
Gestion des données pour l’IA
Vos données sont-elles prêtes pour l’IA ? Découvrez les nouvelles règles de la gestion des données dans ce guide gratuit.

Comme vous le savez, j’ai une passion : transformer mon quotidien en data. Mon fils de 10 ans est un lecteur passionné et peut lire des dizaines de livres par semaine. Alors j’ai voulu mesurer ses lectures.
Mais avec l’âge et l’essor de l’IA, je suis devenu fainéant : je voulais à tout prix éviter les saisies laborieuses et les tableaux Excel remplis à la main. Mon objectif était d’aller au plus simple : un téléphone, une photo du livre, une note. C’est tout.
Et j’ai voulu aller encore plus loin en valorisant cet historique pour créer son propre bibliothécaire personnel grâce à un agent IA de recommandation basé sur son historique et ses goûts. Pour ce faire, j’ai choisi une approche 100 % locale et gratuite, en m’appuyant sur le trio technologique : n8n pour l’orchestration, Ollama avec de l’AI Vision pour l’analyse et Splunk pour l’historique.
Voici comment j’ai mis en place un système souverain capable de transformer une simple couverture de livre en data permettant de lui proposer sa prochaine lecture.
Avant d’entrer dans les flux, quelques mots sur l’infrastructure.
Pas de cloud, pas de serveurs surdimensionnés, pas d’API IA exposées sur Internet.
Tout tourne sur mon ordinateur personnel.
Ce choix du tout local garantit :
n8n est une plateforme d’automatisation open source permettant de connecter des applications, des API et des services via des workflows visuels.
Chaque workflow est composé de nœuds représentant :
C’est un outil particulièrement adapté pour orchestrer des processus métiers, intégrer de l’IA ou automatiser des tâches répétitives de manière fiable et scalable.
Pour analyser mes livres et sauvegarder l’historique de lecture, mon workflow sera le suivant :
Telegram → Extraction JSON → AI Vision avec Ollama → Splunk
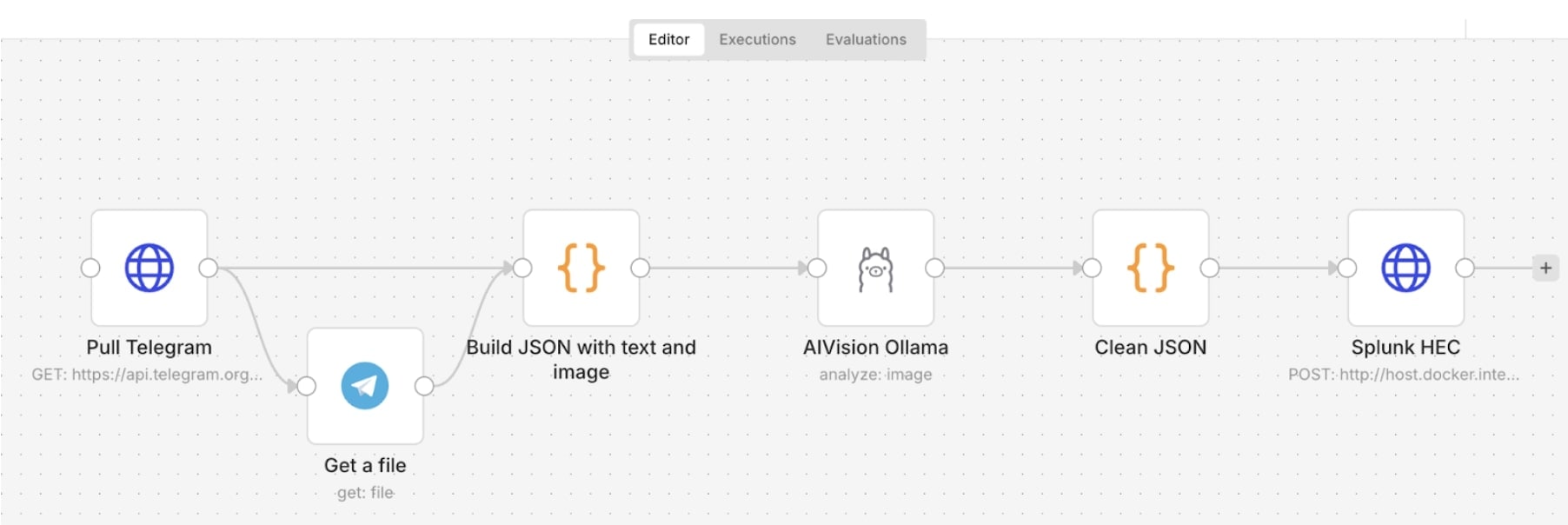
Voyons en détail ces composants :
J’utilise un bot Telegram privé. Pour contourner l’absence d’accès externe de mon instance n8n locale, j’utilise un nœud HTTP qui interroge l’API Telegram en mode PULL pour récupérer les derniers messages.
