
État de l’observabilité en 2025
Découvrez pourquoi la pratique d’observabilité des leaders génère un retour sur investissement 53 % plus élevé que celui de leurs homologues.
À l’occasion de .conf25, nous avons mis un point d’honneur à définir ce que signifie la résilience numérique à l’ère de l’IA. Splunk propose la plateforme la plus puissante du monde pour unifier toutes vos données machine dans un seul et même endroit avec Splunk Platform, appuyer votre centre des opérations de sécurité (SOC) agentique avec Splunk Security et soutenir l’observabilité basée sur l’IA agentique avec Splunk Observability. Ces solutions sont conçues pour vous aider à corréler les données plus rapidement, à obtenir des informations plus pertinentes, à mieux collaborer et à offrir des expériences clients fluides.
Dans cette optique et pour ouvrir le nouveau chapitre de l’observabilité basée sur l’IA agentique, nous avons annoncé plusieurs fonctionnalités basées sur l’IA de détection et d’investigation des problèmes affectant les activités, notamment :
Afin de préserver la santé, les performances et la rentabilité de vos applications et infrastructures d’IA, nous avons également lancé :
Enfin, nous avons annoncé plusieurs innovations pour aider les équipes ITOps et d’ingénierie à profiter d’une expérience unifiée afin de corréler rapidement les données de télémétrie sur les environnements à trois niveaux et les architectures de microservices, et leur permettre de prioriser la résolution des problèmes critiques affectant les activités. Ces nouvelles fonctionnalités incluent : Business Insights in Observability Cloud
Lisez l’article ci-dessous (traduit de l’anglais) pour découvrir un récapitulatif complet de nos nouvelles fonctionnalités d’observabilité.
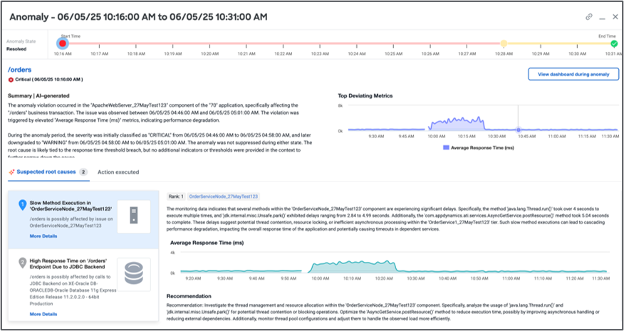
L’IA agentique rebat les cartes de la mise en place d’une pratique d’observabilité de pointe. Avec l’émergence du vibe coding, dans un avenir proche, il sera possible d’écrire des applications avec peu ou pas d’intervention humaine. Cependant, l’IA ne se contente pas seulement d’écrire du code, elle redéfinit les standards de l’observabilité sur l’ensemble du workflow de réponse aux incidents. Depuis des années, nous intégrons l’IA pour vous aider et nous sommes ravis d’annoncer des fonctionnalités basées sur l’IA agentique dans l’ensemble du portefeuille de Splunk Observability afin d’aider les équipes à investiguer et à résoudre les problèmes plus rapidement. Grâce à la corrélation des alertes basée sur l’IA, à la synthèse des incidents et au dépannage guidé par l’IA, l’IA agentique permet aux équipes de comprendre, de dépanner et de résoudre plus rapidement les incidents affectant les activités.
Au moindre problème, qu’il s’agisse d’une défaillance de serveur ou d’un bug dans une application, les alertes affluent et peuvent rapidement vous submerger. Avec tout ce bruit, il peut s’avérer difficile de faire sens des événements, et encore plus de résoudre le problème. Event iQ dans Splunk IT Service Intelligence (ITSI) aide à réduire les déluges d’alertes pour que chacun – novice ou expert – puisse passer moins de temps à gérer les alertes et davantage de temps à garantir le bon fonctionnement des services critiques.
Event iQ offre des fonctions de corrélation des alertes basées sur l’IA afin d’aider les équipes ITOps à réduire le bruit des alertes en regroupant les alertes similaires et en mettant en évidence les incidents critiques nécessitant une attention immédiate. Event iQ suggère en texte brut des champs intéressants et configure des conditions de corrélation d’événements, ce qui permet aux équipes de comprendre le problème et de se concentrer sur les éléments importants.
Le terme « épisode » désigne le regroupement des alertes similaires. Ces épisodes vous permettent d’éviter d’avoir à passer des heures à trier manuellement des dizaines, voire des centaines de notifications. Event iQ rassemble toutes les informations à votre place et vous permet d’identifier immédiatement le problème, quand il a commencé et quels sont les systèmes concernés.
Event iQ vous aide à configurer la corrélation automatisée des alertes en quelques clics seulement. Ainsi, vos équipes disposent instantanément de tout le contexte nécessaire lorsqu’elles ouvrent un épisode : plus besoin de passer d’un onglet à un autre ou d’aller à la chasse aux informations. Tout est clairement expliqué, vous savez donc toujours pourquoi les alertes ont été regroupées de cette manière. Lisez l’article dédié pour en savoir plus.
