Qu’est-ce que l’ITOps ? Plongée dans les opérations informatiques

L’ITOps, ou opérations informatiques, englobe les processus et services administrés par le personnel informatique d’une entreprise pour ses clients internes ou externes.
Toute entreprise qui utilise des ordinateurs a une structure chargée de répondre aux besoins informatiques de ses employés ou de ses clients, qu’elle l’appelle ou non ITOps. Dans un environnement d’entreprise typique, cependant, l’ITOps est un groupe distinct au sein du service informatique.
L’équipe des opérations IT joue un rôle essentiel dans la réalisation des objectifs métiers. Entre autres choses, elle contribue à la stabilité et la fiabilité de l’écosystème informatique et veille à ce que l’informatique permette aux employés et à la direction de l’entreprise d’atteindre les résultats souhaités.
Mais l’exercice de cette fonction évolue avec la migration progressive des entreprises vers le cloud et l’abandon du datacenter. Dans cet article, nous verrons ce que font les équipes ITOps, ce qui les distingue d’autres équipes comme les équipes DevOps, et comment évoluent les opérations IT.
Splunk ITSI est un leader dans le domaine de l’AIOps
Splunk IT Service Intelligence (ITSI) est une solution d’AIOps, d’analytique et de gestion IT qui aide les équipes à anticiper les incidents avant qu’ils n’affectent les clients.

ITSI utilise l’IA et le machine learning pour corréler les données collectées auprès de nombreuses sources de supervision et offrir une vue unifiée des services IT et métiers pertinents. La solution a un double avantage : elle réduit les déluges d’alertes et permet la prévention des interruptions de service.
Rôles et responsabilités des opérations IT
Les opérations IT apportent des conseils technologiques de haut niveau et effectuent quotidiennement des tâches de routine pour maintenir l’infrastructure informatique de l’entreprise. Les opérations IT jouent un rôle clé en assumant la responsabilité de bout en bout des services fournis par l’organisation IT, des systèmes et de l’infrastructure qui appuient les processus métier d’une entreprise. Cette équipe est chargée de maintenir la stabilité opérationnelle de l’organisation tout en soutenant de nouvelles initiatives visant à faire progresser l’entreprise.
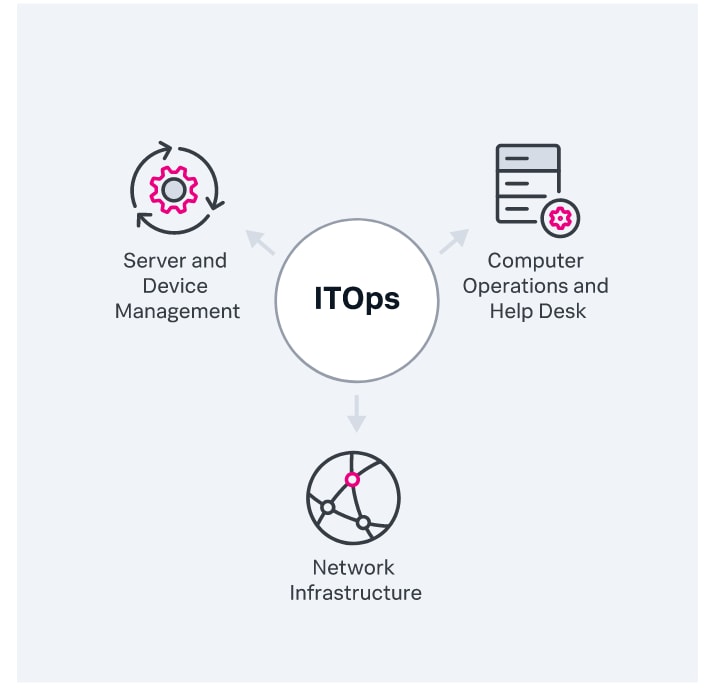
L’ITOps peut être adapté aux besoins et aux ressources de chaque entreprise : on ne peut donc pas dresser une liste de tâches homogène. En tant que fonction, par contre, l’ITOps peut être décomposé en trois domaines de responsabilité clés. Le détail et le nombre des tâches incombant à l’équipe ITOps varient d’une entreprise à l’autre. Ces tâches couvrent les domaines suivants :
Infrastructure du réseau
- Configurer et gérer toutes les fonctions de mise en réseau pour les communications informatiques internes et externes
- Configurer et gérer les lignes de télécommunication
- Gérer les ports de pare-feu pour permettre au réseau de communiquer avec des serveurs externes
- Fournir aux utilisateurs autorisés un accès distant sécurisé au réseau de l’entreprise
- Superviser la santé et les performances du réseau, détecter les anomalies et prévenir ou résoudre rapidement les problèmes, ce qui peut inclure la construction et la gestion d’un centre d’opérations réseau (NOC), emplacement physique centralisé à partir duquel les équipes ITOps peuvent superviser un réseau en permanence
Gestion des serveurs et des appareils
- Configurer, maintenir et gérer les serveurs de l’infrastructure et des applications
