
Le Guide essentiel des données
Les données sont complexes. Éliminez cette complexité et concrétisez la valeur qu’elles renferment avec ce guide gratuit.

Les entreprises utilisent le cloud pour sa grande flexibilité en termes de puissance de calcul et d’espace de stockage, pour mieux répondre à l’évolution de leurs besoins métiers. Mais on voit également émerger un autre modèle de déploiement : l’edge computing, ou informatique de périphérie. Gartner estime en effet que 75 % des données générées par les entreprises seront produites et traitées en périphérie en 2025.
À l’heure où les entreprises cherchent à exploiter de nouveaux cas d’usage, notamment l’intelligence artificielle, l’automatisation et les applications de machine learning, l’edge computing s’annonce comme un moyen stratégique de réduire la latence et d’améliorer les performances globales. Pour les entreprises, elle ouvre la voie à des innovations dans de nombreux domaines :
Mais l’edge computing recouvre une réalité variée. Il en existe plusieurs types, qui répondent aux besoins d’une diversité de structures métiers, d’objectifs et de scénarios d’utilisation. Voici ce que vous devez savoir sur les différents types d’edge computing pour trouver celui qui soutiendra votre entreprise.
L’edge computing est un modèle informatique situé à la source des données ou à proximité. En anglais, le mot « edge » signifie « bordure ».
Traditionnellement, la plupart des données sont traitées par des systèmes centralisés, via de grands fournisseurs de cloud comme AWS et Microsoft Azure. Si vous n’êtes pas au centre, vous êtes en bordure du réseau, à la « périphérie », d’où le terme d’edge computing ou informatique de périphérie.
Lorsque l’informatique se rapproche des sources de données, les services deviennent plus rapides et plus fiables. Les entreprises bénéficient également d’une grande flexibilité, car l’edge computing leur permet d’utiliser et de distribuer leurs ressources sur plusieurs sites.
Aujourd’hui, l’edge computing joue un rôle particulièrement critique dans beaucoup d’environnements cloud (mais pas tous, loin de là). L’infrastructure cloud est souvent poussée dans ses retranchements par l’abondance de services et d’applications qu’elle soutient. Elle parvient péniblement à traiter les données des appareils connectés, et il lui est encore plus difficile de générer des informations et des actions en quasi temps réel sur la base de ces données. Le cloud computing parvient difficilement à suivre le rythme de cette explosion de services et d’applications en raison de la latence, souvent causée par la distance entre le réseau et la source de données.
Qu’elles soient internes ou tournées vers le client, si vous avez des applications qui ont besoin d’analyser des données et de répondre en quasi temps réel, l’edge computing est fait pour vous !
Certes, la plupart des données informatiques se trouvent encore aujourd’hui dans des datacenters centralisés. Mais dans plusieurs, l’edge computing peut être un puissant atout :
Si la plupart des entreprises misent sur la périphérie, c’est parce qu’elle permet de rapprocher les capacités de traitement des appareils des utilisateurs finaux. Cela réduit le temps nécessaire pour interpréter les données et y réagir. L’informatique de périphérie peut être répartie en plusieurs couches de points d’accès. Pour les distinguer, voici quelques critères :
Ces facteurs influencent les choix de conception, d’architecture et de déploiement de la mise en œuvre concrète. Il faut impérativement commencer par établir vos besoins avant de modifier votre infrastructure actuelle.
