
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

S plunk a connu une année d’innovation exceptionnelle et nous sommes ravis de présenter de nouvelles fonctionnalités pour aider les équipes DevOps, ITOps et de développement logiciel à créer, dépanner et innover plus rapidement. Nos clients se lancent dans des initiatives ambitieuses de modernisation IT, de migration vers le cloud et de modernisation des applications. La multiplication des données, des dépendances et des changements dans les environnements de production génère un nombre de scénarios d’échec dépassant les capacités d’anticipation des équipes, qui ont toujours plus de choses à superviser et à traiter.
plunk a connu une année d’innovation exceptionnelle et nous sommes ravis de présenter de nouvelles fonctionnalités pour aider les équipes DevOps, ITOps et de développement logiciel à créer, dépanner et innover plus rapidement. Nos clients se lancent dans des initiatives ambitieuses de modernisation IT, de migration vers le cloud et de modernisation des applications. La multiplication des données, des dépendances et des changements dans les environnements de production génère un nombre de scénarios d’échec dépassant les capacités d’anticipation des équipes, qui ont toujours plus de choses à superviser et à traiter.
Splunk Observability est la seule solution offrant : une visibilité de bout en bout sur les environnements hybrides, des capacités AIOps pour une corrélation complète des logs, des métriques et des traces afin d’anticiper et de prévenir les problèmes avant qu’ils n’affectent les clients, et un dépannage piloté par l’IA exploitant un modèle d’entité unifié qui analyse 100 % des données télémétriques non échantillonnées pour identifier les problèmes qui ont le plus d’impact sur les services et les clients.
Découvrons ensemble ces innovations, accompagnées d’un bref aperçu du contexte dans lequel elles s’inscrivent.
Il est difficile de mesurer l’impact de l’état de l’infrastructure et des performances applicatives sur l’expérience numérique de vos clients lorsque vous devez passer d’un outil à un autre ou à des expériences de supervision différentes. Avec l’intégration de l’observabilité dans la plateforme Splunk, Splunk est le seul à instrumenter l’ensemble de votre environnement technologique, qu’il s’agisse d’applications packagées fonctionnant sur site (comme les systèmes de traitement ou d’exécution des commandes de fournisseurs tiers) ou d’applications Web cloud-native sans échantillonnage. Ainsi, vous bénéficiez d’une visibilité de bout en bout et vous pouvez corréler rapidement les problèmes qui ont un impact sur plusieurs parties de votre pile logicielle entière.
Voici les dernières innovations :
Splunk Log Observer Connect est désormais disponible au grand public. Cette fonctionnalité de Splunk Log Observer connecte vos logs aux métriques et aux traces, vous aidant à déterminer quels logs dépendent de l’infrastructure et des applications lorsque vous analysez les problèmes de performance. Un contexte plus riche entre les métriques, les traces et les données de logs permet d’évaluer rapidement les problèmes dans les environnements de production, d’isoler la latence et d’identifier des détails granulaires pour comprendre la cause profonde plus rapidement.
