
La résilience numérique porte ses fruits
Votre organisation est-elle résiliente ? Découvrez le degré de maturité de votre résilience numérique dans ce guide gratuit.

L’Union européenne élabore actuellement l’une des premières réglementations complètes au monde sur l’intelligence artificielle. Initialement proposé en avril 2021, le projet de loi sur l’IA entre désormais dans sa dernière étape de négociations, et les décideurs politiques ont pour objectif déclaré de s’entendre sur un texte final avant la fin de l’année. Étant donné la portée du règlement et son impact probable au sein de l’UE et en dehors, prenons un moment pour étudier certains sujets clés encore en discussion et les répercussions qu’ils pourraient avoir sur l’adoption de l’IA et l’innovation en Europe.
Splunk utilise l’IA pour accélérer la prise de décision humaine et la met au service de la détection, de l’investigation et de la prise en charge des incidents. Min Wang, Directrice technologique de Splunk, a déclaré dans un récent article de blog : « L’IA peut également améliorer drastiquement la productivité et l’efficacité en soulageant les utilisateurs des tâches rébarbatives et leur permettre de se focaliser sur des activités à plus forte valeur ajoutée. Selon nous, les avantages de l’IA dépassent largement ses inconvénients. C’est pourquoi nous augmentons nos investissements pour perfectionner nos capacités d’IA. » Par exemple, le nouveau Splunk AI Assistant (version bêta) utilise l’IA générative pour proposer une expérience conversationnelle qui aide les clients à apprendre le langage de traitement de recherche SPL et à créer des requêtes en interagissant dans un anglais simple.
L’approche de Splunk en matière d’IA est spécifique à des domaines (elle concerne plusieurs scénarios d’utilisation dans la sécurité et l’observabilité), ouverte et extensible (elle s’intègre facilement à des frameworks tiers) et basée sur la supervision humaine.
Chez Splunk, nous suivons de près les évolutions politiques et réglementaires qui entourent l’IA, et la loi sur l’IA de l’UE occupe une position unique. C’est l’une des premières tentatives de réglementation de l’IA, et nous pensons qu’elle pourrait être une source d’inspiration pour d’autres pays dans un avenir proche. Nous sommes particulièrement désireux de comprendre comment certains principes de la loi sur l’IA de l’UE pourraient être intégrés dans un prochain Code de conduite UE-États-Unis sur l’IA.
Depuis sa publication en 2021, la proposition de loi a suscité un enthousiasme et des réactions passionnées, rarement observés pour un texte législatif à Bruxelles. Au Parlement européen, la rédaction du règlement a été confiée conjointement à deux commissions (dirigées par deux co-rapporteurs, Brando Benifei, socialiste italien et Dragoș Tudorache, libéral roumain) et soumise aux avis de cinq autres commissions. L’IA est l’affaire de tous au Parlement européen. Les commissions principales ont déposé 3 312 (!) amendements en juin 2022, et il a fallu un an au Parlement pour les examiner et adopter une position.
Au sein du Conseil, les discussions ont progressé plus rapidement. Sous l’impulsion de la présidence française de l’UE (de juillet à décembre 2022), le Conseil a adopté son orientation générale en décembre 2022. Les deux institutions sont désormais prêtes à entamer des « trilogues » avec la Commission européenne. Au cours de ces négociations à huis clos, les décideurs politiques examinent le texte article par article et tentent de parvenir à un consensus. La position du Parlement est le résultat d’un compromis délicat entre les groupes politiques, et les co-rapporteurs disposent de très peu de marge de manœuvre dans les négociations en cours.
À ce jour, trois trilogues ont déjà eu lieu (en juillet et début octobre) et un autre doit se tenir le 25 octobre. Des pressions sont exercées sur la présidence espagnole de l’UE et sur les rapporteurs du Parlement pour conclure les négociations d’ici la fin du mois d’octobre.
