
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.
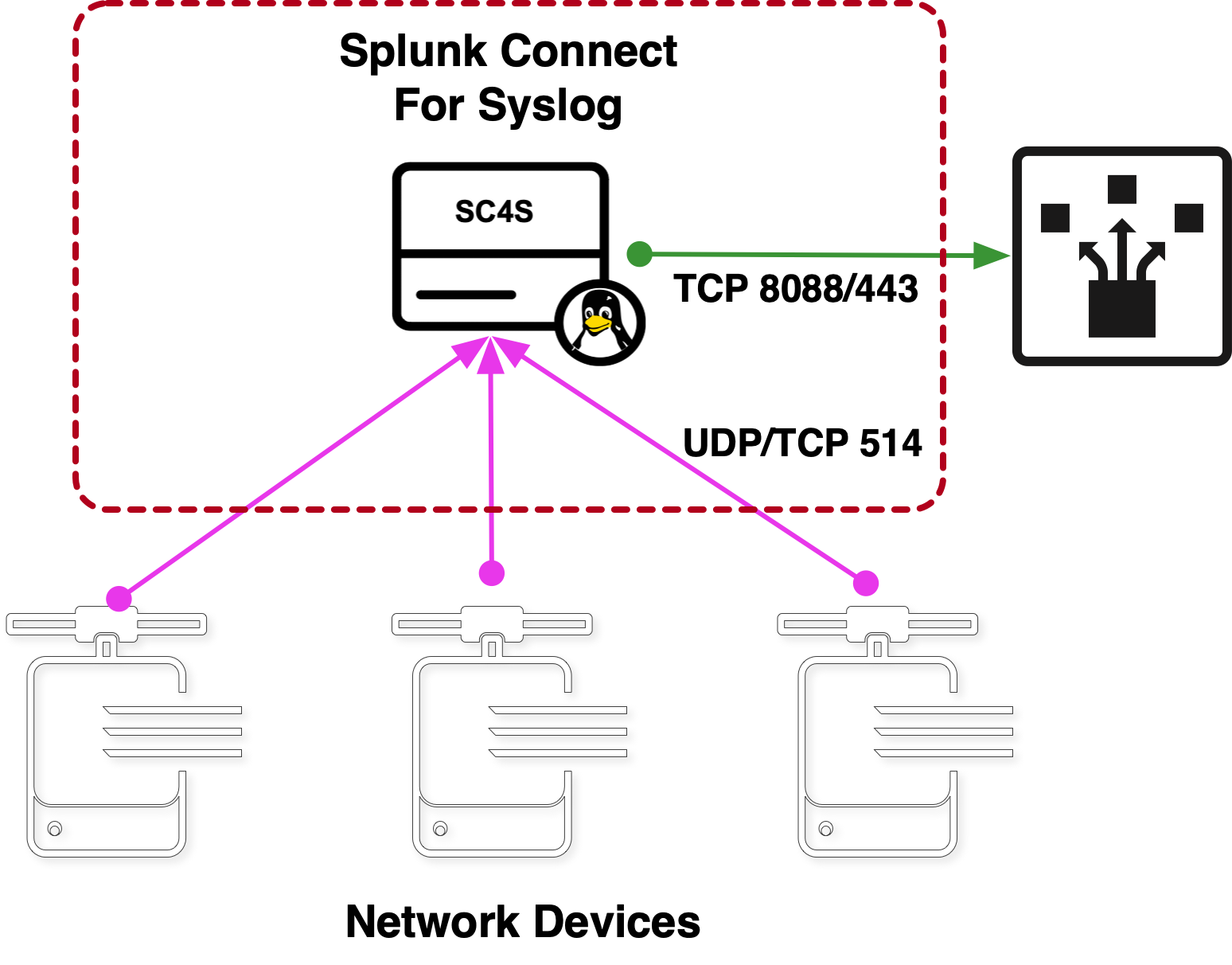
Les précédents épisodes de cette série vous ont donné la vue d’ensemble et les détails de configuration dont vous avez besoin pour importer une source prise en charge par Splunk Connect for Syslog et configurer les personnalisations et les remplacements nécessaires à votre entreprise. Il reste donc une capacité clé de SC4S que nous n’avons pas encore couverte, et qui permet d’étendre la plateforme elle-même.
Dans cet article, nous allons aborder la configuration d’une toute nouvelle source de données, une source que SC4S ne prend pas en charge au départ. Voyons maintenant comment ajouter la prise en charge d’une nouvelle source de données à SC4S !
Avant de vous lancer dans la création d’un chemin de log (filtre) pour un nouveau périphérique, vous aurez besoin de répondre à certaines questions clés :
Les réponses aux questions ci-dessus vous guideront dans la création d’un nouveau chemin de log pour étendre la plateforme. Commençons par un peu de contexte sur la structure globale d’une configuration syslog-ng, car il faut la comprendre pour créer un chemin de log.
