
Une feuille de route pour la résilience numérique des entreprises
Dans la première partie de cette série d’articles de blog, nous avons présenté un scénario d’utilisation sur la façon dont le machine learning peut contribuer à améliorer les opérations policières. Ce scénario d’utilisation explique comment la planification des opérations peut être optimisée au moyen de techniques de machine learning à l’aide d’un jeu de données sur la criminalité à Chicago. Cependant, ce n’est pas le seul moyen de prédire et de prévenir la criminalité. Notre prochain exemple nous emmène à Londres pour découvrir les travaux de Paul McDonough et Shashank Raina du NCC Group.
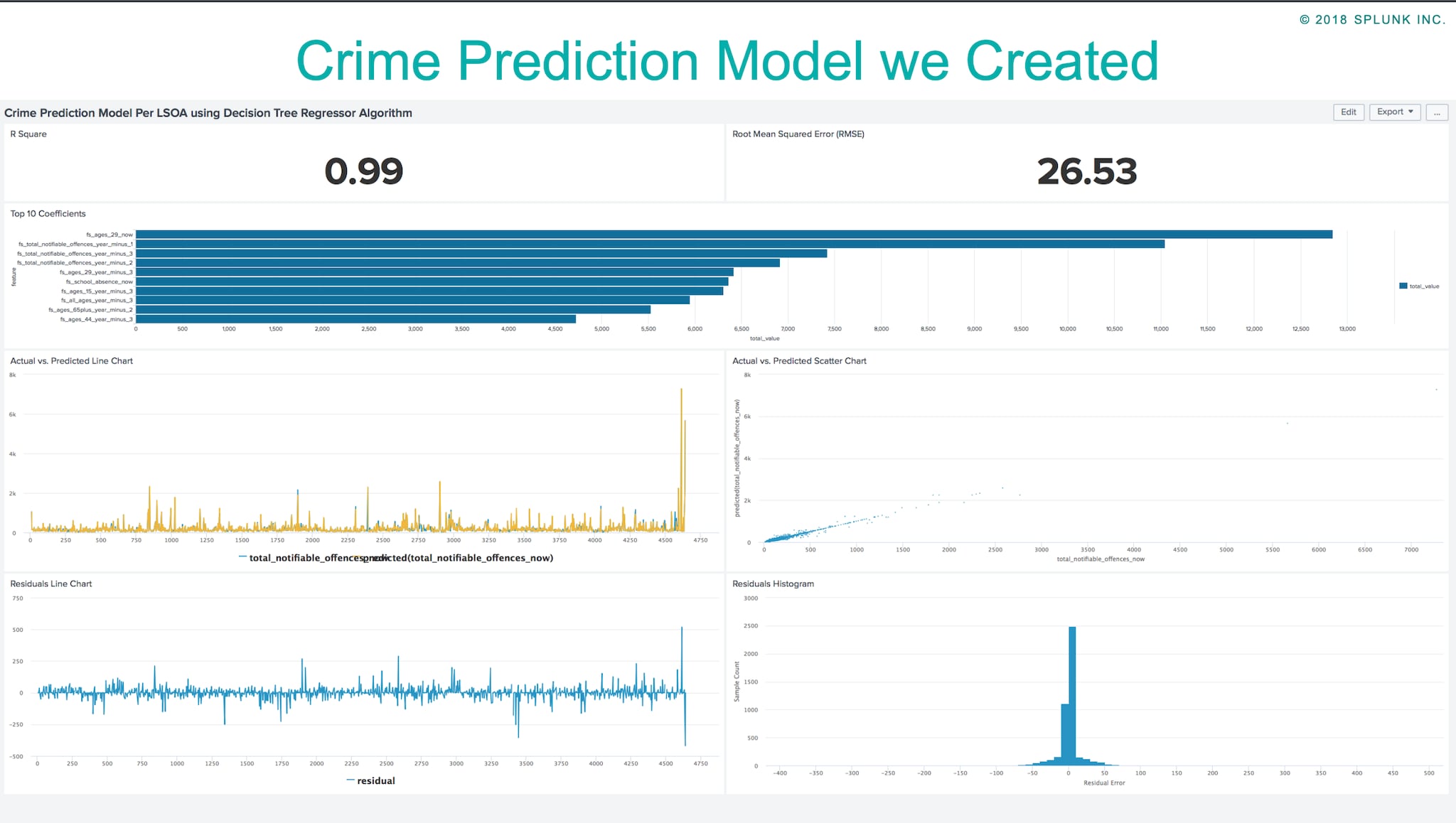
Pour qu’une analyse prédictive fonctionne, nous avons d’abord besoin de données. Supposons que nous avons accès aux données qui conservent une trace de plusieurs aspects des crimes enregistrés. Heureusement, de nombreux gouvernements et administrations publiques autorisent l’accès aux données ouvertes, comme data.police.uk. Nous chargeons ces données dans Splunk pour lancer le processus. Paul McDonough et Shashank Raina ont utilisé cette méthode pour leur présentation lors de .conf18.
