S plunk Observability Cloud bénéficie de plusieurs nouvelles améliorations afin d’aider les équipes à filtrer le bruit et à dépanner plus rapidement en bénéficiant d’une meilleure visibilité sur l’ensemble de leurs environnements, ainsi que d’une approche plus unifiée de la réponse aux incidents. Les ingénieurs en première ligne savent pertinemment qu’il est impossible de protéger et d’assurer la disponibilité de ressources numériques que vous n’êtes pas capables d’observer. Grâce à ces innovations, les équipes profitent maintenant d’un contexte beaucoup plus riche de l’expérience de l’utilisateur final via le réseau cloud et sur chaque transaction. Elles peuvent ainsi isoler rapidement la cause d’un problème (lorsque l’alerte l’appel est passé en interne). Elles bénéficient également d’alertes plus fiables pour réagir plus efficacement et remettre de l’ordre dans les astreintes, le tout au sein d’une interface unique.
plunk Observability Cloud bénéficie de plusieurs nouvelles améliorations afin d’aider les équipes à filtrer le bruit et à dépanner plus rapidement en bénéficiant d’une meilleure visibilité sur l’ensemble de leurs environnements, ainsi que d’une approche plus unifiée de la réponse aux incidents. Les ingénieurs en première ligne savent pertinemment qu’il est impossible de protéger et d’assurer la disponibilité de ressources numériques que vous n’êtes pas capables d’observer. Grâce à ces innovations, les équipes profitent maintenant d’un contexte beaucoup plus riche de l’expérience de l’utilisateur final via