
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

Le Lundi avec Landy est le nom de notre nouvelle série de podcasts vidéo dédiés à l’ITOps et à l’observabilité. L’objectif ? Vous proposer un contenu pertinent en 15 minutes maximum, sur des thématiques variées : découverte de produits Splunk, sujets techniques, expériences clients… Cette fois, je vous propose de plonger dans les solutions d’observabilité de Splunk. Vaste programme en 15 minutes chrono 😎!
Je vous emmène au cœur de l’offre ITOA de Splunk, afin de comprendre de quelle manière elle permet aux opérateurs d’investiguer les causes profondes des incidents qui surviennent dans l’environnement dont ils ont la responsabilité.
Dans cet épisode, je me mets dans la peau d’un opérateur responsable d’un environnement TMI ayant bénéficié de l’installation de la solution d’observabilité de Splunk. Je me lance ici dans l’investigation d’un incident au moyen de plusieurs briques de la suite Observabilité de Splunk :
Mais avant toute chose, posons-nous les bonnes questions, qui détermineront notre capacité à résoudre les problèmes lorsqu’ils se présentent. Comment sommes-nous informés de l’existence d’une défaillance ? Quel est le système d’alerte existant et comment fonctionne-t-il ? Comment accéder aux événements pour les analyser ?
La solution habituelle consiste généralement en un système d’envoi de notifications par e-mail, associé à des bacs à événements. Nous pouvons également, comme dans cette vidéo, utiliser un autre outil de communication, tel que Slack. Avec cette plateforme, il est possible, par exemple, de créer un canal spécifique pour l’envoi et la réception de toutes les alertes relatives à l’environnement technique de l’opérateur.
Voyons comment cela se passe concrètement avec la suite d'observabilité de Splunk.
Me voilà dans la peau d'un opérateur. Je reçois une alerte relative et en consulte les détails. En l’occurrence, je constate que l’incident affiche le statut « Critique » et concerne des moniteurs de type API.
Je me connecte à l’environnement On-Call, l’outil de travail collaboratif de Splunk. Outre l’affichage des détails de l’incident, cet outil propose les fonctionnalités suivantes :
On-Call permet également d’aller un peu plus loin et d’obtenir davantage d’informations sur l’environnement concerné. Pour cela, je peux consulter en un clic le bac à événements de Splunk ITSI, où je retrouve mon incident et tous les événements qui y sont associés, regroupés sous la forme d’un « épisode ». Je trouve aussi l’arborescence de l’environnement ainsi que des tableaux de bord qui me permette de pousser plus avant mon investigation.
En étudiant les différents indicateurs affichés par ITSI, il est possible de mettre en lumière l’ensemble des défaillances de l’environnement TMI et d’identifier l’origine des problèmes. Dans l’exemple que je vous propose, il s’agit du KPI « payment service », qui concerne des transactions en ligne.
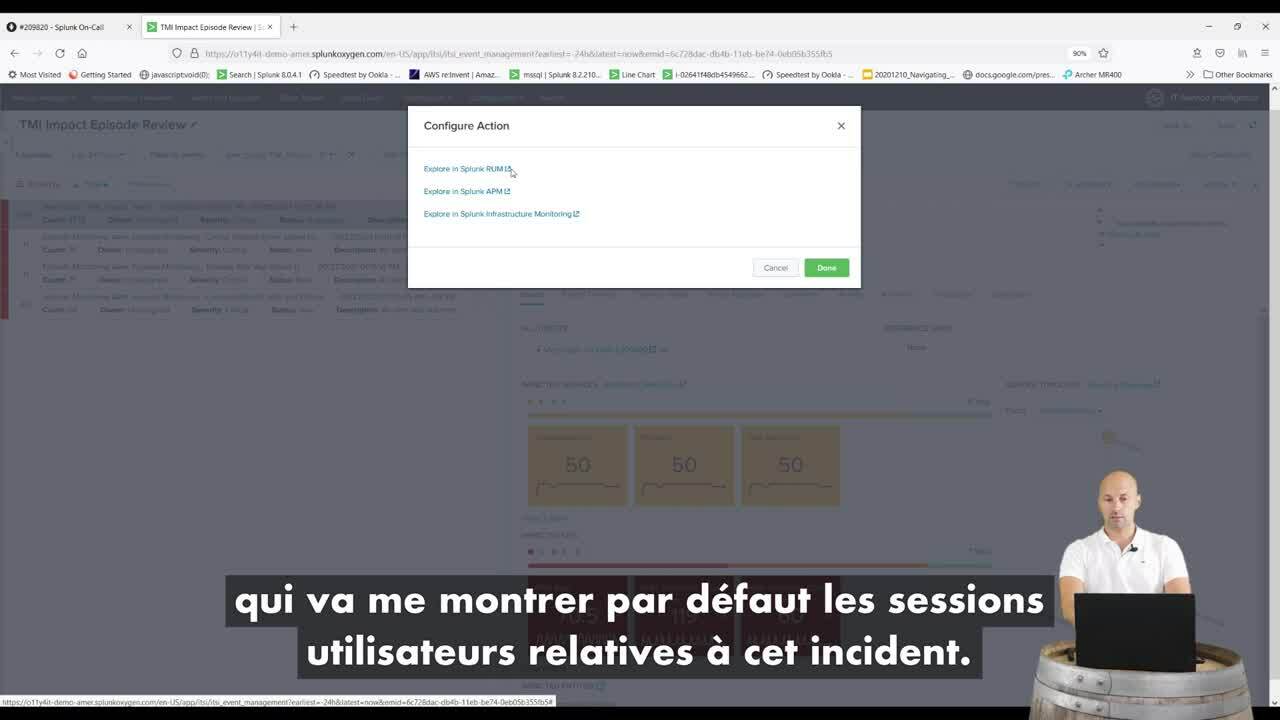