Voici la structure globale d’un fichier de configuration syslog-ng. La syntaxe du fichier de configuration syslog-ng, qui est elle-même un langage de programmation, offre une myriade de façons de parvenir à vos fins. Mais toutes suivent le même schéma de base :
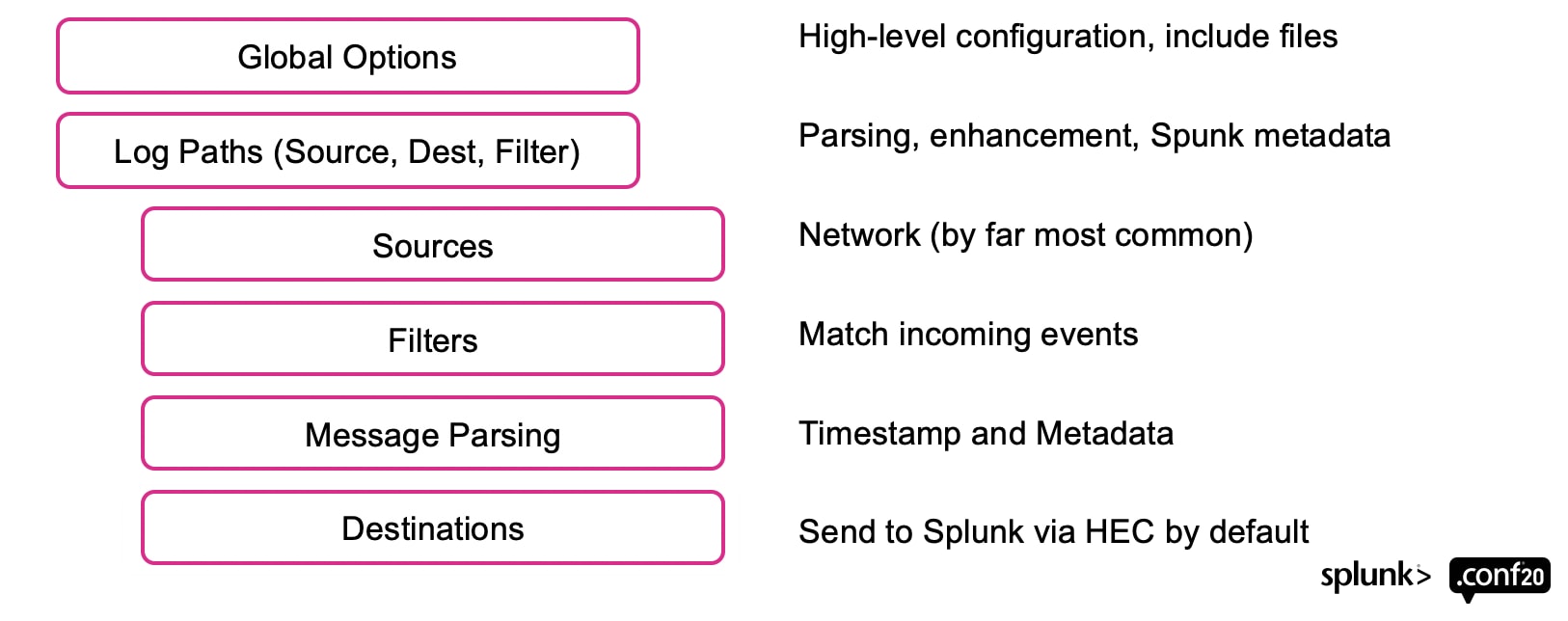
Dans SC4S, la plupart de ces éléments sont abstraits via les mécanismes de configuration décrits dans la partie 3, ce qui évite à l’administrateur d’avoir à comprendre les nuances de la syntaxe syslog-ng. Mais la structure d’un chemin de log devient immédiatement apparente lorsqu’on doit en développer un nouveau, et il est essentiel de comprendre comment les pièces s’assemblent.
Dans une configuration syslog-ng type, ce qui vaut également pour SC4S, il y aura autant de chemins de log que de "variantes" d’événement (périphérique). Ces formats d’événement sont généralement définis par les fournisseurs eux-mêmes et doivent être conformes aux normes syslog publiées (RFC 3164 ou RFC 5424), mais beaucoup présentent des écarts par rapport à ces normes, et vous devez les prendre en compte dans les chemins de log.
Les événements circulent de haut en bas dans le fichier de configuration final ; chacun d’eux est testé par les filtres dans chaque chemin de log afin de déterminer si l’événement y a sa place. Bien que le diagramme ci-dessus montre les filtres comme une entité distincte, en réalité, toutes les étapes (sauf la directive de destination finale) agissent comme un même filtre (ou test). Cela signifie que le bloc source lui-même agit comme un filtre ; si le bloc source indique "Collecter sur le port UDP 5000" et que l’événement s’affiche sur le port UDP 514, ce chemin de log ne sera pas utilisé pour cet événement. De même, le parsage syntaxique des messages peut également agir comme un filtre (si vous le souhaitez) et exclure des événements de ce chemin de log si le parsage échoue. Si l’événement "survit" assez longtemps dans un chemin de log, il est finalement envoyé à une ou plusieurs destinations du choix de l’administrateur.
Rien n’empêche un événement de correspondre à plus d’un chemin de log, mais nous le déconseillons dans SC4S : nous intégrons en effet à la configuration de chaque chemin de log un indicateur qui met fin au traitement si l’événement est traité avec succès par un chemin de log donné. Dans ce cas, "le premier gagne", et c’est le seul endroit dans syslog-ng où le nom des fichiers de chemin de log ont de l’importance : les chemins de log sont traités dans l’ordre lexicographique (essentiellement par ordre alphabétique) des noms de fichier. En interne, SC4S utilise des noms de fichier appropriés pour forcer certains chemins de log à se placer avant (ou après) tous les autres, de manière à imposer un "gagnant" si plusieurs chemins de log se déclenchent sur la seule base du filtrage. Cette technique n’est utilisée que pour les chemins de log de dernier recours (catchall) et de file d’attente "null", elle ne doit donc pas affecter les chemins de log développés localement.
Nous allons maintenant nous pencher sur une fonctionnalité clé de SC4S, fondamentale pour la création d’un chemin de log. Vous vous souvenez qu’au début de la partie 3, nous avons discuté des variables d’environnement dans env_file ? Si nous spécifions un jeton et une URL de point de terminaison HEC avec une variable d’environnement, comment cela se traduit-il dans la syntaxe syslog-ng, qui doit effectivement être "codée en dur" ? La réponse se trouve dans la création de modèles : un élément clé de l’abstraction de la syntaxe sous-jacente pour l’administrateur et un élément clé pour rendre les chemins de log beaucoup plus faciles à créer.
