
Créer une pratique d’observabilité de pointe

Quand nous discutons avec un client Splunk actuel ou potentiel, on nous demande souvent « Pourquoi ai-je besoin de Splunk alors que je peux simplement utiliser AWS Cloudwatch, Azure Monitor ou GCP Cloud Operations Suite (anciennement Stackdriver) pour superviser mon cloud ? » Et c’est une excellente question !
La supervision offerte par les fournisseurs de cloud est souvent perçue comme « moins chère », « plus facile » ou « plus intégrée ». On a donc tendance, en particulier au début de son parcours cloud, à s’appuyer fortement sur ces outils. Nous avons vu cette approche à l’œuvre maintes et maintes fois, et croyez-nous, c’est une grosse erreur.
Dans cet article de blog, nous vous aiderons à comprendre ce qui rend Splunk nécessaire. Nous apporterons une réponse « globale » à cette question en l’appuyant sur cinq idées et des exemples convaincants. Croyez-moi, vous ne vous contenterez plus jamais des seuls outils de votre fournisseur de cloud !
Bien. Pourquoi avez-vous besoin de Splunk, et pas seulement de la solution de supervision de votre fournisseur de cloud ?
La réponse la plus simple que je puisse fournir est la suivante : les solutions de supervision des fournisseurs de cloud ne font souvent qu’alimenter un nouveau silo où les données sont souvent cloisonnées, hors d’accès et impossibles à corréler avec d’autres sources de données. De plus, la solution de supervision de chaque fournisseur de cloud offre des caractéristiques et des fonctionnalités limitées, et il semblerait qu’Amazon, Microsoft et Google ne visent pas plus haut que le « minimum syndical » en matière de fonctionnalité et de convivialité.
Le problème n’est pas nouveau. Depuis des années, Splunk est la solution standard de facto pour libérer et corréler les données. Prenons par exemple VMWare. Bien sûr, les administrateurs VMWare peuvent être tout à fait satisfaits de VSphere et l’utiliser avec aisance pour superviser, administrer et dépanner la plateforme VMWare. Mais qu’en est-il du responsable de l’application qui s’exécute sur une machine virtuelle VMWare ? Il y a de fortes chances qu’il ne se connecte pas à VSphere quand il a un problème avec son application. Pourtant, il est tout à fait possible que le problème soit le fruit d’un événement VMotion inattendu ou d’une VM voisine turbulente ! On peut dire la même chose des bases de données, des réseaux, du stockage et de toutes les autres technologies. Sans la possibilité de centraliser les données de plusieurs systèmes, vous aurez toujours du mal à corréler les informations, à investiguer et à trouver la véritable cause d’un incident.
Si cette réponse globale ne vous a pas encore convaincu, permettez-moi de l’étayer avec cinq exemples d’informations clés que vous aurez du mal à obtenir en utilisant la supervision de votre plateforme cloud.
