
Une feuille de route pour la résilience numérique des entreprises

Bonne nouvelle : l’application Deep Learning Toolkit for Splunk (DLTK) est rebaptisée Splunk App for Data Science and Deep Learning (DSDL). C’est un peu long, mais ce nom lui convient davantage car l’application est utile à la fois pour les opérations d’apprentissage profond et de science des données. Nouveau nom, nouvelles fonctionnalités, mais ce n’est pas tout : la Splunk App for Data Science and Deep Learning 5.0 est officiellement prise en charge par Splunk. Pour nos clients, c’est l’assurance d’obtenir une prise en charge rapide de leurs problèmes en ouvrant un ticket.
 Pour moi, c’est un énorme pas en avant. Lorsque j’ai commencé à travailler sur ce projet en 2018, c’est principalement la curiosité qui m’a amené à travailler avec des conteneurs Docker pour exécuter des modèles d’apprentissage profond sur des GPU et les connecter à Splunk. Le MLTK Container for TensorFlow a été annoncé lors de .conf en 2018, et l’application Deep Learning Toolkit for Splunk est en libre accès sur Splunkbase depuis .conf 2019. En 2020, une approche d’architecture d’application entièrement revue a été mise à disposition sur des sources ouvertes sous le nom de DLTK 4.0. Un grand merci à mon ami et ancien collègue Robert Fujara pour l’effort inestimable qu’il a apporté et qui a façonné l’avenir de cette application. Aujourd’hui, après presque 5 ans et plus de 7 000 téléchargements sur Splunkbase, le petit prototype est devenu une application largement utilisée pour intégrer des approches avancées de science des données, de machine learning et d’apprentissage profond avec Splunk. Ces progrès sont à mettre au crédit des contributeurs et des personnes en soutien qui ont tout apporté, des idées au code source. Un grand merci à vous tous. Je suis extrêmement reconnaissant pour toutes ces collaborations, donc si vous souhaitez qu’on travaille ensemble, n’hésitez pas à me contacter !
Pour moi, c’est un énorme pas en avant. Lorsque j’ai commencé à travailler sur ce projet en 2018, c’est principalement la curiosité qui m’a amené à travailler avec des conteneurs Docker pour exécuter des modèles d’apprentissage profond sur des GPU et les connecter à Splunk. Le MLTK Container for TensorFlow a été annoncé lors de .conf en 2018, et l’application Deep Learning Toolkit for Splunk est en libre accès sur Splunkbase depuis .conf 2019. En 2020, une approche d’architecture d’application entièrement revue a été mise à disposition sur des sources ouvertes sous le nom de DLTK 4.0. Un grand merci à mon ami et ancien collègue Robert Fujara pour l’effort inestimable qu’il a apporté et qui a façonné l’avenir de cette application. Aujourd’hui, après presque 5 ans et plus de 7 000 téléchargements sur Splunkbase, le petit prototype est devenu une application largement utilisée pour intégrer des approches avancées de science des données, de machine learning et d’apprentissage profond avec Splunk. Ces progrès sont à mettre au crédit des contributeurs et des personnes en soutien qui ont tout apporté, des idées au code source. Un grand merci à vous tous. Je suis extrêmement reconnaissant pour toutes ces collaborations, donc si vous souhaitez qu’on travaille ensemble, n’hésitez pas à me contacter !
Si la plupart des utilisateurs de Splunk préfèrent travailler avec l’interface de Splunk, et notamment la barre de recherche et les tableaux de bord, de nombreux data scientists préfèrent mener des expérimentations et des modélisations dans des notebooks Jupyter. DSDL permet de réunir les deux interfaces au sein d’un même workflow qui accélère et simplifie l’opérationnalisation de la science des données et des efforts de recherche au sein de Splunk.
Le langage de traitement de recherche (SPL) de Splunk peut être utilisé pour préparer des tâches de science des données spécifiques dans les frameworks et bibliothèques Jupyter et Python de votre choix, comme des visualisations avec matplotlib, seaborn ou autres. C’est le meilleur des deux mondes : la base SPL de Splunk avec la liberté d’extension de Python, pour réaliser des tâches de science des données dans Jupyter. L’architecture de base de DSDL ci-dessous n’a pas beaucoup changé, mais nous améliorons et étendons constamment les interfaces.