le réseau cloud et sur chaque transaction. Elles peuvent ainsi isoler rapidement la cause d’un problème (lorsque l’alerte l’appel est passé en interne). Elles bénéficient également d’alertes plus fiables pour réagir plus efficacement et remettre de l’ordre dans les astreintes, le tout au sein d’une interface unique.
Nous avons également amélioré les fonctionnalités de pointe de Splunk Observability en matière de journalisation et de réponse aux incidents afin d’offrir aux équipes le contexte partagé dont elles ont besoin lors du dépannage de l’ensemble de leur environnement de production.
Identifiez plus rapidement la source des problèmes grâce à une meilleure visibilité
Plusieurs nouvelles fonctionnalités vous aident à résoudre les problèmes plus rapidement avec une plus grande visibilité et davantage de contexte sur votre pile tech et sur l’expérience de l’utilisateur final. Que vous travailliez dans des architectures monolithiques ou à microservices, ces innovations vous fournissent le contexte de chaque session d’utilisateur problématique ou problème de tag sur l’ensemble de votre réseau cloud et de vos clusters Kubernetes. Vous pouvez ainsi identifier la source des problèmes plus vite et comprendre l’impact des problèmes sur vos clients.
- Splunk Application Performance Monitoring (APM) Trace Analyzer : Détectez les tendances en toute confiance sur des milliards de transactions et identifiez les problèmes spécifiques pour chaque tag, utilisateur ou service. Splunk APM Trace Analyzer vous aide à repérer les problèmes inconnus sur une infinité de combinaisons de tags et de métadonnées, à résoudre les problèmes pour des utilisateurs spécifiques et à comprendre comment un problème affecte vos différents groupes de clients.