Comme dans la plupart des organisations, vous gérez sans doute plusieurs comptes cloud et déployez des ressources dans plusieurs régions, et malheureusement, il n’y a guère que sur vos factures que vous avez une « visibilité complète » de votre infrastructure, si vous voyez ce que je veux dire. Passer d’un compte à l’autre ou d’une région à l’autre dans la console du fournisseur de cloud pour obtenir des informations sur l’infrastructure n’a rien d’amusant. Mais en utilisant Splunk, vous pourrez répondre facilement aux questions touchant vos infrastructures critiques sur tous les comptes et sur toutes les régions :
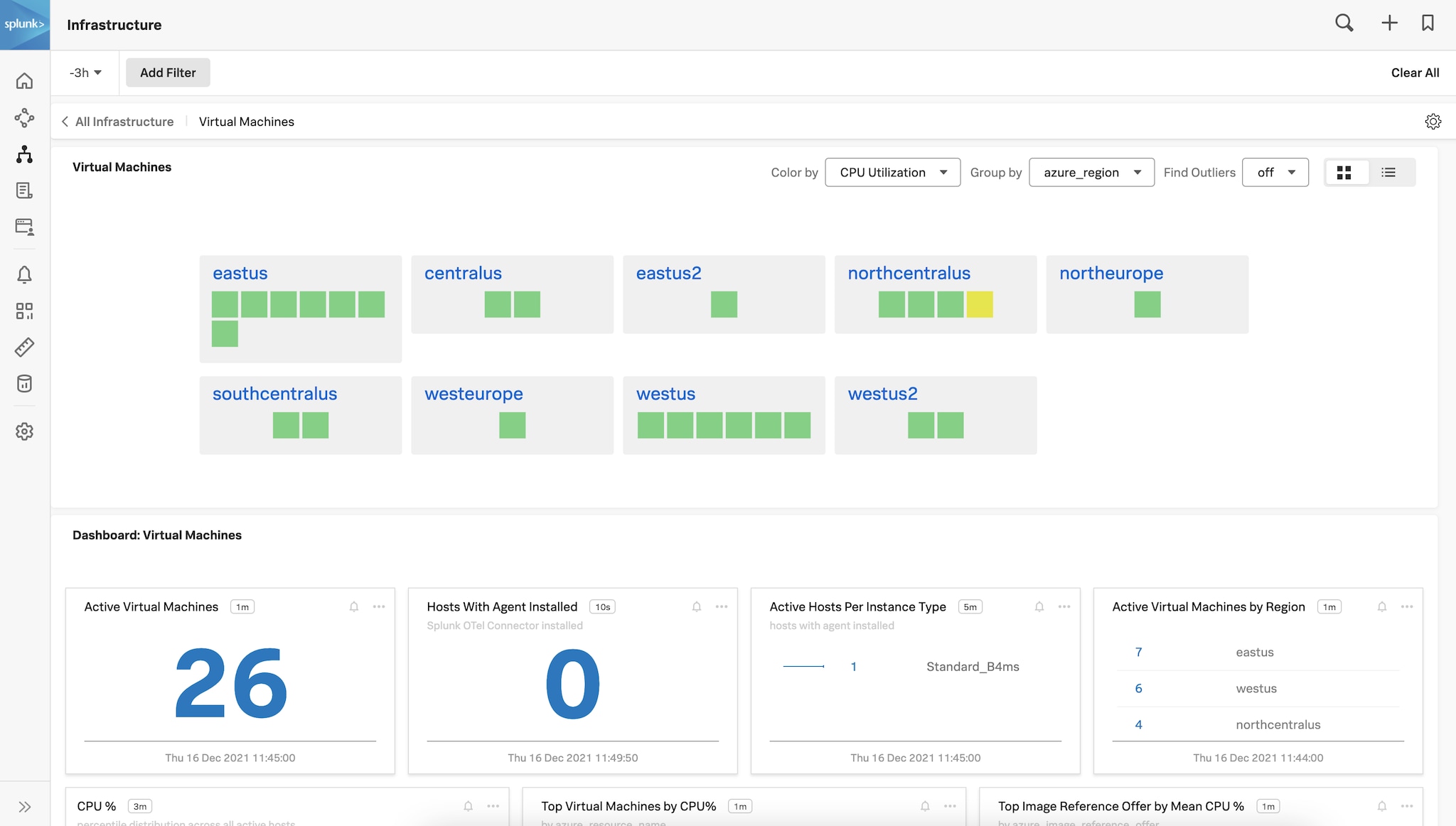
Figure 1 : Inventaire de toutes les VM Azure de tous les comptes, regroupées par région
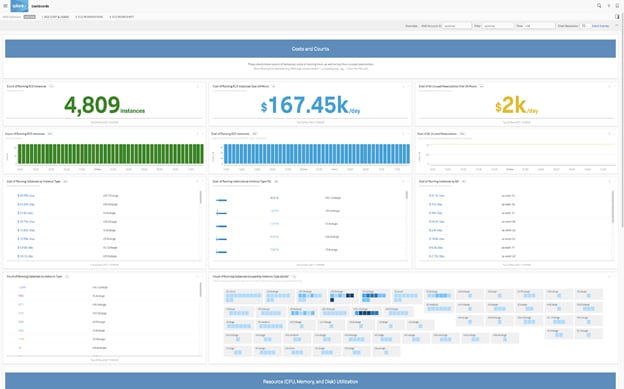
Figure 2 : Tableau de bord d’analyse des coûts Splunk AWS EC2
Dans la plupart des organisations, on migre des workloads vers le cloud, mais ils conservent des dépendances locales et externes. En effet, les workloads qui restent sur site font généralement partie des systèmes stratégiques les plus précieux d’une entreprise. La migration des workloads vers le cloud est souvent échelonnée : les composants à faible risque passent en premier et, dans la plupart des cas, ils font toujours appel à des dépendances externes pour remplir leur mission.
