In meinem letzten Blog ging es um einige Probleme im Zusammenhang mit künstlicher Intelligenz (KI) und mangelndem Vertrauen der Öffentlichkeit, die durch organisatorische Probleme wie Dark Data noch verschärft werden. Diesmal schauen wir uns einige Beispiele an, die zeigen, wie KI für das Gemeinwohl eingesetzt werden kann.
Analyse und Ethik
2019 haben wir gemeinsam mit dem Weltwirtschaftsforum (World Economic Forum, kurz WEF) einige Leitlinien zu KI getestet, die wir zuvor mit dem WEF erarbeitet hatten. Es gab viele rege Debatten, denn zum Einsatz von KI gibt es geteilte Meinungen, insbesondere mit Blick auf das Thema Bildverarbeitung.
In Großbritannien gab es kürzlich Kontroversen darüber, ob die Polizei bei der Auswertung von Überwachungsvideos zur Verbrechensbekämpfung Gesichtserkennungstechnologie verwenden darf. Die Nutzung dieser Technologie veranlasste Elizabeth Denham, die Datenschutzbeauftragte des Vereinigten Königreichs, eine Untersuchung einzuleiten, um festzustellen, ob der Einsatz von Gesichtserkennung in diesem Fall gerechtfertigt ist.
Darüber hinaus gibt es einige Szenarien, die zeigen, dass die Bildverarbeitung leicht in die Irre geführt werden kann. Zum Beispiel, als ein Algorithmus ausgetrickst wurde und eine Reihe von Gewehren für einen Hubschrauber hielt. Angesichts solcher Beispiele fällt es nicht schwer, sich die Welt als Schreckensszenario vorzustellen, wie z. B. in diesem Artikel über Deepfakes beschrieben.
Dies sind durchaus düstere Geschichten über Deep Learning, doch glücklicherweise steht bei Splunk nicht die Bildverarbeitung im Mittelpunkt – bei uns geht's um Maschinendaten!
Und was Maschinendaten betrifft, so gibt es eine ganze Fülle von Use Cases, bei denen sich der Einsatz von Machine Learning definitiv positiv auf das Leben von Menschen ausgewirkt hat.
Verhindern von Drogenmissbrauch
Wenn ihr euch mit einem weit gereisten, viel erfahrenen Security- oder Fraud-Analysten darüber unterhaltet, wie dieser Bedrohungen erfolgreich erkennt, dann fällt dabei häufig der Begriff „Ausreißer“ (Outlier). Es gibt viele unterschiedliche Möglichkeiten für das Erkennen von Anomalien in Datensätzen. Ich würde vorschlagen, dass ihr mit dieser technischen Anleitung über statistische Ausreißer beginnt und dann zu fortgeschrittenen Techniken übergeht (anschaulich beschrieben als Geschmacksrichtungen von Eiscreme – wie auch sonst?!)