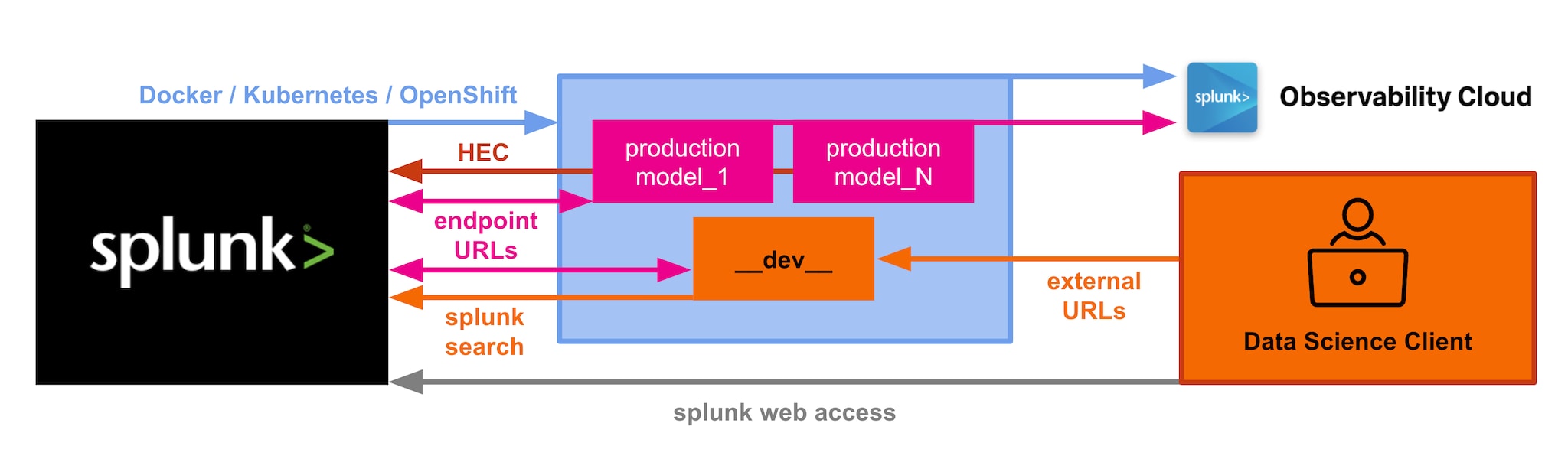
La version 3.9 introduit deux nouvelles fonctions utiles : une barre de recherche Splunk interactive dans Jupyter, ainsi qu’un moyen standard de journalisation et de renvoi direct de données provenant du code Jupyter ou Python vers Splunk via HEC. Testez le notebook Jupyter barebone_template.ipynb dans votre conteneur de développement pour voir ces fonctions en action. Du côté des algorithmes, un nouvel exemple de détection d’anomalies a été introduit avec la puissante bibliothèque PyOD. Pour renforcer le MLOps, une instrumentation automatisée de tous les modèles de conteneurs basés sur DSDL est disponible. Et si vous ajoutez vos métriques d’environnement, vous pouvez obtenir une image assez complète de vos opérations de science des données, de machine learning ou d’apprentissage profond dans la Splunk Observability Suite. Enfin, nous avons ajouté des options de configuration supplémentaires pour l’importation dans les déploiements Kubernetes, pour apporter davantage de transparence à l’utilisation en cluster des conteneurs Splunk et DSDL, par exemple avec le Splunk Operator for Kubernetes.
Avec la version 5.0, nous avons également résolu quelques problèmes pour sécuriser et rationaliser davantage les opérations avec DSDL. Avant tout, une documentation a été créée et ajoutée aux pages de documentation officielles de Splunk. Je tiens personnellement à remercier Emma Lauder et son équipe pour leur travail exceptionnel. Je crois sincèrement qu’elle comprend mieux le fonctionnement de DSDL que moi. La documentation a également conduit à une certaine restructuration du contenu de l’application pour rendre sa structure plus propre.