La syntaxe syslog-ng est très stricte, et bien qu’elle se rapproche d’un langage de programmation complet, il lui manque certaines constructions clés, en particulier la possibilité d’interagir avec l’environnement en cours d’exécution et d’adapter sa configuration en fonction de tests conditionnels des variables d’environnement. Lorsque syslog-ng est instancié, la configuration doit être solidifiée lors de l’exécution. Par conséquent, SC4S a besoin d’un mécanisme pour construire dynamiquement cette configuration fixe juste avant le lancement de syslog-ng. C’est là qu’intervient "gomplate", ou "Go templates".
Le processus de modélisation permet aux variables d’environnement de dicter la configuration syslog-ng finale utilisée par SC4S. Prenons cette variable d’environnement :
SC4S_SOURCE_UDP_SO_RCVBUFF=33554432
Comment la valeur de cette variable s’inscrit-elle dans la configuration finale ? La clé réside dans la modélisation ; la configuration source syslog-ng qui se trouve à l’intérieur du conteneur n’est pas codée en dur, mais ressemble plutôt à ceci pour le tampon de réception UDP :
so-rcvbuf({{getenv "SC4S_SOURCE_UDP_SO_RCVBUFF" "1703936"}})
Tout ce qui se trouve à l’intérieur des paires d’accolades doubles fait partie du modèle (qui est lui-même son propre langage) et est utilisé pour insérer, de façon conditionnelle, des éléments de configuration en fonction des paramètres des variables d’environnement. Le résultat est la configuration finale suivante, dans laquelle la valeur par défaut (1703936) est remplacée par la valeur de la variable :
so-rcvbuf(33554432)
L’exemple ci-dessus est une simple substitution, mais il est possible de réaliser des remplacements conditionnels plus complexes :
{{- if or (conv.ToBool (getenv "SC4S_ARCHIVE_GLOBAL" "no")) (conv.ToBool (getenv "SC4S_ARCHIVE_CISCO_ASA" "no")) }}
destination(d_archive);
{{- end}}
Cette construction insère la destination de l’archive alternative dans la configuration si l’une des variables ARCHIVE est définie sur "yes". Si aucune des variables n’est définie dans env_file ou si les deux ont la valeur "no", le texte spécifié au sein de l’instruction conditionnelle "if/end" n’est pas inséré dans la configuration.
Nous allons maintenant nous intéresser au processus de création d’un chemin de log, qui utilise grandement le processus de modélisation décrit ci-dessus. Mais nous devons encore nous occuper de quelques aspects avant d’écrire le chemin de log, et cela nous facilitera la tâche. Une étape critique, après avoir déterminé qu’un chemin de log est effectivement nécessaire en vérifiant les "tâches préalables" au début de cette section, consiste à obtenir un événement brut avec lequel il sera possible de travailler.
Vous avez peut-être de l’expérience dans la collecte d’échantillons de données brutes lors de la configuration de SC4S, en particulier si les événements arrivent dans Splunk avec des métadonnées incorrectes (sourcetype, etc.). Cette tâche est essentielle pour le développement du chemin de log et elle doit être la première étape technique. Plusieurs options sont à votre disposition, les deux plus courantes étant tcpdump et l’utilisation de SC4S lui-même. Les détails sont documentés ici, ils sont brièvement résumés ci-dessous et seront examinés dans notre guide :
Nous avons maintenant les données dont nous avons besoin pour créer pas à pas un exemple de chemin de log. Allons-y !
Il existe deux types de chemins de log dans SC4S: "simple" et "traditionnel". Les chemins de log simples peuvent être utilisés lorsque le périphérique peut envoyer ses messages sur un port unique et qu’une interprétation minimale, reposant uniquement sur un protocole, suffit pour déterminer le sourcetype unique de l’événement. Ils peuvent être entièrement configurés via des variables d’environnement et ne nécessitent pas le développement d’un chemin de log dédié. Vous trouverez ici plus d’informations sur les chemins de log simples.
D’autre part, si la famille d’appareils nécessite plusieurs sourcetypes (par exemple, Palo Alto), un chemin de log traditionnel intégrant une interprétation plus complète doit être développé.Dans le cadre de notre guide, nous déterminerons si notre nouveau périphérique peut être pris en charge par un chemin de log simple, ou s’il faut développer un chemin traditionnel.
Nous utiliserons le produit Stealthbits StealthINTERCEPT comme exemple pour notre nouveau chemin de log. La configuration de l’application et du périphérique pour le fonctionnement de syslog est typique dans la mesure où aucun échantillon brut "sur le fil" n’est fourni. Par conséquent, il faut utiliser tcpdump ou SC4S pour obtenir un échantillon brut comme indiqué ci-dessus.
