
Une feuille de route pour la résilience numérique des entreprises
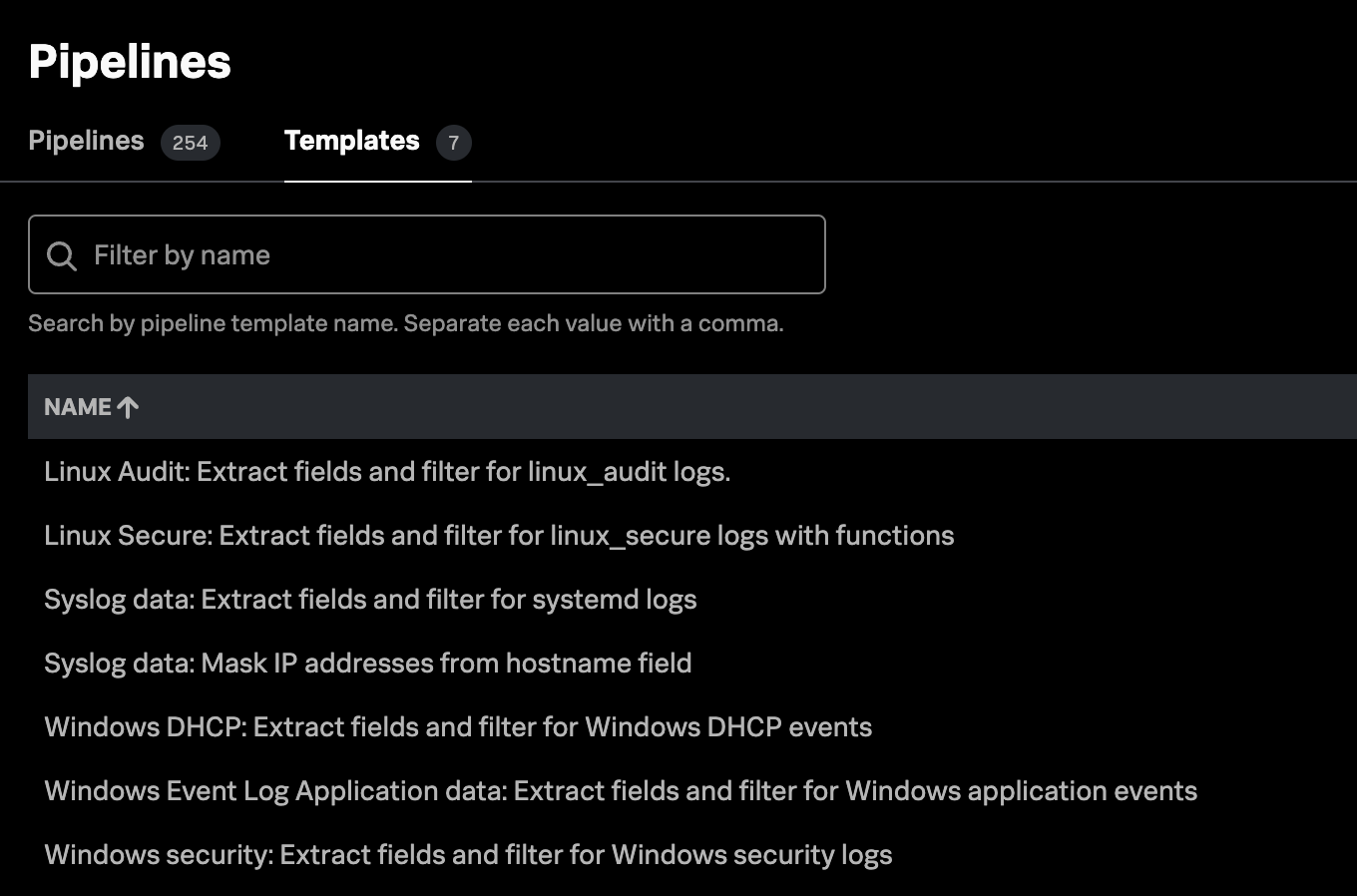
À l’heure qu’il est, vous avez peut-être déjà entendu parler d’Edge Processor, l’outil convivial de préparation des données de Splunk pour filtrer, transformer et aiguiller les données en périphérie, qui est maintenant accessible au grand public. Edge Processor permet aux administrateurs de données dans les environnements Splunk d’ignorer les données inutiles, de masquer les champs sensibles, d’enrichir les charges utiles et de définir des conditions d’aiguillage des données vers une destination donnée. Géré via Splunk Cloud Platform mais déployé à la périphérie des données du client, Edge Processor vous aide à contrôler les coûts liés aux données et à préparer leur utilisation pour une utilisation efficace en aval.
