 Seid ihr Fans von Juwelen und Edelsteine? Perfekt geschliffene Diamanten? Umwerfend schöne, kristallklare Strukturen? Ja? Dann nehmt euch zehn Minuten Zeit und lest weiter. Spoiler-Alert: es geht um Graphen und die Suche nach verborgenen Schätzen in euren Daten.
Seid ihr Fans von Juwelen und Edelsteine? Perfekt geschliffene Diamanten? Umwerfend schöne, kristallklare Strukturen? Ja? Dann nehmt euch zehn Minuten Zeit und lest weiter. Spoiler-Alert: es geht um Graphen und die Suche nach verborgenen Schätzen in euren Daten.
Aber ich muss euch warnen, denn ich nehme euch auch mit auf eine geheimnisvolle Reise. Eine Reise in die Tiefen der Datenphilosophie. Doch eure Zeit wird nicht vergeudet sein: Als Belohnung winken Artefakte, mit denen ihr direkt in die Edelsteingewinnung einsteigen könnt. Und ob ihr es glaubt oder nicht, wenn ihr die neueste Version von Splunks Machine Learning Toolkit besitzt, sind die großen Juwelen noch leichter zu finden als ihr denkt. Also, los geht's!
Bildquelle: Commonwikimedia.org
Im Wunderland der Daten
Um zu verstehen, was Graphen sind, stellt euch ein Netzwerk miteinander verbundener Elemente vor. In den letzten Jahrzehnten haben Publikationen von der formalen Graphentheorie bis hin zu angewandten (sozialen) Netzwerkwissenschaften und komplexen Systemdynamiken einen Boom erlebt. Trotzdem ist vielen Menschen nicht bewusst, wie leistungsstark Graphen sind, obwohl die meisten von uns im Alltag von ihren realen Anwendungsmöglichkeiten profitieren. Hier einige Beispiele:
- Euer Navi, das euch rechtzeitig ans Ziel bringt
- Euer Lieblings-Online-Shop, der euch interessante Produktvorschläge und -empfehlungen gibt
- Euer Kreditkartenanbieter, der euch erfolgreich vor Betrug schützt
- Und dann lest ihr diesen Artikel vermutlich auch auf einem Gerät, das an eine Graphstruktur angebunden ist – das Internet.
Lange Rede, kurzer Sinn: Graphen können sehr kostbar sein – genau wie Edelsteine. Doch wo finden wir sie? Und was hat all dies mit Splunk zu tun?
Eine kleine Bergbau-Übung
Fast alle Daten in Splunk können in Graphen verwandelt werden, ein Aspekt, den ihr bisher vielleicht noch gar nicht in Betracht gezogen habt. In euren Network-Traffic-Daten wird eine Quell-IP mit einer Ziel-IP verbunden, mit Attributen wie Bytes in/out, Paketen, Ports und anderen Eigenschaften. Benutzer melden sich bei einem Stack vernetzter Systeme, Services, Geräte und Anwendungen an. Transaktionen laufen von A über B bis C und können einen Prozess beschreiben, der euch bei der Analyse von User Journeys und Geschäftsprozessen im Allgemeinen hilft.