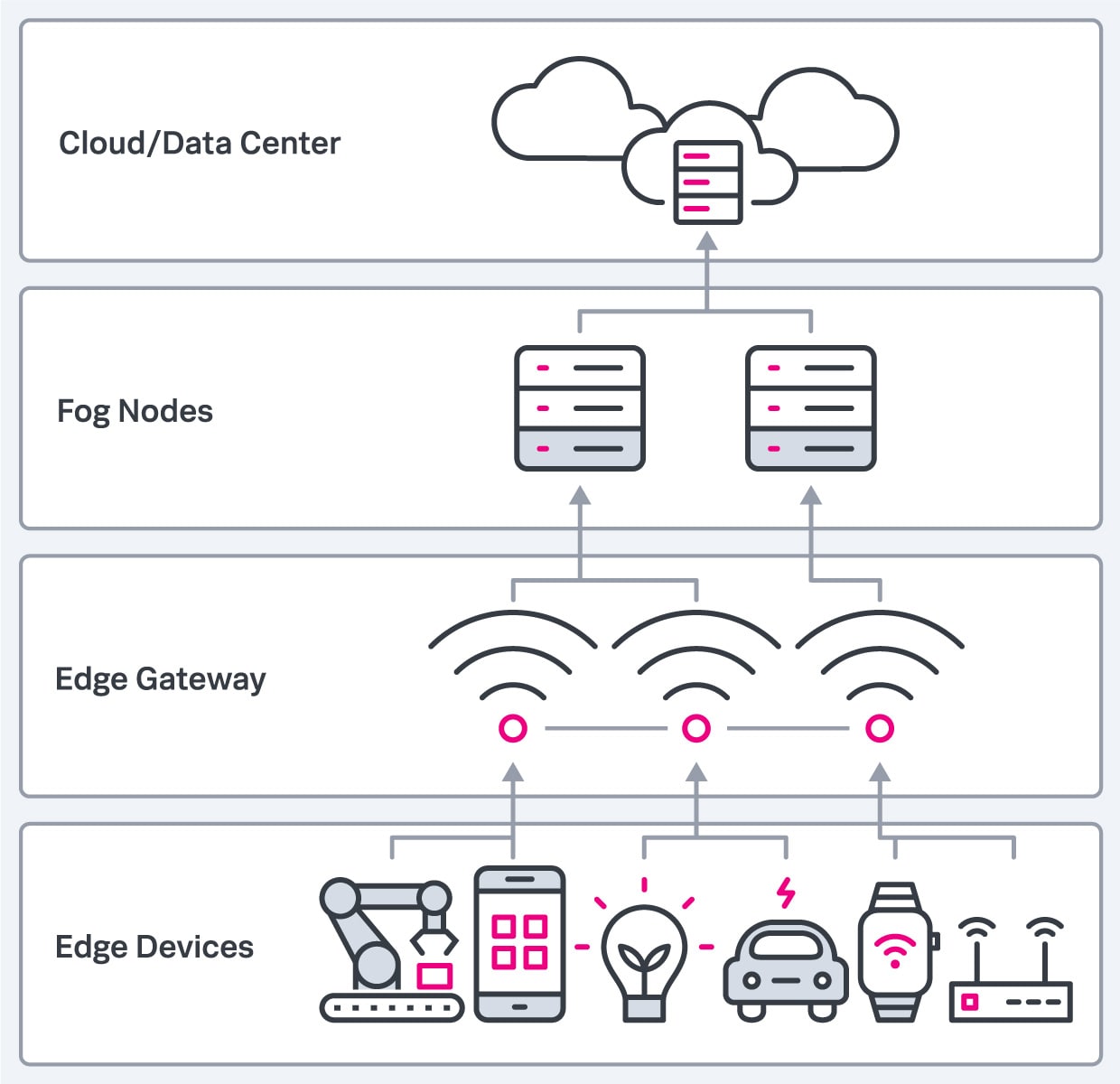
Comme il existe d’innombrables manières de classer les réseaux et les technologies de périphérie, il est difficile d’en faire un recensement exhaustif. Les systèmes et les plateformes sur lesquels elle repose offrent toutefois une piste de classement.