Imaginez devoir dépanner une application comme celle-là. Attendez... vous avez certainement déjà dû le faire ! Et laissez-moi deviner comment cela s’est passé : la solution de supervision du fournisseur de cloud utilisée par l’équipe des opérations cloud annonçait « tout va bien », tandis que les outils de supervision des équipes des opérations IT disaient la même chose.
D’après ce que nous avons vu chez Splunk, quand les organisations sont capables de résoudre ce problème complexe, c’est parce qu’elles ont centralisé leur supervision et leurs investigations sur une seule plateforme. Les recherches, les tableaux de bord et les visualisations Splunk deviennent le « langage universel » utilisé par les équipes pour trier, isoler et analyser les incidents.
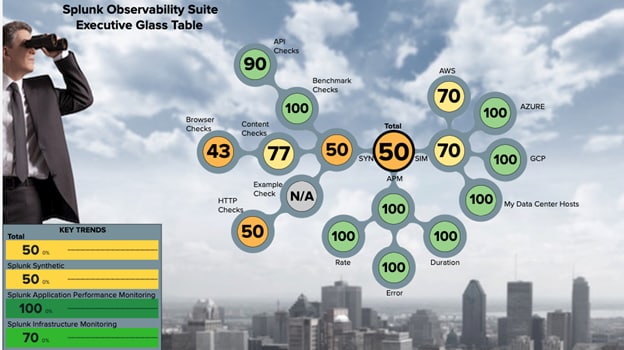
Figure 3 : Scores de santé du service multicloud affichés dans une glass table de Splunk Observability
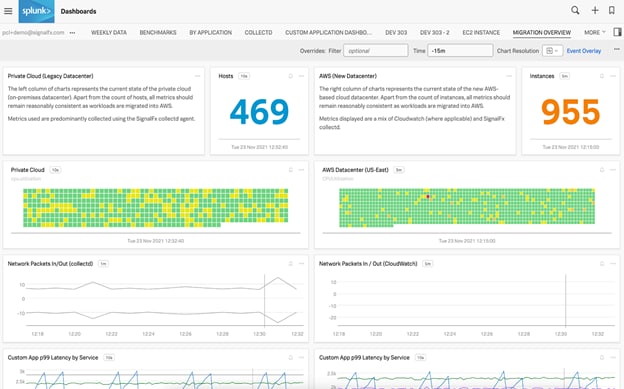
Figure 4 : Tableau de bord Splunk affichant les métriques des hôtes de cloud privé et les métriques des instances AWS
Les fournisseurs de cloud, et c’est compréhensible, limitent le type et la granularité des données de supervision auxquelles vous avez accès. Par exemple, les métriques AWS Cloudwatch sont collectées par défaut à intervalles de cinq minutes. Au mieux, vous pouvez augmenter cette fréquence à une fois par minute, mais pas plus. Imaginez votre fournisseur de cloud comme un baby-sitter chargé de garder vos enfants. Comment vous sentiriez-vous s’il était constamment collé à son téléphone et n’en levait les yeux que toutes les cinq minutes pour « surveiller les enfants » ? Pas très bien. Il peut se passer beaucoup de choses en cinq minutes.