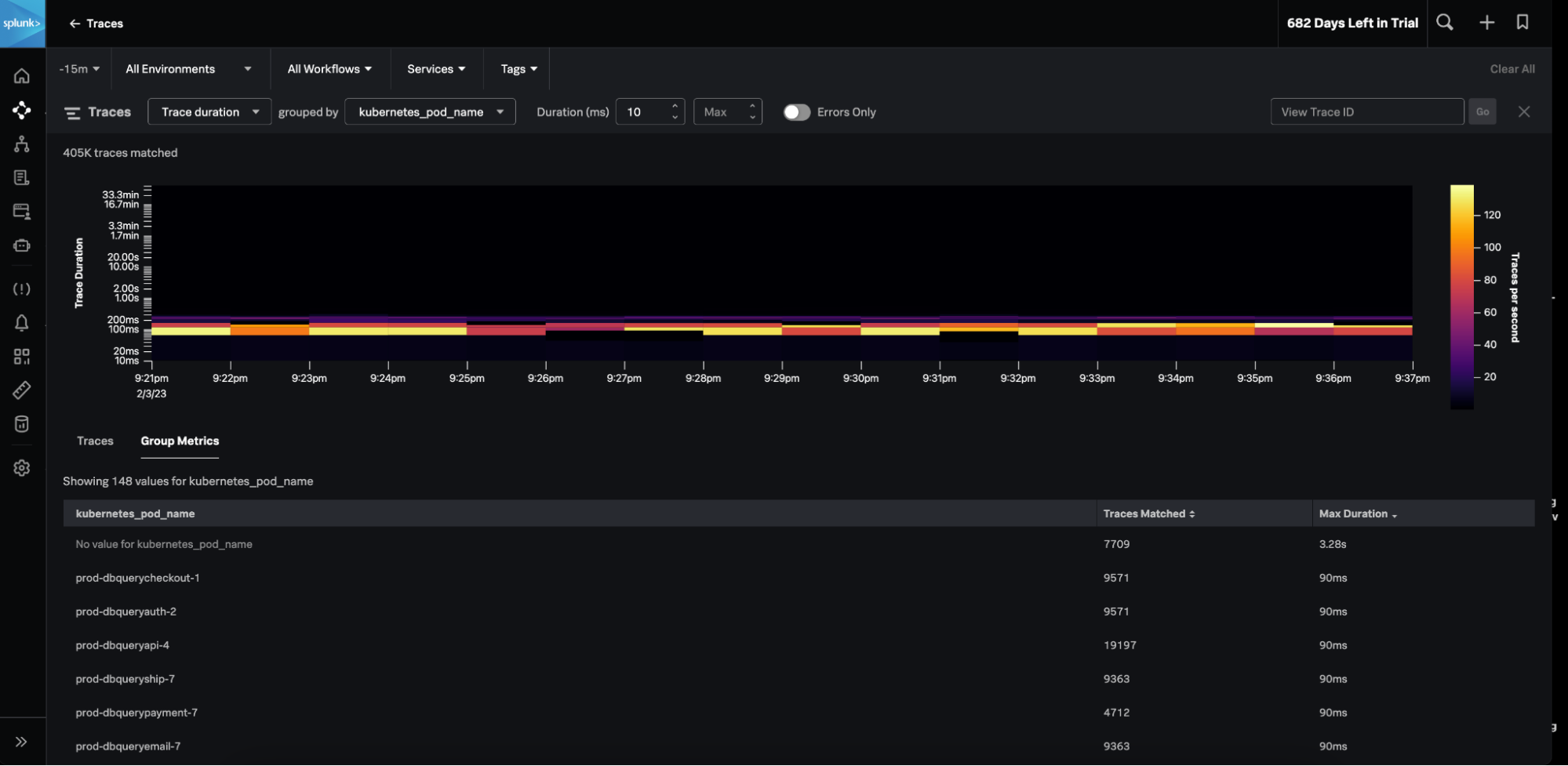
- Splunk Infrastructure Monitoring Network Explorer : Network Explorer est une nouvelle fonctionnalité de Splunk Infrastructure Monitoring qui fournit aux équipes d’ingénierie une visibilité sur le réseau cloud afin qu’elles puissent identifier plus rapidement la source des problèmes de réseau cloud. Supervisez et évaluez la santé de votre réseau cloud en toute simplicité, profitez d’une vision claire de votre environnement cloud, de la topologie de votre réseau et optimisez vos investissements dans votre réseau cloud en identifiant les tendances de trafic et les services coûteux avec Network Explorer.
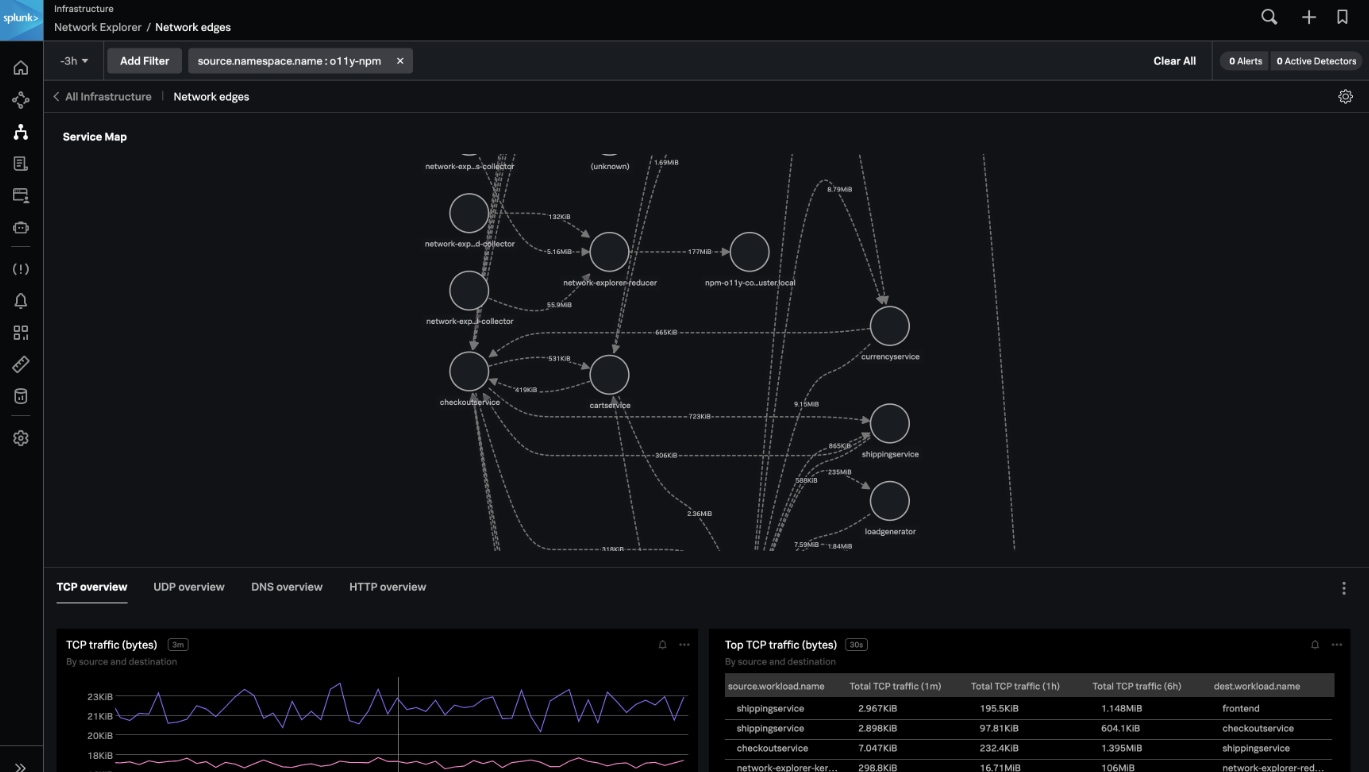
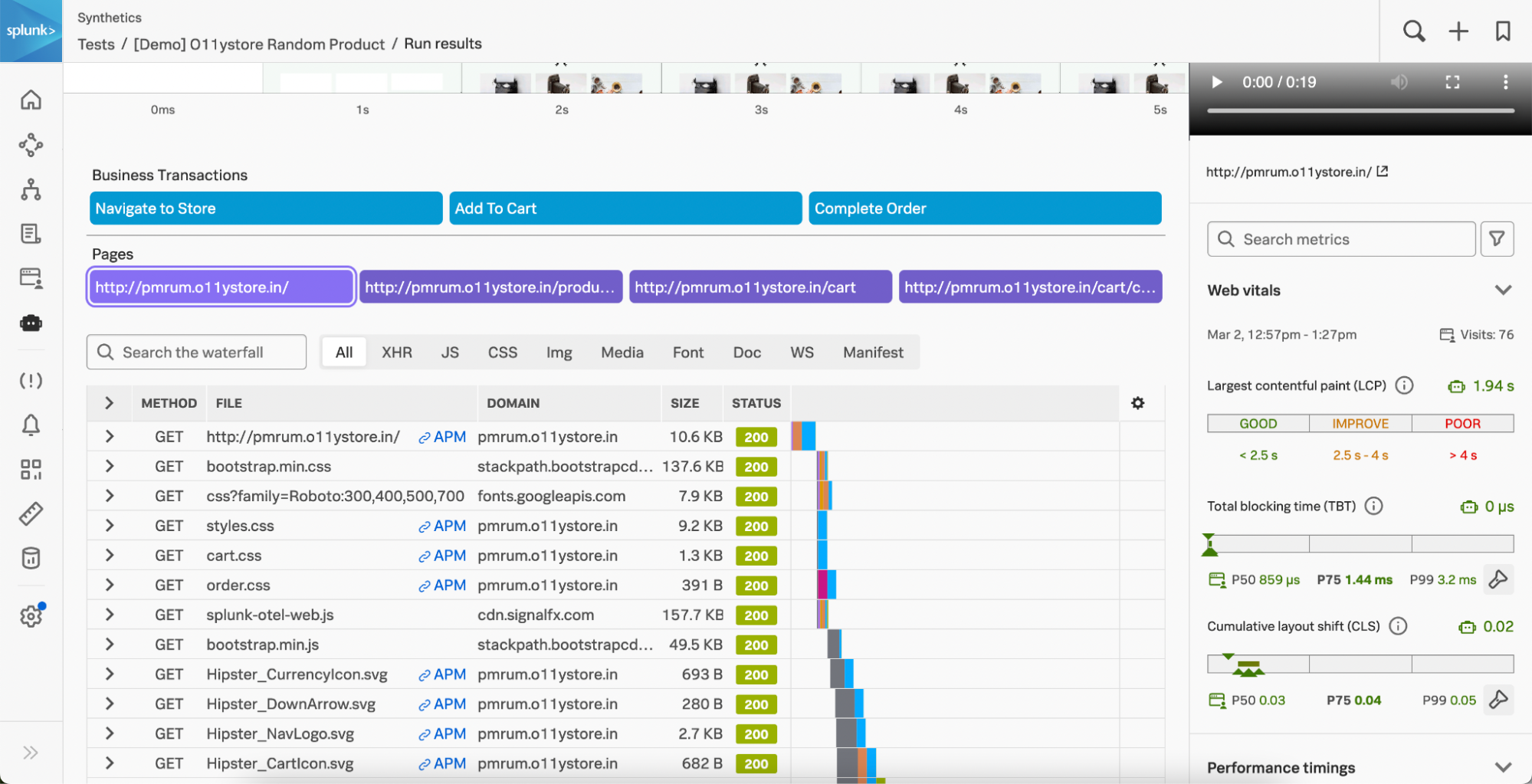
- Intégration de la supervision de l’expérience numérique (DEM) dans Splunk Observability Cloud : Visualisez les métriques RUM de navigateur corrélées aux métriques de performance des pages issues de tests synthétiques sur un seul écran. Grâce à la visualisation intégrée des métriques RUM corrélées aux métriques synthétiques, vous pouvez rapidement déterminer si les problèmes sont systémiques ou régionaux et s’il s’agit d’anomalies de test ou s’ils affectent les utilisateurs. Vous pouvez ainsi prioriser et accélérer la résolution des problèmes afin de proposer des expériences numériques infaillibles.