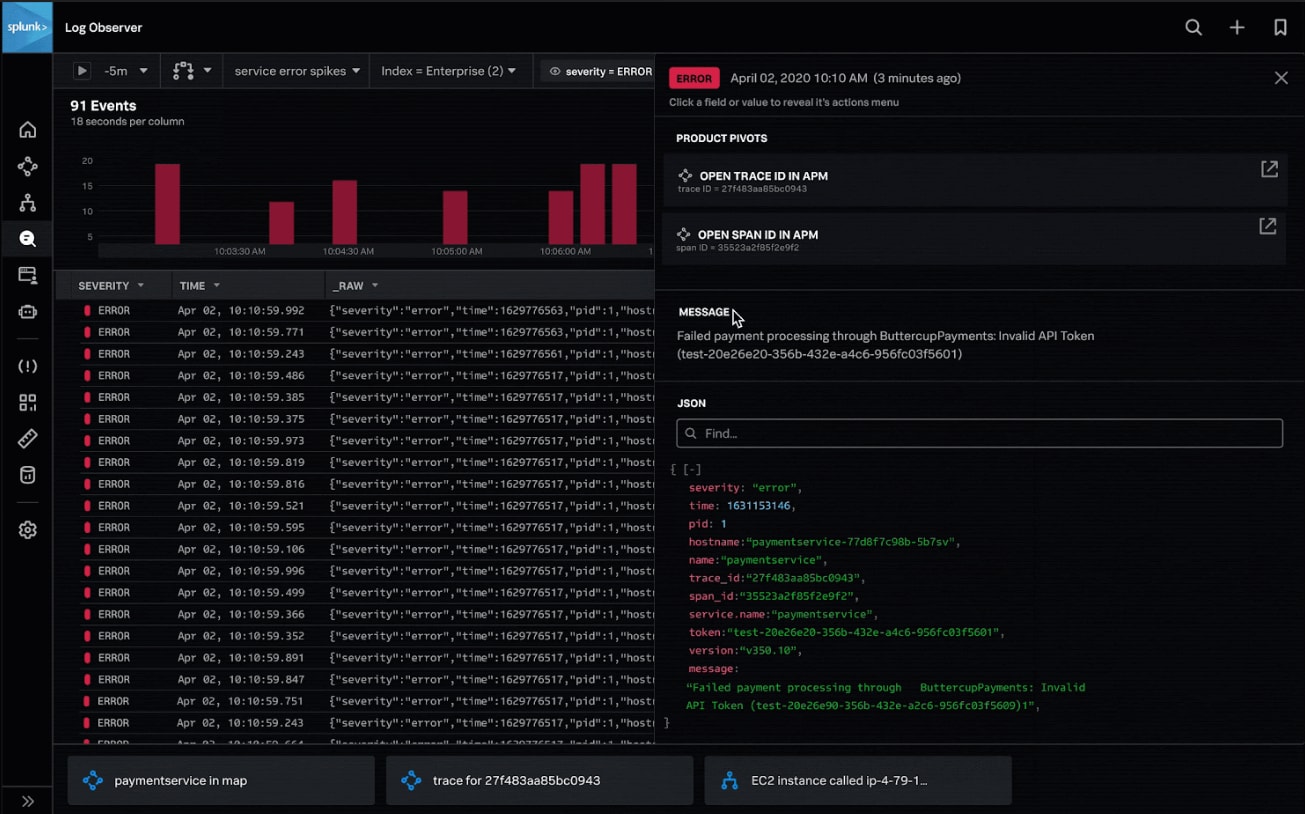
Log Observer Connect permet de réunir les données de logs, de métriques et de traces en contexte afin d’évaluer et d’isoler les problèmes de performance dans votre infrastructure et vos applications.
La version anticipée de Logs in Observability Dashboards est une autre fonctionnalité contribuant à faciliter la connexion des données de logs granulaires avec les métriques. Vous pouvez désormais combiner les logs et les métriques dans vos tableaux de bord Observability pour vous aider à évaluer la gravité et la portée d’un problème, et à analyser rapidement les causes possibles de manière plus détaillée.
Avec la version anticipée de l’auto-instrumentation des applications Java via le collecteur OpenTelemetry, vous pouvez commencer à diffuser leurs traces et superviser vos applications distribuées avec Splunk APM en quelques minutes seulement. Cette fonctionnalité réduit le temps nécessaire pour obtenir des données dans Splunk Observability Cloud, offrant une valeur immédiate sans aucune configuration pour l’instrumentation ou les agents de collecte de données.
La disponibilité générale de notre Infrastructure Navigator 2.0, basé sur Splunk Infrastructure Monitoring, offre une visibilité immédiate de l’ensemble de la pile sur les hôtes, les conteneurs, les bases de données et les services dans les environnements cloud hybrides. Les ingénieurs peuvent diagnostiquer rapidement les problèmes de fonctionnement et de performance de leur pile technologique grâce à une fonctionnalité facile à utiliser et à des barres latérales pivot conviviales, qui guident intelligemment les utilisateurs vers les problèmes de performance dans les environnements d’infrastructure complexes.
Il est impossible d’anticiper les inconnues lorsque vous ne comptez que sur les alertes pour savoir ce qui change. L’AIOps est intégrée à Splunk Observability, ce qui permet d’anticiper et de prévenir les problèmes avant qu’ils ne se transforment en incidents affectant vos clients.