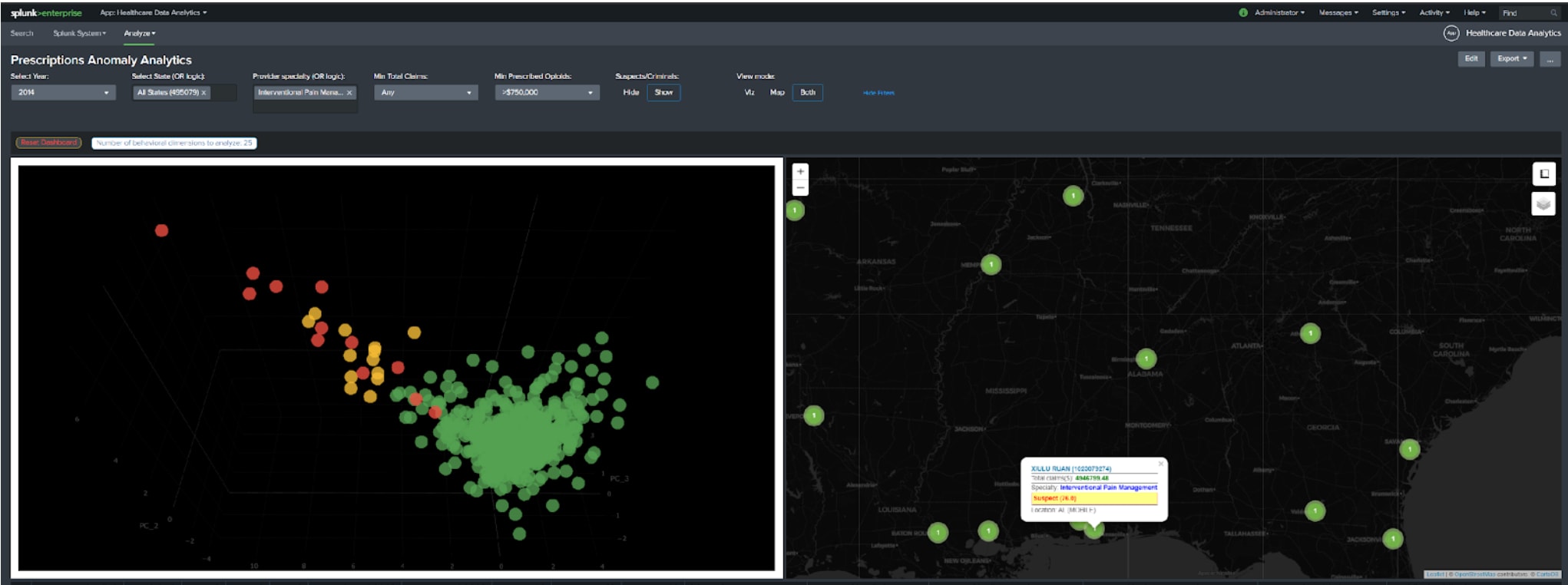 *Clustering-Technik zur Erkennung gefälschter Rezepte mit Daten von data.cms.gov. Die roten Punkte sind Personen, die bereits in Haft sind oder aufgrund verdächtiger Aktivitäten Gegenstand einer Untersuchung durch die US-amerikanische Drogenvollzugsbehörde DEA, das Justizministerium oder die Strafverfolgungsbehörden sind.
*Clustering-Technik zur Erkennung gefälschter Rezepte mit Daten von data.cms.gov. Die roten Punkte sind Personen, die bereits in Haft sind oder aufgrund verdächtiger Aktivitäten Gegenstand einer Untersuchung durch die US-amerikanische Drogenvollzugsbehörde DEA, das Justizministerium oder die Strafverfolgungsbehörden sind.
Den Verantwortlichen im NewYork-Presbyterian Hospital wurde bewusst, dass viele Methoden, die üblicherweise im Bereich Cyber-Security zur Outlier-Erkennung verwendet werden, auch geeignet wären Ausreißer bei der Verschreibung von Betäubungsmitteln zu ermitteln.
Dabei orientierte man sich im NewYork-Presbyterian bei der Ausreißererkennung eng an der „Schokoladeneis-Technik“, die in diesem Blog zur Erkennung von Anomalien beschrieben wird. Die Ergebnisse können wir euch hier (aus ethischen Gründen natürlich) nicht zeigen. Zur Veranschaulichung präsentieren wir jedoch einige auf Open-Source-Daten basierende Grafiken, auf die in Splunk dieselben Techniken angewandt wurden, und zwar zu folgendem Zweck:
- Zeigen, dass Anomalien in Rezeptdatensätzen in direktem Zusammenhang mit betrügerischer oder krimineller Aktivität stehen
- Identifizieren von Dr. Joel Smithers, der kürzlich wegen Rezeptbetrugs eine Haftstrafe angetreten hat
Vielen Dank an Gleb Esman, der die Details für diese Beispiele beigesteuert hat.
Bei Splunk freuen wir uns immer, Kunden zu unterstützen, die Interesse an der Anwendung von Methoden zur Erkennung von Anomalien haben oder Splunk zur Betrugserkennung einsetzen möchten. Einen hervorragenden Einstieg bietet Splunk Security Essentials for Fraud Detection. Hier wird detaillierter auf einige der in diesem Blog vorgestellten Techniken eingegangen.