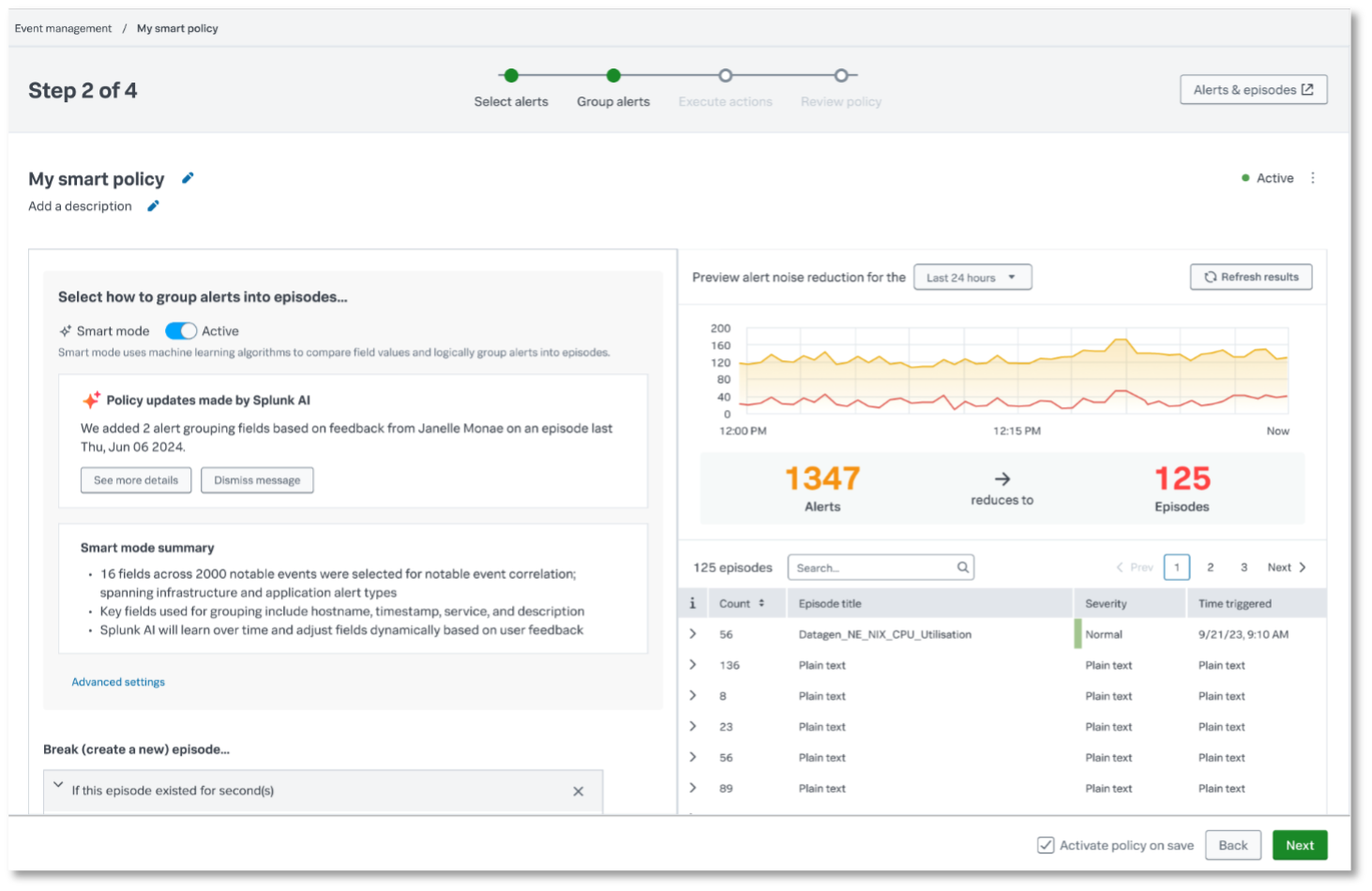
ITSI réduit déjà le bruit des alertes en corrélant et en regroupant les alertes similaires en épisodes. Désormais, grâce à l’IA avancée, Splunk ITSI peut réunir toutes les informations relatives à un incident (ce qui s’est passé, quand, les principaux événements et même un aperçu de sa cause) dans un résumé généré par IA et facile à lire. Cela signifie que les équipes n’ont plus besoin de jongler entre une multitude d’onglets, les informations pertinentes et des suggestions de mesures sont accessibles en un clic. Cela représente non seulement un gain de temps précieux, mais cela aide les utilisateurs moins expérimentés à tirer immédiatement parti de la plateforme. De plus, il est facile de partager les résumés avec ses collègues ou de les ajouter sur des outils tels que ServiceNow afin que tout le monde reste informé. En bref, Episode Summarization aide les équipes à travailler plus intelligemment, à réagir plus rapidement et à assurer le bon fonctionnement de leurs principaux services. ITSI Episode Summarization est disponible en alpha.
Demandez un accès sur la page Voice of the Customer du site de Splunk.
