant toujours vérifier les résultats et s’en méfier, car il peut y avoir des trolls s’amusant à les fausser.
Je crois qu’on a bien fait le tour pour comprendre les vrais enjeux de la dataviz, qu’on ne fait pas de la dataviz pour faire de la dataviz, mais que c’est avant tout de l’humain, c’est avant tout réfléchir à ce qu’on veut et où on veut aller, c’est aussi sortir des sentiers battus, et après seulement commencer à travailler sa dataviz. Ne jamais commencer à faire du code sans réfléchir, ce n’est pas la bonne solution, c’est vraiment ça qui est important.
Merci Victor, à bientôt pour un nouvel épisode !
Les exemples de dataviz cités dans l’article
La Lune https://joshworth.com/dev/pixelspace/pixelspace_solarsystem.html
Les séries https://www.ratingraph.com/
Les odeurs et les bruits par rue : http://goodcitylife.org/chattymaps/index.html
Strava Global HeatMap & un article medium sur la Strava Global HeatMap
Une carte du monde très détaillée
Des découvertes archéologiques à Amsterdam
https://twitter.com/VictorBaissait
https://www.twitch.tv/victorbaissait
https://www.youtube.com/channel/UCYOPzkhalbSwFNHz7p6YbUQ
Participation à l’émission On n'est plus des pigeons ! en tant qu’expert sur les fake news

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.