https://api.telegram.org/bot/getUpdates

Grâce au nœud Telegram de n8n et à l’option Get File, je récupère directement le flux binaire de l’image, prêt à être analysé.
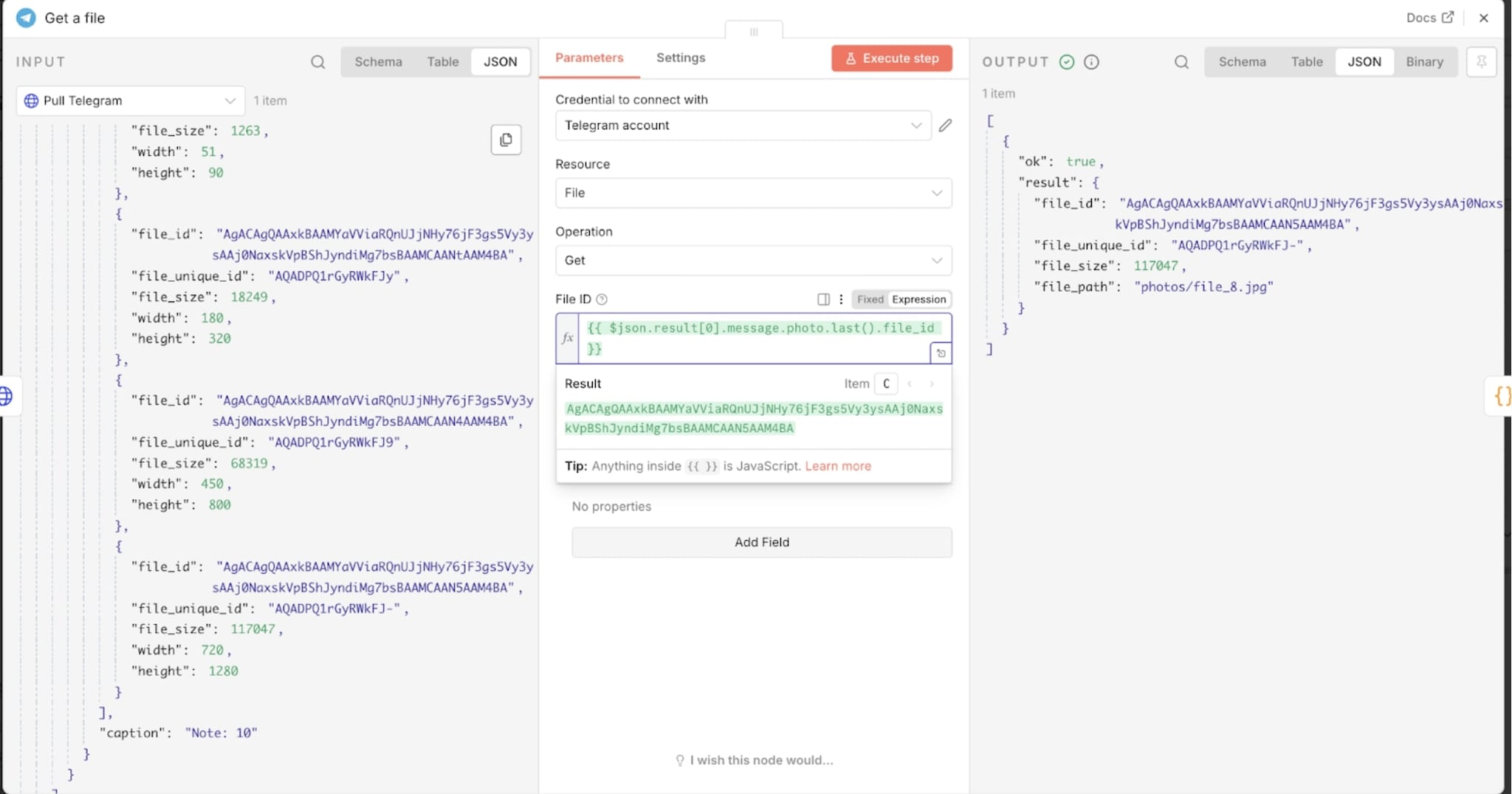
Dès que la photo arrive, n8n la transmet à Ollama via un modèle vision. L’IA va lire la couverture et en extraire toutes les métadonnées : titre, nom du tome, auteur.
