
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.
La plupart des systèmes classiques de machine learning, axés sur le traitement par lot, suivent le paradigme « adapter et appliquer ». Dans un précédent article de blog, j’ai abordé plusieurs approches pour mieux organiser les pipelines de données et les workflows de machine learning dans Splunk. Dans cet article de blog, nous verrons comment vous pouvez organiser votre modèle de machine learning d’une nouvelle manière : avec l’apprentissage en ligne.
La différence entre l’apprentissage par lot et les systèmes d’apprentissage en ligne est qu’avec la première approche, vous essayez d’apprendre à partir d’un ensemble de données complet en une fois, tandis qu’avec la seconde, vous procédez par incréments et mettez constamment à jour votre modèle « en ligne ». Sur le plan pratique, chacune présente des avantages et des inconvénients, et il peut être difficile de choisir l’approche la plus appropriée.
Le principal avantage d’un système d’apprentissage en ligne réside dans son empreinte de calcul et de mémoire généralement inférieure, car vous n’avez pas à traiter un grand ensemble de données comme c’est le cas dans l’apprentissage par lots traditionnel. En effet, le traitement par lot des données peut coûter cher et prendre du temps, mais vous pouvez fournir régulièrement des lots de données plus petit à un modèle apprenant en ligne, afin d’obtenir plus rapidement des réponses. Le système apprend à partir des lots et en mémorise les caractéristiques importantes dans sa représentation tout en continuant à les appliquer pour faire des inférences sur les données présentées. De plus, dès que de nouvelles données arrivent, le modèle peut s’adapter à de nouvelles situations, et donc continuer à apprendre.
Devant tous ces avantages, gardez tout de même à l’esprit plusieurs défis : le modèle doit être capable de gérer la dérive conceptuelle, qui peut se produire lorsque les données changent de manière significative. De plus, si vous disposez uniquement du modèle en ligne, mais que vous n’avez plus les données historiques, il est difficile de réentraîner le modèle de manière significative en cas de problème dans vos données ou dans l’algorithme en ligne que vous avez choisi. Dans les systèmes de production, vous aurez idéalement mis en place des stratégies pour faire face à de telles situations, en particulier si des applications stratégiques reposent sur système d’apprentissage en ligne. Néanmoins, cette approche reste un outil viable dans votre arsenal quand vous étudiez un cas d’utilisation.
Depuis la version 3.8, l’Application Splunk pour la science des données et l’apprentissage profond (DSDL), anciennement connue sous le nom de Boîte à outils de l’apprentissage profond (DLTK), vous propose d’essayer des algorithmes d’apprentissage en ligne alimentés par la bibliothèque Python River avec une image de conteneur dédiée. Elle propose également un exemple de détecteur d’anomalies avec apprentissage en ligne, basé sur l’algorithme HalfSpaceTrees, une variante en ligne des forêts d’isolement. Ils fonctionnent bien lorsque les anomalies sont réparties.
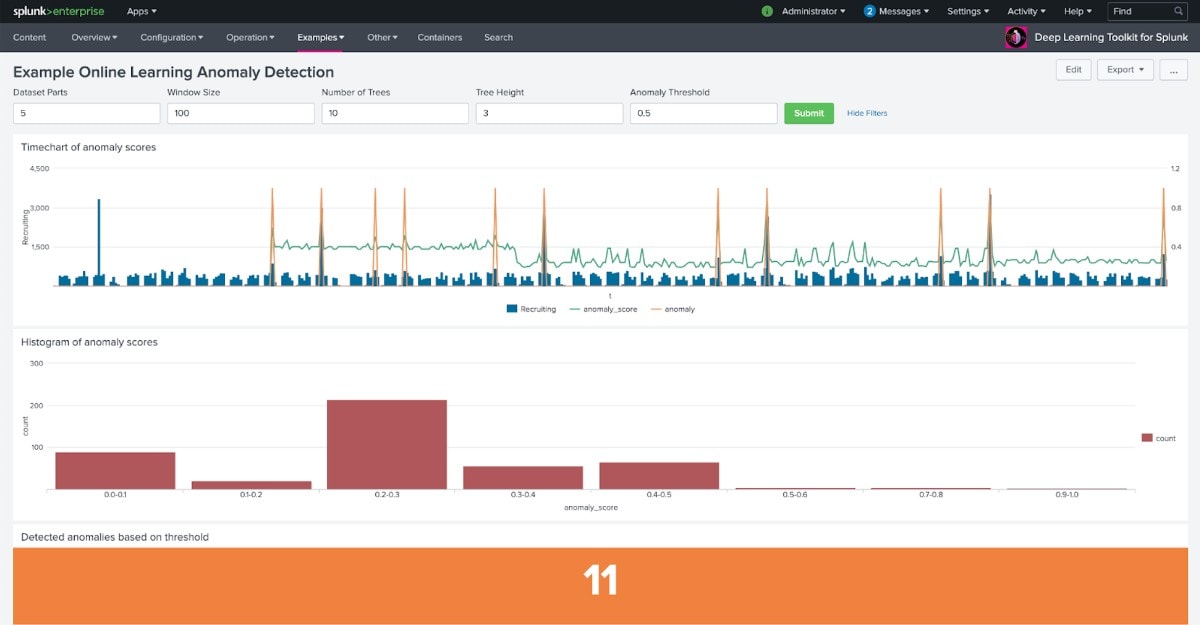
Dans la capture d’écran ci-dessus, vous voyez une simple série chronologique du nombre d’accès à un service de recrutement, représentée par des barres bleues. Dans le graphique linéaire superposé, la courbe verte indique le score d’anomalie, calculé par le modèle d’apprentissage en ligne. Sur le côté gauche du graphique, vous remarquez que le score apparaît après une certaine phase d’échauffement définie, ce qui est assez typique de l’apprentissage en ligne. Si vous suivez la courbe verte d’encore plus près, vous verrez également comment, après un certain temps, le modèle passe d’une valeur moyenne de 0,40 à une valeur inférieure qui se stabilise autour de 0,25 à l’extrémité droite du graphique. Enfin, la courbe orange indique les anomalies signalées, en fonction d’un seuil facilement ajustable selon la sensibilité souhaitée du détecteur. Les 11 anomalies sont ainsi automatiquement repérées et pourraient ensuite très facilement être utilisées à des fins d’alerte ou de recherches de corrélation plus sophistiquées.
Pour conclure cet exemple d’apprentissage en ligne, voyons à quoi ressemblerait concrètement un workflow dans Splunk. En règle générale, vous devez suivre les étapes ci-dessous pour que votre système d’apprentissage en ligne soit opérationnel dans DSDL :
J’espère que cet article de blog vous suggérera une nouvelle approche de certains défis de machine learning. Notez que tous les algorithmes ne se prêtent pas à l’apprentissage en ligne : vous devez donc évaluer soigneusement les cas d’utilisation et comparer les approches d’apprentissage en ligne possibles avec d’autres approches traditionnelles pour prendre une décision éclairée.
Si vous souhaitez en savoir plus sur l’application Splunk pour la science des données et l’apprentissage profond, vous pouvez regarder cette session .conf : vous découvrirez comment le groupe BMW utilise DSDL pour une stratégie de test prédictif dans la construction automobile. Si vous souhaitez savoir comment utiliser DSDL pour faire évoluer les prévisions avec Prophet, restez à l’écoute, car nous en parlerons dans un prochain article.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.