

Créer une pratique d’observabilité de pointe
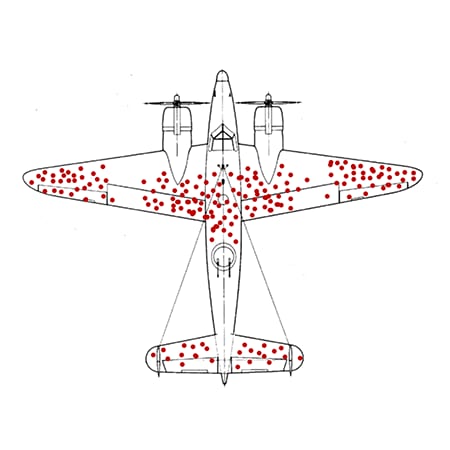
Pendant la Seconde Guerre mondiale, un mathématicien du nom d’Abraham Wald a travaillé sur un problème: identifier les parties des avions à renforcer en se basant sur l’étude des appareils qui étaient revenus de leurs missions et de la localisation des impacts de balles. L’idée évidente et communément acceptée était que les impacts de balle désignaient les zones problématiques des avions. Wald a alors observé que les portions vulnérables n'étaient au contraire pas celles-ci, puisque ces avions avaient survécu aux attaques. Les avions disparus étaient porteurs de données inconnues, indiquant d'autres zones problématiques. En réalité, la localisation des impacts sur les avions survivants désignait les zones peu vulnérables.
De McGeddon – Œuvre de l’auteur, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=53081927
Dans le monde émergent de l'observabilité, c’est souvent exactement ce qu’on nous demande de faire : baser nos réponses uniquement sur les données survivantes. Pour faire court, appuyer la supervision uniquement sur les éléments connus de votre environnement peut vous pousser dans certains biais. Les outils présentent de nouvelles vues et échelles d’informations utiles dans le monde de l’orchestration, des microservices et des clouds hybrides. Mais sont-ils assez complets ? Vous donnent-ils les informations dont vous avez vraiment besoin ?
Pour citer Sherlock Holmes, le personnage d’Arthur Conan Doyle, «Vous voyez, mais vous n’observez pas» (Un scandale en Bohème). Bienvenue dans le biais du survivant, qui consiste à tirer des conclusions sur la base des survivants et non sur celle de la population dans sa globalité.
Au cours des quelques dernières années, nous avons vu une accélération vertigineuse de la complexité des architectures et de l’élargissement des abstractions. Nos applications monolithiques sont en train de devenir natives du cloud. Nos environnements à fil unique et trois couches se transforment en architectures de microservices toujours plus complexes, élastiques et massives.
Mais une chose est devenue parfaitement claire. Les abstractions nous rendent la vie «plus simple» de plusieurs façons importantes. Toutefois, en raison des mêmes abstractions, il est devenu plus difficile d’explorer nos applications et nos environnements quand il le faut. On se retrouve bien vite confronté au problème sans fin de l'œuf et de la poule.
Tout cela découle de changements dans la façon dont nous adoptons la technologie. Nous nous sommes approprié un grand nombre d'abstractions pour gérer cette évolution.

