
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

L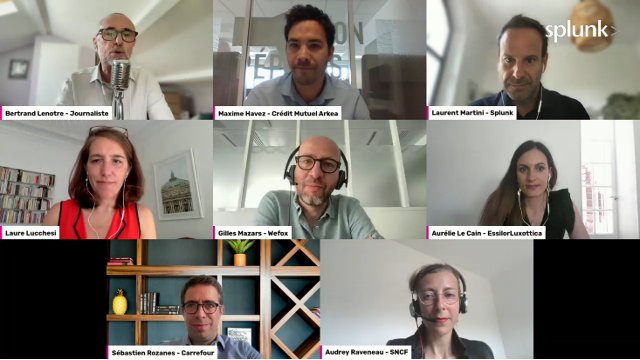 a première édition de notre e-book dédié à La data du Futur avait souligné les enjeux sociaux du numérique et les inégalités parfois criantes en matière d’accessibilité et de traitement des données. Un an plus tard, la tendance paraît s’être totalement inversée. L’explosion récente des initiatives dans les domaines de l’open data, de l’intelligence artificielle et du machine learning permettent en effet à un nombre croissant d’individus de tirer parti de la manne des données, sans pour autant être des experts.
a première édition de notre e-book dédié à La data du Futur avait souligné les enjeux sociaux du numérique et les inégalités parfois criantes en matière d’accessibilité et de traitement des données. Un an plus tard, la tendance paraît s’être totalement inversée. L’explosion récente des initiatives dans les domaines de l’open data, de l’intelligence artificielle et du machine learning permettent en effet à un nombre croissant d’individus de tirer parti de la manne des données, sans pour autant être des experts.
On pense notamment à ChatGPT qui, avec ses plus de 200 millions d’utilisateurs, connaît un succès plus fulgurant encore que la plupart des réseaux sociaux, mais le phénomène est loin d’être isolé. Peut-on dès lors affirmer que l’ère de la démocratisation de la data est arrivée ? Pour ce qui est des usages et des technologies, la machine semble en tout cas être déjà bien lancée.
C’est justement un des points soulevés par les invités de notre podcast Étant Données, qui donne la parole aux acteurs et aux actrices de la data. À l’occasion d’un LinkedIn Live, Maxime Havez, Chief Data Officer de Crédit Mutuel Arkéa, Sébastien Rozanes, Global Chief Data & Analytics Officer de Carrefour, Gilles Mazars, Head of Advanced Innovation de wefox, Aurélie Le Cain, Head of data pour les technologies de lunettes connectées d’EssilorLuxottica, et Laurent Martini, Vice-président Europe du Sud et marchés émergents de Splunk, ont accepté de revenir sur ces thèmes d’actualité en répondant aux questions du journaliste Bertrand Lenotre.
Le Chief Data Officer du Crédit Mutuel Arkéa est formel : « l’arrivée de ChatGPT a mis un nouveau coup de projecteur sur l’IA » en permettant au grand public de se projeter dans des usages potentiels, jusqu’ici réservés aux experts du secteur. Et ces technologies ouvrent tout un monde de possibilités pour les entreprises.
 Mais comment les exploiter de manière optimale ? D’après Maxime Havez, les organisations doivent commencer par cartographier avec pertinence les usages ainsi que les différentes formes d’implémentation de l’IA générative qui peuvent être mises en place. La task force du Crédit Mutuel Arkéa a d’ailleurs déjà identifié un certain nombre d’enjeux fondamentaux :
Mais comment les exploiter de manière optimale ? D’après Maxime Havez, les organisations doivent commencer par cartographier avec pertinence les usages ainsi que les différentes formes d’implémentation de l’IA générative qui peuvent être mises en place. La task force du Crédit Mutuel Arkéa a d’ailleurs déjà identifié un certain nombre d’enjeux fondamentaux :
De nombreux cas d’usage qui s’imposent aujourd’hui dans les pratiques étaient déjà identifiés, voire amorcés, bien avant le lancement de ChatGPT, mais leur intérêt n’était pas toujours évident pour les utilisateurs. La popularité des IA génératives permet dorénavant à une multitude de collaborateurs de l’entreprise de mieux se représenter la manière dont ils peuvent tirer parti de ces technologies dans le cadre de leur travail.
Les chatbots, mailbots et autres solutions conversationnelles semblaient avoir atteint leurs limites, mais les IA génératives pourraient leur donner un nouvel élan et permettre d’améliorer les interactions avec les utilisateurs.
Avec tous ces changements, il est essentiel de communiquer à tous les niveaux de l’organisation pour clarifier les risques liés à l’utilisation de ces outils et aux enjeux de souveraineté. Il est également important de mettre en place des plans d’action afin de pouvoir mener des expérimentations dans ce domaine.
 L’exemple de Carrefour illustre à merveille ce phénomène de démocratisation ultra rapide de l’IA et du machine learning, jusqu’ici réservés à l’élite de la data. Comme l’explique Sébastien Rozanes, au sein de son organisation, « jamais une technologie n’était passée aussi vite de l’annonce (de lancement) à l’application concrète », un succès dû en grande partie au caractère intuitif et personnalisable de ces technologies, qui offrent ainsi un potentiel gigantesque pour développer le fast data : un moyen d’offrir la puissance du big data sur le terrain, en temps réel.
L’exemple de Carrefour illustre à merveille ce phénomène de démocratisation ultra rapide de l’IA et du machine learning, jusqu’ici réservés à l’élite de la data. Comme l’explique Sébastien Rozanes, au sein de son organisation, « jamais une technologie n’était passée aussi vite de l’annonce (de lancement) à l’application concrète », un succès dû en grande partie au caractère intuitif et personnalisable de ces technologies, qui offrent ainsi un potentiel gigantesque pour développer le fast data : un moyen d’offrir la puissance du big data sur le terrain, en temps réel.