Voici les dernières innovations :
Nous avons intégré nos fonctionnalités Synthetic Monitoring à Splunk Observability en version anticipée, pour vous aider à tester et superviser de manière proactive le temps de fonctionnement et les performances de vos API et services critiques, ainsi que l’expérience client, dans une interface utilisateur unifiée. Synthetic Monitoring dans Splunk Observability vous permet de détecter et de résoudre les problèmes avant que les clients ne soient affectés, avec un contexte transparent pour les performances côté client et back-end.
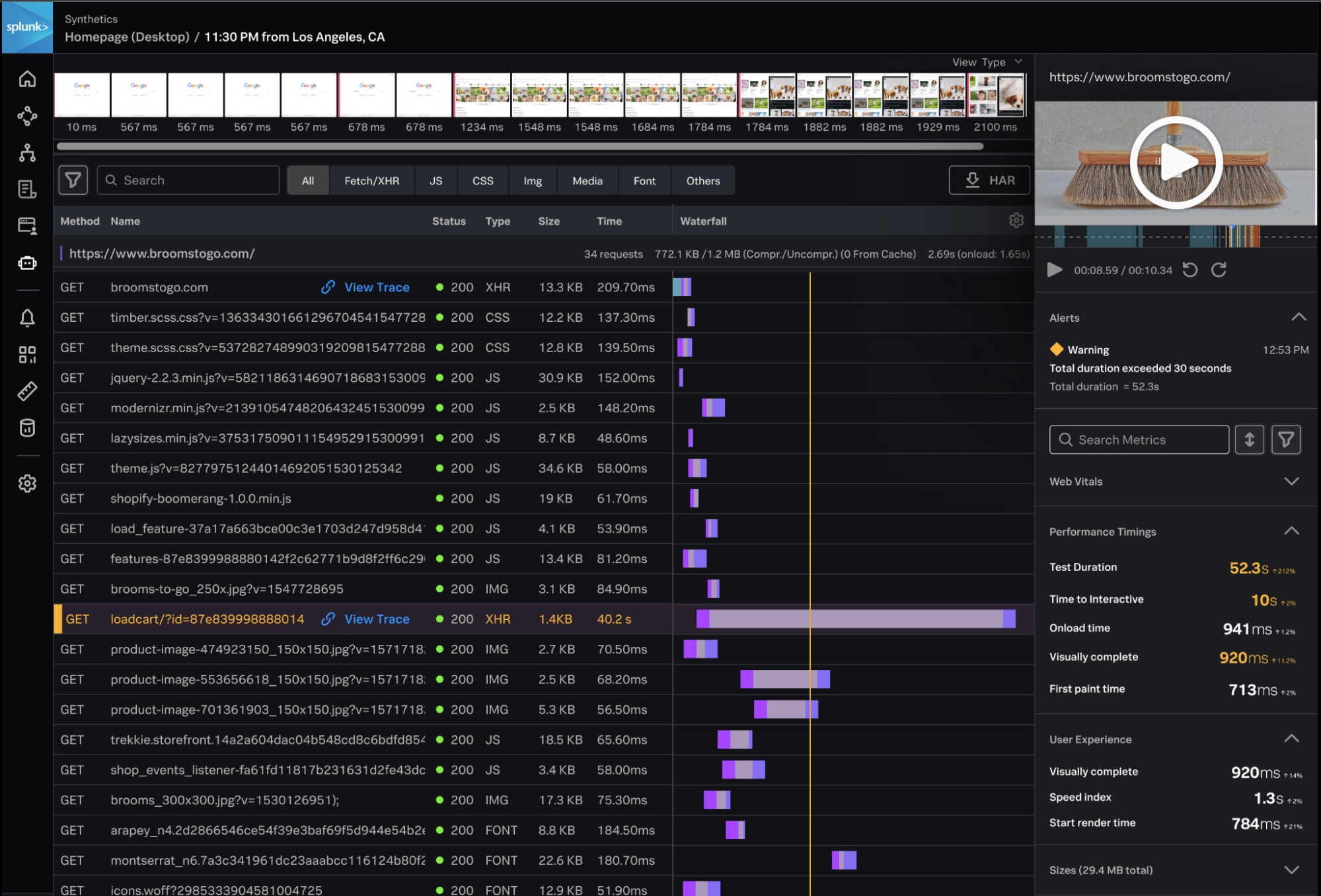
Dans Splunk Observability, la supervision synthétique de pointe fournit des ventilations complètes de la performance de la page, avec des pellicules et des vidéos pour visualiser l’expérience client
En ce qui concerne IT Service Intelligence (ITSI), nous avons pris en compte vos commentaires, et nous ajoutons trois fonctionnalités que vous avez jugées prioritaires sur ideas.splunk.com. Tout d’abord, la disponibilité générale de la version 2 du Content Pack Splunk Observability, qui inclut des Executive Glass Tables de pointe pour des résumés efficaces, ainsi qu’une navigation rapide depuis ITSI et IT Essentials Work vers Splunk Observability pour analyser plus en détail l’expérience de l’utilisateur final avec Splunk RUM, la performance des applications avec Splunk APM, et l’état de l’infrastructure avec Splunk Infrastructure Monitoring. La version anticipée de Custom Threshold Windows permet d’identifier le moment où un comportement anormal attendu peut survenir afin de réduire la saturation due aux alertes et de vous préparer aux changements à venir dans vos KPI et services. Notre Content Pack Service Now est désormais disponible au grand public. Cette fonctionnalité permet d’intégrer des données clés de vos instances ServiceNow, telles que les événements, les demandes de changement, les incidents et les applications commerciales, en les rendant facilement visibles et disponibles.
