Les cinq principes de l’observabilité
Observability Splunk
Dans cet article, j’expliquerai brièvement ce qu’est l’observabilité, ce dont un système a besoin pour vous offrir une véritable observabilité et comment entamer vous-même le voyage vers l’observabilité.
L’observabilité est un état d’esprit qui vous permet de répondre à des questions sur votre entreprise, de l’expérience utilisateur, à travers l’application elle-même, jusqu’aux indicateurs commerciaux et processus activés par l’application. C’est une évolution de la supervision qui augmente considérablement le volume de données ingérées et augmente radicalement le nombre et le type de questions auxquelles vous pouvez répondre. Il ne s’agit pas seulement des « métriques, traces et logs » : l’observabilité consiste en réalité à tout instrumenter et à utiliser ces données pour prendre de meilleures décisions. J’ai approfondi ce sujet dans un autre article, Observabilité : ce n’est pas ce que vous pensez, que je vous invite à consulter pour une analyse détaillée de l’observabilité.
Avant de travailler chez Splunk, j’ai été SRE (enfin, administrateur système dans l’un de mes emplois, mais je suis vieux.) D’expérience, je sais à quel point l’observabilité de qualité professionnelle est importante, car j’ai résolu par le passé un grand nombre de problèmes dans lesquels j’aurais aimé me plonger à l’aide d’un système d’observabilité comme celui que nous vendons chez Splunk. Dans la suite de cet article, je vais discuter des cinq fonctions qu’un système d’observabilité doit avoir pour que votre investissement en vaille la peine, et je vais également donner quelques exemples tirés de mon expérience dans les opérations pour expliquer en quoi elles sont essentielles.
Qu’est-ce qui différencie un produit d’observabilité d’un autre ?
Chaque fournisseur vous dira qu’en achetant son produit et en l’installant, vous « obtenez » instantanément l’observabilité. Dans tous les cas, y compris en achetant notre produit, ce n’est pas vrai. Cependant, ce que vous obtenez en ouvrant la boîte varie considérablement. Lorsque vous réfléchissez à ce qu’une solution d’observabilité doit vous apporter, vous devez penser à certains éléments qui ne figurent pas nécessairement sur le site web et ne sont pas toujours abordés dans les critiques. Dans la section suivante, je vais vous présenter ce qui, selon moi, constitue les cinq principes fondamentaux d’un système d’observabilité. Ils s’appliquent à n’importe quel système, commercial ou interne, et ont un impact réel sur la valeur que vous pouvez obtenir de l’adoption de l’observabilité.
Les cinq principes clés de l’observabilité
Lorsque vous évaluez un système d’observabilité, gardez en tête ces cinq grands principes : visibilité de bout en bout sur l’intégralité de la pile ; réponses en temps réel ; informations basées sur l’analyse ; dimensions et fonctionnalités professionnelles ; normes ouvertes. Abordons chacun de ces éléments plus en détail :
De bout en bout, sur l’intégralité de la pile
Adopter une plateforme d’observabilité qui ne peut pas vous donner une visibilité à 100 % sur toutes vos transactions, du navigateur de l’utilisateur à votre application, en passant par la plateforme commerciale sous-jacente, c’est prendre le risque de manquer des informations vitales. Cela implique donc de prendre en charge des capacités telles que la RUM pour déterminer le comportement du navigateur de l’utilisateur, mais aussi d’éviter l’échantillonnage (lisez ce post pour comprendre pourquoi l’échantillonnage est contraire à l’observabilité). En plus de l’expérience de l’utilisateur, vous devrez également obtenir des informations sur les performances du back-end, notamment sur les requêtes à la base de données ou le profilage du code.
Je ne sais combien de problèmes j’ai dû résoudre chez LinkedIn parce que quelqu’un d’important avait envoyé un rapport de bug à la liste de diffusion sre@. Quand cela se produit, vous n’avez pas d’autre choix que de comprendre ce qui s’est passé et trouver une solution. Si nos outils n’avaient pas été en mesure de visualiser l’historique de bout en bout de tous nos utilisateurs, je n’aurais sans doute pas pu résoudre ces problèmes du tout, ou bien cela aurait pris beaucoup plus de temps que nécessaire.
