
État de la cybersécurité en 2025
Pour soutenir votre équipe dans sa réponse à la note de sécurité de SolarWinds, nous tenions à apporter des conseils supplémentaires afin de vous aider à importer plus efficacement les indicateurs de menaces, et ainsi lutter contre la backdoor Sunburst dans Splunk Enterprise Security (ES). Après avoir appliqué ces recommandations, vous pouvez lire l’article « Utiliser Splunk pour détecter la backdoor Sunburst » et passer à l’action.
Si la méthode actuelle de téléchargement des indicateurs dans Splunk Enterprise est en place depuis longtemps, que vous utilisiez ES 6.4 ou une version plus ancienne comme ES 4.5, nous avons quelques conseils et astuces à vous proposer afin d'éviter les cahots que vous avez pu rencontrer par le passer.
L’un des aspects les plus pénibles de l’importation des indicateurs de menace réside dans le nommage des champs. Le framework d'information sur les menaces s'attend à des valeurs spécifiques pour les champs d’en-tête. Vous trouverez la référence ici.
Par exemple, si j’extrais une liste d'adresses IP, le framework s'attend à ce que le champ contenant l’adresse IP soit nommé « IP », et pas dest, src, source_ip ou quoi que ce soit d'autre, tout simplement « IP ». De même, pour un nom de domaine, il recherche le champ « domain ». Vous trouverez ci-dessous un exemple provenant du lien que j’ai indiqué ci-dessus.

Pour illustrer cela, nous allons utiliser le dépôt GitHub de la backdoor Sunburst créé par Shannon Davis à titre d’exemple. J’ai commencé par créer deux téléchargements d’informations, appelés SunburstDomain et SunburstIP. J'ai configuré le type, la description et l’URL de provenance.

Lorsque je clique sur chacun d’eux et que je fais défiler la page, je vois des options d’interprétation. Observez le champ Fields : la première colonne du fichier .csv va renseigner le champ ip, et la colonne Description contiendra la constante SunburstIPListing.

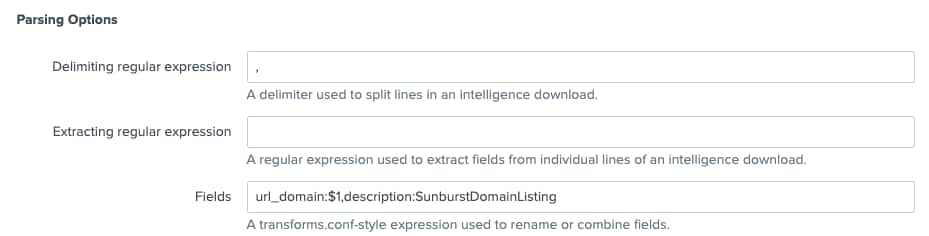
De même dans notre téléchargement de domaines, les valeurs de domaine sont en première position dans la liste, et c’est pourquoi nous utilisons $1 pour indiquer sa localisation. Nous utilisons une fois de plus une constante pour décrire la liste. Cette fois, je n’ai pas tenu compte du sage conseil qui recommande d'utiliser le type d'information sur les menaces pris en charge ; de plus, au lieu de nommer mon premier champ « domain », je l’ai appelé « url_domain ».
Mon téléchargement d’informations s’enregistre correctement et le téléchargement se fait, mais je suis déçu de voir que ces domaines n'apparaissent pas dans mes lookups. Comment puis-je résoudre ce problème ?
La bonne nouvelle, c’est que je peux chercher des pistes à plusieurs points du parcours.
Commencez par vérifier que les Intelligence Downloads (téléchargements d’informations) sont bien activés.