Nous allons indiquer au nœud Ollama que nous traitons une image et sélectionner le modèle pertinent (que nous avons préalablement installé en local). J’ai testé llama3.2-vision.
Le défi ici est le prompt engineering : il faut être suffisamment précis pour obtenir un résultat pertinent malgré la diversité des graphismes des livres jeunesse.

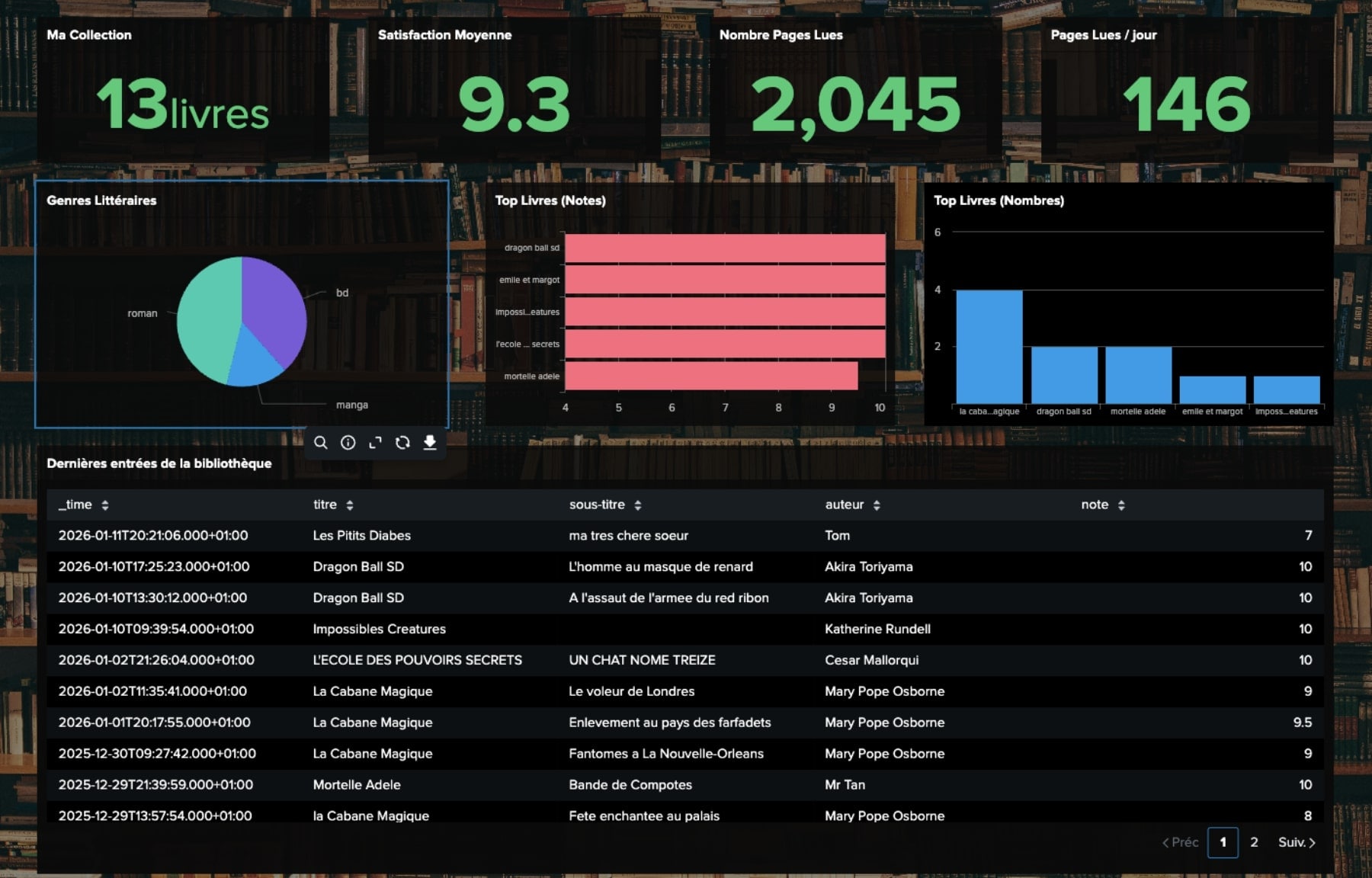
Une fois la donnée formatée en JSON, n8n la pousse vers Splunk via le HTTP Event Collector (HEC). Forcément, j’en profite pour Splunker quelques statistiques sur les habitudes de lecture via Dashboard Studio.