Temps réel

Dans l’un de mes premiers emplois techniques, un problème nous a été signalé par un appel téléphonique du Directeur technique, avant que nos alertes ne nous indiquent quoi que ce soit. Pendant qu’il expliquait le problème, les alertes ont commencé à se manifester, mais le problème était déjà présent depuis près de 15 minutes. Ce problème de désynchronisation par rapport à la survenue du problème peut arriver à n’importe qui.
Basée sur l’analyse
Le volume de données généré par un système d’observabilité est astronomique. Vous ne pouvez pas y échapper : vous avez donc besoin d’un outil pour interpréter ces données et suggérer des pistes pertinentes. Une plateforme d’observabilité doit rendre les problèmes plus faciles à résoudre, et non l’inverse. Se contenter d’ajouter de l’instrumentation et donc des volumes considérables de données dans un système sans aucun moyen de mettre en évidence les éléments importants va aggraver vos problèmes.
Si vous n’avez pas de moyen de les analyser, ajouter des informations à un système d’observabilité peut se retourner contre vous. Dans l’un de mes emplois précédents, presque tous les services fonctionnaient dans une JVM. Naturellement, il était logique de collecter des statistiques de mémoire JVM et de produire ensuite des alertes en cas d’utilisation excessive de la mémoire, de temps de pause du GC, etc. Ce que nous n’avions pas prévu en ajoutant ces métriques, c’était le nombre d’événements qui seraient générés par des problèmes mineurs touchant une seule application. L’outil d’alerte ne supprimait pas les doublons et il y avait des milliers d’événements à effacer manuellement chaque fois que l’applicatif changeait suffisamment pour modifier les modèles d’allocation de mémoire dans une application. Ces modèles n’avaient aucun impact sur l’utilisateur, l’application se comportait simplement différemment pour nous. Un bon outil d’analyse aurait au moins éliminé les doublons, et au mieux indiqué que les changements n’avaient pas d’incidence sur les indicateurs côté clients et ne méritaient donc pas une investigation immédiate.
Niveau entreprise
Oui, je sais que le mot « entreprise » ouvre la porte à tous les slogans commerciaux, mais un système d’observabilité robuste doit remplir de nombreuses fonctions qui vont au-delà de la simple supervision. Votre système devra probablement fonctionner sur plusieurs clouds (et probablement quelques systèmes locaux). Et comme vous allez vous appuyer dessus, il doit rester fonctionnel au fil de votre croissance et quel que soit le nombre de services que vous administrez. Si votre infrastructure prend encore de l’envergure, de véritables fonctionnalités « entreprise » comme le RBAC, les jetons d’accès et la comptabilité vont devenir indispensables. Le pire serait que vous ayez besoin de ces fonctionnalités mais qu’elles ne soient pas disponibles : vous devriez alors changer d’outils d’observabilité, ce qui vous ferait perdre un temps considérable inutilement.
Normes ouvertes

Les avantages pour vous
Pour commencer votre parcours d’observabilité, vous devez vous assurer que la plateforme que vous choisissez respecte ces cinq principes clés. Splunk Observability Cloud est conçu pour répondre à ces besoins, en plus de vous donner un emplacement unique pour visualiser l’ensemble de vos opérations, qu’il s’agisse d’un monolithe local ou d’un déploiement Kubernetes distribué à l’échelle mondiale, de prendre en charge de l’observabilité en tant que code via Terraform, etc.
Vous pouvez commencer un essai gratuit sans carte de crédit et en faire l’expérience par vous-même, ou visionner une démonstration sur la page de présentation générale du produit.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.
Articles similaires
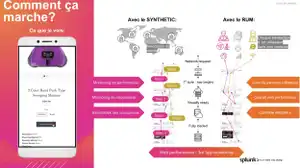
Mesurer l’expérience des utilisateurs : deux technos à connaître
OTel(l) Me How to : Ping — ICMP avec le Splunk OpenTelemetry Collector