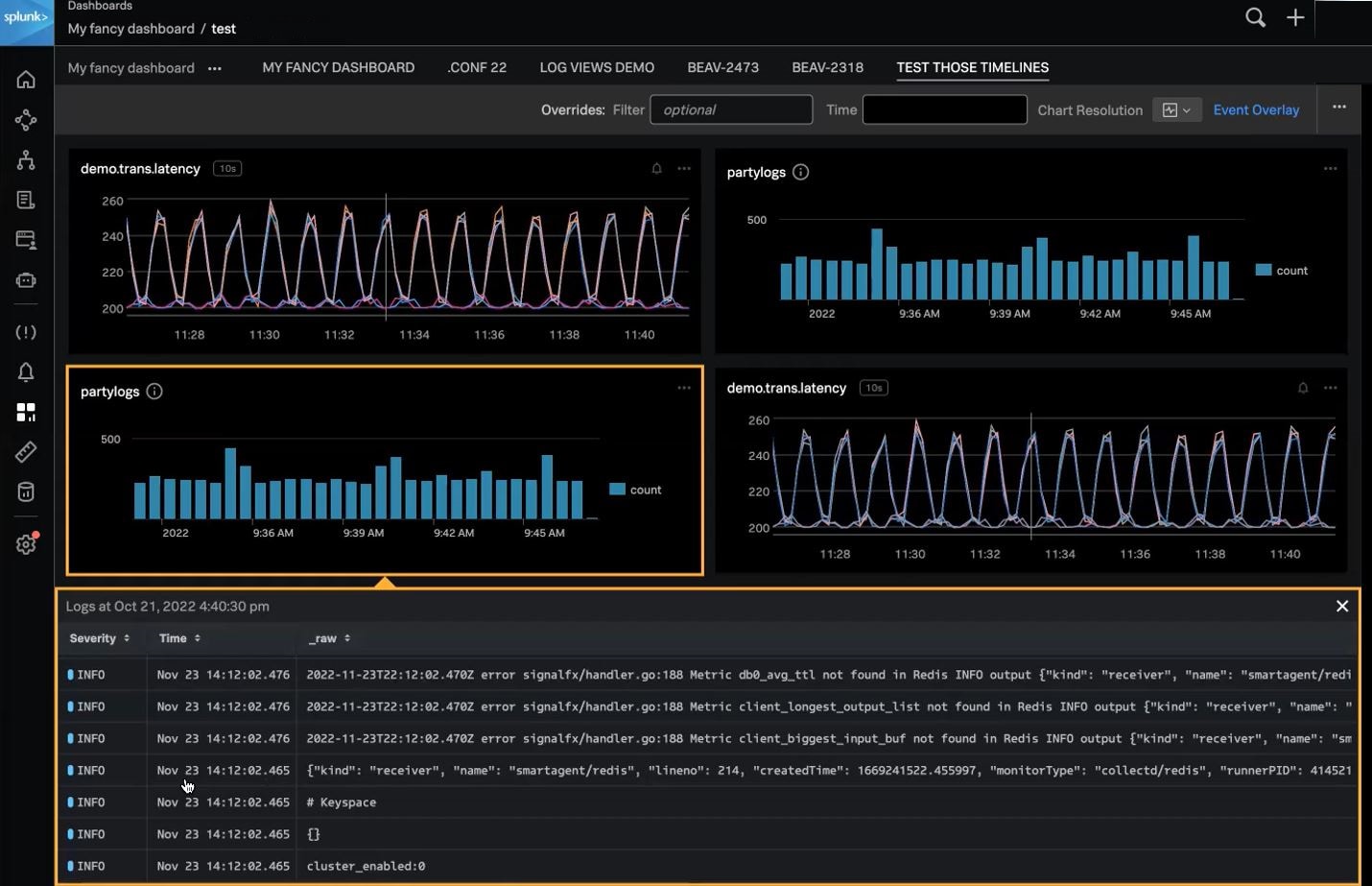
- Log Timelines dans Splunk Observability Cloud : S’appuyant sur les capacités de journalisation et la fonctionnalité Log Views de Splunk, Log Timelines vous permet d’ajouter des diagrammes temporels à vos tableaux de bord d’observabilité. Avec Log Timelines, vous pouvez analyser les tendances en fonction des données de log pour investiguer un problème plus rapidement et efficacement, et réduire vos délais de résolution.
