
Créer une pratique d’observabilité de pointe

« Comment transformer nos données DevOps en données DevSecOps utiles ? Il y en a tellement ! Elles arrivent de n’importe où ! Dans toutes sortes de formats différents ! »
Tout cela est vrai. Mais heureusement, on peut dégager certaines similitudes dans les différentes phases du cycle de vie DevOps, qui peuvent être mises à profit pour interpréter et unifier toutes ces données. Comment mettre de l’ordre dans ce chaos ? En imitant les scientifiques qui étudient des phénomènes complexes et en élaborant un modèle conceptuel des données. En modélisant des idées communes à partir des différents segments du cycle de vie DevOps, de la planification à la publication, vous augmenterez l’observabilité de vos processus DevOps, fondement des pratiques DevSecOps.
Vous ne pouvez pas développer une pratique DevSecOps si vous n’avez pas la possibilité d’exploiter toutes vos données DevOps, quels que soient l’outil et le fournisseur dont elles proviennent. Ce principe a d’ailleurs une telle importance qu’il est rappelé dans le premier paragraphe du document Défense des environnements d’intégration continue/de livraison continue (CI/CD) de la NSA. L’objectif de ce document est d’intégrer « les bonnes pratiques de sécurité dans les environnements typiques d’intégration continue/de livraison continue (CI/CD) pour le développement et l’exploitation de logiciels (DevOps), quels que soient les outils choisis » – ce qui représente un enjeu majeur pour la pratique DevSecOps.
Cette série d’articles de blog sur la modélisation des données DevOps vous aidera à établir des concepts et des liens communs à différentes étapes du SDLC, afin de les exploiter au sein d’un modèle de données DevOps. Ce modèle de données peut ensuite être utilisé pour unifier les données DevOps dans leur ensemble et faciliter leur exploitation avec d’autres modèles de données plus traditionnels axés sur la sécurité (comme le modèle de données unifié CIM de Splunk). Commençons donc par décomposer une partie des éléments et points communs à différentes phases du cycle de vie DevOps, en commençant par la planification du travail. Nous aborderons ensuite le code, la compilation et la publication dans de prochains articles.
La planification du travail pour les projets logiciels s’intéresse généralement aux projets, aux epics, aux problèmes, aux tickets, etc. Quel que soit l’outil, les plateformes de planification Agile utilisent toutes des concepts communs qui reposent sur la méthodologie Agile et facilite son utilisation dans les organisations logicielles. Les epics, les problèmes, les tâches, les tickets, etc. sont les objets qui constituent la base de la plupart des workflows Agile (Sprint, Kanban et autres). Ces objets nous permettent de dégager des points communs au sein des données, quelle qu’en soit la source.
On retrouve ces points communs dans Jira, les projets Github, Trello et autres. Les modèles dédiés à ces types de données peuvent utiliser ces points communs comme champs pour mapper les données provenant de sources disparates et produire une source de données plus unifiée et facile à exploiter. Par exemple, si Jira nomme l’identifiant de l’objet « IssueID », que GitHub l’appelle « IssueNumber » et Trello, « CardNumber », ces trois champs peuvent être simplement mappés à « issueNumber » dans le modèle de données. Désormais, les objets présents dans chacun de ces outils peuvent être retrouvés à l’aide de recherches utilisant le champ « issueNumber ». En ajoutant un champ d’identification de référentiel unifié tel que « repository_name », on aura également la possibilité de voir tous les objets de travail d’un référentiel donné pendant une période de temps spécifiée.