Parallèlement à l’annonce de la disponibilité d’Edge Processor, nous sommes également heureux d’annoncer la disponibilité au grand public du SPL2 Profile for Edge Processor ! Le SPL2 Profile for Edge Processor contient le sous-ensemble de commandes et de fonctions de SPL2 qui peuvent être utilisées pour contrôler et transformer le comportement des données dans Edge Processor. Il représente une portion de la surface du langage SPL2.
Dans Edge Processor, vous pouvez définir vos pipelines de traitement de deux manières différentes. La première, idéale pour créer rapidement et facilement des pipelines, permet aux administrateurs de données de profiter des fonctionnalités de pointer-cliquer de l’éditeur de pipeline d’Edge Processor. Depuis ce même éditeur de pipeline, les utilisateurs peuvent également choisir d’interagir directement dans la fenêtre d’édition de code du SPL2 pour créer des pipelines avec un degré élevé de flexibilité. Cela permet aux administrateurs de données d’utiliser directement le langage SPL2 de Splunk pour créer des pipelines via un éditeur de code selon une méthode familière aux experts SPL. Cette méthode est très utile car elle permet d’utiliser des modèles syntaxiques SPL pour transformer des données en mouvement ! Intéressons-nous plus en détail au SPL2.
Le SPL2 est le langage de recherche et de préparation des données nouvelle génération de Splunk. Il fait office de point d’entrée unique pour un large éventail de scénarios d’utilisation des données et sera, à l’avenir, disponible dans plusieurs produits. Les utilisateurs peuvent utiliser le SPL2 pour créer des pipelines qui traitent les données en mouvement, établissent et valident des schémas de données tout en exploitant la documentation et les outils inline. Le SPL2 souhaite appliquer un modèle de langage « learn once, use anywhere » (apprendre une fois, utiliser n’importe où) dans toutes les fonctionnalités de Splunk, un modèle bien connu des utilisateurs du SPL.
Le SPL2 reprend tous les avantages du SPL – sa syntaxe, ses commandes les plus utilisées, la convivialité de ses fonctionnalités d’investigation et sa structure en flux – et les rend utilisables non seulement sur des données au repos (par ex. via splunkd), mais aussi des runtimes de flux. Cela permet aux administrateurs de données, aux développeurs ainsi qu’aux habitués du SPL, mais qui ne maîtrisent pas la configuration de règles complexes dans des fichiers props et transforms, de tirer profit de leur connaissance du SPL et de l’appliquer directement aux données en mouvement via Edge Processor.