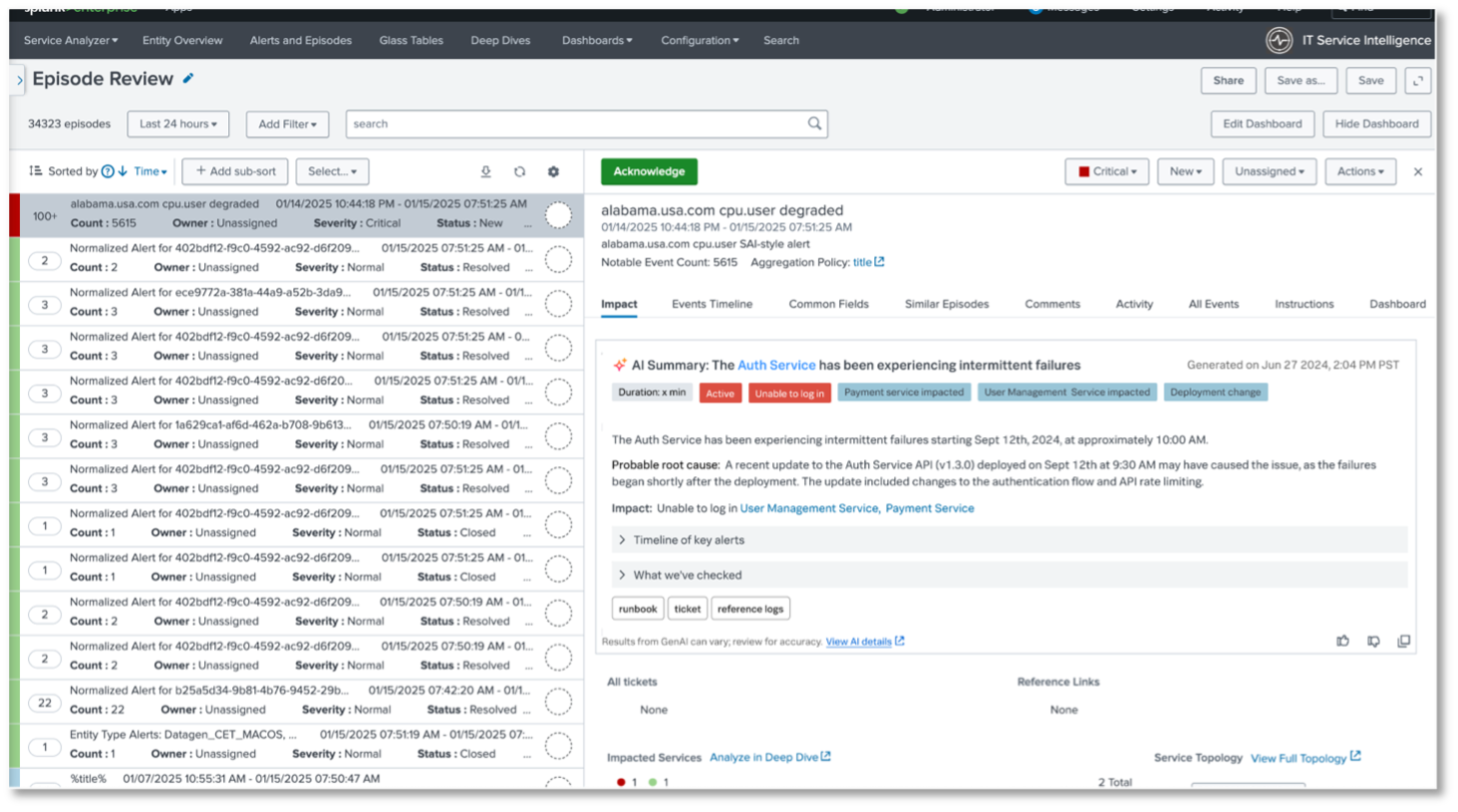
Traditionnellement, les ingénieurs DevOps et les ingénieurs en fiabilité des sites (SRE) doivent passer au crible les tableaux de bord, les logs et les métriques sur plusieurs écrans et outils pour identifier la cause d’une interruption de service ou d’un problème de performance. Le dépannage guidé par l’IA dans Observability Cloud agit comme un assistant SRE, triant automatiquement toutes les données relatives aux services et à l’infrastructure, déterminant si votre application ou votre infrastructure est en cause et mettant en évidence les causes profondes les plus probables, le tout dans un langage simple, dans le cadre de votre workflow existant.
Au lieu de passer leur temps à jongler entre les différents écrans, onglets et outils, les équipes disposent d’un classement des causes les plus probables, d’une analyse claire de l’impact de l’incident et de recommandations concrètes ; plus besoin de passer des heures à analyser manuellement les informations.
En cas d’alerte, l’IA analyse tout, des déploiements récents aux événements Kubernetes en passant par les incidents historiques et les schémas récurrents issus des correctifs précédents. Elle offre également une analyse concise des causes profondes (RCA) afin que les équipes puissent agir rapidement et en toute confiance. Ainsi, les temps d’arrêt sont réduits et le bon fonctionnement des services est assuré. AI-Directed Troubleshooting dans Observability Cloud est disponible en alpha.