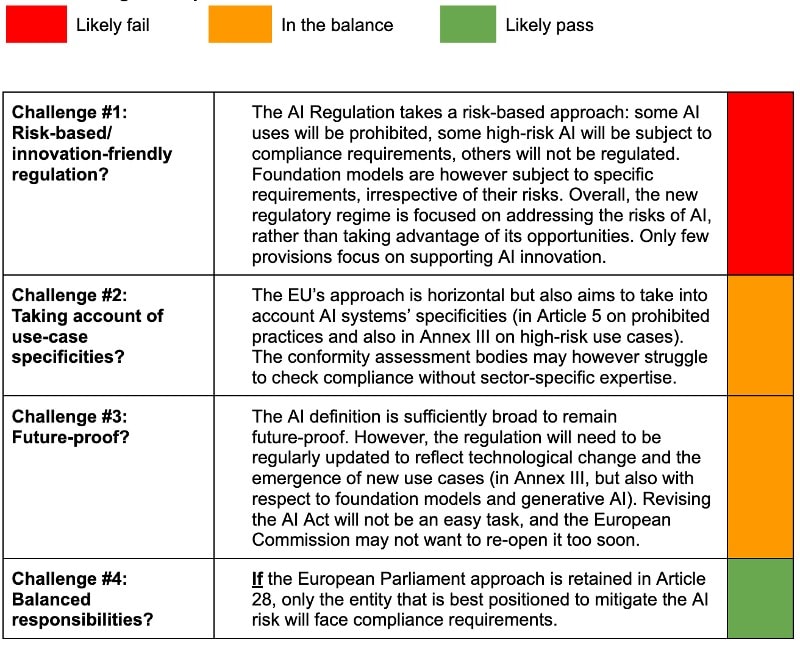
Depuis la proposition, l’ambition de la Commission européenne n’a pas changé : réglementer les usages à risque de l’IA (pour la santé, la sécurité et les droits fondamentaux) sans compromettre la capacité de l’Europe à innover avec l’IA. C’est le défi n° 1.
La Commission visait également à développer un cadre horizontal appliquant des règles communes à tous les secteurs, tout en tenant compte de certaines spécificités. C’est le défi n° 2.
Les institutions européennes se sont également efforcées de mettre en place une réglementation évolutive, capable de suivre les progrès technologiques. C’est le défi n° 3.
Enfin, la chaîne de valeur de l’IA est complexe : différents acteurs sont impliqués dans la conception, le développement et le déploiement des systèmes d’IA. Les obligations éventuelles devraient incomber à l’entité la mieux placée pour atténuer le risque de préjudice associé à un système d’IA donné. Trouver le juste équilibre entre les différentes responsabilités est le défi n° 4.
Je considère ces défis comme des tests pertinents pour évaluer l’efficacité et les performances du règlement final sur l’IA. Je vous propose d’examiner les questions qui seront discutées dans les trilogues en nous demandant comment le texte final passera ces quatre tests. Consultez notre tableau d’évaluation à la fin de ce blog pour une première évaluation !
Qu’est-ce que l’IA ? Il existe autant de définitions que de personnes ou d’organisations qui cherchent à en produire une. Pour l’OCDE, « Un système d'IA est un système qui fonctionne grâce à une machine et capable d'influencer son environnement en produisant des résultats (tels que des prédictions, des recommandations ou des décisions) pour répondre à un ensemble donné d'objectifs ». Le gouvernement britannique préfère définir l’IA comme « l’utilisation d’une technologie numérique pour créer des systèmes capables d’effectuer des tâches généralement considérées comme nécessitant de l’intelligence ».
La définition de l’IA (en Annexe I) initialement proposée par la Commission européenne a été jugée trop large, car elle couvrait des techniques qui ne relevaient pas toujours de l’IA, mais « simplement » de logiciels traditionnels. Le Parlement et le Conseil ont donc proposé de supprimer l’Annexe I. Entre-temps, le Parlement a proposé une nouvelle définition à l’article 3, paragraphe 1, alignée sur celles de l’OCDE et capable de résister à l’épreuve du temps : « un système basé sur une machine conçu pour fonctionner avec différents niveaux d’autonomie et qui peut, pour des objectifs explicites ou implicites, générer des résultats tels que des prédictions, des recommandations ou des décisions qui influencent les environnements physiques ou virtuels ». L’OCDE travaille sur une nouvelle définition de l’IA (qui devrait être prête d’ici octobre ou novembre), et celle-ci pourrait avoir un impact sur les négociations de l’UE sur le sujet.