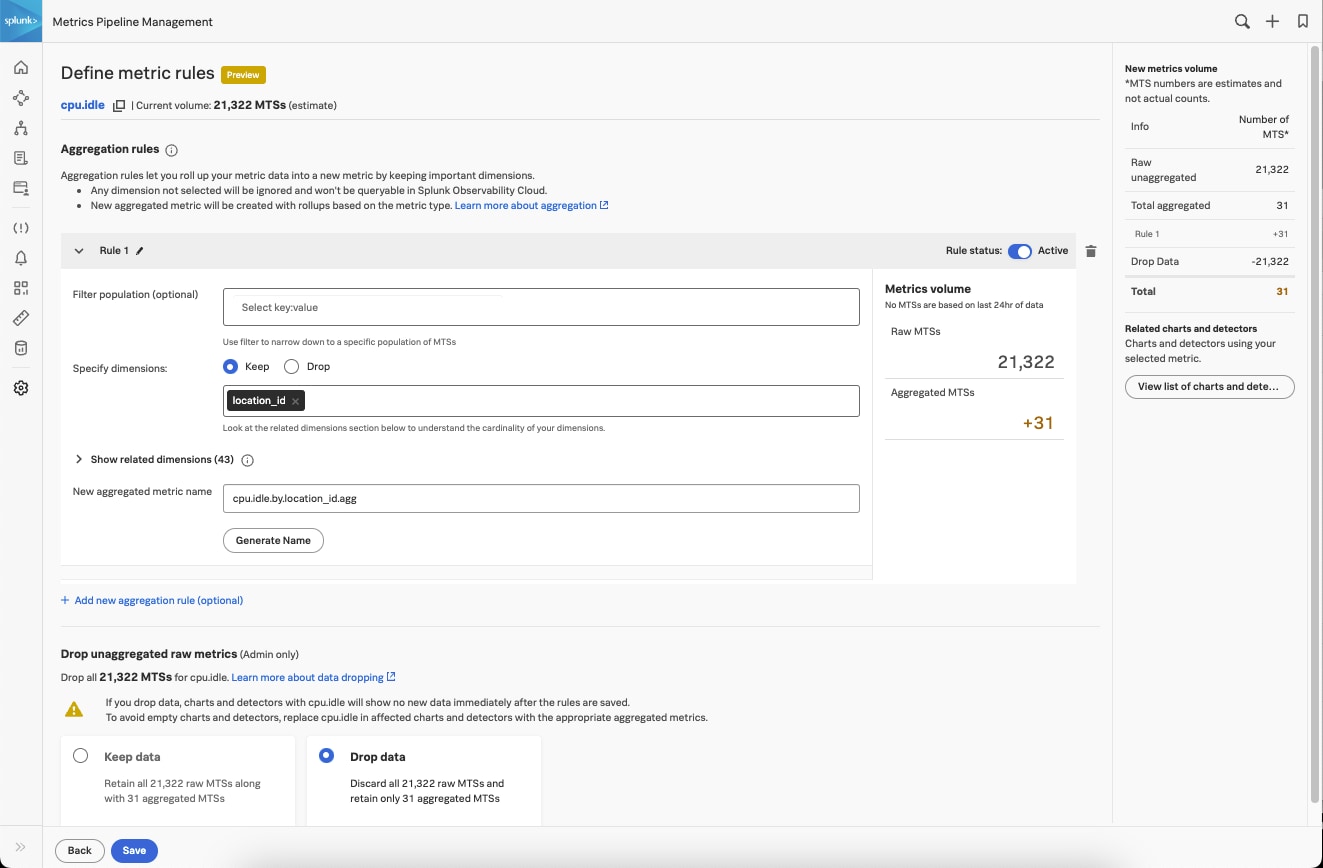
- Splunk Infrastructure Monitoring Metrics Pipeline Management : Splunk Infrastructure Monitoring Metrics Pipeline Management vous permet de faire évoluer votre pratique de supervision afin de disposer des données dont vous avez besoin pour réaliser des dépannages rapides sans augmenter drastiquement vos frais de supervision. Contrôlez et agrégez facilement de grands volumes des données de métriques en filtrant les données dont vous n’avez pas besoin grâce à des règles définies dynamiquement pour uniquement importer, stocker et analyser les données dont vous avez besoin.