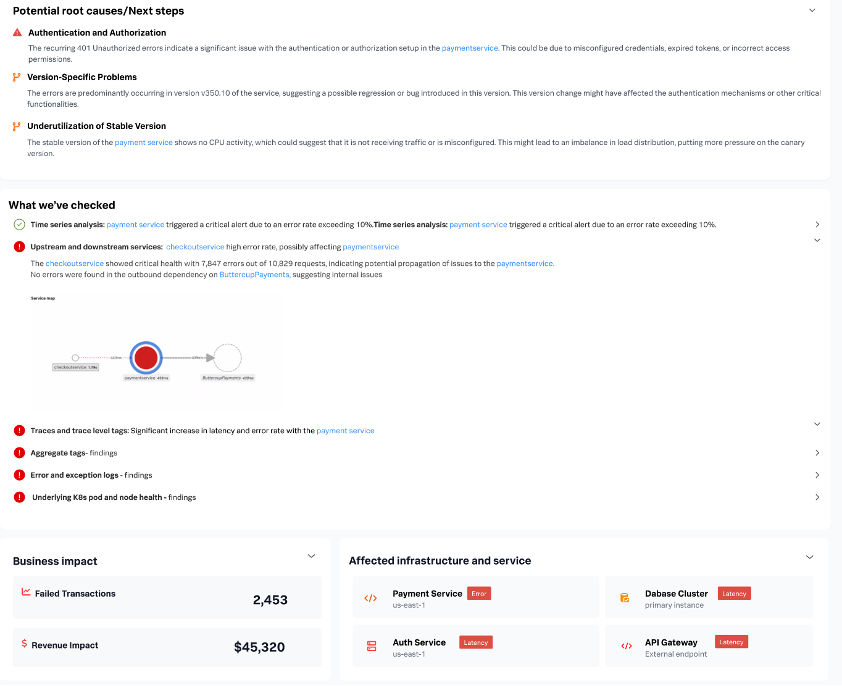
AI-Directed Troubleshooting est désormais disponible dans AppDynamics grâce à l’IA agentique. Cette nouvelle fonctionnalité vous aide à comprendre et à réagir rapidement en cas d’anomalies et d’infractions aux règles en analysant les incidents en temps réel. Elle permet de révéler les causes probables et propose des recommandations concrètes.
En cas d’anomalies ou d’infractions aux règles, l’IA ne se contente pas de signaler le problème. Elle explique ce qu’il se passe, pourquoi et comment y remédier. Vous obtenez des résumés précis des causes profondes sans avoir à jongler entre différents tableaux de bord ou à deviner quelle métrique est la plus pertinente.
Résultat : vos équipes résolvent les incidents plus rapidement et plus précisément, même si elles ne sont pas composées d’experts du système en question. Grâce à AI-Directed Troubleshooting, les manques de connaissances ne sont plus un frein, l’IA guide vos investigations en un seul clic et vous propose des informations exploitables dans le contexte des données en temps réel. AI-Directed Troubleshooting dans AppDynamics est disponible en alpha.

Il faut se rendre à l’évidence, l’IA est aujourd’hui omniprésente. Par conséquent, les équipes ITOps et d’ingénierie ont besoin d’outils de pointe pour minimiser les efforts et les coûts liés à la mise en place d’une infrastructure plus résiliente et plus complexe, capable de prendre en charge une télémétrie spécialisée. Pour atteindre des objectifs ambitieux et répondre aux demandes des clients, les équipes doivent également créer et déployer des modèles, des agents et des applications d’IA de grande qualité et performants.
Face à l’essor continu de l’IA, l’infrastructure nécessaire à la création d’applications a grandement évolué. En plus des GPU, de la capacité de calcul et des serveurs hébergés, il faut désormais ajouter aux composants d’infrastructure de base les grands modèles de langage (LLM), les bases de données vectorielles, ainsi que les frameworks et les bibliothèques d’IA. À l’instar de la supervision des infrastructures traditionnelle, une visibilité approfondie est nécessaire pour identifier et traiter les menaces, les inefficacités et les dégradations de performance, mais elle doit désormais s’accompagner d’une visibilité en temps réel et dans tous les environnements sur ces nouveaux composants d’IA. Avec AI Infrastructure Monitoring, les équipes ITOps et d’ingénierie peuvent s’assurer de la fiabilité, de la sécurité et de l’évolutivité de leurs systèmes.
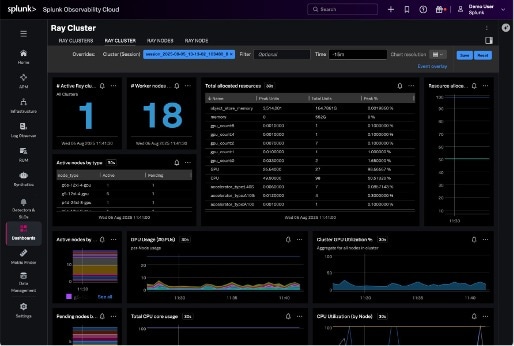
Les équipes peuvent consulter des tableaux de bord détaillés, des détecteurs et des traces de transactions afin de corréler la santé de l’entreprise, les tendances d’utilisation, les schémas récurrents et les valeurs aberrantes avec les composants d’infrastructure IA défaillants. Ces vues permettent aux équipes d’identifier de manière proactive les noisy neighbors, d’émettre une alerte concernant les métriques opérationnelles d’applications et de services IA, et de résoudre les problèmes de conflits de ressources et de demandes de workloads non satisfaites. Cette fonctionnalité contribue en fin de compte à atténuer les risques liés à la sécurité, aux performances, aux coûts et à la réputation. Lisez l’article dédié pour en savoir plus sur AI Infrastructure Monitoring.
L’essor de l’IA s’accompagne également de celui des agents IA et des applications agentiques tirant parti des LLM pour interpréter les données, raisonner et accomplir des tâches complexes. À l’instar du cerveau humain, les agents utilisent leurs LLM pour apprendre et mémoriser des informations afin d’être performants. Sans contrôle humain, les LLM peuvent souvent produire des résultats ou des réponses de mauvaise qualité ou trompeurs, ce qui nuit à la confiance des clients, à l’expérience des utilisateurs finaux et augmente les coûts de correction.