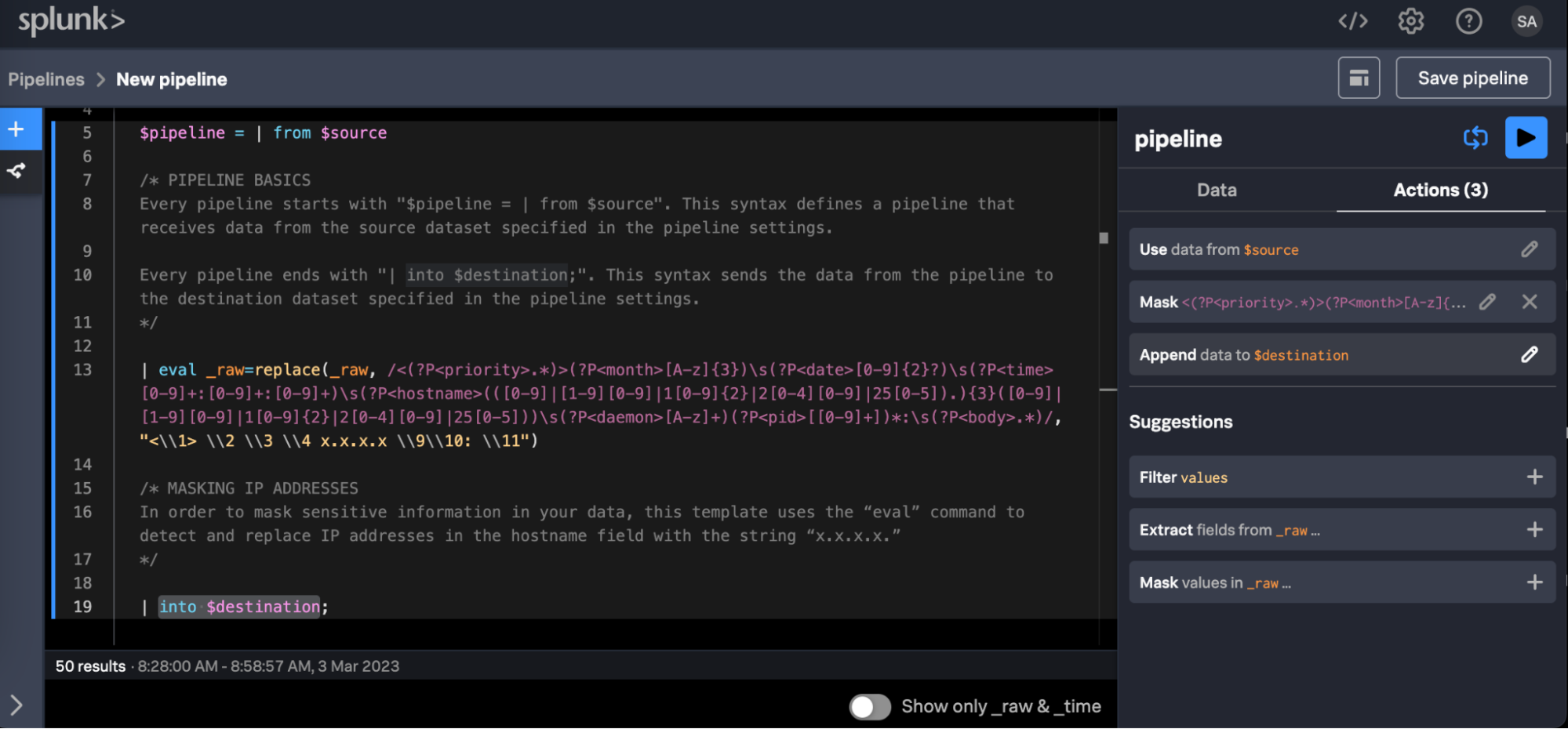 Un modèle de pipeline SPL2 qui masque les adresses IP du champ hostname des données syslog.
Un modèle de pipeline SPL2 qui masque les adresses IP du champ hostname des données syslog.
Le SPL2 est déjà utilisé implicitement par plusieurs produits Splunk pour gérer la préparation, le traitement et l’interrogation des données par exemple. Au fil du temps, nous comptons mettre le SPL2 à disposition sur l’ensemble du portefeuille de Splunk afin de proposer une plateforme véritablement unifiée.
Les clients connaissant le SPL seront ravis d’apprendre que le SPL2 apporte un éventail de nouvelles fonctionnalités pour répondre encore mieux aux besoins de préparation des données en mouvement, notamment :
Le SPL2 prend en charge un large éventail d’opérations sur les données. Le SPL2 Profile for Edge Processor représente un sous-ensemble du langage SPL2 qui peut être utilisé dans le cadre de l’offre Edge Processor. Par exemple : au lancement, Edge Processor est principalement conçu pour aider les clients à gérer l’envoi de données, masquer leurs données sensibles, enrichir les champs et préparer les données en les aiguillant au bon endroit. Les commandes SPL2 et les fonctions eval prenant en charge ces comportements sont prises en charge dans le profil pour Edge Processor afin de garantir une expérience utilisateur fluide. En savoir plus sur les profils du SPL2 et voir une matrice de compatibilité des commandes par produit pour les commandes du SPL2 et les fonctions eval.