Certains systèmes d’IA présentent un niveau de risque considéré comme inacceptable et seront donc interdits par la prochaine réglementation. Par exemple, les États membres et le Parlement ont convenu que les systèmes de notation sociale seraient interdits. La liste définitive des pratiques interdites sera cependant une question très politique. Certains États membres souhaitent conserver la possibilité d’utiliser des systèmes d’identification biométrique à distance « en temps réel » à des fins répressives (sous certaines conditions), tandis que le Parlement européen souhaite interdire leur utilisation dans l’espace public.
Le Parlement estime que les systèmes de police prédictive (basés sur le profilage, la localisation ou le comportement criminel passé) doivent également être interdits, ainsi que les systèmes de reconnaissance des émotions dans les domaines de la police et de la gestion des frontières, sur le lieu de travail et dans les établissements d’enseignement. La position du Parlement sur les interdictions est jugée inacceptable par des États membres, qui souhaitent rester libres d’utiliser certains systèmes d’IA à des fins répressives.
Les systèmes d’IA à haut risque seront autorisés, mais sous réserve du respect d’exigences en matière d’IA et d’une évaluation de conformité au préalable. Les systèmes d’IA à haut risque sont répertoriés à l’Annexe III du règlement sur l’IA. Les scénarios d’utilisation critiques qui y sont répertoriés font l’objet d’un large consensus, mais le Parlement européen a ajouté certains cas d’usage, notamment les systèmes d’IA « utilisés pour influencer le résultat d’une élection (…) ou le comportement électoral de personnes physiques ».
En outre, l’article 6(2) vise à affiner cette liste en offrant une définition de ce qui constitue un « risque élevé ». Le Parlement européen insiste sur « le risque important d’atteinte à la santé, à la sécurité ou aux droits fondamentaux des personnes physiques », tandis que le Conseil propose de considérer tous les scénarios d’utilisation répertoriés à l’Annexe III comme à haut risque, « sauf si le résultat du système est purement accessoire et n’est donc pas susceptible d’entraîner un risque significatif pour la santé, la sécurité ou les droits fondamentaux ». Nous soutenons l’approche du Parlement au titre de l’article 6, paragraphe 2, qui offre plus de certitude.
Les exigences de conformité des systèmes d’IA à haut risque ne suscitent que peu de débats entre les États membres et les parlementaires. La liste finale des obligations a déjà été en grande partie convenue et devrait donc porter sur la gouvernance des données, la documentation technique, la tenue de registres (journalisation), la transparence, la supervision humaine, l’exactitude, la robustesse et la cybersécurité.
Nous prévoyons toutefois des discussions concernant la demande du Parlement d’introduire une « évaluation d’impact sur les droits fondamentaux » pour les systèmes d’IA à haut risque avant leur mise sur le marché de l’UE, car certaines délégations nationales jugent cette exigence excessive.
Comme mentionné précédemment, la chaîne d’approvisionnement de l’IA est complexe. Depuis 2021, les États membres et les députés cherchent le bon équilibre entre les responsabilités des différents acteurs de la chaîne d’approvisionnement. Le Parlement propose une approche raisonnable dans ses amendements à l’article 28 : tout distributeur, importateur, déployeur ou autre tiers sera soumis aux obligations de conformité du fournisseur s’il place un système d’IA ne présentant pas de risque élevé dans un environnement à haut risque. En bref, l’entité qui décide de la destination du système d’IA est considérée comme le « nouveau » fournisseur et responsable de la conformité. Le fournisseur « initial » devra toutefois fournir au « nouveau » fournisseur la documentation technique nécessaire pour répondre aux exigences et respecter ses obligations. Cette approche nous semble logique et nous espérons qu’elle sera retenue dans le texte final.
Les négociations sur la loi sur l’IA tiennent compte des évolutions du marché et de la technologie. Si l’année 2022 a été consacrée à la régulation de « l’IA à usage général » (voir le nouveau Titre IA de l’Orientation générale du Conseil), 2023 a surtout été celle de l’IA générative et des modèles de fondation de l’IA, suite à l’adoption très rapide de ChatGPT (100 millions d’utilisateurs seulement 2 mois après son lancement !). Le Parlement européen a proposé de réglementer les modèles de fondation, quel que soit le risque qu’ils présentent, allant à l’encontre de l’approche initiale de la Commission européenne, basée sur le risque. Le Conseil n’a pas encore décidé si les mesures de sauvegarde doivent cibler en priorité les modèles de fondation, l’IA à usage général ou les deux.