Avec AI Agent Monitoring, les équipes ITOps et d’ingénierie peuvent identifier et corriger de manière proactive les réponses erronées, inexactes ou indésirables des LLM (et des agents qu’ils alimentent) afin de garantir le bon fonctionnement, la sécurité et la fiabilité des applications. Les équipes peuvent suivre les métriques établies pour les transactions, les taux d’erreur et les performances, et analyser en détail les interactions afin d’identifier les problèmes affectant le comportement des applications, tels que les échecs d’utilisation de LLM ou d’outils. Grâce à l’intégration avec Cisco AI Defense, les équipes peuvent également bénéficier d’une vue unifiée des risques de sécurité critiques, notamment des injections de prompts, des fuites de données et des contenus préjudiciables, sur l’ensemble des agents et des LLM. Cette visibilité améliorée s’accompagne d’informations détaillées sur la consommation, les coûts, les performances et les mesures de qualité pour les modèles et les agents, ce qui permet aux équipes AI SRE et MLSecOps de gérer à la fois les risques et l’efficacité opérationnelle à partir d’un seul et même écran.
AppDynamics AI Agent Monitoring propose une interface unifiée pour superviser en temps réel les agents IA, les intégrations et l’infrastructure sous-jacente. Il permet aux équipes de suivre l’utilisation des LLM afin de garantir la conformité avec les politiques internes et réglementaires, et ainsi réduire les risques. Les équipes bénéficient d’une meilleure visibilité sur la consommation des ressources et les coûts. La supervision standardisée de la santé et des performances permet de détecter et de résoudre les problèmes avant qu’ils n’affectent les utilisateurs ou les applications métiers. Des tableaux de bord personnalisables et le mappage du parcours métier permettent de mieux comprendre l’impact des agents IA. AppDynamics AI Agent Monitoring permet aux entreprises de gérer, de faire évoluer et de garantir la fiabilité des initiatives d’IA critiques. Pour en savoir plus sur AI Agent Monitoring dans Observability Cloud et AppDynamics, rendez-vous ici.
L’essor de l’internet des agents augure une nouvelle ère de l’observabilité. En juillet, Outshift, le moteur d’innovation de Cisco, a fait don d’AGNTCY à la Linux Foundation, posant ainsi les bases d’un avenir où les agents de tous les fournisseurs pourront collaborer en toute simplicité. Avec la ferme intention de donner aux équipes ITOps et d’ingénierie les moyens d’agir grâce à des normes ouvertes, Splunk contribue activement à AGNTCY et s’associe aux leaders d’OpenTelemetry (OTel).
Splunk fait progresser les nomenclatures (Semantic Conventions) d’OTel en établissant un cadre de télémétrie standardisé et extensible facilitant la collecte transparente de données dans divers environnements d’IA. En intégrant le Metrics Compute Engine d’AGNTCY, la plateforme de Splunk propose une observabilité indépendante de tout fournisseur, évolutive et interopérable dans divers environnements d’IA. Cette fonctionnalité transforme les données télémétriques brutes en informations exploitables, pour fournir des métriques de performance fondamentales et avancées, telles que l’exactitude des informations au sein des applications agentiques.
Pour découvrir comment AI Agent Monitoring s’appuie sur des normes industrielles – OpenTelemetry et Cisco AGNTCY – pour proposer une supervision IA sans dépendance vis-à-vis d’un fournisseur, rendez-vous ici.
Enfin, nous avons présenté une expérience d’observabilité unifiée visant à fournir aux équipes davantage de contexte métier afin qu’elles puissent se concentrer sur les tâches les plus importantes. Ces fonctionnalités permettent de mettre en évidence les informations contextuelles et de sécuriser les processus métiers critiques nécessaires à la création d’applications performantes et de systèmes fiables à grande échelle, en temps réel, le tout en un seul endroit.
Dans un océan d’alertes et de métriques, identifier les axes de priorité de l’entreprise peut sembler tout bonnement impossible. Business Insights aide les équipes d’ingénierie et métiers à se concentrer sur la rentabilité en montrant, en temps réel, comment les performances des applications affectent les processus métiers critiques. Dans cette nouvelle version, Business Insights permet aux équipes de visualiser les processus longue durée, tels que les approbations de prêts ou de crédits, et de relier les performances techniques aux indicateurs clés de performance (KPI) de l’entreprise au sein d’une vue unifiée du parcours client. Au-delà des mesures SLA traditionnelles, il offre une vision claire de l’impact sur les revenus afin que les équipes puissent se concentrer sur les axes les plus importants. Business Insights est disponible en alpha. Demandez un accès sur la page Voice of the Customer du site de Splunk.

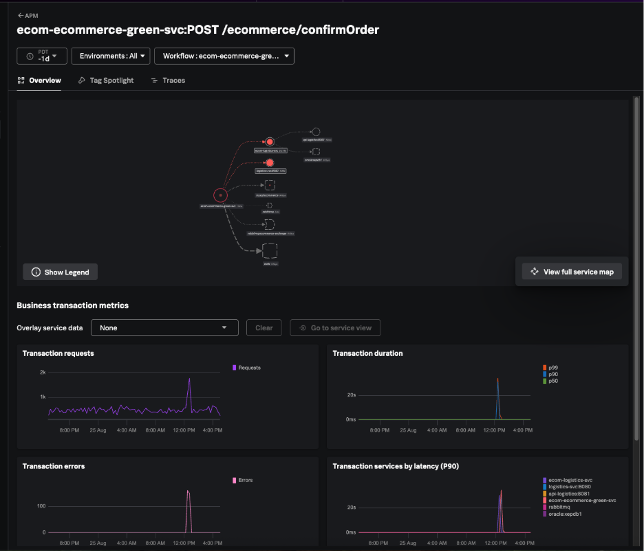
De nombreuses équipes utilisent à la fois des applications traditionnelles à trois niveaux et des services cloud-native, et elles ont besoin d’une solution APM pour les relier. Nous lançons de nouvelles fonctionnalités dans Splunk Observability Cloud afin de renforcer l’APM pour les applications cloud-native et d’étendre la prise en charge des environnements hybrides, en nous appuyant sur l’expertise d’AppDynamics en matière de supervision des applications traditionnelles à trois niveaux.