Les pipelines Edge Processor sont des constructions logiques qui lisent les données d’une source, mènent des opérations sur ces données puis les inscrivent dans une destination. Tous les pipelines sont entièrement définis dans le SPL2 (soit lorsqu’ils sont manipulés directement dans l’éditeur de code d’Edge Processor ou lorsqu’ils sont indirectement créés via l’interface graphique de création de pipeline). Les pipelines SPL2 définissent un ensemble entier de transformations, souvent liées à des types de données similaires.
Tous les pipelines doivent suivre cette syntaxe :
$pipeline = from $source | <processing logic> | into $destination;
Prenez le pipeline Edge Processor ci-dessous, défini dans SPL2 :
$pipeline = from $source | rex field=_raw /user_id=(?P<user_id>[a-zA-Z0-9]+)/ | into $destination;
Ce pipeline du SPL2 peut être décomposé en plusieurs composants :
$pipeline_part_1 = from $source | where … | rex field=_raw /fieldA… fieldB… fieldC…
$pipeline = from $pipeline_part_1 | eval … | into $destination;
Comme vous pouvez le constater, il y a quelques différences entre le SPL2 et le SPL que vous connaissez. La première est que le SPL2 permet non seulement d’utiliser des expressions simples, mais aussi des attributions d’expression. Des recherches complètes peuvent être nommées, traitées comme des variables et liées pour former une unité acheminable. Le SPL2 prend également en charge l’écriture dans les ensembles de données, et non plus seulement la lecture dans les ensembles de données (et avec une syntaxe légèrement différente). Les ensembles de données peuvent prendre différentes formes : index, buckets S3, forwarders, vues, etc. Vous écrirez la plupart du temps dans un index Splunk. Pour en savoir plus sur les différences entre le SPL2 et le SPL, rendez-vous ici.
Mais que se passe-t-il si votre pipeline n’est pas limité à un seul sourcetype ? Dans ce cas, vous pouvez plutôt lire à partir d’un ensemble de données spécifique appelé all_data_ready (le regroupement de toutes les données Ingress d’Edge Processor) et appliquer n’importe quelle logique de sourcetype :
$pipeline = from $all_data_ready | where sourcetype=”WMI:WinEventLog:*” | rex field=_raw /user_id=(?P<user_id>[a-zA-Z0-9]+)/ | into $destination;
Vous commencez peut-être à voir que le SPL2 n’est pas seulement un ensemble de commandes et de fonctions, mais aussi un ensemble de concepts fondamentaux qui peuvent permettre d’utiliser des scénarios de traitement de données puissants. En fait, Edge Processor propose de base des modèles de pipeline SPL2 pour traiter des scénarios d’utilisation de préparation des données :
Au-delà de ces modèles, analysons quelques exemples qui montrent comment le SPL2 simplifie la préparation des données.
Je veux séparer de manière logique les composants de pipelines complexes à plusieurs niveaux.
Le SPL2 permet de définir des pipelines à plusieurs niveaux, à des fins d’organisation, de débogage et de séparation logique. L’utilisation des attributions de statement en tant que variables plus tard dans le module SPL2 permet aux administrateurs des données de formuler leurs règles de préparation des données de façon modulaire.