Outre la granularité, il se peut également qu’un appareil envoie de la télémétrie intéressante mais que les métriques de votre fournisseur de cloud ne les prennent pas en charge. Je vais m’attarder un peu plus sur AWS à ce sujet. Le stockage EBS est tarifé en fonction de la taille totale du disque allouée, quelle que soit la quantité d’espace réellement utilisée. Pour faire des économies, nous allons donc utiliser Cloudwatch pour visualiser et superviser le pourcentage de stockage utilisé pour chaque volume EBS, n’est-ce pas ? Faux. Vous n’aurez aucun problème à déterminer le volume, mais aucune métrique ne vous indique quel pourcentage vous en utilisez. Aïe !
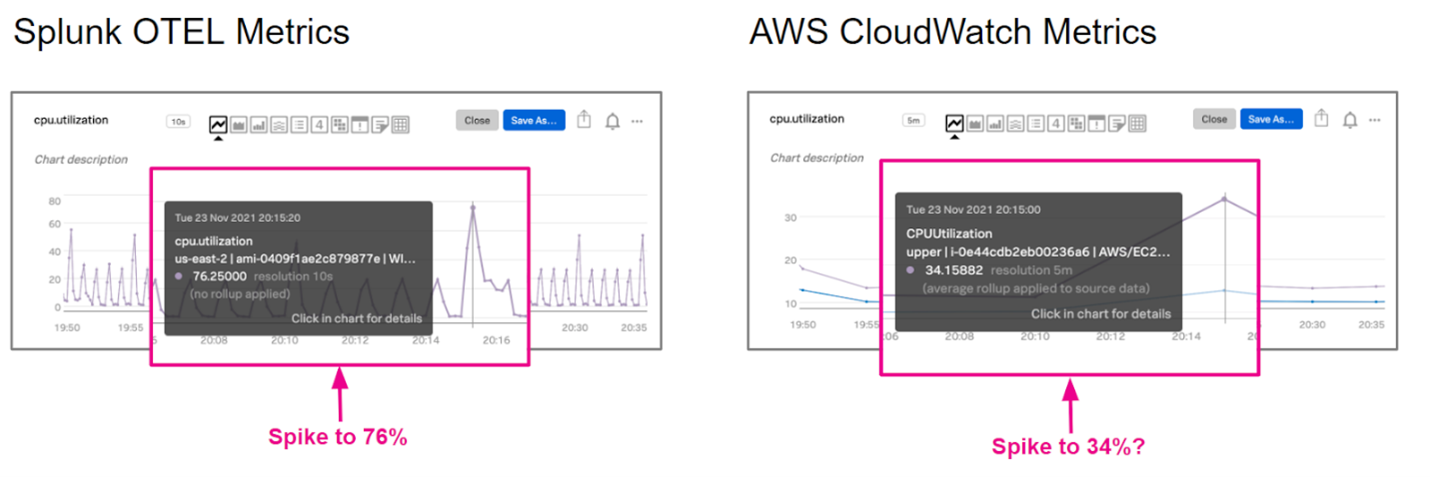
Figure 5 : Graphique comparant les métriques Splunk Open Telemetry (OTEL) et les métriques AWS CloudWatch
Étant donné que Splunk domine indéniablement ce domaine, je vais tout de suite le dire... L’inspection et l’analyse des logs permises dans l’outil de supervision de votre fournisseur cloud vous laissera rapidement sur votre faim. Vous aurez accès à une collecte, des recherches et des informations de base, mais pour réaliser des investigations approfondies et bénéficier d’une couverture à l’échelle de l’environnement, il faut des capacités avancées de collecte, d’analyse et de recherche que l’on ne trouve que dans Splunk. Donnons quelques exemples concrets.
Supposons que vous souhaitiez déterminer si du code déployé récemment cause de nouveaux problèmes dans l’environnement. Une technique analytique avancée consiste à rechercher les traces récentes dans la pile, mais cela peut être délicat. Comment savoir quand une trace de pile est identique à une autre ? Avec du SPL bien pensé, c’est assez facile à détecter.
Supposons que vous souhaitiez déterminer si des données de bucket S3 ont été configurées par inadvertance comme accessibles au public. Sans Splunk, cela peut être difficile ! Mais avec le puissant langage de recherche de Splunk, nous pouvons collecter les logs d’accès S3, les enrichir avec une recherche de géolocalisation et les représenter sur une carte par nom de bucket S3.