Voici quelques-unes de ces fonctionnalités :
Ensemble, ces fonctionnalités offrent une solution APM véritablement unifiée aux organisations qui développent et exploitent des applications hybrides ou centrées sur les microservices. Lisez notre article de blog pour en savoir plus.
Gérer votre workload de remédiation tout en respectant les accords de niveau de service (SLA) en matière d’innovation est difficile. Grâce à Secure Application pour Splunk Observability Cloud, les équipes d’ingénierie sont assurées que chaque ticket de vulnérabilité critique présent dans leur backlog représente un risque réel et validé pour leurs applications en cours d’exécution.
Contrairement aux outils traditionnels de détection statique des vulnérabilités et des menaces, Secure Application intègre la sécurité directement dans le framework d’observabilité à l’aide du même agent Splunk Observability que vous utilisez déjà. Cette innovation comble le fossé entre les conclusions du point de vue de la sécurité et les réalités de l’environnement de développement. En intégrant parfaitement la sécurité des applications à vos workflows d’observabilité et en enrichissant les résultats d’exécution avec des informations de sécurité complètes, vous pouvez hiérarchiser les vulnérabilités en fonction de leur exploitabilité en temps réel et de leur impact direct sur les applications, sans avoir à jongler entre différents outils, tout en respectant vos accords de niveau de service (SLA).
Avec Secure Application, les vulnérabilités sont directement mappées aux microservices qu’elles affectent dans la cartographie des services d’Observability Cloud APM. Ce contexte d’application aide les équipes de sécurité à faire la distinction entre les vulnérabilités au sein des bibliothèques et les risques exploitables réels dans votre environnement de production, et à s’assurer que la liste des vulnérabilités que vous recevez a été filtrée afin d’éliminer les informations superflues. Vous pouvez rapidement prioriser ces vulnérabilités en fonction de leur exploitabilité en temps réel et de leur impact direct sur les applications. Ainsi, vous pouvez corriger et résoudre les problèmes avant qu’ils n’affectent vos utilisateurs finaux ou ne compromettent la sécurité.
Application Vulnerability Detection est disponible en alpha. Pour en savoir plus, lisez l’article de blog concernant Secure Application sur Splunk Observability Cloud. Demandez un accès sur la page Voice of the Customer du site de Splunk.
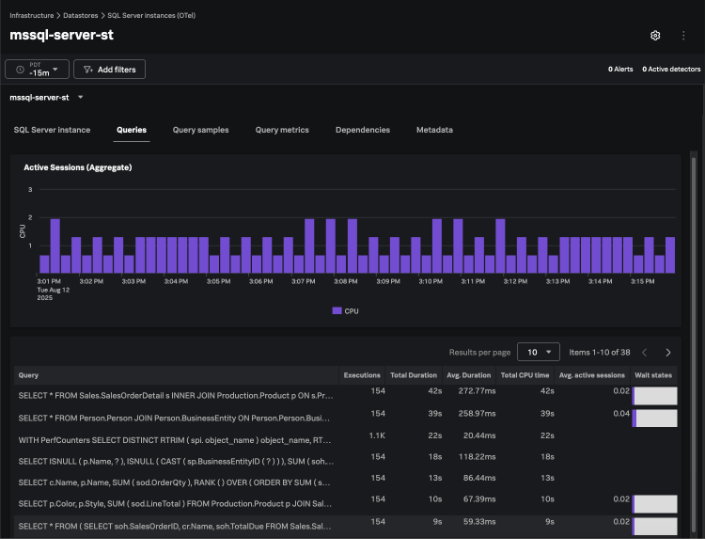
Traditionnellement, les clients de Splunk Observability Cloud utilisent les fonctionnalités Database Query Performance et Database Infrastructure Monitoring d’APM pour obtenir une visibilité sur les performances des requêtes et des hôtes. Cependant, nombre d’entre eux ont demandé la création d’une interface unifiée et la possibilité d’obtenir des informations plus précises sur les causes profondes des requêtes lentes.
Database Monitoring est une nouvelle solution de pointe permettant de disposer d’informations plus précises sur n’importe quel type de base de données. Basée sur OpenTelemetry, elle permet aux équipes en charge des applications et des bases de données de résoudre rapidement les problèmes d’inefficacité à l’aide d’informations détaillées sur les requêtes, telles que le temps d’attente, les catégories d’attente, le temps CPU, l’utilisation de mémoire et les plans d’exécution. En corrélant les performances des bases de données aux services d’applications et aux métriques d’infrastructure, elle permet aux équipes de hiérarchiser les priorités tout en identifiant les inefficacités afin de réduire les conflits et de contrôler les coûts.