$capture_and_filter = from $all_data_ready | where sourcetype=”WinEventLog:*”
$extract_fields = from $capture_and_filter | rex field = _raw /^(?P<dhcp_id>.*?),(?P<date>.*?),(?P<time>.*?),(?P<description>.*?),(?P<ip>.*?),(?P<nt_host>.*?),(?P<mac>.*?),(?P<msdhcp_user>.*?),(?P<transaction_id>.*?),(?P<qresult>.*?),(?P<probation_time>.*?),(?P<correlation_id>.*?),(?P<dhc_id>.*?),(?P<vendorclass_hex>.*?),(?P<vendorclass_ascii>.*?),(?P<userclass_hex>.*?),(?P<userclass_ascii>.*?),(?P<relay_agent_information>.*?),(?P<dns_reg_error>.*?)/
$indexed_fields = from $extract_fields | eval dest_ip = ip, raw_mac = mac, signature_id = msdhcp_id, user = msdhcp_user
$quarantine_logic = from $indexed_fields | eval quarantine_info = case(qresult==0, "NoQuarantine", qresult == 1, "Quarantine", qresult == 2, "Drop Packet", qresult == 3, "Probation", qresult == 6, "No Quarantine Information")
$pipeline = from $quarantine_logic | into $destination
Comme vous pouvez le voir ci-dessus, nous avons défini quatre « niveaux » de traitement de ce pipeline : $capture_and_filter, $extract_fields, $indexed_fields et $quarantine_logic, chacun débouchant sur le suivant, et avec bien évidemment la variable $pipeline pour arriver à la destination. Lorsque $pipeline est exécutée, tous les niveaux s’enchaînent en coulisses, permettant au pipeline de fonctionner comme prévu tout en conservant un degré de segmentation logique et de lisibilité.
J’ai un événement JSON imbriqué complexe que je veux transformer en champ à valeur multiples puis l’extraire en plusieurs événements.
Si vous avez déjà utilisé JSON dans Splunk, vous savez que cela peut s’avérer… délicat. C’est une combinaison interminable de mvindex, mvzip, eval, mvexpand, split, et peut-être même SEDCMD dans prop.conf.