C’est ici que le projet bascule de l’archivage vers l’intelligence. Mon agent IA va suivre un cheminement similaire au flux précédent : Telegram (mot clé “Recommandation) → Lecture historique Splunk → Recommandation via IA → Retour dans Telegram
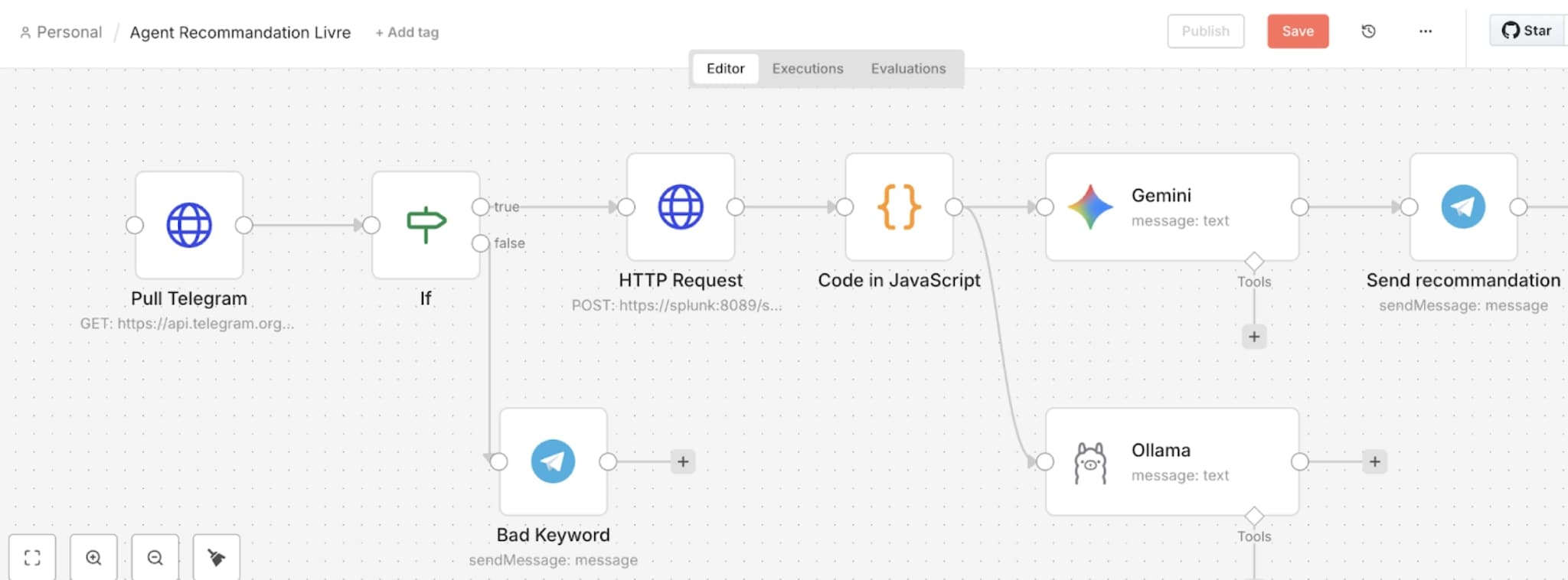
Comme pour notre cas précédent, le workflow n8n va surveiller les messages entrants. Si je tape le mot-clé « recommandation », le mode agent va s’enclencher.