- Gérer le réseau et les systèmes de stockage pour veiller à ce qu’ils répondent aux exigences des applications
- Configurer et autoriser les serveurs de messagerie et de fichiers
- Provisionner et gérer les ordinateurs approuvés par l’entreprise
- Provisionner et gérer les téléphones portables et autres appareils mobiles
- Gérer les licences et les logiciels pour ordinateurs de bureau, ordinateurs portables et appareils mobiles
Opérations informatiques et service d’assistance
- Gérer l’emplacement et l’équipement des datacenters
- Administrer le service d’assistance
- Créer, autoriser et gérer tous les profils d’utilisateurs sur les systèmes de l’entreprise
- Fournir des informations d’audit de configuration de réseau aux organismes de réglementation, aux partenaires commerciaux et autres entités externes
- Déployer des correctifs et des mises à jour sur le réseau
- Assurer la haute disponibilité du réseau et tenir des plans de reprise après sinistre
- Avertir les utilisateurs lorsqu’un incident majeur impacte les services réseau
- Mettre en place des sauvegardes régulières pour faciliter la récupération des données en cas de besoin
Opérations métiers
- Gérer les fournisseurs et les prestataires et travailler avec eux
- Acquérir et payer le matériel, les logiciels et les applications
- Gestion de projet
Comment évoluent les opérations IT ?
Comme tout autre domaine du monde des technologies, l’ITOps n’est ni statique ni monolithique. Les technologies évoluent et de nouvelles approches opérationnelles émergent, notamment en combinant les opérations traditionnelles à d’autres équipes, systèmes et outils.
ITOps
Pour clarifier, commençons par établir où se situe l’ITOps.
En raison de sa description large et parfois nébuleuse, on peut avoir l’impression que l’ITOps recouvre tout ce qui a trait à l’informatique. Et il est vrai que les activités de l’ITOps varient considérablement d’une entreprise à l’autre. Mais dans tous les cas, sa responsabilité est de fournir et entretenir la technologie nécessaire aux activités d’une entreprise.
Dans la pratique, il s’agit de tâches telles que la maintenance des réseaux, la gestion des data centers, la garantie de la sécurité et de la conformité réglementaire, la gestion du service d’assistance, la gestion des licences et des logiciels, et d’autres tâches encore visant à donner des moyens aux autres employés de faire leur travail et à soutenir les opérations commerciales quotidiennes.
On notera que le développement de programmes et d’applications et les tâches connexes n’entrent pas dans les prérogatives de l’ITOps.
DevOps
Le DevOps est une approche de la livraison des services IT qui conjugue des personnes, des pratiques et des outils pour abattre les silos qui isolent les équipes de développement et d’exploitation. Mais le DevOps fait également référence à un rôle IT spécifique, chargé du développement, de la mise en œuvre et de la maintenance d’applications personnalisées à usage interne ou externe.
Comme son nom l’indique, le DevOps regroupe les rôles de développement et d’opérations informatiques. Au départ, le DevOps émane de l’idée que les équipes devraient assumer le support de ce qu’elles mettent en production. En suivant un ensemble de pratiques spécifiques, les équipes DevOps accélèrent le développement des applications et des services grâce à une approche plus réactive de la gestion de l’infrastructure IT, afin de déployer et mettre à jour des produits à la vitesse des marchés d’aujourd’hui.