Pour les ingénieurs souhaitant comprendre et dépanner rapidement leur infrastructure, AutoDetect with Customization est également disponible. Cette fonctionnalité propose des intégrations et des flux de travail d’alertes intuitifs qui offrent une vue consolidée sur les alertes d’infrastructure, ainsi que des analyses de flux en temps réel pour détecter instantanément les motifs et anomalies critiques.
Difficile de trouver la cause profonde des problèmes quand il faut passer au crible une multitude de tableaux de bord pour tenter d’identifier les solutions possibles... autant chercher une aiguille dans une botte de foin. Splunk est la seule technologie à offrir une expérience de dépannage guidée qui inclut le contexte métier et vous indique où chercher lorsque vous analysez un problème, pour un MTTR plus rapide.
Voici les dernières innovations :
Nous annonçons la version anticipée de Splunk Incident Intelligence sur Splunk Observability Cloud, qui aidera les équipes IT et DevOps à éviter les interruptions non planifiées grâce à des alertes de type full-stack et full-context. Cette nouvelle solution réduit le nombre d’alertes lancées grâce à une corrélation prête à l’emploi pour les alertes Splunk et tierces, afin que les intervenants en cas d’incident puissent améliorer leur temps moyen de reconnaissance des problèmes. Incident Intelligence automatise l’ensemble du flux de travail de réponse aux incidents, de la planification aux examens post-intervention, et s’intègre à Slack, Microsoft Teams et ServiceNow pour améliorer la collaboration, la base de connaissances et le temps moyen de résolution des incidents.