n8n lance alors une requête HTTP vers l’API Splunk (via l’endpoint https://splunk:8089/services/search/v2/jobs/export). Il récupère l’historique des dernières lectures.
J’aurais également pu, dès cette étape, utiliser la commande | ai pour générer les recommandations directement dans Splunk, en reliant la plateforme à Ollama via l’application Splunk AI Toolkit.
J’ai toutefois choisi de centraliser l’ensemble de la logique dans n8n, afin de gérer plus facilement les paramètres, les prompts et les itérations au même endroit, et de conserver une orchestration unique et lisible.
Un bloc de code JavaScript dans n8n nettoie ce retour pour ne garder que l’essentiel (titres, dates, notes, auteurs, pages). On évite ainsi d’envoyer du « bruit » technique à l’IA.
Le cœur du système repose sur un agent capable d’analyser l’historique de lecture pour générer des conseils pertinents. La difficulté ici, en travaillant initialement sans cloud avec Ollama, a été de trouver un modèle capable de distinguer les nuances de la littérature jeunesse contemporaine.
Après de nombreux essais de modèles (Gemma 3, Mistral, Llama, Deepseek) le même constat s’imposait :
Pour avoir des recommandations pertinentes, j’ai finalement basculé vers Gemini 2.5 Flash (via l’API Google AI Studio). Ce changement s’est grandement ressenti sur la qualité des réponses :
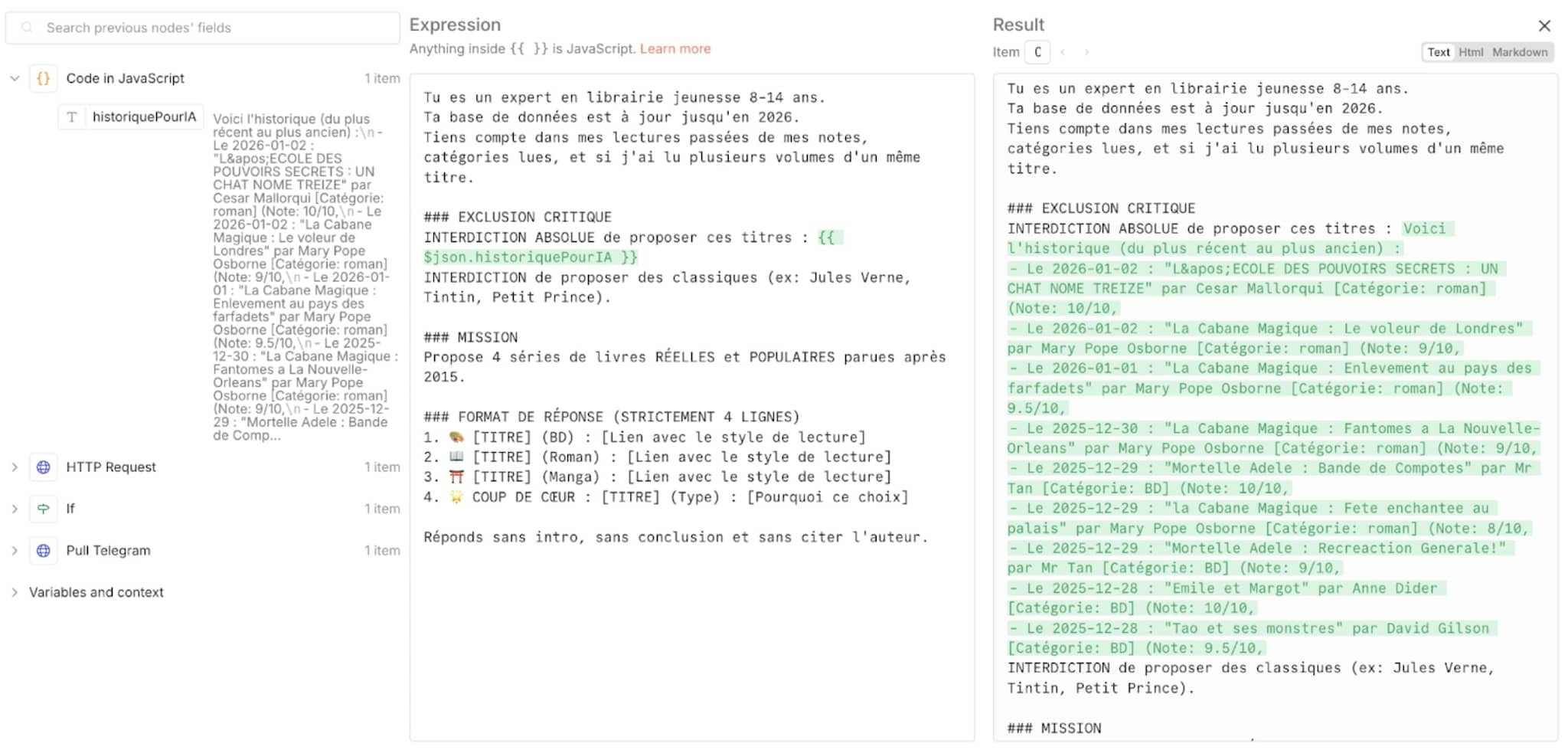
L’agent renvoie finalement sa réponse directement dans Telegram, avec :
Il n’y a plus qu’à ouvrir un nouveau livre !
Ce projet illustre un point essentiel dans les débats actuels autour de l’IA : le choix entre local et cloud n’est pas idéologique, il est contextuel.
Le local offre la maîtrise, la souveraineté et le contrôle des données.
Le cloud apporte la fraîcheur des connaissances, la fiabilité et la qualité des réponses.