Voici leur intervention à la conférence : nous voulons montrer que le Machine Learning Toolkit de Splunk peut être utilisé pour des problèmes du monde réel et qu’il peut nous aider à obtenir de meilleures réponses. Ce faisant, nous présenterons également les différentes étapes sur la façon d’utiliser facilement Splunk pour les problèmes de prédiction. Nous avons effectué quelques tâches de base qui peuvent être utilisées sur n’importe quel exemple de ML Toolkit :
En suivant les étapes ci-dessus, nous avons créé un modèle de prédiction de la criminalité à l’aide de l’application Splunk ML Toolkit. Cela nous a donné un aperçu intéressant des facteurs qui affectent les niveaux de criminalité à Londres. Vous trouverez ci-dessous notre présentation et un article de blog expliquant en détail les étapes que nous avons suivies.
Comme mentionné précédemment, nous avons expliqué dans notre présentation à l’occasion de Splunk .conf18 comment nous pouvons exploiter Splunk ML Toolkit pour la création de modèles de machine learning. Le terme « Machine learning » étant depuis quelques temps à la mode dans le monde numérique, nous avons pris du recul pour essayer de comprendre l’effet des modèles développés et la façon dont ils sont appliqués dans le monde réel. En raison des progrès technologiques en cours, nous avons observé une utilisation accrue des techniques prédictives, mais nous avons également constaté un grand nombre de rapports sur le biais des machines. Mentionnons à titre d'exemples :
Le biais est défini comme un préjugé ou une discrimination contre quelque chose, une personne ou un groupe. Un biais discriminatoire est créé lorsque les décisions basées sur les données ont des résultats déséquilibrés. Aussi étonnant que cela puisse paraître, tous les jeux de données volumineux sont biaisés. Cependant, la plupart des utilisateurs qui créent ces modèles n’en sont pas conscients, car le biais du ML n’est pas un phénomène largement discuté. Même si certaines personnes sont au courant du problème, ils ne sauraient de toute façon pas quoi en faire. Le buzz autour du ML a conduit les modélisateurs à se concentrer sur la création de modèles de ML de plus en plus grands et complexes qui les aident à obtenir une meilleure couverture. Pourtant, peu sont disposés à régler les problèmes inhérents au biais dans les données et les modèles de ML qu’ils ont développés.