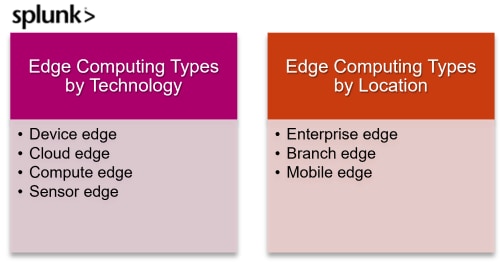
On peut ainsi distinguer les formes d’edge computing selon la technologie : appareil, cloud, calcul et capteur.
La périphérie sur l’appareil est la forme la plus traditionnelle d’edge computing. Ces réseaux de périphérie utilisent des appareils locaux pour distribuer les tâches de calcul. Ils affichent une faible latence mais sacrifient une part de capacité : ces réseaux utilisent en effet des appareils peu puissants, comme les gadgets connectés, les téléphones ou les routeurs. Lorsque les entreprises ont remarqué l’importance de la latence dans les transmissions longue distance entre les sites de colocation, elles ont adopté la périphérie sur l’appareil pour rapprocher les processus de traitement de la source des données.
Les réseaux de périphérie sur l’appareil se prêtent idéalement aux applications simples mais très spécialisées. Il est donc crucial de comprendre précisément les objectifs de l’entreprise et les capacités des appareils avant de les implémenter.
La périphérie sur le cloud, comme le cloud computing, s’appuie sur de vastes datacenters. En revanche, la périphérie cloud utilise des centres situés à proximité des utilisateurs finaux et des applications spécialisées. Elle améliore considérablement la latence tout en offrant les capacités du cloud computing conventionnel. En effet, 58 % des utilisateurs de la périphérie cloud enregistrent des latences de moins de 10 millisecondes, contre 29 % des utilisateurs de datacenters traditionnels, un écart qui peut être crucial dans certains secteurs.
Comme elle coûte plus cher et n’est pas disponible partout, la périphérie cloud est adaptée aux grandes entreprises et aux applications de grande envergure conjuguant forte demande en données et infrastructures existantes à proximité.
Le calcul en périphérie offre un compromis entre la périphérie sur l’appareil et sur le cloud. Ce modèle consiste à distribuer les tâches sur de petites machines spécialisées tout en utilisant des micro-datacenters (MDC) pour gagner en capacité.
Les MDC affichent habituellement une puissance allant de 50 à 400 kWh et comprennent quelques racks. Leur modularité les rend plus flexibles et évolutifs que les centres traditionnels, et ils apportent aux systèmes de périphérie une puissance supplémentaire avec une empreinte réduite.
Le calcul en périphérie convient aux entreprises qui n’ont pas accès à des datacenters à proximité mais doivent répondre à des besoins divers en périphérie. Si les MDC coûtent plus cher que les réseaux de périphérie sur l’appareil, ils ont l’avantage de prendre en charge un éventail plus large de cas d’utilisation.
Avec l’avènement de l’Internet des objets (IoT) et de l’automatisation, les entreprises ont été contraintes d’exploiter des réseaux aussi proches que possible des sources de données pour minimiser la latence. La proximité des données permet d’effectuer des calculs de base à l’aide de capteurs.
Les terminaux IoT sont les points de collecte des données. Le calcul sur capteur permet aux entreprises de déplacer une partie de leurs processus d’analyse vers les endpoints pour minimiser la latence et maximiser la performance. Il faut toutefois que les calculs soient moins complexes car le matériel de ces endpoints est minimaliste.
La périphérie des capteurs offre la latence la plus faible, mais aussi la puissance de calcul la plus limitée. Elle est idéale pour les tâches simples et propres à un appareil.
(Apprenez à superviser l’IoT.)
La localisation physique du déploiement est aussi employée pour distinguer différents types d’edge computing. Il y a naturellement des recoupements avec les catégories technologiques, mais cette fois c’est la façon dont les tâches de calcul sont géographiquement réparties qui permet de les classer.
De nombreuses organisations emploient l’edge computing pour réaliser des tâches dans leurs différents sites et succursales. La périphérie d’entreprise permet de distribuer les tâches de calcul en combinant différentes configurations et plusieurs appareils de périphérie pour utiliser toutes les ressources avec efficacité.