Le DevOps s’articule autour de l’innovation et de l’optimisation des applications, tout en raccourcissant le cycle de vie du développement logiciel et en accélérant la mise sur le marché.
AIOps
Les itérations constantes et l’évolution des technologies ont imprimé leur marque sur le DevOps et l’ITOps. Et c’est sans aucun doute l’intelligence artificielle qui a eu le plus d’impact sur ces pratiques. Le terme « AIOps » désigne la pratique consistant à exploiter l’analyse IA et le machine learning pour automatiser et améliorer les opérations IT.
Les plateformes d’AIOps sont conçues pour les réseaux actuels et savent capturer de vastes ensembles de données dans l’environnement tout en assurant la qualité des données à des fins d’analyse complète. Elles peuvent également suggérer des solutions, automatiser des réponses et altérer des algorithmes pour améliorer la prise en charge des problèmes à venir.
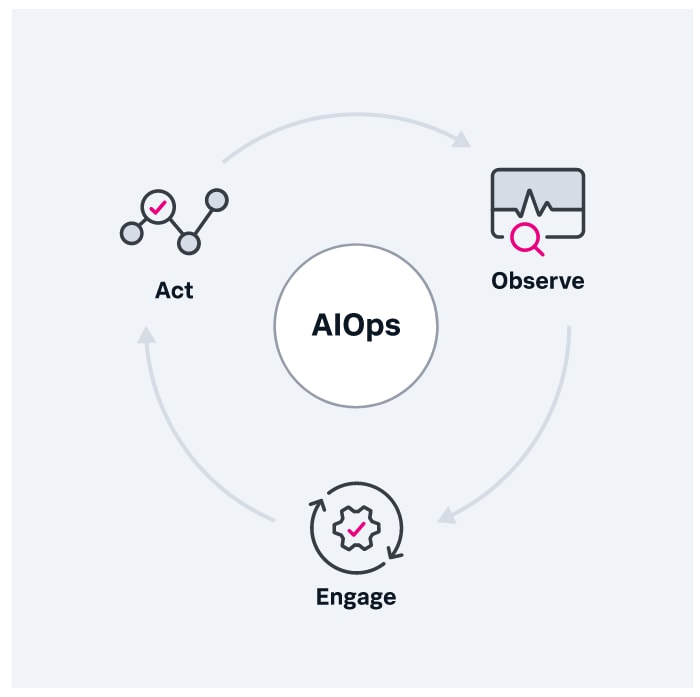
En pratique, l’AIOps est un processus en trois étapes – observation, engagement, action – exécuté en continu :
- Observation : tout d’abord, la plateforme AIOps traite les données provenant de diverses sources en temps réel, y compris celles de la supervision informatique traditionnelle et les événements de log, entre autres. Les algorithmes d’IA s’appuient sur les anomalies présentes dans les données pour détecter automatiquement les problèmes importants, que la plateforme analyse ensuite en regroupant les problèmes similaires.
- Engagement : la plateforme AIOps avertit les équipes informatiques concernées de la présence d’anomalies. Comme elles sont regroupées par type, le nombre de notifications est réduit.
- Action : les plateformes AIOps peuvent automatiser l’acheminement des workflows avec ou sans intervention humaine, en apprenant des réponses de l’équipe informatique pour gagner progressivement en précision. À terme, elle peut apprendre à résoudre les problèmes avant qu’ils n’atteignent l’entreprise et n’affectent les utilisateurs finaux.
(D’autres tendances « Ops » émergent également : découvrez le NoOps ou le CloudOps par exemple.)
L’avenir de l’ITOps
Dans un paysage technologique qui évolue à grande vitesse, les opérations informatiques (ITOps) jouent un rôle central en assurant la stabilité des écosystèmes IT qui sous-tendent la réussite de l’entreprise. Avec les progrès technologiques, l’ITOps fusionne avec le DevOps et se tourne vers l’AIOps en misant sur l’IA et l’automatisation pour gagner en efficacité. Cette évolution souligne la nature dynamique de l’ITOps, indispensable à l’adaptation et au succès des entreprises.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.

Articles connexes
À propos de Splunk
Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Abonnez-vous à notre blog
Recevez les derniers articles de Splunk par e-mail.