Avec le SPL2, c’est pourtant plus facile que jamais grâce aux commandes expand() et flatten() ! Souvent utilisées ensemble, elles peuvent être utilisées pour, dans un premier temps, étendre un champ qui contient une série de valeurs pour produire une rangée de résultats séparée pour chaque objet de la série, puis pour aplatir les paires de valeurs-clés dans l’objet dans des champs séparés dans un événement, autant de fois que nécessaire.
Prenons par exemple ce JSON passé comme un événement unique, et supposons qu’il est représenté par un ensemble de données appelé $json_data. Nous voulons créer l’horodatage au moment de l’indexation (qui n’existait pas) et extraire chaque section imbriquée dans un événement :
{
"key": "Email",
"value": "john.doe@bar.com"
},
{
"key": "ProjectCode",
"value": "ABCD"
},
{
"key": "Owner",
"value": "John Doe"
},
{
"key": "Email",
"value": "jane.doe@foo.com"
},
{
"key": "ProjectCode",
"value": "EFGH"
},
{
"key": "Owner",
"value": "Jane Doe"
}
}
Par lui-même et sans préparation, ce code renvoie un événement unique dont les champs sont bloqués dans le corps JSON.
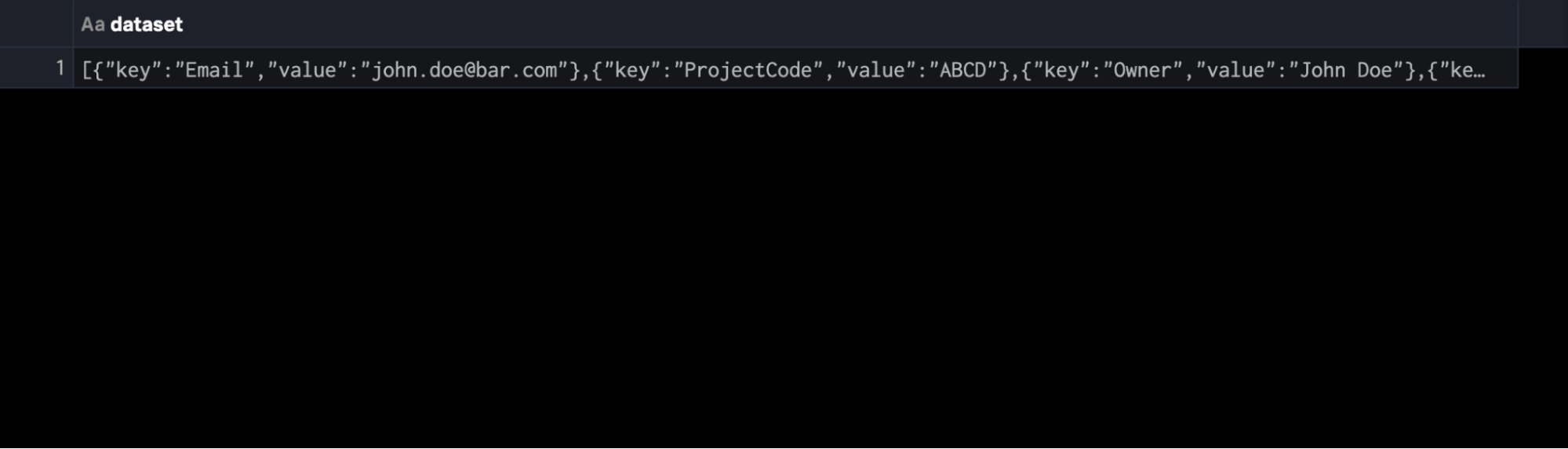
Cependant, nous pouvons écrire le SPL2 suivant pour aplatir ce JSON et l’horodater :
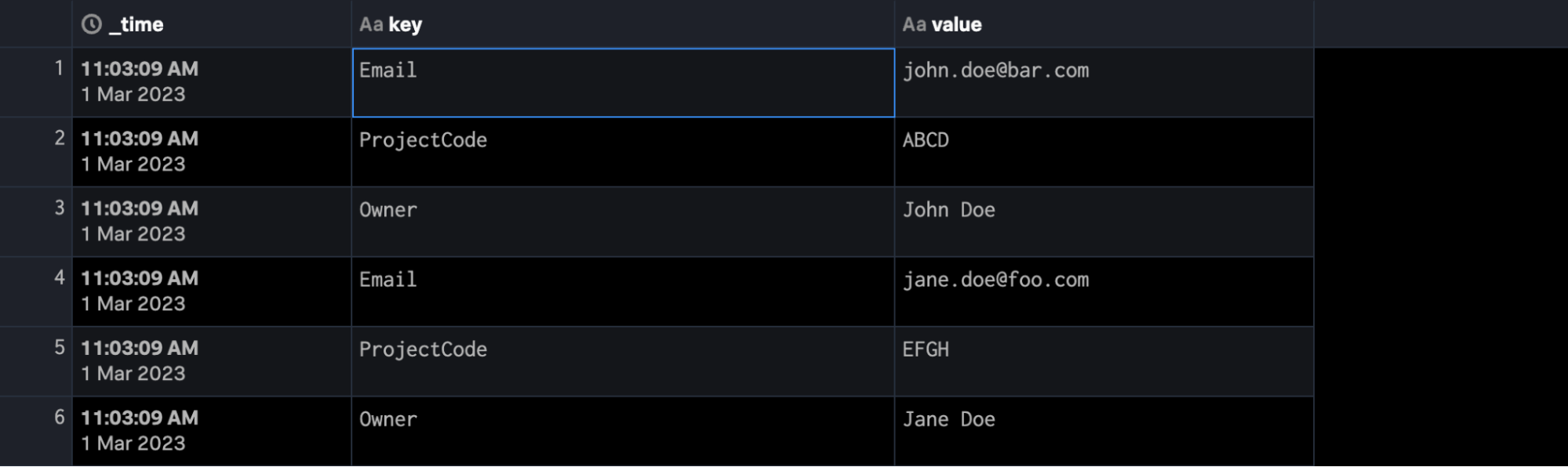
$pipeline = FROM $json_data as json_dataset | eval _time = now() | expand json_dataset | flatten json_dataset | into $destination
Ce qui devrait permettre l’extraction de cet événement JSON en plusieurs événements avec leurs champs, comme suit :
Le SPL2 dans Edge Processor est extrêmement performant, et cet article n’aborde qu’une infime partie de son potentiel ! Si vous souhaitez en savoir plus sur le SPL2 ou SPL2 Profile for Edge Processor, n’hésitez pas à contacter votre équipe de compte Splunk ou à commencer une discussion dans le canal Slack splunk-usergroups.
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

Recevez les derniers articles de Splunk par e-mail.
© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.