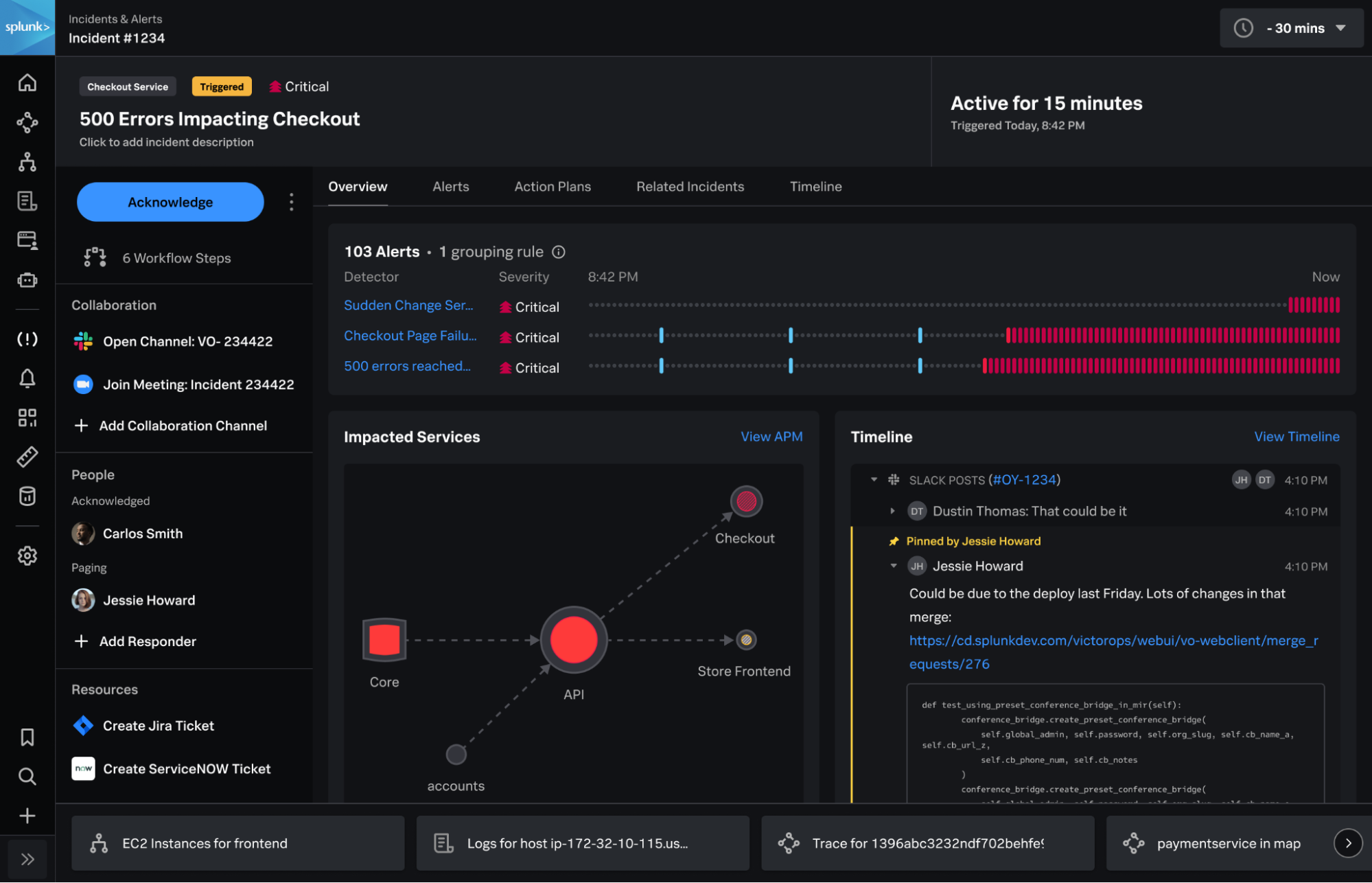
Splunk Incident Intelligence aide les équipes de réponse aux incidents à éviter les interruptions non planifiées et à réduire leur MTTR et résoudre les problèmes affectant les services critiques.
Nous étendons les capacités de la fonctionnalité AlwaysOn Profiling de Splunk APM pour superviser en permanence votre CPU et votre mémoire. Des versions anticipées sont disponibles pour le profilage CPU des applications Node.js et .NET, et le profilage de la mémoire des applications Java. Les ingénieurs peuvent désormais superviser en permanence les performances au niveau du code pour trouver les goulots d’étranglement dans vos applications Node.js et .NET, et comprendre l’impact du code sur l’utilisation de la mémoire dans les applications Java.