Dans notre présentation lors de .conf 2019, nous avons analysé le biais du ML et ses effets. Nous avons également abordé la façon de les minimiser. Examinons cela de plus près :
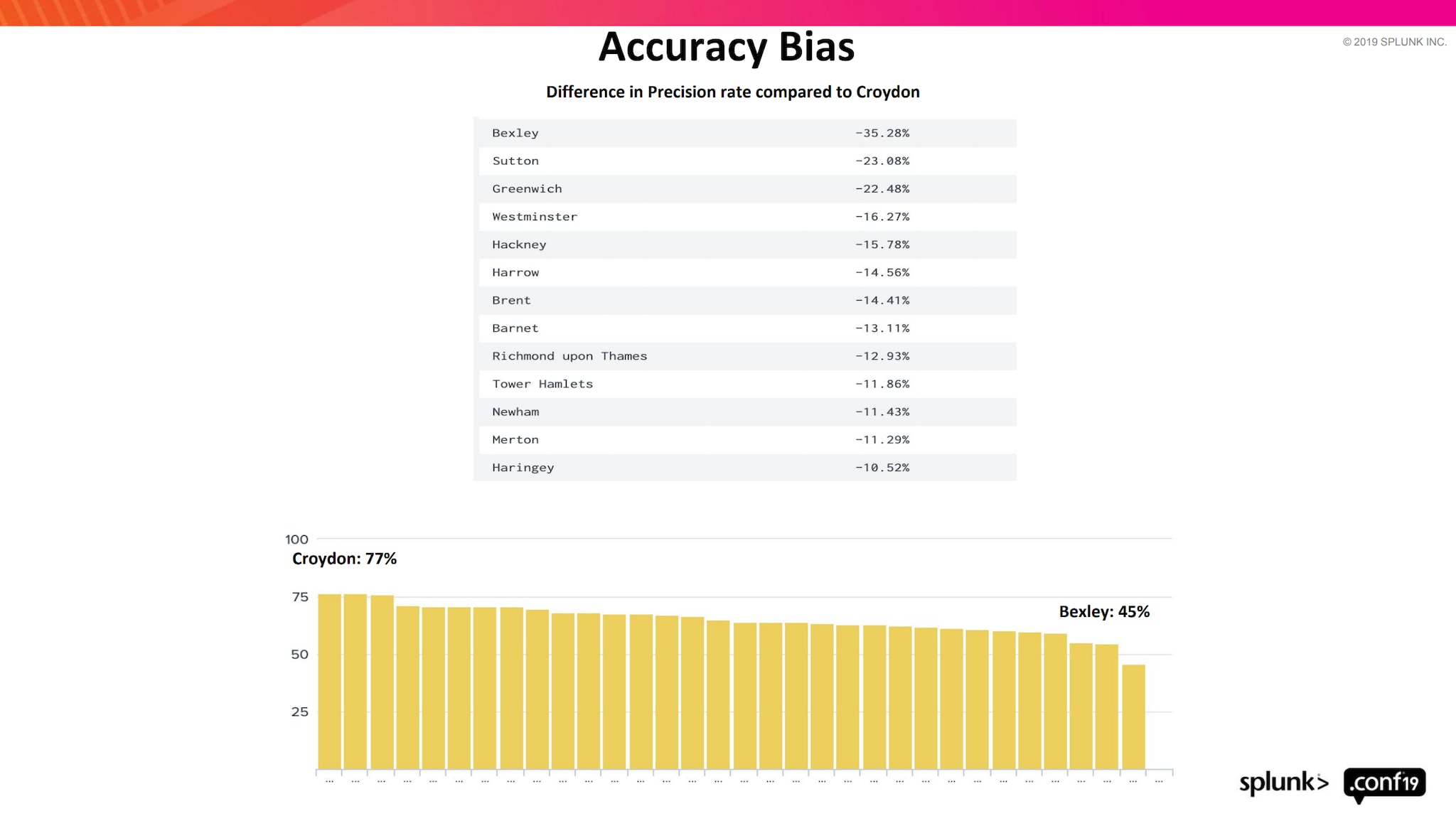
Dans cette série d’articles de blog, nous avons abordé plusieurs aspects liés à la prédiction et à la prévention de la criminalité. La réflexion relative au biais dans les modèles nous montre à quel point il est indispensable de faire preuve de prudence, en particulier lorsqu’il s’agit de modèles qui ont des effets directs ou indirects sur les personnes. Si vous souhaitez approfondir ce sujet, vous trouverez plus de conférences .conf relatives au biais ici et Dipock’s Mind the Gap!, pour une étude plus détaillée.
Personnellement, je voudrais dire un grand « MERCI » à Shashank de NCC et Paul de 13 Fields qui ont collaboré sur le contenu mentionné.
Continuez votre excellent travail et bon Splunking,
Philipp
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.