Des liens directs vers les autres briques permettent de se connecter directement à l’environnement dans lequel des éléments problématiques ont été mis au jour. Ici, je peux accéder à RUM (Real User Monitoring) afin de visualiser les différentes sessions utilisateur défaillantes.
À ce stade, une visualisation temporelle permet de sélectionner, parmi toutes les sessions, celles qui présentent des temps de réponse dégradés, et d’identifier les actions les plus chronophages.
Maintenant que nous savons où le bât blesse, nous pouvons cliquer directement sur un lien redirigeant vers l’APM (Application Performance Monitoring) et analyser la trace de ces appels de pages.
Dans la brique APM, les défaillances sont mises en évidence dans une arborescence représentant l’ensemble de l’environnement IT. Parmi les informations disponibles, je peux notamment prendre connaissance du taux d’erreur en fonction du nombre de requêtes. Autant de données qui permettent de bien affiner mon diagnostic !
Maintenant, poussons l’investigation jusqu’au bout, et consultons les logs…
Des liens directs permettent de basculer dans Log Observer, qui liste tous les journaux relatifs aux différents pods. Je peux alors choisir le type de données à afficher, agir sur certains champs (notamment en appliquant des filtres et des exclusions) et identifier le ou les pods présentant des erreurs.
Je peux alors analyser chaque événement et remonter à la cause profonde des défaillances. Dans l’exemple que je vous propose, un simple certificat SSL défectueux a entraîné le ralentissement d’un des pods et donc des temps de passage de commande en ligne anormalement longs pour l’utilisateur final.
Vous l’aurez compris, les solutions d’observabilité de Splunk sont vos meilleures alliées pour comprendre les incidents survenant dans votre environnement. Et plus encore : elles permettent de mieux les anticiper.
Outre une analyse particulièrement fine des incidents et l’identification de leurs causes profondes, la suite d'observabilité de Splunk permet ensuite, via les tableaux de bord de l’environnement APM, de créer de nouvelles alertes associées au métrique identifié comme défaillant. Par exemple, je peux créer un seuil de taux d’erreur qui entraînera le déclenchement d’une alerte et régler de manière fine les paramètres de l’alerte en question (conditions de déclenchement et de réinitialisation, personnalisation du message…). Ainsi, la prochaine fois, je pourrais intervenir plus rapidement en cas de nouvelle dégradation des temps de réponse.
Quant à l’incident rencontré, une fois le problème solutionné, il suffit d’indiquer l’alerte comme « Résolue » dans On-Call pour le clôturer automatiquement. C'est pas si sorcier ?
Vous voulez tout savoir sur l’observabilité et ses bénéfices pour votre activité ? Téléchargez le guide Splunk Boostez votre supervision IT grâce à l’observabilité.
Rendez-vous très bientôt pour une nouvelle session consacrée à l’ITOps avec Splunk ! Pour toute suggestion de sujets, contactez-moi sur LinkedIn.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.