Les étapes permettant de créer un chemin de log qui prendra en charge la famille de périphériques StealthINTERCEPT sont décrites ci-dessous :
Commençons par examiner l’échantillon brut dans Splunk (en écoutant un appareil réel ou en utilisant la commande "echo" décrite ci-dessus) :
Envoyez l’événement à SC4S (ici raccourci pour plus de lisibilité) :
echo "<37>`date +\"%b %d %H:%M:%S\"`"’.986 stealth-host StealthINTERCEPT - Authentication Auth failed - PolicyName="StealthDEFEND for AD" Domain="TDOMAIN" Server="TDOMAIN-DC" ServerAddress="10.2.8.55" Perpetrator="MarkB" ClientHost="AP34.TEST.COM" ClientAddress="10.2.8.55" TargetHost="TDOMAN-DC.TEST.COM" TargetHostIP="10.135.33.7"’ > /dev/udp/sc4s.test.com/514
Voici l’événement dans Splunk; vous pouvez voir que RAWMSG est activé :
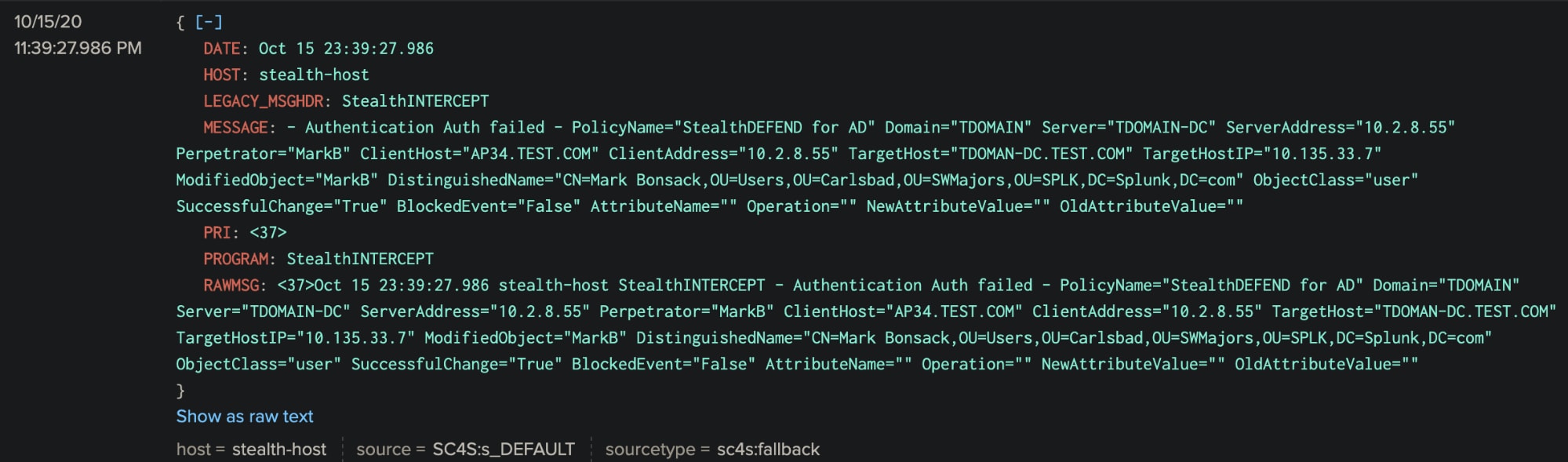
On peut observer plusieurs choses :
Maintenant que nous savons que nous devons développer un chemin de log traditionnel, par où commencer ? Rappelez la structure de répertoire décrite plus haut. Vous verrez le répertoire
/opt/sc4s/local/config/log-paths
Il contient deux fichiers :
lp-example.conf
lp-example.conf.tmpl
Le répertoire log-path (et les autres du répertoire config) sont tous des fichiers de configuration syslog-ng "actifs" et sont inclus dans la configuration globale lorsque le conteneur et le processus syslog-ng sous-jacent sont exécutés. La syntaxe doit donc être parfaite, sans quoi tout cela ne pourra pas démarrer. Pour cette raison, de nombreux fichiers .conf ne sont pas édités directement, mais plutôt via leurs variantes .tmpl. En plus de la substitution de variables et des substitutions conditionnelles abordées dans la partie 3, le processus de modélisation nous permet d’abstraire certaines parties complexes du chemin de log qui n’ont pas besoin d’être exposées (et configurées) par l’administrateur.
Examinons maintenant le fichier lp-example.conf.tmpl. Ne vous inquiétez pas si le fichier d’exemple spécifique de votre version SC4S diffère de celui utilisé pour ces captures d’écran. Le fichier d’exemple change régulièrement au fur et à mesure que SC4S est amélioré et affiné, et aura certainement subi des modifications pour simplifier sa structure lorsque vous lirez ceci. Concentrez-vous sur la structure globale tout en passant en revue les étapes ci-dessous, elles resteront cohérentes, quelles que soient les spécificités du fichier.
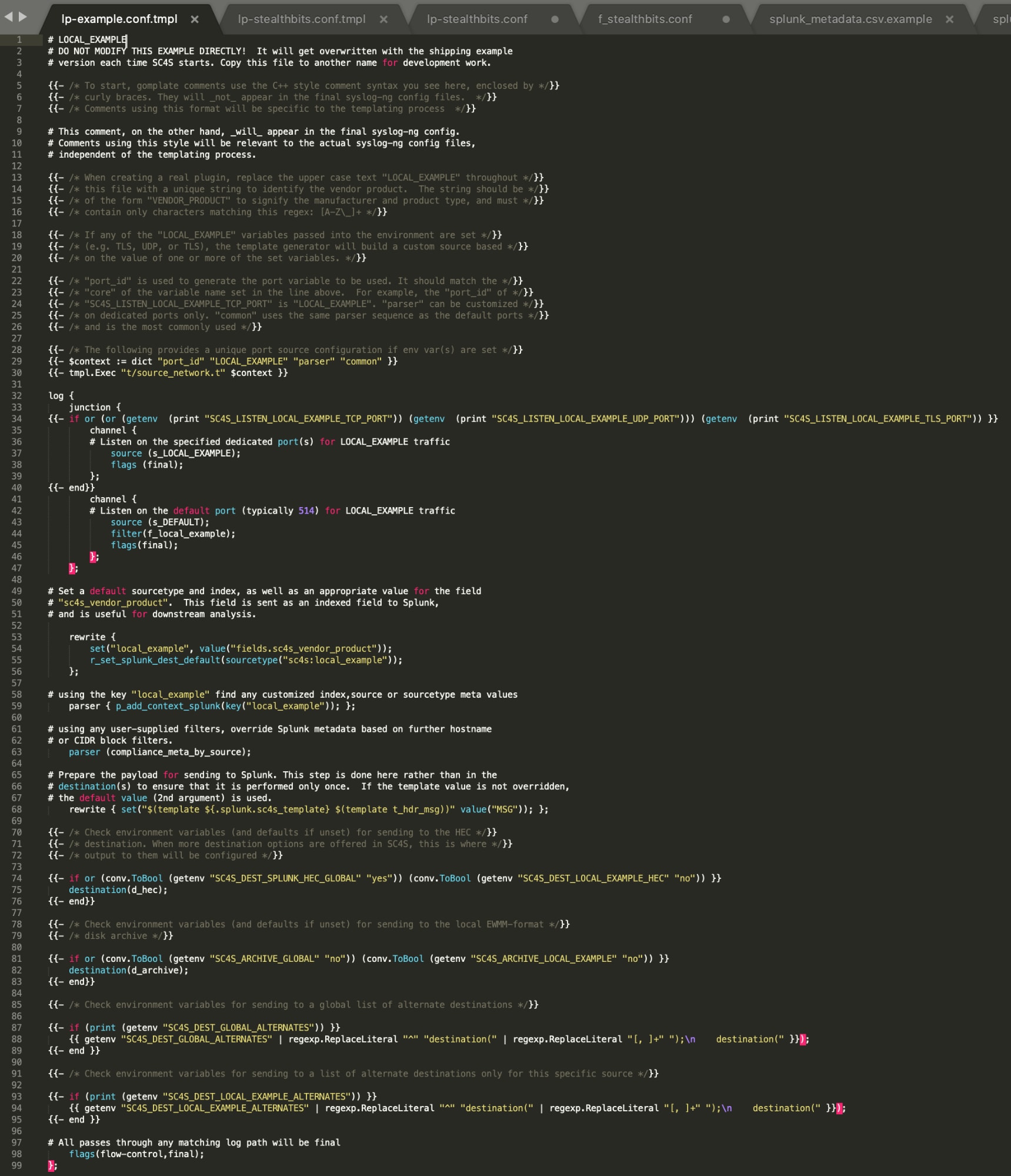
Avant tout, vous verrez que le fichier est parsemé de commentaires d’instructions. Le nombre de lignes exécutables sera au final assez réduit. Ensuite, il est peu probable que vous ayez un éditeur de texte orienté contexte (comme Sublime en mode de langage "C") sur votre serveur SC4S, il peut s’avérer utile lors de la création initiale de votre fichier de modèle à partir du fichier d’exemple ci-dessus, pour faciliter la vérification de la syntaxe.
Passons en revue les étapes nécessaires pour convertir ce fichier "exemple" en chemin de log fonctionnant avec un appareil réel, "Stealthbits" dans notre cas. Les étapes suivantes prépareront le nouveau chemin de log pour la personnalisation spécifique au périphérique :
