
Créer une pratique d’observabilité de pointe

Les logiciels d’aujourd’hui sont incroyablement complexes et génèrent des quantités considérables de données. Métriques, logs et traces sont générés en permanence par des centaines de services, même pour des applications très simples. Chaque transaction peut générer des kilooctets de métadonnées ; même un faible taux de transactions simultanées peut produire plusieurs mégaoctets de données par seconde, soit près de 300 Go par jour, qu’il faut capturer et analyser. Cette échelle ne fait que croître avec la multiplication des utilisateurs et des services de votre application. Les questions que vous vous posez sur votre entreprise sont légion et il vous faut des données pour y répondre : combien de temps mes clients passent-ils sur mon site ? Que devient l’expérience utilisateur si l’un de mes services ralentit ? Comment savoir s’il y a un problème, tout simplement ? Tout cela repose sur l’observabilité, qui s’appuie sur les données.
Pour gérer toutes ces données, une solution consiste à les envoyer dans un système d’observabilité. C’est la solution la plus simple et la plus évidente, et elle vous garantit de ne rien laisser de côté. Mais le défi est double : le coût d’abord, et les capacités ensuite. La plupart des outils d’observabilité sont facturés en fonction du volume de données que vous y envoyez. Plus vous envoyez de données, plus vous payez. Pire encore, de nombreux fournisseurs vous demandent d’évaluer à l’avance la quantité de données que vous allez envoyer, et vous pénalisent financièrement si vous ne lisez pas assez bien l’avenir. De plus, de nombreux systèmes sont tout simplement incapables de gérer de grands volumes de données. Ils ne sont pas faits pour tout importer et se contentent de « la plupart des données ». Lorsque votre entreprise grandit et que vos flux de données approchent les centaines de Mo, de Go ou même de To de données par secondes, votre plateforme d’observabilité doit être à la hauteur.
 Pour contourner ces problèmes, beaucoup de fournisseurs vous proposent « d’échantillonner » (autrement dit, jeter une partie de) vos données. Ils vous présentent cette approche comme un moyen de faire des économies : en vous envoyant moins de données, ils facturent moins pour leur analyse et leur stockage. Toutefois, l’élimination d’une partie des données est lourde de conséquences. Dans de nombreux cas, les fournisseurs d’observabilité vendent l’échantillonnage sans en tenir compte, et ils le font parce que leurs systèmes sont en réalité incapables de gérer le volume de données produit par les systèmes d’aujourd’hui.
Pour contourner ces problèmes, beaucoup de fournisseurs vous proposent « d’échantillonner » (autrement dit, jeter une partie de) vos données. Ils vous présentent cette approche comme un moyen de faire des économies : en vous envoyant moins de données, ils facturent moins pour leur analyse et leur stockage. Toutefois, l’élimination d’une partie des données est lourde de conséquences. Dans de nombreux cas, les fournisseurs d’observabilité vendent l’échantillonnage sans en tenir compte, et ils le font parce que leurs systèmes sont en réalité incapables de gérer le volume de données produit par les systèmes d’aujourd’hui.
L’échantillonnage des données peut vous empêcher de voir des problèmes critiques. Si vous avez un système qui se comporte normalement la plupart du temps mais présente parfois des problèmes passagers avec des pics de latence dépassant 5 secondes, par exemple, la méthodologie d’échantillonnage peut échouer à les capturer en temps voulu, voire les ignorer totalement. Imaginez un instant que ces pics de latence ne se produisent qu’en cas de grosse commande. Imaginez que ces pics de latence incitent les clients à annuler ces commandes. Chaque commande annulée, c’est de l’argent qui n’entre pas dans vos caisses. Si votre application est instable ou lente, les utilisateurs vont se plaindre sur les réseaux sociaux, et cette dégradation de la confiance vous coûtera encore plus cher.
Fondamentalement, l’échantillonnage contredit l’observabilité.
Il existe diverses manières de contourner le problème des données manquantes, comme vous le diront les fournisseurs adeptes de la pratique, mais fondamentalement, l’échantillonnage contredit l’observabilité. Vous ne pouvez tout simplement pas avoir des informations complètes sur un système si vous ignorez délibérément une partie de ce qu’il produit.
Illustrons le problème avec un exemple. De nombreux fournisseurs d’outils d’observabilité qui vendent des systèmes basés sur l’échantillonnage vous diront que des données échantillonnées offrent les mêmes informations que la moyenne de toutes les données, mais c’est une contre-vérité. Dans l’exemple ci-dessous, nous présentons les métriques de durée des appels à un service de traitement de commande. Ce service de traitement des commandes, comme bien d’autres services, a parfois du mal à tenir le rythme de la demande et affiche des pics de durée.