Elle offre la possibilité de s’adapter en souplesse à la distribution des ressources de calcul et à l’évolution des demandes. Elle répond aux besoins divers des grandes entreprises qui n’ont pas besoin d’une forte spécialisation à l’échelle locale.
Les réseaux de périphérie de succursale sont des réseaux edge dédiés à chaque succursale d’une entreprise. Parfois appelés systèmes de périphérie de réseau local (LAN), ils offrent une solution spécifique et à faible latence pour répondre aux besoins, aux objectifs et aux défis de chaque antenne d’une entreprise. Ils sont donc parfaits pour les entreprises dont les opérations locales sont spécialisées et qui exploitent plusieurs branches.
L’edge computing sur mobile offre l’environnement le plus flexible et le plus dynamique. Son réseau est réparti sur des appareils mobiles tels que des smartphones, et sur des gadgets IoT non fixes.
Comme la majorité des Français possèdent un smartphone et que beaucoup ont des tablettes, la périphérie sur mobile s’appuie la puissance de calcul et la distribution de ce vaste réseau. Elle reste toutefois limitée car les appareils mobiles n’ont pas les capacités des datacenters et des machines conventionnelles.
La périphérie sur mobile offre un réseau efficace pour les entreprises qui réalisent une grande part de leurs tâches à l’aide d’appareils mobiles. D’autre part, les personnes dont l’activité se fait majoritairement en déplacement plutôt qu’à un bureau sont très bien placées pour profiter des avantages du réseau de périphérie mobile.
Face au grand nombre d’options disponibles aujourd’hui, il peut être difficile de savoir quelle forme d’edge computing pourrait répondre aux besoins de votre entreprise.
Dans un premier temps, il faut bien comprendre ce qu’offre chaque type d’edge computing et ce qu’il peut faire pour les objectifs de votre entreprise. Par exemple :
Autrement dit, les deux premiers conviennent mieux aux processus fortement consommateurs de ressources et aux entreprises qui ont des besoins variés, tandis que les deux autres prendront parfaitement en charge des tâches très spécialisées.
La localisation est un facteur important pour choisir le bon type de périphérie. Si votre entreprise est plutôt centralisée, la périphérie d’entreprise ou de succursale – selon la puissance de calcul requise – sera plus adaptée. En revanche, si vos sites sont plus indépendants et vos workflows plus variés, pensez à un environnement de périphérie mobile.
La sécurité est un aspect essentiel de l’edge computing : 52 % des équipes IT disent avoir des difficultés à assurer une sécurité complète de tous leurs appareils de périphérie. À cet égard, le calcul en périphérie et la périphérie sur le cloud sont plus faciles à sécuriser parce qu’ils sont moins distribués. Ils se prêtent donc idéalement aux données et aux applications sensibles.
La périphérie de succursale convient aux sites dispersés dont les besoins en sécurité varient, et la périphérie d’entreprise est idéale lorsque les différentes branches ont les mêmes besoins.
(Découvrez comment les frameworks de sécurité peuvent appuyer les scénarios d’utilisation de la périphérie.)
Chaque modèle d’edge computing a ses points forts et ses inconvénients. Votre choix dépend de la taille et du type de votre activité, de vos besoins en données et de vos objectifs. L’industrie évolue constamment, et les modèles et cas d’usage de la périphérie offrent de nombreuses possibilités d’innovation. En connaissant les avantages de chacun et les critères à rechercher, vous trouverez la solution idéale pour vos besoins et vos opérations.
Une erreur à signaler ? Une suggestion à faire ? Contactez-nous à l’adresse ssg-blogs@splunk.com.
Cette publication ne représente pas nécessairement la position, les stratégies ou l’opinion de Splunk.

Les plus grandes organisations mondiales font confiance à Splunk, une filiale de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.