Après ces substitutions de chaînes, nous allons maintenant examiner chaque section à tour de rôle. Un examen attentif des fragments présentés dans les sections ci-dessous révèle les substitutions de chaînes par rapport à la capture d’écran complète du fichier d’exemple non modifié ci-dessus.
Conformément à la marche à suivre que nous avons annoncée, nous allons maintenant disséquer ce fichier en quatre sections principales:
Commençons par la partie "Source" du chemin de log. À partir de la ligne 28, nous voyons :

Ces deux lignes modélisées font l’essentiel du travail pour vous, grâce au processus de modélisation. Il vous suffit de la chaîne STEALTHBITS_INTERCEPT principale, qui forme la "racine" des variables d’environnement utilisées pour définir des ports d’écoute uniques, et d’une valeur "parser" (définie pour correspondre à la structure de haut niveau des événements, en cas de doute, utilisez "common") pour créer une déclaration de source personnalisée pour votre appareil. Gardez à l’esprit que cette section va créer la déclaration de source, c’est-à-dire la fonction appelée depuis le chemin de log, comme nous le verrons plus bas.
Ensuite, nous allons examiner le début du chemin de log lui-même, en commençant à la ligne 32 (ligne 34 tronquée):
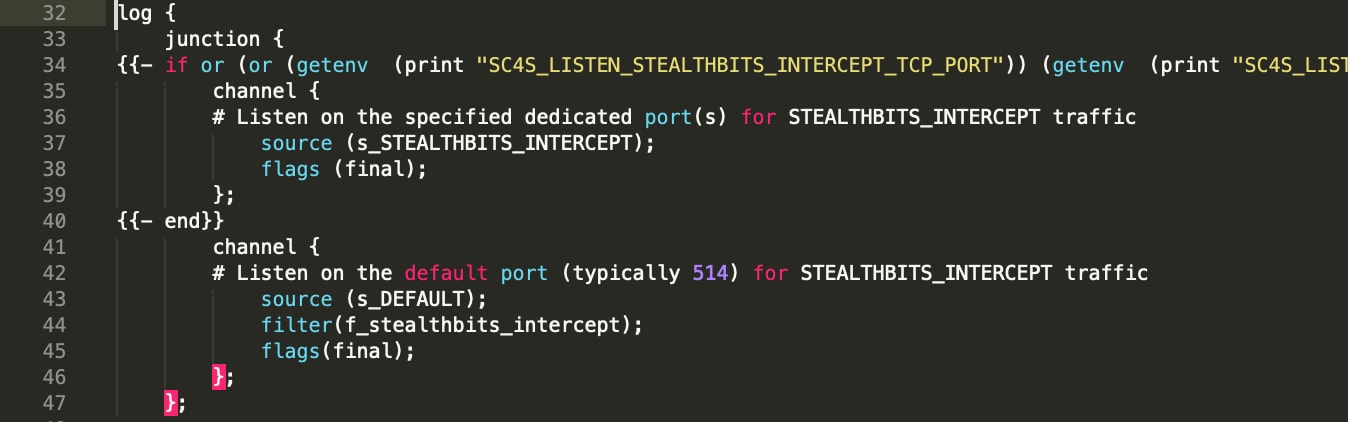
Vous verrez que chaque événement prend deux chemins parallèles à travers un filtre "junction", qui "fusionnent" après la traversée de tous les éléments "channel". Dans le canal supérieur, la nouvelle source appelée s_STEALTHBITS_INTERCEPT est vérifiée. Si des événements arrivent sur cette source (port unique), ils sont transmis au reste du chemin de log sans filtrage supplémentaire. Si, en revanche, l’événement arrive sur le port par défaut s_DEFAULT (généralement UDP ou TCP 514), vous pouvez voir qu’un filtre supplémentaire (f_stealthbits_intercept) doit également être validé, sans quoi l’événement ne sera pas "autorisé à entrer" dans ce chemin de log. Ce filtre peut être déclaré (tout comme la source personnalisée) immédiatement au-dessus de la section log{} du fichier de chemin de log, ou inclus dans un fichier séparé comme indiqué ci-dessous. Comme dans le cas de la source, il s’agit simplement d’une fonction nommée f_stealthbits_intercept :
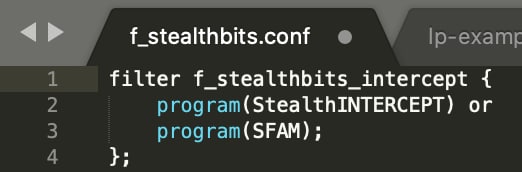
Examinons les lignes 2 et 3. Vous vous souvenez de la capture d’écran du message brut dans Splunk (ci-dessus) ? Recherchez le champ PROGRAM. C’est un exemple de la façon dont l’interprétation initiale de syslog-ng peut être extrêmement utile pour créer des filtres dans les chemins de log, et les lignes 2 et 3 montrent comment ce champ ("macro" dans le langage syslog-ng) est vérifié pour déterminer s’il correspond aux deux valeurs affichées. Vous verrez également dans la section ci-dessous comment la même macro peut être très utile pour attribuer les sourcetypes attendus par la TA.