Cette version est compatible avec Microsoft SQL Server et d’autres types de basés de données seront ajoutés ultérieurement. Database Monitoring est disponible en alpha. Demandez un accès sur la page Voice of the Customer du site de Splunk.
Nous sommes fiers d’annoncer que Splunk Observability Cloud devrait obtenir l’autorisation FedRAMP Moderate dans les prochains mois. En franchissant cette nouvelle étape importante, Splunk Observability Cloud respecte les normes de sécurité nécessaires au déploiement de ses solutions de pointe pour permettre aux agences gouvernementales américaines de gérer en toute sécurité les données sensibles du gouvernement.
Cette autorisation FedRAMP Moderate permet également aux services publics et aux agences gouvernementales d’accélérer leur transformation cloud, que ce soit dans des environnements sur site, hybrides ou cloud-native, afin qu’ils puissent répondre efficacement à la demande croissante de services aux citoyens, renforcer leurs capacités de cybersécurité et cloud, et offrir des expériences numériques fluides.
En offrant une visibilité complète sur les interactions des utilisateurs et en facilitant l’identification rapide des problèmes, leur résolution et l’amélioration continue au sein d’une solution unique, les organismes gouvernementaux peuvent renforcer la confiance du public et proposer des services fiables aux citoyens.
Pour en savoir plus sur notre autorisation FedRAMP Moderate, rendez-vous ici.
L’expérience applicative repose sur un réseau complexe (CDN, DNS, Internet) et des services externes, tels que des API tierces et des plateformes cloud, sur lesquels le service informatique n’a bien souvent aucun contrôle. L’intégration de Splunk Observability Cloud Real User Monitoring (RUM) à ThousandEyes regroupe les données relatives aux expériences des utilisateurs réels provenant de Splunk aux informations réseaux de ThousandEyes au sein d’une vue unifiée. Les équipes d’ingénierie peuvent rapidement déterminer si les problèmes proviennent de l’application ou du réseau, standardiser le processus de dépannage et résoudre les incidents plus rapidement, ce qui améliore finalement les performances et l’expérience utilisateur. Cette intégration est disponible sans frais supplémentaires pour les clients utilisant Splunk Observability Cloud et ThousandEyes. Elle est actuellement en alpha. Demandez un accès sur la page Voice of the Customer du site de Splunk.
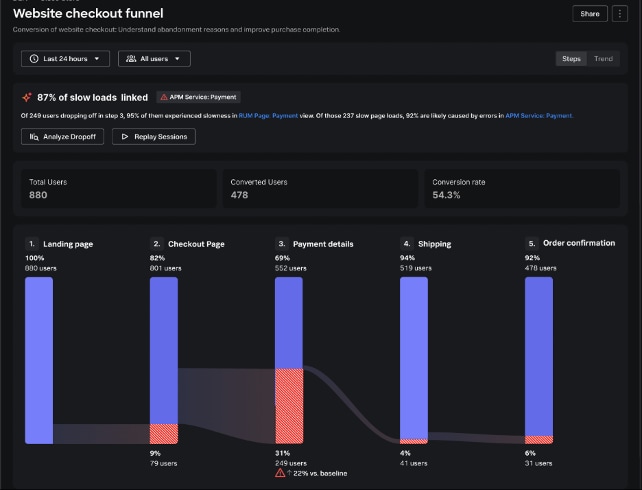
Les équipes d’ingénierie et produit partagent la responsabilité d’offrir une expérience utilisateur fluide et de générer des résultats métiers. Digital Experience Analytics (DEA) étend les capacités de Real User Monitoring (RUM) en offrant aux équipes d’ingénierie, de produit et de conception une visibilité approfondie sur le comportement, les intentions et les sentiments des utilisateurs. Contrairement aux outils cloisonnés, DEA met en corrélation les données comportementales avec les données de performance des applications, aidant ainsi les équipes à comprendre l’impact des incidents applicatifs sur l’expérience utilisateur et à les résoudre plus rapidement. En utilisant le même agent d’instrumentation OpenTelemetry que RUM, il simplifie également la configuration et réduit les frais généraux. Dans sa version initiale, DEA introduit l’analyse du tunnel de conversion avec un replay détaillé des sessions à chaque point d’abandon, ce qui facilite l’identification des problèmes et la prise de mesures. Digital Experience Analytics est disponible en alpha. Demandez un accès sur la page Voice of the Customer du site de Splunk.