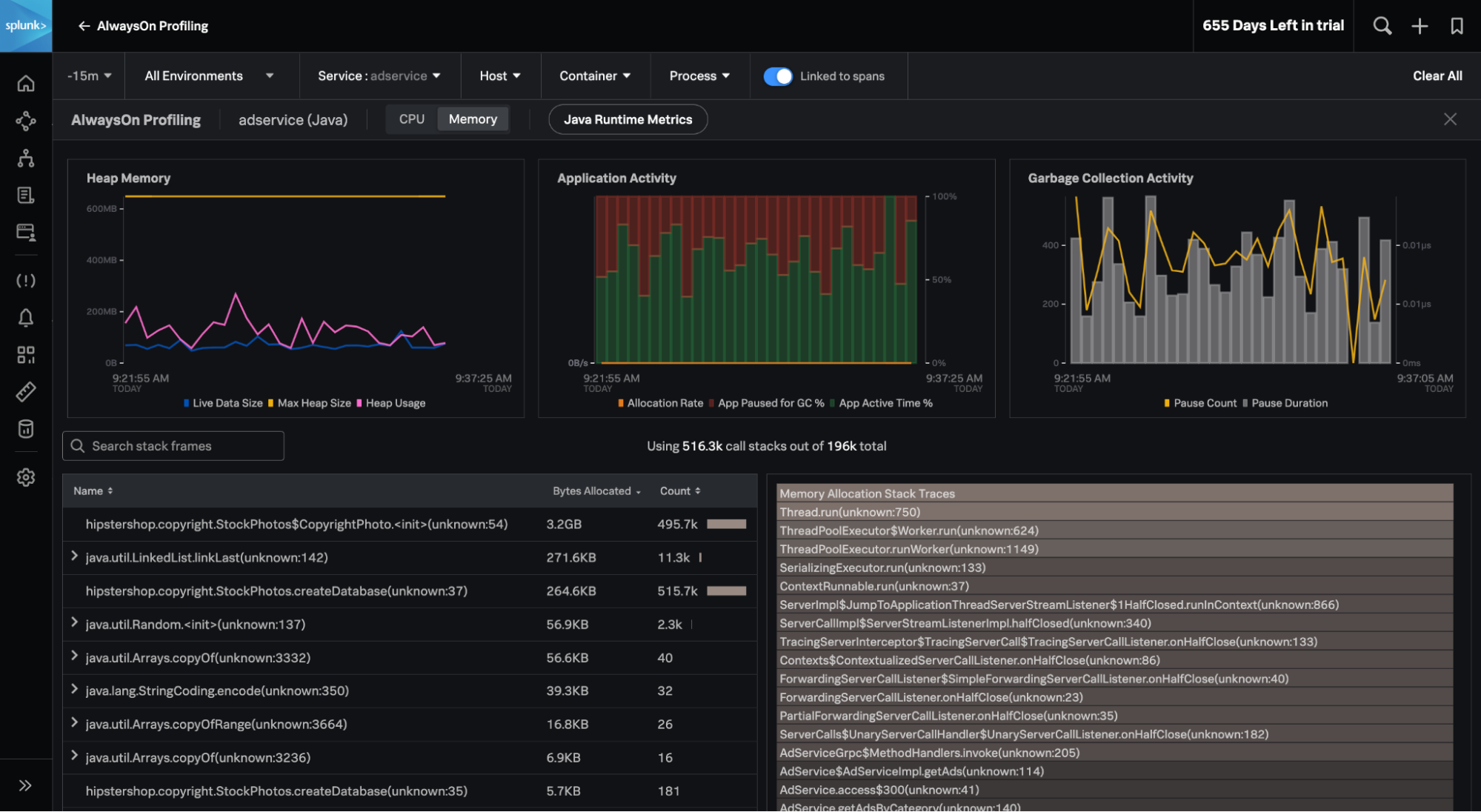
- APM AlwaysOn Profiling, le profilage de la mémoire pour .NET et Node.js : Nous avons continué d’améliorer la compatibilité des langages pour les fonctionnalités de profilage de la mémoire d’AlwaysOn Profiling et ajouté la compatibilité avec .NET et Node.js. Mesurez continuellement l’impact de votre code sur la consommation de CPU et de mémoire dans .NET, Node.js et les applications Java, en contexte avec l’ensemble de leurs données de trace, afin d’identifier les problèmes, avec une surcharge minimale.
Remettez de l’ordre dans les astreintes grâce à une approche unifiée de la réponse aux incidents
Vous pouvez maintenant utiliser Splunk Incident Intelligence et les fonctionnalités d’AutoDetect pour augmenter considérablement l’efficacité de votre équipe d’astreinte. Grâce à ces nouvelles capacités, vous profitez d’alertes plus fiables et de workflows optimisés pour améliorer la coordination et l’efficacité de votre équipe, qui pourra rapidement passer de l’alerte à la résolution et réduire les MTTD, MTTA et MTTR.