Dans cette phase du développement, tout le langage de programmation syslog-ng config peut être mis en œuvre. Bien que vous puissiez analyser en profondeur la charge utile de l’événement et même aller jusqu’à l’extraction complète des champs comme dans Splunk, il est préférable de limiter l’interprétation aux métadonnées Splunk qui devront être envoyées avec l’événement à indexer. Ces métadonnées comprennent l’index normal, l’heure, l’hôte, la source et le sourcetype. Notez que le temps est inclus dans cette liste, nous voulons nous assurer qu’il est correctement interpréter avant d’atteindre Splunk, car le traitement de l’horodatage est ignoré (par défaut) avec le point de terminaison /event HEC utilisé par SC4S.
Voici les "entrailles" du chemin de log, où cette attribution de métadonnées a lieu :
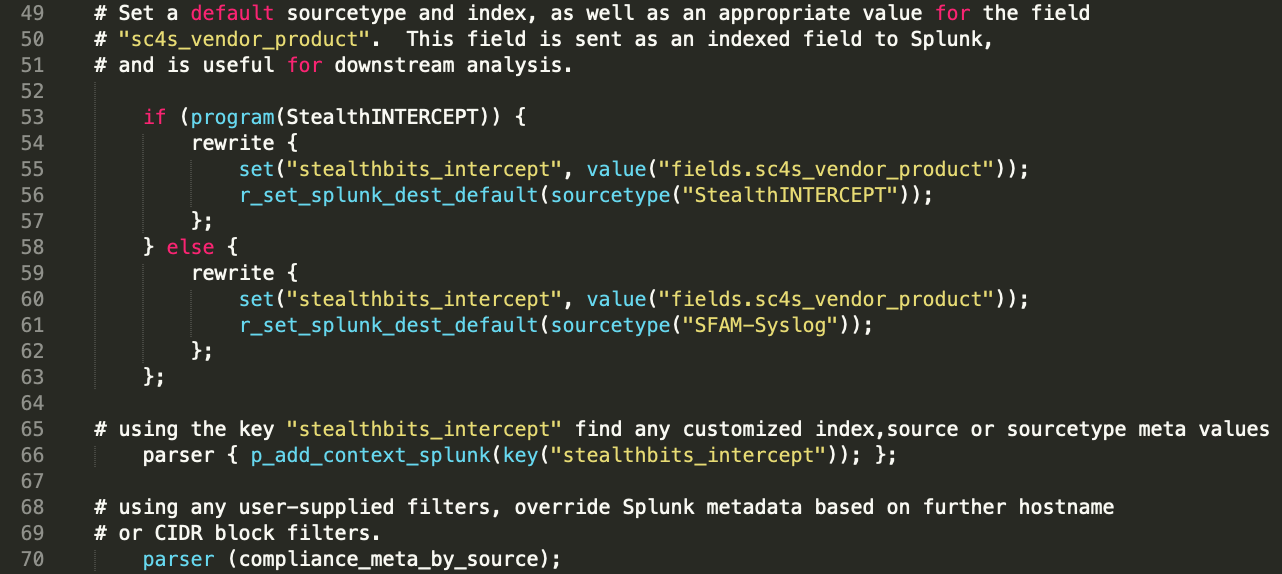
Plusieurs fonctions de réécriture sont mises à la disposition du développeur, comme illustré, de sorte que même cette section peut être "plug and play" pour la plupart des chemins de log. Les valeurs par défaut de toutes les métadonnées Splunk sont définies à l’aide des réécritures aux lignes 56 et 61, et la réécriture utilisée dépend de la valeur de la macro PROGRAM. Encore une fois, l’interprétation syslog-ng initiale a été mise à profit. Vous pouvez voir que le sourcetype est défini lorsque ces fonctions sont appelées, mais aucune autre métadonnée ne l’est. En effet, les autres métadonnées (hôte, heure et source) sont généralement définies au moment de l’acquisition (dans la déclaration de source) et n’ont pas besoin d’être définies (ou remplacées) spécifiquement ici.