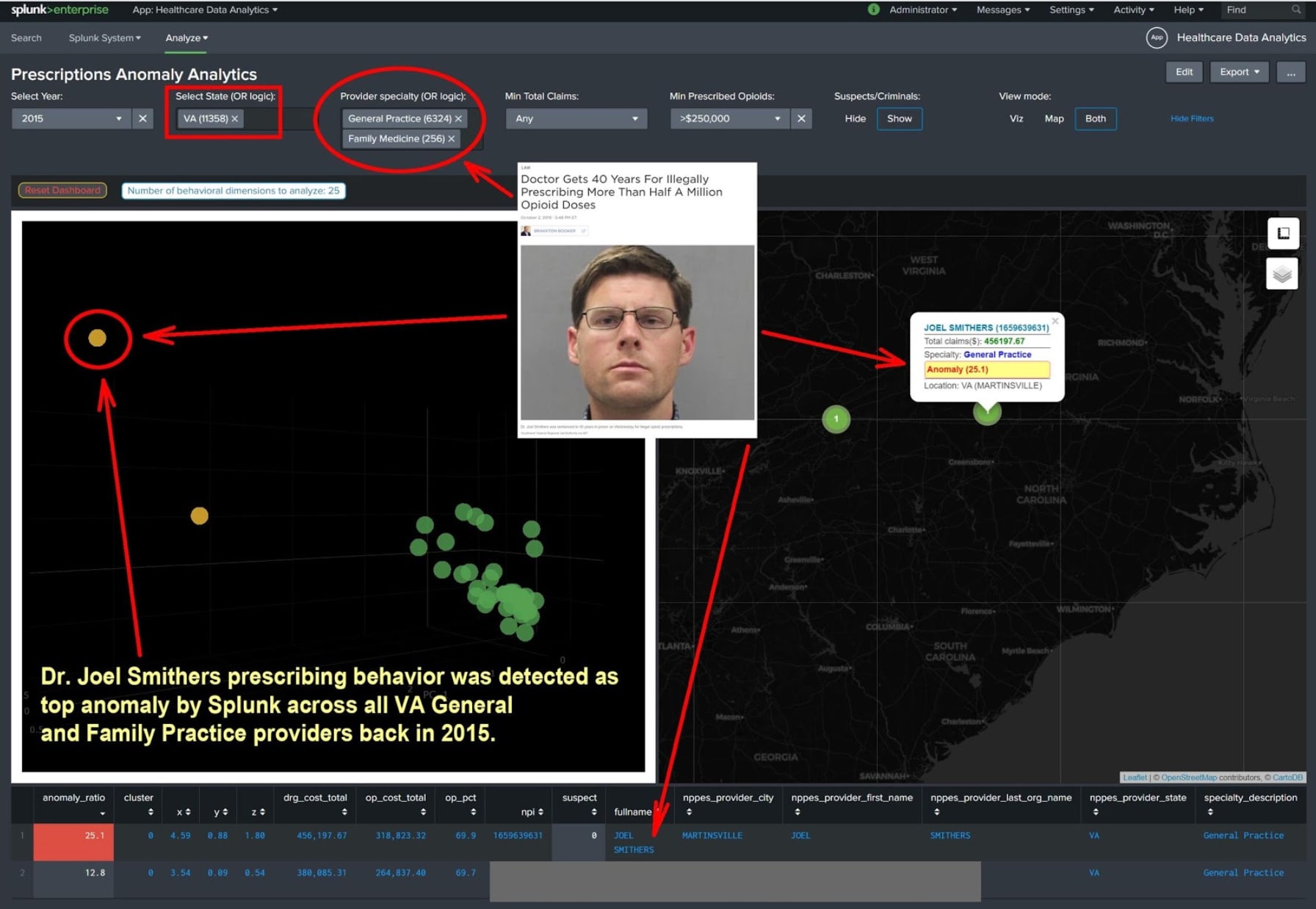 *Anomalieerkennungsanalyse von Daten, die von data.cms.gov veröffentlicht wurden, mit aggregierten Details von Rezepten, die zur Abrechnung bei Medicare eingereicht wurden.