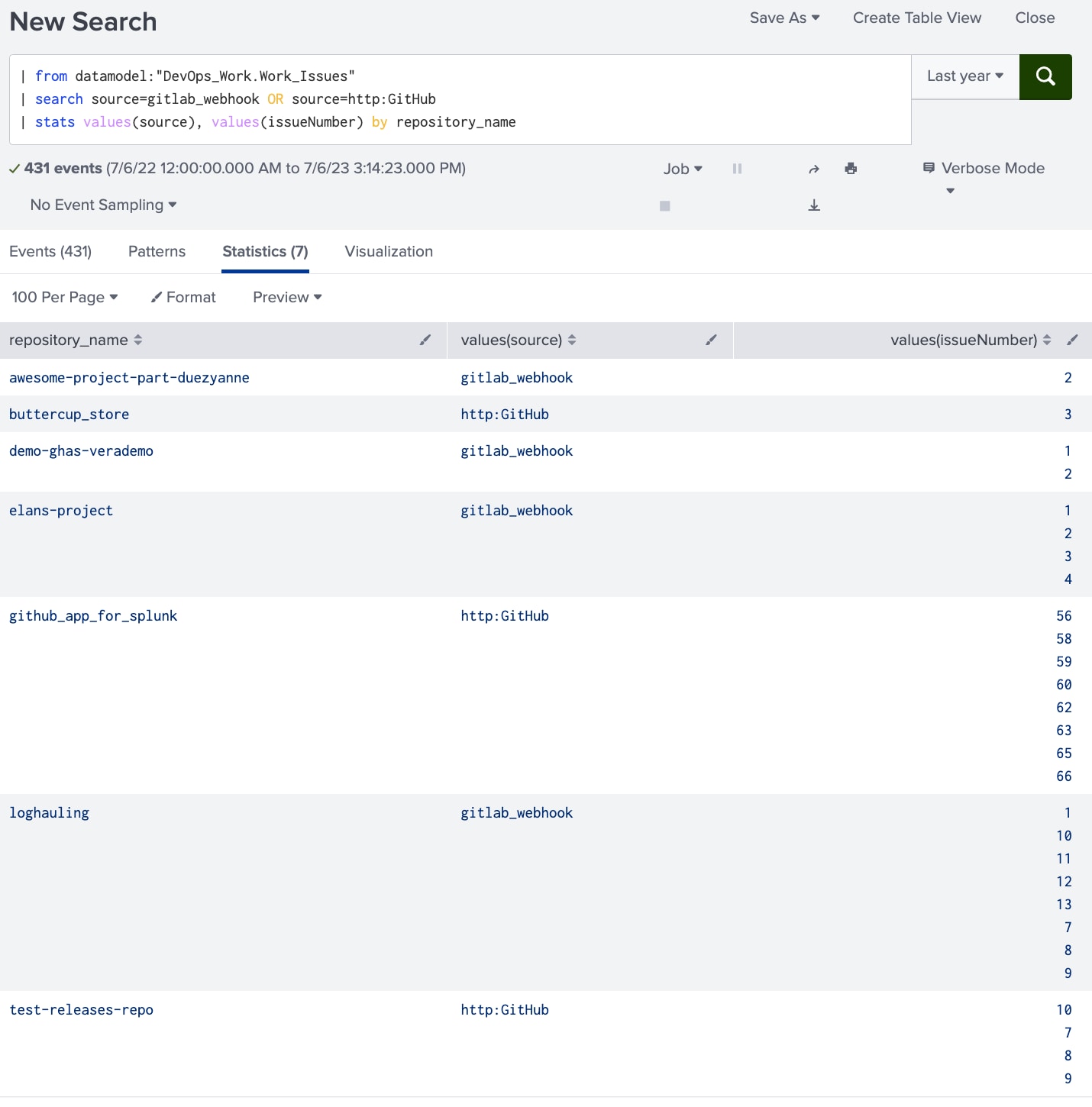
Figure 1-1. Une simple recherche Splunk peut mettre en évidence le travail effectué au cours de l’année écoulée dans divers référentiels et à l’aide de divers outils. On pourrait ajouter à la recherche un champ unifié comme status_current pour renvoyer uniquement les tickets qui ont été fermés au cours de l’année précédente ou qui sont actuellement ouverts.