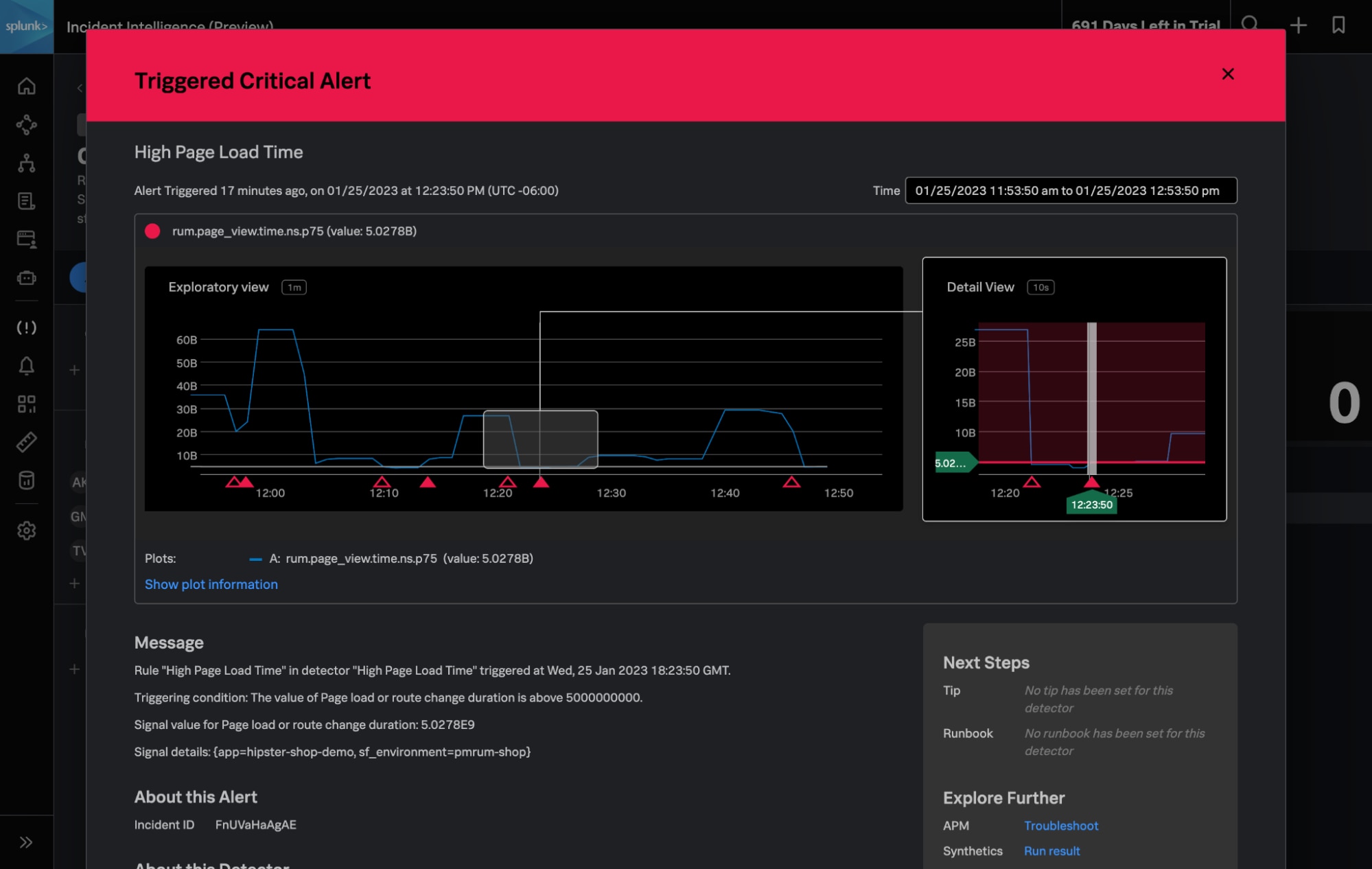
- Splunk Incident Intelligence dans Observability Cloud : Cette solution de réponse aux incidents, disponible dans Splunk Observability Cloud, connecte vos équipes d’ingénierie d’astreinte aux données dont elles ont besoin pour diagnostiquer, corriger et rétablir les services avant que les clients ne soient affectés. Évitez les temps d’arrêt imprévus grâce à des alertes en contexte sur l’ensemble de votre pile et coordonnez la réponse aux incidents dans l’ensemble de vos équipes avec la planification des astreintes, la remontée d’informations et la création de notifications personnalisées.