*Anomalieerkennungsanalyse von Daten, die von data.cms.gov veröffentlicht wurden, mit aggregierten Details von Rezepten, die zur Abrechnung bei Medicare eingereicht wurden.
Erfolg von Studierenden vorhersagen
Machine Learning (ML) leistet nicht nur bei der Bekämpfung krimineller Aktivitäten wertvolle Dienste. ML kann auch an anderer Stelle für interessante Ergebnisse sorgen.
Weltweit gibt es Hunderte von Universitäten, die Splunk im Security- und Operations-Bereich für das Monitoring ihrer IT verwenden. An einer dieser Universitäten, nämlich der University of Nevada, Las Vegas (UNLV), fiel einem Psychologieprofessor namens Matt Bernacki auf, dass die aus Systemen des gesamten Campus zusammengetragenen Daten auch einen guten Überblick über das Engagement der Studenten geben. Er nahm ein Projekt zur Erstellung eines Modells in Angriff, über das prognostiziert wurde, ob Studierende einen Kurs voraussichtlich bestehen oder nicht bestehen würden. Dozenten und andere akademische Mitarbeiter bekamen dadurch die Chance, rechtzeitig zu intervenieren und die Studierenden entsprechend zu unterstützen. Im ersten Semester, in dem dieses System eingesetzt wurde, konnten an der UNLV über 100 Studierende ermittelt werden, die im Begriff waren durchzufallen. Durch entsprechenden Support erhielten sie am Ende Bestnoten.
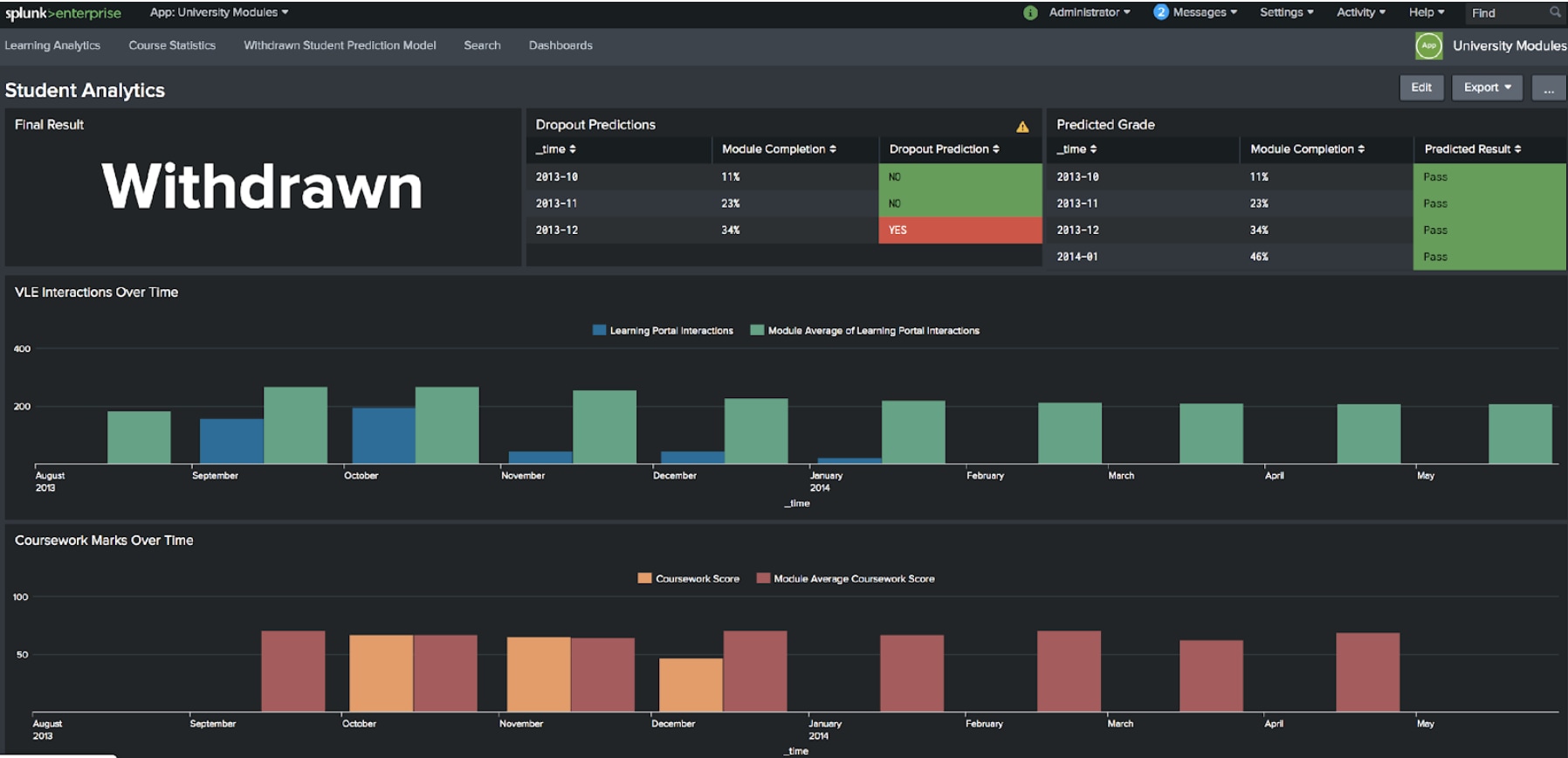 *Analyse von Open University-Daten zeigt, wie anhand des „digitalen Fußabdrucks“ der Studierenden in den IT-Systemen der Universitäten Vorhersagen bezüglich ihres Abschneidens getroffen werden können.
*Analyse von Open University-Daten zeigt, wie anhand des „digitalen Fußabdrucks“ der Studierenden in den IT-Systemen der Universitäten Vorhersagen bezüglich ihres Abschneidens getroffen werden können.