Mais qu’en est-il de l’index ? Il est rare qu’on puisse lui appliquer une valeur par défaut. Où pouvons-nous le définir ? À la ligne 66 : c’est celle du parseur qui consulte le fichier splunk_metadata.csv dont nous avons parlé dans la partie 3. Le seul argument passé dans cette fonction est la clé que le développeur attribue (à nouveau, en utilisant la convention fournisseur_produit). De la même façon, les fichiers compliance_meta_by_source.* sont référencés dans l’interpréteur appelé à la ligne 70 et constituent la dernière lookup consultée avant que l’événement ne soit envoyé à une ou plusieurs destinations, comme décrit ci-après.
Une fois toutes les variables définies (y compris plusieurs champs indexés dérivés du parsage syslog-ng initiale), l’événement est prêt à être envoyé à une ou plusieurs destinations. Ces destinations sont fortement contrôlées par des variables d’environnement, ce qui implique plusieurs constructions de modélisation. Cette section du fichier est illustrée ci-dessous :
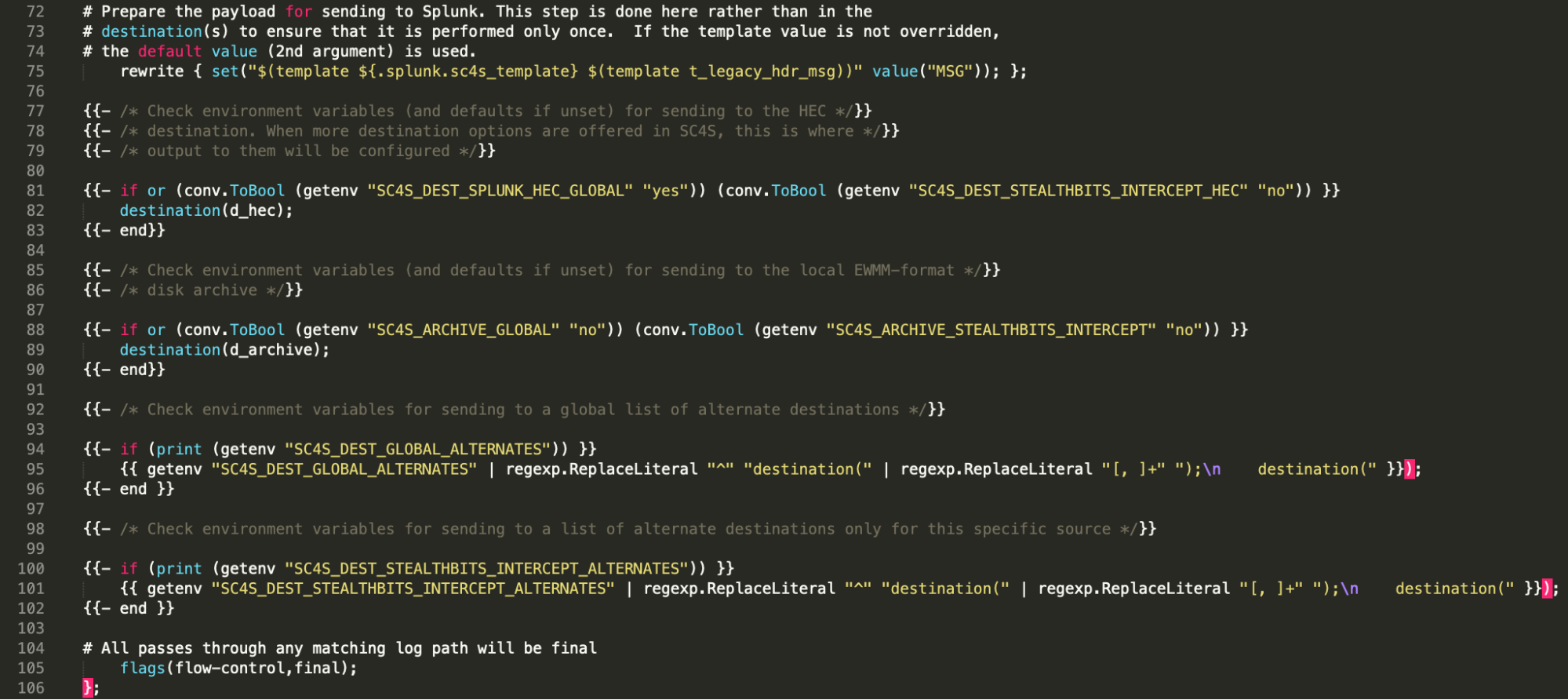
La dernière étape de la préparation de l’envoi est le réglage du modèle de sortie, illustré à la ligne 75. Un modèle par défaut approprié (basé en grande partie sur ce qu’attend la TA) est sélectionné. Ces modèles sont tous documentés et sont construits à partir des différentes macros syslog-ng (PROGRAM, MESSAGE, etc.). Cette valeur par défaut peut être remplacée via splunk_metadata.csv si vous le souhaitez.
Enfin, aux lignes 81 à 102, les variables d’environnement sont consultées et les destinations appropriées sont ajoutées au fichier de configuration final. Le chemin de log se termine ensuite par deux indicateurs : l’un indique à syslog-ng de contrôler le flux du trafic TCP si nécessaire (le flux UDP ne peut pas être contrôlé), et l’autre empêche l’événement d’emprunter un autre chemin de log et met fin à toute poursuite du traitement.