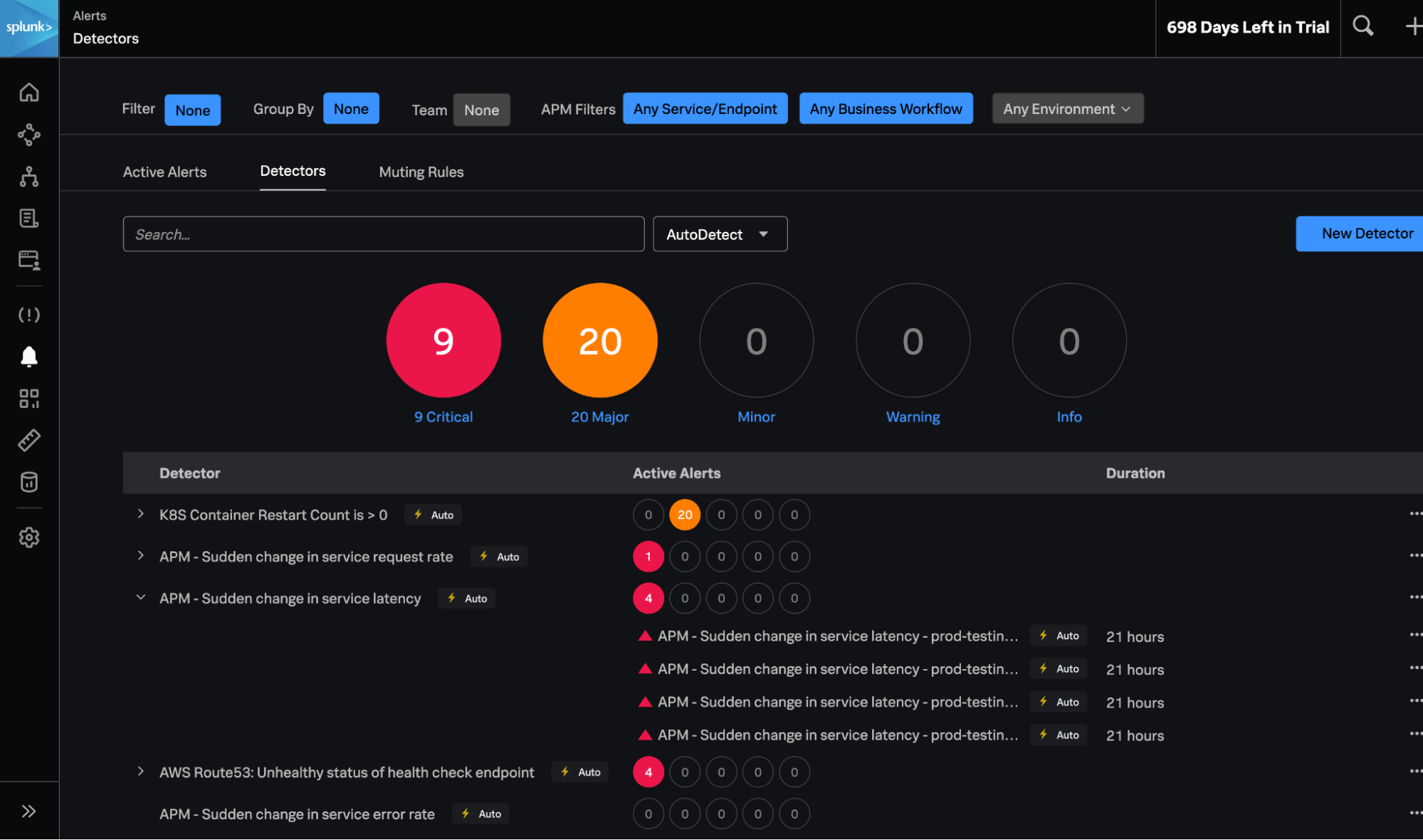
- Splunk Application Performance Monitoring (APM) AutoDetect : APM AutoDetect utilise le machine learning (ML) pour grandement améliorer la fiabilité et réduire les efforts manuels nécessaires pour mettre en place des alertes de service. AutoDetect vous permet d’établir des références de performance pour chaque service, de créer des détecteurs automatiques en cas de variation soudaine des taux de latence, d’erreur et de demande, et de personnaliser et s’abonner aux notifications des alertes de ces détecteurs en toute simplicité. Par conséquent, vous passerez moins de temps à reconfigurer vos alertes et recevrez les alertes les plus fiables sur l’ensemble de vos environnements cloud-native.
Les temps d’arrêt, les interruptions de service et les défaillances critiques des systèmes peuvent avoir des répercussions considérables sur votre organisation. Le rapport annuel Outage Analysis 2022 d’Uptime Institute révèle que 60 % des défaillances ont entraîné au moins 100 000 $ de pertes pour les entreprises interrogées. En tant que plateforme unifiée de sécurité et d’observabilité, Splunk s’engage à continuer à travailler avec vous au renforcement de votre résilience numérique en garantissant les performances et la fiabilité de vos systèmes.
Franchissez le pas : découvrez la nouvelle expérience d’essai améliorée de Splunk Observability Cloud
Vous souhaitez essayer toutes les nouvelles fonctionnalités de Splunk Observability Cloud ? Vous pouvez dès maintenant tester Splunk Observability Cloud de deux manières différentes, en utilisant :
- vos propres données en instrumentant vos applications avec OpenTelemetry, ou
- des échantillons de données pour commencer votre essai gratuit en moins de 12 minutes.
Commencez votre essai gratuit de 14 jours dès aujourd'hui !
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.