De plus, lorsque l’on planifie un travail dans des référentiels de code, l’ajout du nom du référentiel de code, de la branche et d’autres informations aux objets de planification devient incroyablement utile ! Certains outils fournissent des solutions spécifiques pour référencer des objets de planification, d’autres non. Mais dans tous les cas, ces données peuvent être déduites par d’autres moyens en référençant et en analysant le numéro de l’objet de travail dans une description de validation ou de demande d’extraction.
Dès lors que les données du référentiel référencent les objets de planification dans les événements au niveau du code (validations, demandes d’extraction), on peut tracer une ligne du travail au code, de la conception à la livraison et de l’idée à la réalité. Les points communs des données de code peuvent même être utilisés pour retracer le cycle de vie du développement logiciel (SDLC) jusqu’à la compilation et la publication. Le nom du référentiel, les identifiants de problème, les hachages de validation, les branches, les événements de fusion et autres données spécifiques au code fournissent les liens nécessaires pour savoir quel code est en cours de compilation, publié et même en cours d’exécution dans votre environnement logiciel.
Lorsque l’on crée ce type de mappages, ne serait-ce que pour les données de planification du travail mentionnées ci-dessus, on peut alors suivre le qui, le quoi, le où, le quand et le pourquoi d’un travail, quels que soient les outils utilisés. L’équipe A utilise Jira et l’équipe B utilise GitHub ? Aucun problème, les données sont désormais unifiées et utilisables ! Les données de planification apportent une valeur immédiate et permettent de répondre à des questions telles que :
Autant de questions assez simples qui trouvent facilement une réponse dès que vous ajoutez ce type de données de planification DevOps à la boîte à outils de votre organisation.
En ajoutant des données provenant d’autres étapes de la chaîne d’outils DevOps, vous commencerez à obtenir une image plus complète du fonctionnement de votre organisation logicielle. Toujours en utilisant les points communs des données, il devient possible de suivre et déduire des métriques à chaque étape du cycle de vie du logiciel : délai de révision, temps de test et temps total depuis l’idée à la publication du code.