Nous vivons dans un monde où nous pouvons disposer d’hôtes en grand nombre. Nous pouvons être multi-cloud. Nos services sont écrits dans différents langages de programmation et nous employons des frameworks variés. Nous nous agrandissons sans cesse grâce à la souplesse des capacités de calcul et des besoins sans bornes en données.
Envisageons Kubernetes comme un seul et même élément. Kubernetes est le leader incontesté de l’orchestration de conteneurs. Il est largement employé dans nos applications en conteneurs complexes, domine le cloud public et élargit constamment ses capacités. Mais la simplicité de l’abstraction s'accompagne souvent de défis :
Ajoutez à ces difficultés les différentes structures de conteneurs Docker, vos services d'applications sous-jacentes, les services tiers et les protocoles de communication, et vous aurez une idée de l’envergure du système. Nous allons donc avoir des difficultés à superviser les performances de bout en bout des services distribués. Face à cette complexité, il est généralement impossible de tracer à la main le parcours d'une requête dans l'application.
Il est aussi relativement courant de voir les volumes de données de la télémétrie d’observabilité dépasser les centaines de téraoctets par jour. L’agrégation des métriques est d’une grande efficacité mais elle requiert l’ajout de balises, de catégories et d’informations sur l’infrastructure sous-jacente pour permettre d’identifier rapidement les causes profondes, dont découle naturellement une grande cardinalité. Les traces distribuées peuvent générer des dizaines d’unités logiques, avec une moyenne de 8 environ par requête. Imaginez un simple site d’e-commerce générant 500requêtes par seconde. Cela représente 4000unités logiques contenant chacune des données d’une importance considérable, et notamment des valeurs anormales et des événements uniques et totalement inattendus.
Nous sommes ainsi confrontés à un problème de rapport signal-bruit dans lequel chaque parcelle de bruit est un signal important. C’est précisément à ce stade que le biais du survivant s’insinue dans l'éventail de choix de l'observabilité.
Il existe des moyens de réduire le bruit, du moins en théorie. On peut filtrer la télémétrie grâce à l'échantillonnage. On peut réduire l'agrégat de transmission à l'aide de méthodes passe-bande. On peut être confronté à du bruit de quantization dans les signaux numériques (bien que cela soit très peu probable).
Toutes ces méthodes ont un même défaut: elles supposent que toutes les données qui sont rejetées étaient effectivement du bruit. Dans une application en microservices axée sur des requêtes, aucune donnée n’est du bruit. Toute technique visant à réduire la quantité de données ne fait rien d'autre que cela: elle réduit vos données. Et c’est cela qui rend difficile la détection des conditions que nous demandons précisément aux techniques d'observabilité de repérer: les inconnues ignorées (unknown unknowns).
Pour certains outils de traçabilité distribuée, l'échantillonnage apporte une réponse. Ces outils examinent 5 ou 10 % des traces et rejettent le reste sans discernement (échantillonnage de tête). D'autres, plus intelligents, attendent que la trace soit terminée puis l’analysent pour y trouver des détails intéressants, et choisissent de vous envoyer celles qui paraissent pertinentes (échantillonnage de queue). Mais si l’objectif de l’observabilité est la découverte, l’identification et la résolution des inconnues ignorées, examiner ce qu’on vous envoie induit nécessairement un biais.
Vous cherchez toujours à identifier les valeurs anormales, mais vous êtes désormais en possession de toutes les données, bonnes ou mauvaises. Vous n’appuyez pas vos décisions uniquement sur les survivants, vous pouvez maintenant identifier les points faibles et les renforcer. Vous pouvez établir des références pertinentes, identifier les anomalies réelles et maintenir votre embarcation à flot.
Sans cela, comment cartographier vos services pour suivre vos requêtes ? Comment suivre les tendances historiques si vous ne possédez pas toutes les données ?
Vous allez me dire : « Attendez un instant. Mes métriques ne sont-elles pas censées tout me dire ? »
La réponse n’est pas simple. Si vous appliquez un échantillonnage aléatoire avant une analyse, en particulier avec des données de trace, vos chiffres RED (taux, erreurs, durées) ne seront pas valides. Vous exploitez vos systèmes en vous appuyant uniquement sur ce que vous voyez, et vous n’avez aucune visibilité sur les inconnues ignorées.
Et cela peut même être pire. Dans l’anecdote de l’avion, la première réaction a été de renforcer le blindage des zones qui présentaient le plus d'impacts de balles pour augmenter les chances de survie de l’appareil. Pourtant, ce blindage l'aurait rendu plus lent et plus difficile à manœuvrer, diminuant ainsi ses chances. Reconnaître le biais du survivant aurait produit le résultat opposé.
Appliquons maintenant l’exemple de l'avion à notre tableau de bord RED. Quand on effectue un échantillonnage, on obtient la courbe de distribution normale actuelle des métriques de la période choisie. On passe ainsi à côté des valeurs anormales, les P95 et P99. Nos tableaux de bord sont parfaits mais nos clients sont insatisfaits (par moments du moins).
Même avec une agrégation complète de nos métriques, l'absence de données sous-jacentes complètes peut être problématique. Avec cette même approche, nous pouvons maintenant voir un pic sporadique sur la période. Nos métriques peuvent nous avertir qu’il y a un problème. C’est sans doute une valeur anormale, et la question qui se pose maintenant est : « Est-ce que notre approche d’échantillonnage a enregistré cette trace ? » Ou bien, comme Bender dans Futurama, allons-nous chercher le fichier dans l’Inspecteur 5 pour découvrir qu’il ne s’y trouve pas du tout. Et même si notre échantillonnage intelligent a conservé cette valeur anormale, comment allez-vous la comparer aux activités qui l’entourent à cet instant précis, ou à la progression normale des requêtes pour ce client et son infrastructure ?
En réalité, la réponse est très simple. Appuyez-vous sur une instrumentation qui délivrera toutes les données, en continu et en temps réel, sous une forme efficace. Vous éviterez ainsi les écueils et les erreurs associés à des données incomplètes. Ces données, présentées dans le tableau de bord de votre choix, qu’il soit basé sur le concept RED ou sur une approche personnalisée, vous donneront une vision complète de vos applications et de votre environnement, en vous permettant d’atteindre les causes sous-jacentes. En bref, c’est vous qui déterminez ce qui est important et ce que vous voulez savoir, et non le fournisseur de l’outil.
Examinez votre technologie d'observabilité. Vérifiez que vous ne recevez pas qu’une image partielle du fonctionnement de vos systèmes. Gardez à l’esprit le biais du survivant et sachez qu’il est extrêmement facile d’y céder, surtout si les données que vous voyez appuient vos conclusions de départ. Assurez-vous d’obtenir des données d’observabilité non biaisées pour maintenir vos applications à flot.
Cliquez ici pour en savoir plus sur l’observabilité avec Splunk.
----------------------------------------------------
Thanks!
Splunk

Les plus grandes organisations mondiales font confiance à Splunk, une entreprise de Cisco, pour renforcer en permanence leur résilience numérique grâce à une plateforme unifiée de sécurité et d’observabilité, alimentée par une IA de pointe.
Nos clients se fient aux solutions de sécurité et d’observabilité primées de Splunk pour sécuriser leurs environnements numériques complexes et en renforcer la fiabilité, quelle que soit l’échelle.

© 2005 - 2026 Splunk LLC Tous droits réservés.
© 2005 - 2026 Splunk LLC Tous droits réservés.