Vous pouvez voir toutes les données dans la colonne la plus à gauche. Vous pouvez également les voir analysées par un système d’échantillonnage naïf qui prélève une donnée sur trois (notez que la plupart des fournisseurs qui pratiquent l’échantillonnage prélèvent bien moins de 33 % des événements), puis analysées par un système d’échantillonnage « de pointe », qui applique l’échantillonnage naïf décrit précédemment et capture également toute transaction d’une durée supérieure à 1000 ms :
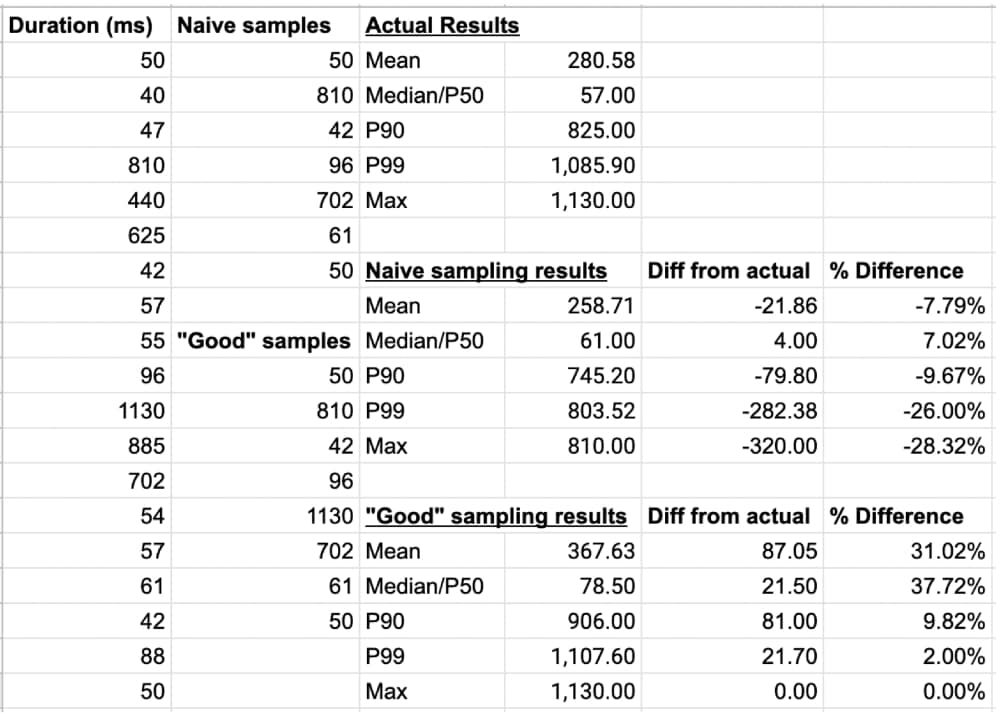
Comme vous pouvez le voir, les systèmes reposant sur l’échantillonnage ne donnent pas une image précise de la situation. Ces deux systèmes sont dans l’incapacité de vous montrer l’état réel de votre système. Selon la métrique que vous choisissez, les systèmes d’échantillonnage peuvent sous-estimer ou surestimer la durée de près de 38 % ! De nombreux systèmes traditionnels sont conçus pour traiter des moyennes mais aujourd’hui, avec l’utilisation de SLOs et de budgets d’erreur, les moyennes ne sont plus d’aucune utilité. Les centiles offrent une représentation plus précise de l’état de vos services et les systèmes d’échantillonnage les interprètent mal dans notre exemple ci-dessus.
Enfin, discutons brièvement de l’effort d’instrumentation nécessaire à la mise en place de l’observabilité. À moins que vous n’utilisiez un système intégrant OpenTelemetry nativement, vous avez certainement dû installer un agent lourd et instrumenter manuellement toutes vos applications afin de transmettre les métriques, les traces et les logs. Même avec un système basé sur OpenTelemetry, des efforts de développement ont été nécessaires pour configurer et mettre en place l’instrumentation, et vérifier que toutes les données utiles parvenaient bien à la plateforme d’observabilité.
L’échantillonnage réduit cet effort à néant. En utilisant un outil d’observabilité qui échantillonne vos données, vous réduisez la valeur de votre plateforme d’observabilité et vous n’exploitez pas pleinement l’investissement réalisé dans l’instrumentation des applications au départ. Pourquoi perdre du temps et de l’argent à créer des systèmes capables d’émettre toutes ces données pour en jeter la moitié en chemin ? Cela n’a pas de sens, et ce n’est certainement pas un moyen de faire des économies. C’est même tout le contraire, car vous risquez de passer à côté d’informations cruciales au moment le plus important.
Si vous cherchez un système qui ne jette pas vos données par la fenêtre et a été conçu pour traiter les données à grande échelle, il vous faut Splunk Observability Cloud. Commencez dès aujourd’hui votre essai gratuit de Splunk Observability Cloud.
Pour en savoir plus sur l’observabilité en général, lisez le Guide pratique de l’observabilité.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.
----------------------------------------------------
Thanks!
Splunk

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.