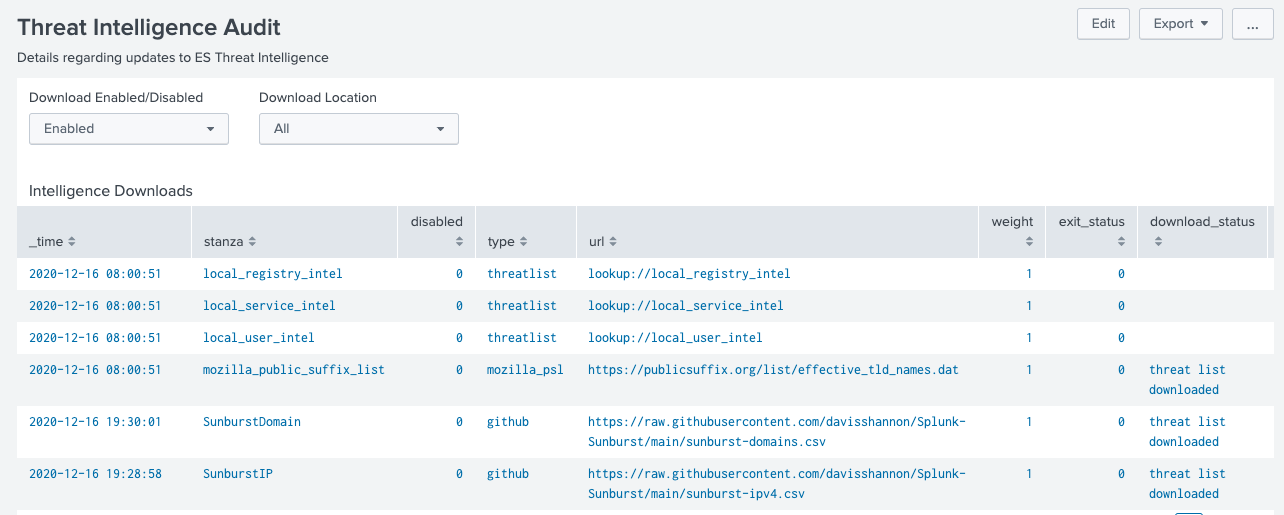
Ensuite, vérifiez si le fichier a été téléchargé en vous rendant dans Audit – Threat Intelligence Audit dans Enterprise Security. Le download_status doit indiquer que la liste de menaces a bien été téléchargée. Si ce n’est pas le cas, il est fort probable que l’URL soit incorrecte.
Pour les sceptiques comme moi, savoir que des fichiers d’informations sur les menaces ont bien été téléchargés est plutôt réconfortant. Dans la ligne de commande, rendez-vous dans le répertoire $SPLUNK_HOME/etc/apps/SA-ThreatIntelligence/local/data/threat_intel/. Si les fichiers ont bien été téléchargés, SunburstDomain et SunburstIP doivent être visibles dans le système de fichier. La convention de nommage des fichiers s'appuie sur le nom spécifié dans la section Intelligence Downloads.

Maintenant que j’ai la confirmation que les fichiers sont là, comment savoir s’ils sont bien lus et chargés dans les lookups ?
La portion inférieure du tableau de bord Threat Intelligence Audit contient tous les logs d’audit relatifs à l’interprétation des informations sur les menaces et à leur chargement : c’est un bon endroit pour faire nos vérifications. Cela dit, il n’affiche que les 1 000 derniers événements et si je veux me concentrer sur mes deux téléchargements, j’ai tout intérêt à l’ouvrir et à ajouter mes propres noms de fichiers.