Dans ce cas précis, le bon équilibre consiste à garder la donnée sensible et l’orchestration en local, tout en s’appuyant ponctuellement sur un modèle cloud lorsque la valeur métier l’exige.
L’agent IA joue ici un rôle clé. On ne parle plus simplement d’un modèle qui répond à une question, mais d’une IA agentique capable de :
C’est précisément cette logique d’agent qui transforme une simple automatisation en véritable assistant intelligent.
Enfin, ce cas d’usage domestique est volontairement simple, mais il est loin d’être anecdotique.
Les mêmes briques, ingestion, orchestration, stockage, agent IA décisionnel, sont directement transposables à l’entreprise pour de la recommandation, support utilisateur, analyse d’incidents, qualification de tickets, aide à la décision ou pilotage opérationnel.
Et vous ? Quel processus de votre quotidien, personnel ou professionnel, mériterait d’être confié à un agent IA ?
📌 ChatGPT et Splunk : l’IA combinée à la data pour une analyse automatique des logs ?
📌 Monitorer le prix de l’essence
📌 Télétravail : la data pour mesurer nos changements de rythme de vie
📌 Confinement : Splunker sa consommation Netflix
***
 Cet article est signé Thomas Labetoulle, Directeur conseil expert Observabilité chez notre partenaire CGI. Depuis 2017, il accompagne ses clients dans la mise en place de Splunk pour exploiter et valoriser leurs données et les accompagner dans leurs transformations vers l’observabilité.
Cet article est signé Thomas Labetoulle, Directeur conseil expert Observabilité chez notre partenaire CGI. Depuis 2017, il accompagne ses clients dans la mise en place de Splunk pour exploiter et valoriser leurs données et les accompagner dans leurs transformations vers l’observabilité.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.