Et les domaines d’application sont considérables. Par exemple, dans une entreprise comme Carrefour, où la majorité des collaborateurs travaille au contact des clients, il peut être particulièrement difficile de faire des choix basés sur des données. Mais, grâce à l’IA générative, les employés n’ont plus à interpréter des statistiques, des tableaux et des graphiques pour prendre leurs décisions. Ils ont désormais directement accès à des recommandations exploitables, concrètes, en temps réel et en langage naturel, générées à partir des données de l’organisation. Cette capacité de l’IA générative à traduire d’immenses volumes de données en langage humain, en temps réel, a donc été décisive pour rendre la data accessible à tous, même sans aucune connaissance technique.
La tendance n’est toutefois pas nouvelle. Certains éditeurs de logiciel en avaient déjà fait leur cheval de bataille, avec des outils permettant d’utiliser le machine learning sans écrire la moindre ligne de code et parfois même sans le savoir. Mais les choses se sont accélérées de manière phénoménale au cours des six derniers mois, et les trajectoires de l’adoption du machine learning par les métiers ont été bouleversées par la tornade des grands modèles de langage (LLM) tels que ChatGPT, qui offrent l’opportunité aux entreprises d’exploiter des possibilités inaccessibles jusqu’ici.
Au sein de l’entreprise, cette démocratisation des usages de la donnée a surtout été rendue possible grâce à des avancées technologiques majeures, qui ont permis à un public plus large de bénéficier de la puissance du machine learning et du big data.
 Comme l’explique Laurent Martini, « la capacité des entreprises à gérer et à exploiter les données est devenue un avantage concurrentiel ». Mais pour tirer son épingle du jeu, encore faut-il être en mesure de traiter un volume de données sans cesse plus important et plus volatil.
Comme l’explique Laurent Martini, « la capacité des entreprises à gérer et à exploiter les données est devenue un avantage concurrentiel ». Mais pour tirer son épingle du jeu, encore faut-il être en mesure de traiter un volume de données sans cesse plus important et plus volatil.
C’est là que l’AIOps entre en jeu, car la tâche est désormais impossible pour un être humain, d’autant plus que la plupart des sources concernées sont des données machine ou des informations que l’organisation n’a même pas conscience d’avoir en sa possession. Dans ce contexte, l’AIOps consiste à utiliser l’intelligence artificielle pour classifier et exploiter la donnée, tout en automatisant un certain nombre de tâches. Et l’enjeu est de taille, dans la mesure où ces solutions peuvent aider les entreprises à prévenir les dysfonctionnements critiques.
 Les avancées technologiques récentes ont ouvert la porte du machine learning à de nombreuses équipes techniques, qui ne disposaient pas des ressources ou des infrastructures nécessaires pour accéder à ces outils auparavant. Et selon Gilles Mazars, cette démocratisation s’explique par deux phénomènes concomitants.
Les avancées technologiques récentes ont ouvert la porte du machine learning à de nombreuses équipes techniques, qui ne disposaient pas des ressources ou des infrastructures nécessaires pour accéder à ces outils auparavant. Et selon Gilles Mazars, cette démocratisation s’explique par deux phénomènes concomitants.
De plus, contrairement à ce que l’on a pu craindre au début du processus, cet écosystème n’a pas été accaparé par une poignée d’organisations. Au contraire, on constate qu’il est extrêmement large et ouvert, ce qui permet à une multitude de développeurs de profiter d’un nombre croissant de datasets et de modèles.
 Pour Aurélie Le Cain, il faut toutefois prêter attention à ce que ces avancées technologiques ne nous fassent pas oublier les questions déontologiques, et tout particulièrement les enjeux écologiques du secteur de la data. Car le numérique représente aujourd’hui 3 à 4 % des émissions de gaz à effet de serre dans le monde et 2,5 % de l’empreinte carbone de la France. Et si les pratiques n’évoluent pas, ce chiffre risque fort d’exploser dans les années à venir.
Pour Aurélie Le Cain, il faut toutefois prêter attention à ce que ces avancées technologiques ne nous fassent pas oublier les questions déontologiques, et tout particulièrement les enjeux écologiques du secteur de la data. Car le numérique représente aujourd’hui 3 à 4 % des émissions de gaz à effet de serre dans le monde et 2,5 % de l’empreinte carbone de la France. Et si les pratiques n’évoluent pas, ce chiffre risque fort d’exploser dans les années à venir.
Au-delà des lois et réglementations, il est donc important que les entreprises s’emparent de ces problématiques et les intègrent dès la phase de conception. Par exemple, EssilorLuxottica a fait le choix de développer des lunettes connectées prenant en compte l’impact environnemental lié à leur utilisation en optimisant ses algorithmes et ses processus de transfert des données. Cette approche permet non seulement d’économiser la batterie et de limiter le recours à des matériaux polluants, mais également d’améliorer l’expérience de l’utilisateur, qui peut ainsi profiter d’un produit ayant besoin d’être rechargé moins fréquemment.
Cet exemple montre bien que les organisations ont tout intérêt à intégrer des solutions innovantes dès la conception de leurs produits, tant au niveau du software que du hardware, afin de faire efficacement face aux enjeux d’aujourd’hui et de demain.
Vous voulez en savoir plus sur l’avenir de la data ? Visionnez l’intégralité du LinkedIn Live et téléchargez notre e-book hors-série La data du futur : l’ère de la démocratisation.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.