eventtype=threatintel_internal_logs (SunburstIP.csv OR SunburstDomain.csv)
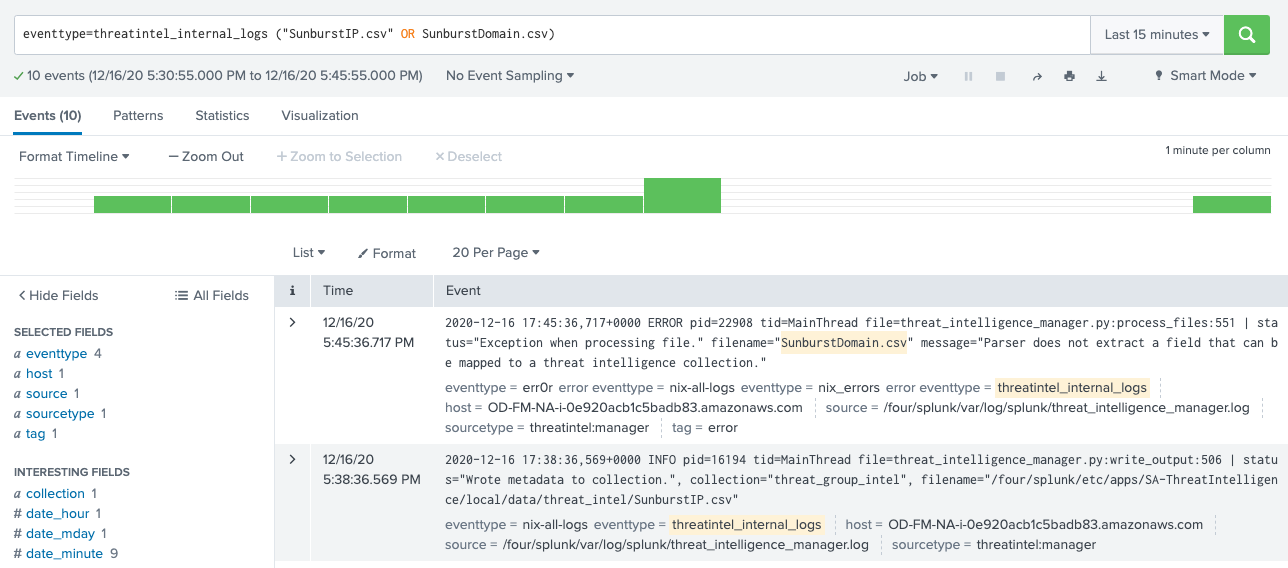
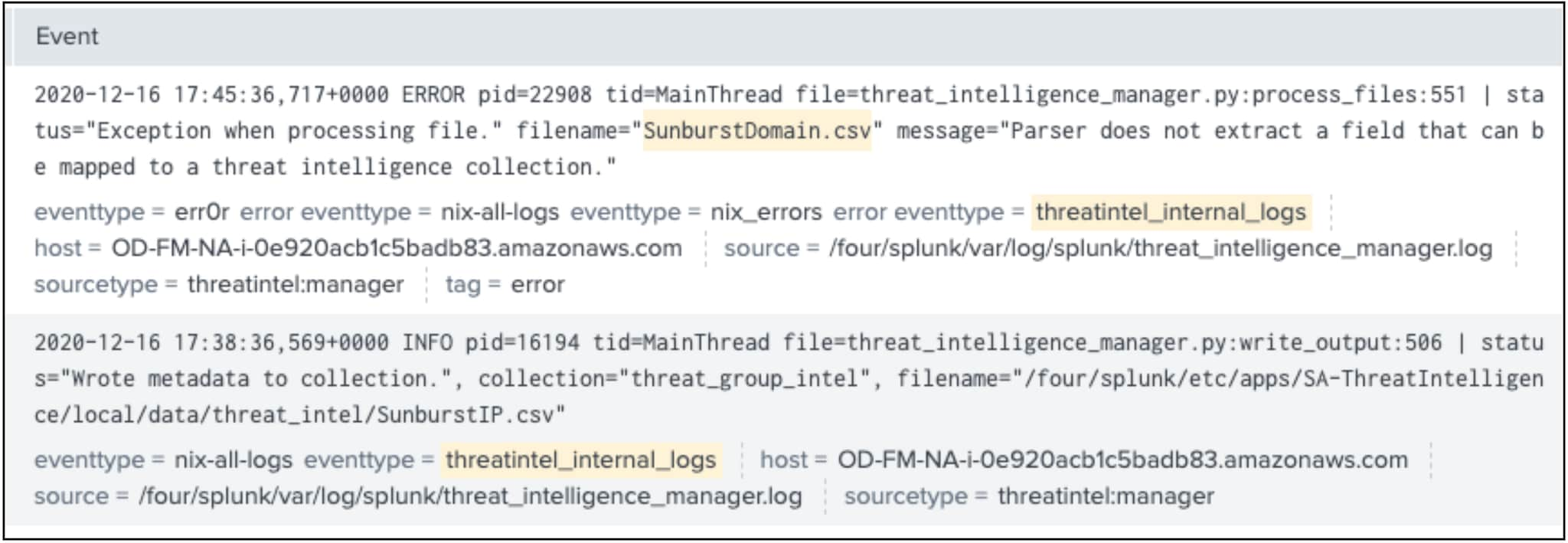
Si j’examine attentivement ces deux événements, j’y vois tout à la fois le frisson de la victoire et l’amertume de la défaite. (J’espère que cela évoque quelque chose à ceux d’entre vous qui, comme moi, dévoraient les retransmissions sportives à la télévision.) Le deuxième événement de l’image ci-dessous indique que les adresses IP sont bien inscrites dans la collection. Les adresses IP sont chargées !