Selon le Parlement, un modèle de fondation est « un modèle d’IA entraîné à grande échelle sur d’importants volumes de données, conçu pour produire des résultats généraux et pouvant être adapté à un large éventail de tâches distinctes ». Le Parlement souhaite également que les modèles de fondation répondent à certaines exigences avant leur mise sur le marché européen : atténuation des risques, gouvernance des données, garantie des niveaux de « performance, prévisibilité, interprétabilité, possibilité de correction, sûreté et cybersécurité », efficacité de la consommation en énergie et en ressources du modèle, documentation technique, système de gestion de la qualité, enregistrement du modèle.
Certaines de ces exigences vont très loin, comme l’identification et l’atténuation de « tous les risques raisonnablement prévisibles pour la santé, la sécurité, les droits fondamentaux, l’environnement, la démocratie et l’État de droit ». Il semble très difficile pour les fournisseurs de prédire et d’atténuer ces risques, car la conception de ces modèles de fondation a une visée généraliste. Garantir les performances de tels modèles tout au long de leur cycle de vie semble également presque impossible, dans la mesure où le fournisseur d’origine aura peu de contrôle sur la manière dont le modèle sera déployé par des tiers.
Les négociateurs du Conseil et du Parlement devront se mettre d’accord sur des exigences réalisables pour les développeurs et déployeurs de modèles de fondation, grands et petits, sans quoi ces exigences pourraient devenir un obstacle à la conception et au déploiement de l’IA en Europe. Kai Zenner, Conseiller en politique numérique du député européen Axel Voss, a proposé de limiter l’application de ces exigences aux modèles de fondation systémiques, c’est-à-dire aux modèles de fondation jugés « d’importance systémique » selon des indicateurs tels que les sommes investies dans le modèle ou la quantité de calcul impliquée.
Le Parlement européen a également proposé des règles spécifiques pour encadrer l’IA générative. Les systèmes d’IA générative basés sur des modèles de fondation, comme ChatGPT, devraient se conformer à des exigences de transparence (divulguer que le contenu a été généré par l’IA, faciliter la distinction des images dites « deepfakes » des images réelles) et offrir des garanties contre la génération de contenu illégal. Des résumés détaillés des données protégées par le droit d’auteur et utilisées pour leur entraînement devraient également être rendus publics.
Certains États membres comme la France ont exprimé leurs inquiétudes face aux obligations supplémentaires visant les modèles de fondation et l’IA générative, et s’inquiètent de l’impact d’une réglementation excessive sur l’innovation en matière d’IA en Europe.
Pour conclure, n’oublions pas les dispositions qui doivent favoriser l’innovation en IA. Elles arrivent vers la fin du texte et ne représentent malheureusement qu’une toute petite partie du règlement (seulement 2 ou 3 articles sur 85). Le principe des bacs à sable est bien connu : des systèmes d’IA innovants peuvent être développés, entraînés, testés et validés sous le contrôle d’une autorité compétente avant leur mise sur le marché.
Deux visions s’opposent sur le sujet des bacs à sable : les États membres souhaitent que la création de bacs à sable réglementaires pour l’IA se fasse sur la base du volontariat au niveau national, tandis que le Parlement européen tient à ce que chaque État membre établisse au moins un bac à sable national pour l’IA avant la date d’application du règlement. Certains États membres ont progressé plus rapidement que d’autres : l’Espagne a déjà lancé son bac à sable IA réglementaire en 2022.
Nous comprenons qu’un accord a déjà été trouvé sur ce point : les bacs à sable seront obligatoires, mais les États membres qui ne sont pas en mesure de développer leur propre bac à sable seront autorisés à rejoindre ceux d’autres États membres ou à en créer un conjointement.
Le but de ce tableau est d’évaluer dans quelle mesure le règlement sur l’IA peut relever les quatre « défis » décrits au début de cet article.
Le règlement sur l’IA relèvera-t-il les 4 défis?
J’espère que cet examen des problématiques de l’IA vous a été utile. Si vous souhaitez avoir un point de vue privilégié sur les sujets clés qui seront abordés dans les trilogues, je vous recommande cette interview de Kai Zenner.
J’ai l’intention de mettre à jour ce tableau d’évaluation lorsque le texte final du règlement sur l’IA sera adopté, probablement vers la fin de l’année. Restez à l’écoute !

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.