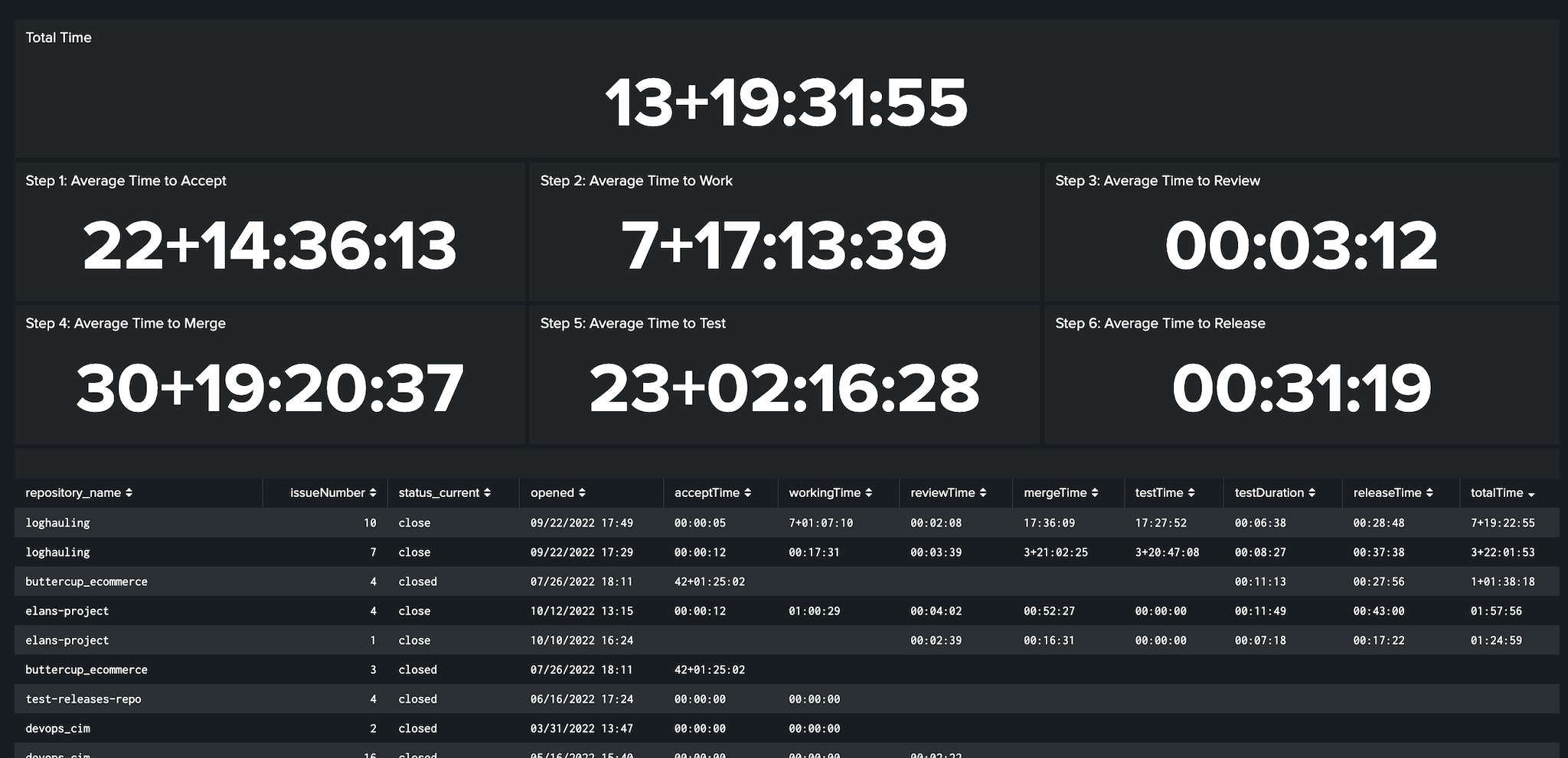
Figure 1-2. Aborder les DevOps avec un modèle unifié ouvre la voie à une analyse détaillée du cycle de vie de développement logiciel, de la planification du travail à la publication du code, quels que soient les outils et les plateformes.
C’est sans doute dans les liens établis entre les différents composants du SDLC (planification du code, des tests et de la publication dans notre cas) que se trouve l’essentiel de l’intérêt d’un modèle de données pour les DevOps. Mais en utilisant des points communs tels que le « IssueNumber », le nom du référentiel, la branche, le hachage de validation et le hachage de fusion comme champs de liaison tout au long du cycle de développement logiciel, de la planification à la supervision en passant par l’exploitation, vous serez mieux armé pour comprendre vos processus DevOps et informer directement les pratiques DevSecOps, qui ont besoin de ce type de données unifiées pour remplir leur mission et protéger les logiciels de l’organisation.
Vous voulez en savoir plus ? Vous voulez savoir quel type de données fournissent GitLab, GitHub, BitBucket, etc., et ce que ces données ont en commun ? Vous vous intéressez aux DevSecOps et à l’intersection des données de code DevOps et de la sécurité ? Ne manquez pas notre prochain article de blog pour en savoir plus sur les points communs des données DevOps liées au code. Vous y découvrirez notamment comment l’unification de ces données peut s’ajouter aux données de planification agile pour améliorer la résilience, la sécurité et l’observabilité de votre entreprise.
Vous souhaitez savoir comment Splunk gère les modèles de données ? Vous pouvez vous inscrire pour commencer un essai gratuit de Splunk Cloud Platform pour en faire l’expérience dès aujourd’hui !
Ce billet de blog a été rédigé par Jeremy Hicks, ingénieur en Solutions d’innovation de terrain pour l’observabilité du personnel chez Splunk, avec des remerciements particuliers à Doug Erkkila, David Connett, Chad Tripod et Todd DeCapua pour leur collaboration, leurs idées et l’aide qu’ils ont apportée au développement du concept de modèle de données DevOps.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.