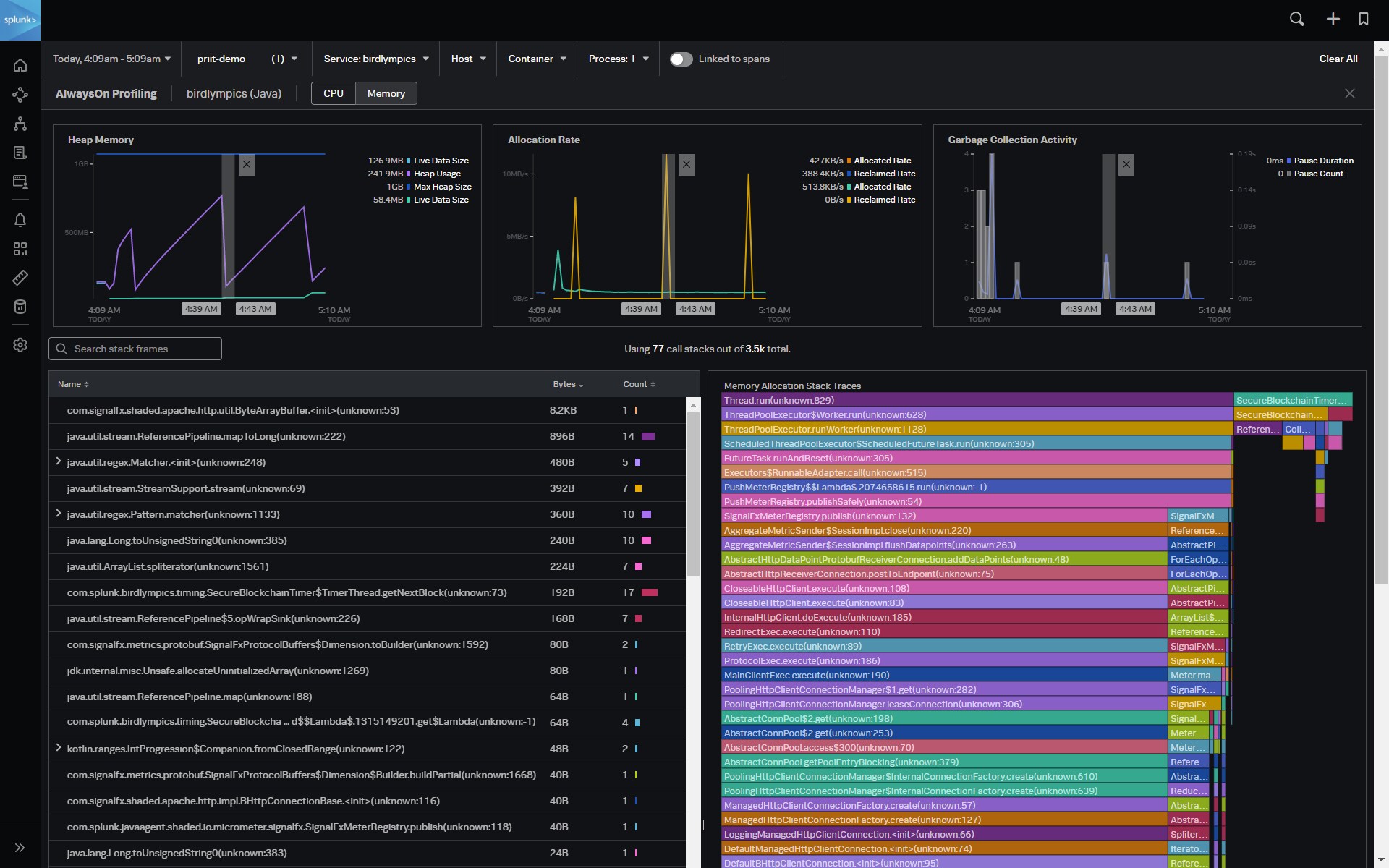
Le profilage de la mémoire AlwaysOn de Splunk APM permet d’identifier le code responsable d’une consommation élevée de mémoire
Nous vous encourageons à poursuivre votre aventure Splunk et à essayer nos capacités Observability. Que vous soyez un utilisateur actuel de Splunk cherchant à étoffer vos capacités de sécurité ou de journalisation de pointe, ou que vous souhaitiez unifier vos équipes informatiques et d’ingénierie sur une plateforme unique pour vos initiatives de modernisation IT, de migration vers le cloud ou de modernisation des applications, Splunk Observability vous aide à résoudre les problèmes plus rapidement, au fil de votre évolution.
Découvrez Splunk Observability dès aujourd’hui grâce à notre essai gratuit.
Suivez toutes les conversations liées à #splunkconf22!
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.