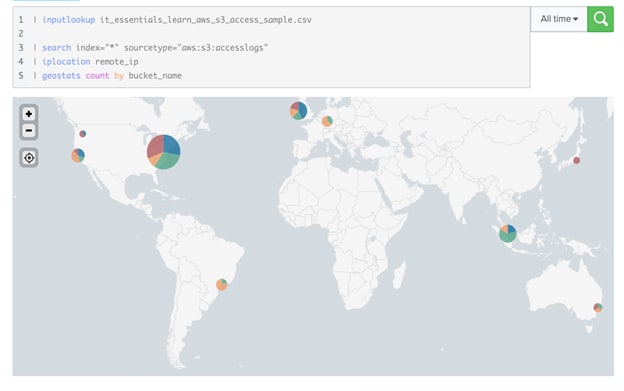
Figure 6 : Recherche et visualisation de géolocalisation AWS S3 dans un tableau de bord Splunk

Figure 7 : Détails de la recherche de trace dans Splunk

Figure 8 : Détecter les traces et identifier les tendances dans Splunk
Dernier point, vous devriez normalement savoir que l’acquisition des données n’est qu’une première étape. C’est dans la façon dont vous utilisez les données que réside la véritable valeur. Si les fournisseurs de cloud facilitent la collecte de données à partir de leurs services et proposent souvent des tableaux de bord spécifiques à un domaine, la corrélation et l’affichage des données sur différents services restent en grande partie un processus manuel. De plus, chaque application et son architecture sous-jacente sont uniques : il peut donc être ardu de créer des visualisations utiles incluant de nombreuses sources de données différentes.
Splunk Infrastructure Monitoring (SIM) et Splunk Application Performance Monitoring (APM) fournissent des workflows prêts à l’emploi pour vos données critiques, quelle que soit leur origine. Vous pouvez ainsi les utiliser immédiatement à l’aide d’analyses contextuelles, pour un retour sur investissement rapide et une exploitation optimale de la valeur de vos données. Les tableaux de bord prêts à l’emploi peuvent en outre être utilisés comme modèles pour passer de façon harmonieuse d’un tableau de bord spécifique à un domaine à une vue de bout en bout hautement corrélée de vos services critiques. Vous pouvez