Qu’obtenons-nous une fois que le fichier modèle est passé par le moteur de modélisation gomplate ? Voici la sortie après la modélisation de l’exemple ci-dessus, avec les variables suivantes
SC4S_LISTEN_STEALTHBITS_INTERCEPT_TCP_PORT=5015
SC4S_DEST_GLOBAL_ALTERNATES=d_hec_debug
définies dans le fichier env_file:
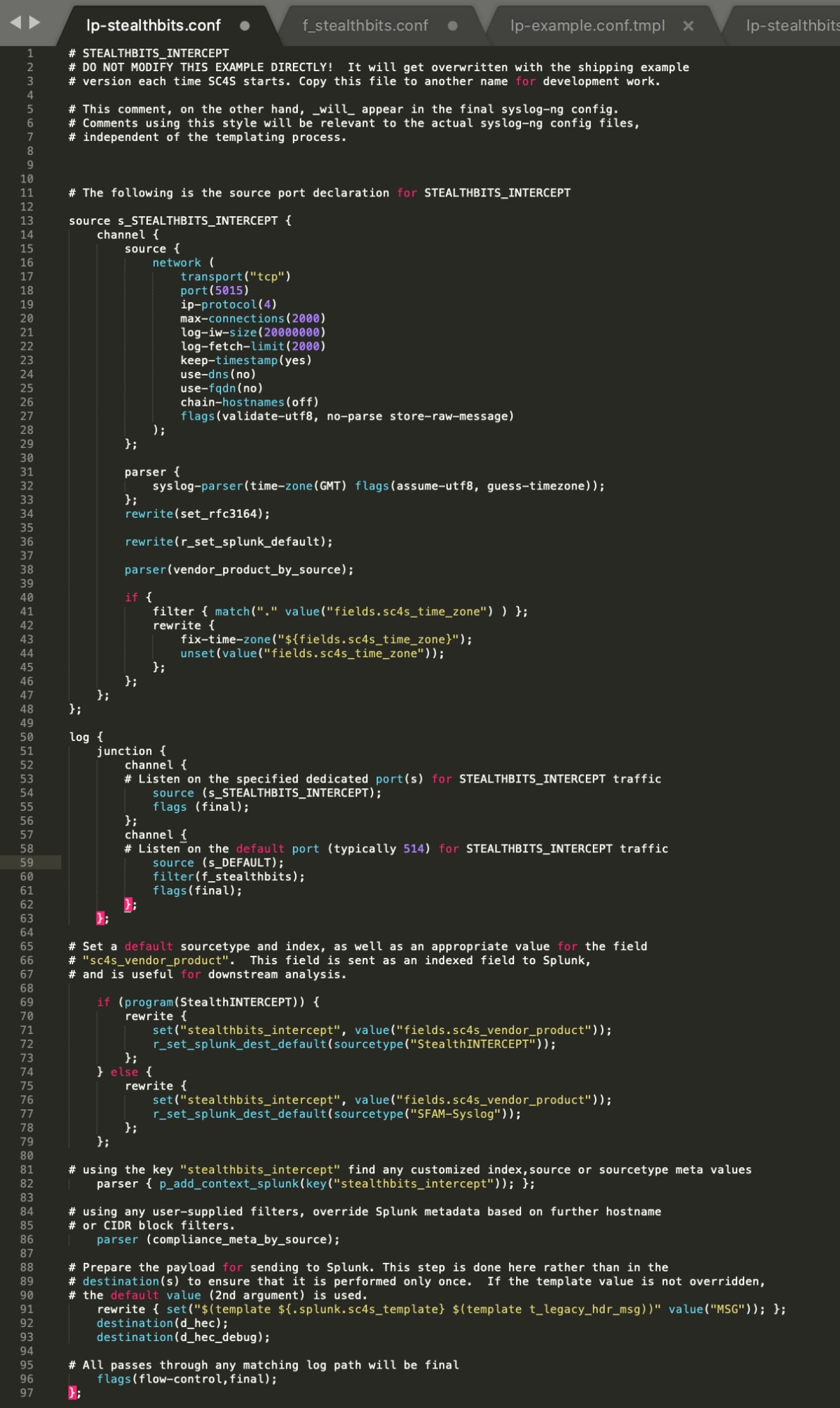
Tout d’abord, vous voyez que tout le code gomplate entre accolades a maintenant disparu. Le fichier commence par la déclaration de source (seulement 3 lignes de code "gomplate") qui s’étend maintenant sur plusieurs lignes (11–48) dans la sortie finale. La déclaration de source gère la plupart des métadonnées initiales et la préparation des champs indexés, ainsi que la configuration de la socket d’écoute sur le port TCP 5015 d’après le paramètre du fichier env_file. Les sections de filtrage et de parsage (lignes 50 à 87) traversent le moteur de modélisation en subissant relativement peu de modifications, tandis que la section de destination (qui couvrait plusieurs lignes de code gomplate) se trouve réduite à 3 lignes de code dans la sortie finale (lignes 91-93) et inclut la destination d_hec_debug, encore une fois à cause du paramètre contenu dans env_file.
Voici le résultat final tel qu’il apparaît dans Splunk. Notez que le format de sortie n’est plus JSON (comme c’est le cas avec les événements de "dernier recours") : il s’agit simplement de l’événement d’origine sans l’en-tête (chaîne, hôte et horodatage). C’est ce à quoi s’attendent la plupart des TA.

Voici quelques conseils utiles au cours du développement :
Nous sommes conscients que ce qui précède n’est qu’un rapide tour d’horizon et que de nombreux détails ont été survolés, en particulier les nuances de la syntaxe de configuration syslog-ng elle-même. La communauté est là pour vous aider à répondre à vos questions ou à relever vos défis de conception ! Bonne chance !
Communauté Splunk Connect for Syslog
De nombreuses ressources sont à votre disposition pour vous aider à réussir avec SC4S ! En plus du dépôt principal et de la documentation, vous pouvez également consulter:
Tous nos vœux de réussite avec SC4S. Impliquez-vous, essayez, posez des questions, proposez de nouvelles sources de données et rencontrez de nouvelles personnes !
De nombreuses ressources sont à votre disposition pour vous aider à réussir avec SC4S ! En plus du dépôt principal et de la documentation, vous pouvez également consulter :
Tous nos vœux de réussite avec SC4S. Impliquez-vous, essayez, posez des questions, proposez de nouvelles sources de données et rencontrez de nouvelles personnes !
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.