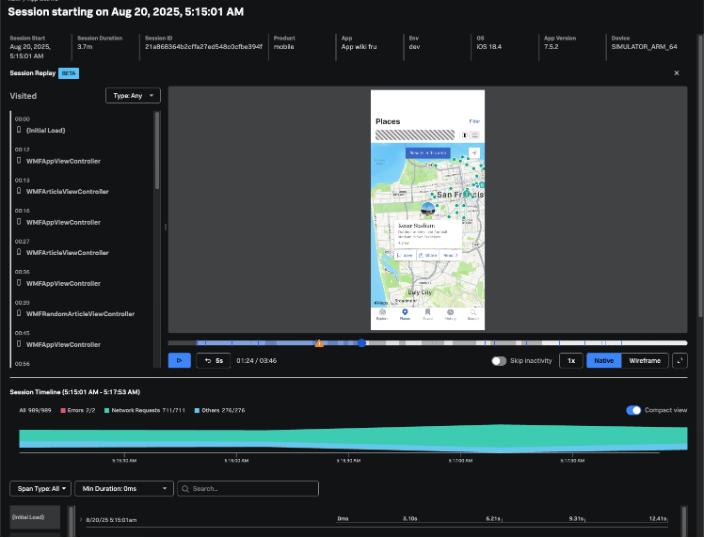
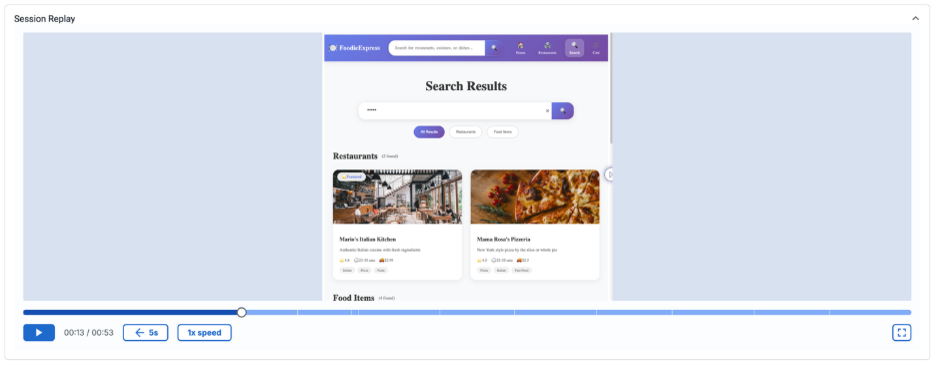
Des plantages ou des erreurs sont inévitables et les équipes doivent pouvoir visualiser ce que les utilisateurs ont vu. C’est pourquoi nous lançons la fonctionnalité Session Replay pour navigateur et mobile dans AppDynamics et améliorons la fonctionnalité Session Replay dans Observability Cloud, qui ne concernait auparavant que les navigateurs. Session Replay enregistre les interactions des utilisateurs sous forme de parcours dynamiques, semblables à des vidéos, associés à des métadonnées détaillées concernant la session, offrant ainsi aux équipes une visibilité claire sur l’expérience des utilisateurs en cas de problèmes. Grâce à ce contexte, les équipes peuvent aller au-delà du simple dépannage des problèmes de performances et évaluer la convivialité, identifier les points de friction et découvrir les défis cachés de l’UX. Pour en savoir plus sur Session Replay, rendez-vous sur les pages d’AppDynamics et d’Observability Cloud.
Cette fonctionnalité offre aux utilisateurs d’AppDynamics un agent commun pour collecter des données télémétriques à utiliser dans Splunk AppDynamics ou Observability Cloud. Les utilisateurs peuvent éviter des changements coûteux et perturbateurs dans leurs pipelines de déploiement et d’intégration, tout en évaluant les outils Splunk APM.
Il contient à la fois le code AppDynamics Agent et le code Splunk OpenTelemetry, qui est déployé de la même manière que tout autre AppDynamics Agent. Il vous suffit de mettre à jour vos agents existants et les dernières fonctionnalités OpenTelemetry seront ajoutées via une mise à jour normale. Vous pouvez effectuer la mise à jour via Smart Agent ou tout autre moyen que vous utilisez actuellement.
Nous proposons trois modes :
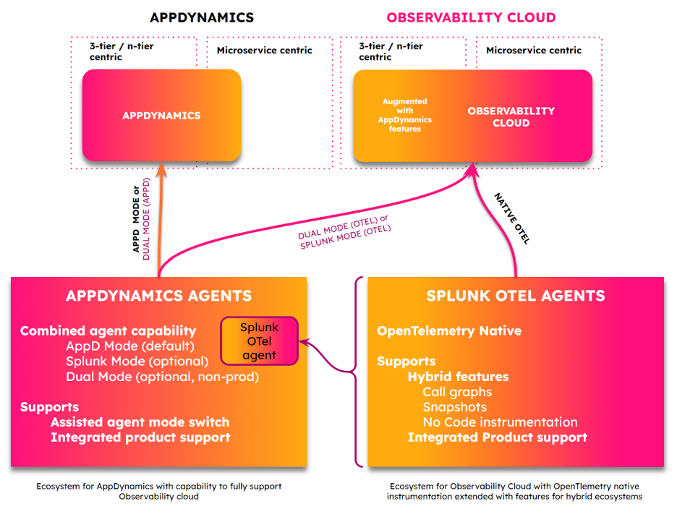
Lisez l’article de blog pour en savoir plus sur AppDynamics Combined Agent.
*Les versions alpha correspondent aux appellations « Private Preview » (aperçu privé) ou « Early Field Trial » (essai préliminaire) utilisées auparavant par Splunk. Le terme « alpha » indique que ces produits ou fonctionnalités sont en cours de développement par les équipes produit de Splunk. L’utilisation de versions alpha est réservée à certains clients et partenaires, sur invitation uniquement. Les utilisateurs des versions alpha peuvent partager leurs retours directement avec les équipes produit et sont susceptibles d’influencer le développement des fonctionnalités. En règle générale, la documentation relative aux fonctionnalités en alpha n’est accessible qu’aux utilisateurs de la version alpha. L’assistance aux clients et aux partenaires dans le cadre des programmes alpha est assurée par les équipes produit et d’ingénierie plutôt que par le biais des processus d’assistance habituels.

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.