facilement copier des graphiques et autres visualisations à partir de tableaux de bord disparates et les coller dans des tableaux de bord personnalisés et optimisés pour l’action. Ces tableaux de bord peuvent ensuite être partagés avec d’autres et inclus dans des collections par équipe pour fluidifier la collaboration.
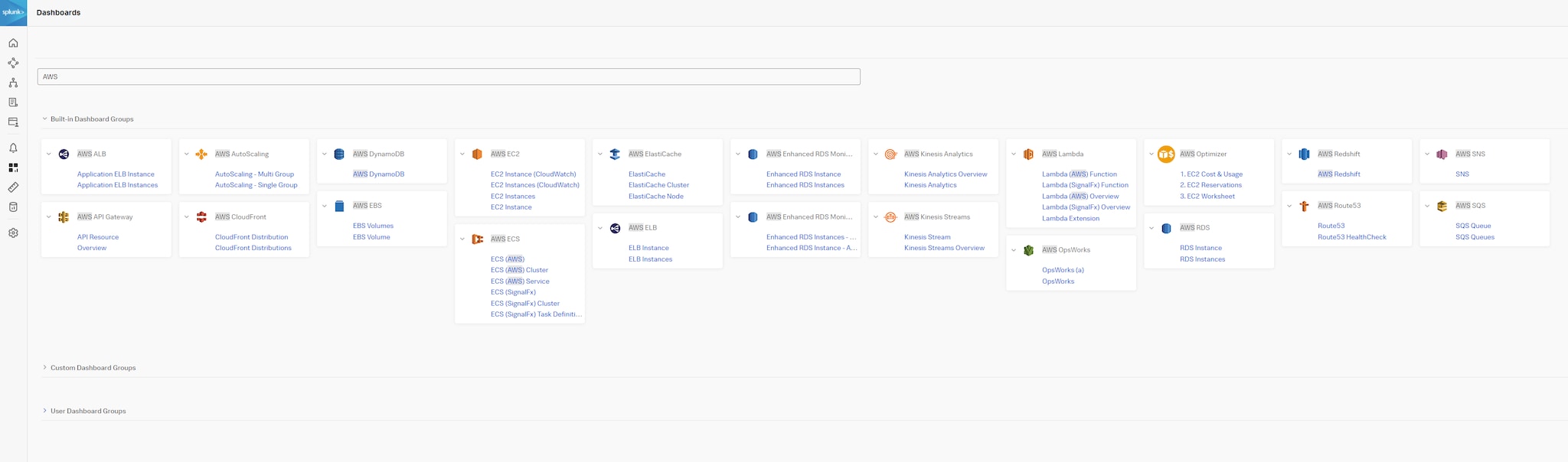
Figure 9 : Groupes de tableaux de bord AWS intégrés dans Splunk Observability Cloud
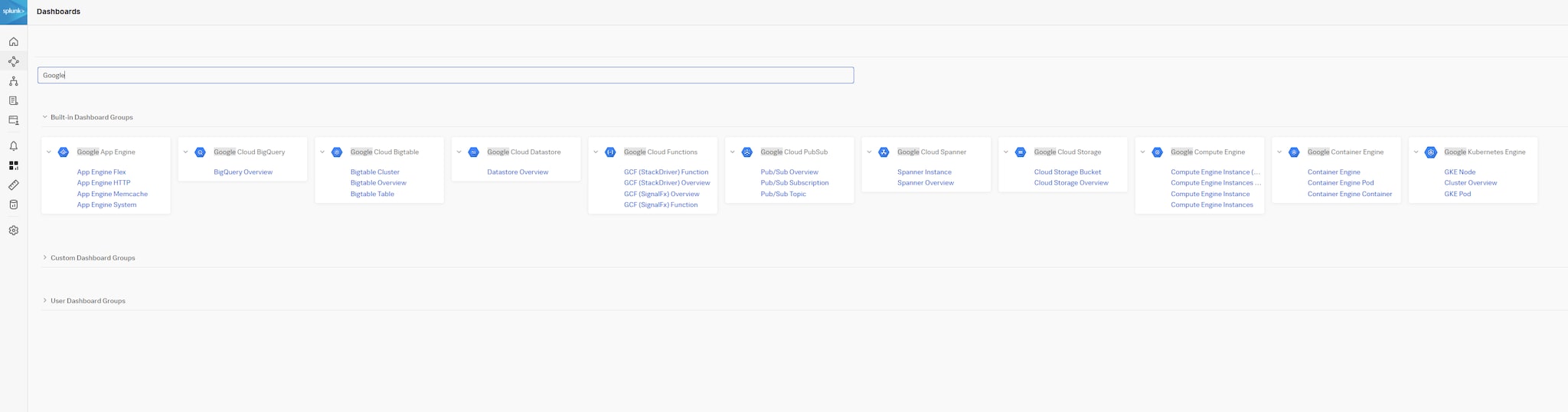
Figure 10 : Groupes de tableaux de bord Google Cloud Platform intégrés dans Splunk Observability Cloud
Figure 11 : Groupes de tableaux de bord Azure intégrés dans Splunk Observability Cloud
L’objectif principal des fournisseurs de cloud est de proposer une infrastructure, des plateformes et des logiciels en tant que service. Assurer une supervision efficace de cette infrastructure est, au mieux, un objectif secondaire. Nous le constatons depuis des années au fil de l’émergence de nouvelles technologies, et il n’y a aucune raison de croire que les fournisseurs de cloud se distinguent dans ce domaine. Chez Splunk, notre objectif principal est de collecter, interroger, analyser et superviser efficacement tous les types de données machine afin que vous puissiez les transformer en actions.
Pour savoir comment Splunk peut aider vos équipes IT, CloudOps et DevOps à observer et analyser de manière proactive l’évolution de votre parc cloud, consultez notre page Splunk Observability Cloud.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.