Dans cette nouvelle version, toutes les images de conteneur ont été actualisées pour intégrer les dernières mises à jour et les correctifs. Les clients nous ont souvent dit qu’ils avaient besoin de créer leurs propres images de conteneurs : nous avons donc introduit une nouvelle expérience de création d’images en un clic guidée par l’interface utilisateur, basée sur Docker. Grâce à cette fonctionnalité, les utilisateurs peuvent désormais créer leurs images de conteneurs et les adapter facilement à leurs bibliothèques de science des données Python habituelle. Nous avons également reçu des demandes d’outils pour construire plus facilement des réseaux de neurones. Dans la version 5.0, nous avons introduit la première itération d’un concepteur de réseau de neurones. Ce workflow prédéfini permet aux utilisateurs de Splunk de définir, créer, entraîner, appliquer et évaluer facilement des réseaux de neurones sur leurs données Splunk. J’espère que vous trouverez les nouvelles fonctionnalités utiles, mais si vous avez une suggestion : n’hésitez pas à soumettre une idée.
Enfin, nous avons ajouté une nouvelle façon d’appliquer des méthodes avancées de science des données à la cybersécurité. Mon collègue Josh Cowling a publié un notebook Jupyter et un exemple de tableau de bord Splunk dans DSDL qui montre comment les systèmes hôtes peuvent être mis en cluster à l’aide de la réduction de dimensionnalité UMAP sur les signatures JA3. Il s’agit de mieux comprendre les comportements et les anomalies associées, qui constituent de puissants indices pour les investigations dans le cadre d’attaques de la chaîne d’approvisionnement, comme décrit par l’équipe SURGe de Splunk. Merci à Marcus, Ryan et à toute l’équipe. Ne manquez pas le discours de Josh à la conférence SANS CyberThreat et retrouvez-le à Londres !
Pour finir, je dois absolument vous parler d’une nouvelle contribution visant à détecter les domaines DGA à l’aide d’un modèle pré-entraîné dans DSDL, dans les mises à jour de contenu de Splunk Enterprise Security. Cette nouvelle approche de la détection des DGA s’appuie sur un réseau de neurones large et profond. Je suis vraiment ravi de constater les progrès réalisés en matière de cybersécurité grâce aux techniques d’apprentissage profond de pointe en question. Un grand bravo à Namratha Sreekanta, Kumar Sharad, Glory Avina et à toute l’équipe de recherche sur les menaces de sécurité pour ce travail ! Et si je comprends bien, DSDL a aussi été intégré dans Attack Range ?! Merci à Patrick Bareiss, à Jose Hernandez et à l’équipe pour toutes ces fructueuses collaborations !
Comme vous pouvez le voir, l’application et la communauté autour de DSDL se développent. Si vous ne l’avez pas encore essayée, rendez-vous simplement sur Splunkbase et téléchargez-la gratuitement ou installez-la. Si vous connaissez déjà DSDL ou l’ancien DLTK et que vous l’utilisez déjà, n’hésitez pas à mettre à jour l’application. Pensez à sauvegarder et à faire des tests, en particulier si vous exécutez des opérations critiques avec DSDL dans des scénarios d’utilisation en production.
Bon Splunking et continuez à innover avec DSDL,
Philipp
Des remerciements particuliers à Emma Lauder, Namratha Sreekanta, Kumar Sharad, Glory Avina, Patrick Bareiss, Jose Hernandez, Josh Cowling, Marcus LaFerrera, Ryan Kovar, Greg Ainslie-Malik et tous les autres collègues de Splunk pour votre soutien et vos contributions à DSDL. Un grand merci à Judith Silverberg-Rajna, Katia Arteaga, Mina Wu et Carleanne O’Donoghue pour votre soutien dans la rédaction et la publication de cet article de blog.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.