Le premier événement a renvoyé une erreur, qui est due au fait que nous avons utilisé url_domain à la place de domain comme nom de champ : cela génère une exception dans le traitement du fichier. Le framework ne sait pas quoi faire des données téléchargées, il renvoie une erreur et passe à la suite. C’est un point très important à rechercher dans les événements : si vous voyez cette erreur, vérifiez les options d’interprétation pour confirmer que les noms de champs utilisés sont définis par ES.
À ce stade, je vais mettre les indicateurs de domaine de côté et terminer avec les adresses IP. Il y a quelques étapes intermédiaires que je vais vous épargner, la conférence « Enterprise Security Biology » de .conf2017 les explique dans les moindres détails, mais nous cherchons à faire en sorte que les données soient envoyées vers le KV Store dans les différentes collections de menaces en fonction du type d'indicateur.
| inputlookup ip_intel | search description=SunburstIPListing
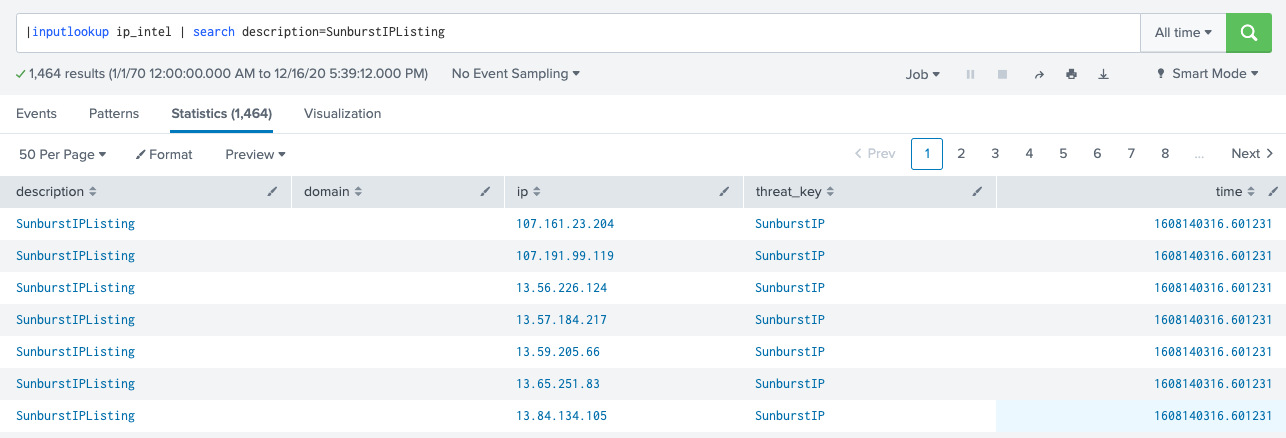
Dans notre cas, je peux faire une recherche dans la table ip_intel pour voir si les indicateurs ont été chargés. Comme je tiens à me focaliser sur SunburstIPListing, qui, si vous vous en souvenez, est la description que j’ai ajoutée aux options d’interprétation, je peux utiliser | search pour restreindre les résultats à cette liste seulement.
Ensuite, le framework d’informations sur les menaces prend le relais et une série de recherches enregistrées s’exécute à intervalles réguliers pour corréler les événements des différentes collections de menaces et inscrire les données dans le modèle threat_activity. La recherche de corrélation va ensuite s’exécuter conformément à sa planification, extraire les nouveaux éléments du modèle de données et créer des événements notables.
J’espère que cela vous aidera à harmoniser l’importation de ces indicateurs de menaces dans votre instance de Splunk Enterprise Security.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.