Wir haben mit einer Reihe von Universitäten in den USA und Großbritannien an ähnlichen Use Cases gearbeitet und darüber hinaus ein Student Success Toolkit auf den Markt gebracht, um ein leicht nutzbares Schema für die Entwicklung solcher Vorhersagemechanismen bereitzustellen.
„Human in the Loop“ – Nicht ohne den Menschen
Wichtig ist, nicht zu vergessen, dass bei beiden Anwendungsfällen für Analyse und Intervention noch immer das Eingreifen einer Person erforderlich ist. Wenn ihr KI als Augmented Intelligence (also erweiterte Intelligenz) betrachtet, dann dient sie nicht etwa dazu, eine Person zu ersetzten, sondern soll den Entscheidungsprozess dieser Person durch zusätzliche Intelligenz unterstützen. Menschen können Informationen nämlich viel besser in einen Kontext setzen als Maschinen (noch jedenfalls).
Wenn ihr diese Methoden und Techniken anwenden möchtet, solltet ihr euch auch sicher sein, dass ihr kein Problem damit habt, wenn Details dazu veröffentlicht werden. Sollte das nicht der Fall sein, dann ist es möglich, dass die Art der Verwendung nicht jedermanns Ethikstandard entspricht. Letztlich gilt es nämlich, das Vertrauen der Öffentlichkeit nicht zu enttäuschen, während ihr versucht, positive Ergebnisse zu erzielen.
Deep Learning Toolkit
Zu guter Letzt möchte ich noch an den Hinweis zu den Produktfunktionen anknüpfen, den ich beim letzten Mal gegeben hatte. Das Deep Learning Toolkit for Splunk ist jetzt verfügbar. Tolle Arbeit von Philipp Drieger – eine fantastische Möglichkeit, noch komplexere Use Cases mit Splunk zu lösen.
Bis zum nächsten Mal,
Greg
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Machine Learning for Social Good.
----------------------------------------------------
Thanks!
Splunk