Und jetzt wird es interessant: Viele dieser Beziehungen können per Data Mining mit einem einfachen SPL-Muster aus euren Rohdaten zutage gefördert werden:
... | stats count by source destination
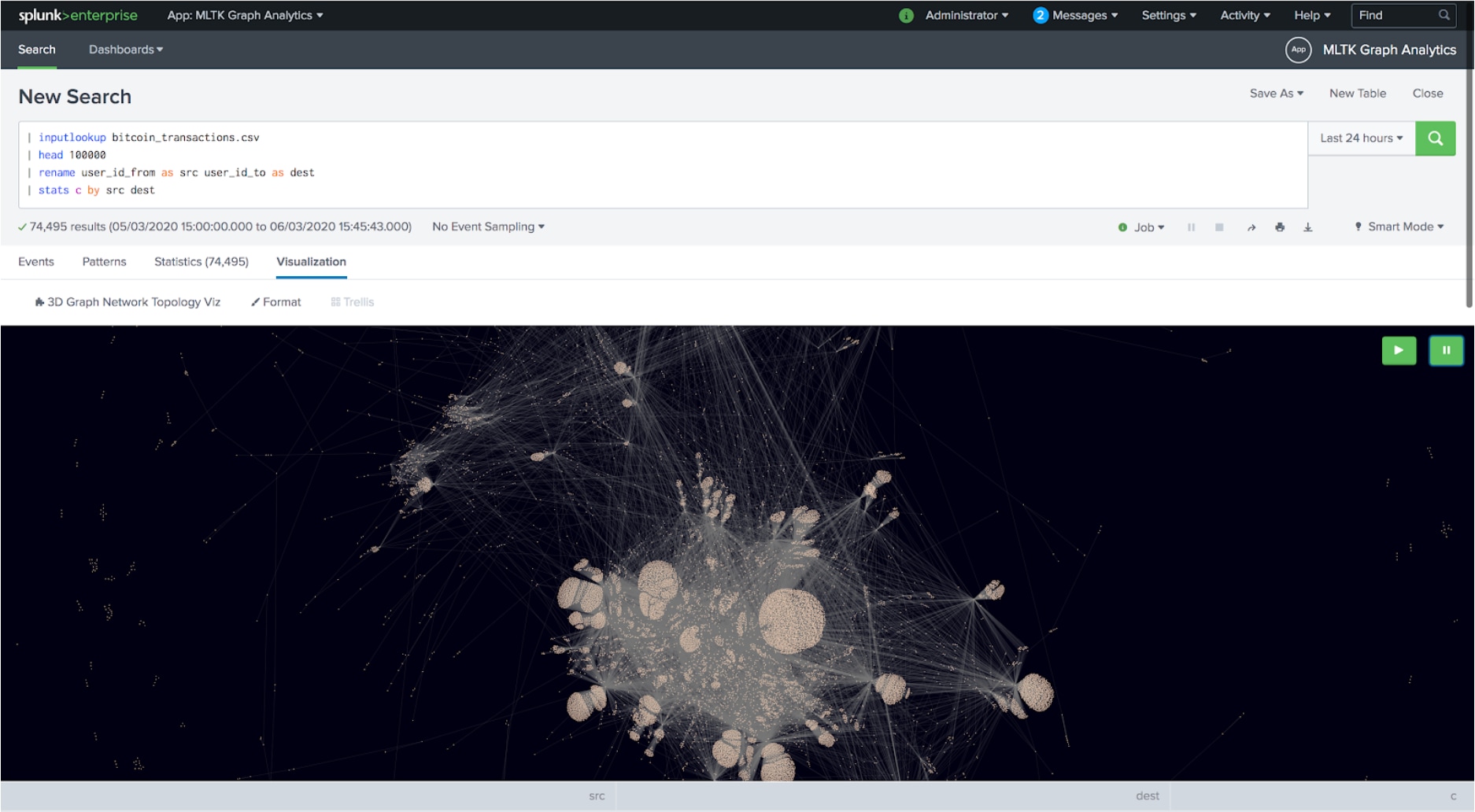
Et Voilá, wie ihr oben sehen könnt, habt ihr den ersten Graphen aus euren Rohdaten in Splunk zutage gefördert. Mit ein wenig SPL habt ihr eine sogenannte Kantenlistendarstellung (Edge List Representation, d.h. eine Liste aller Verbindungen) abgerufen, die darüber hinaus direkt in Splunk schön visualisiert werden kann. Ein großes Dankeschön an Erica für ihre tolle benutzerdefinierte 3D-Graphvisualisierung, die kostenlos auf Splunkbase heruntergeladen werden kann!
Nach dieser kleinen Bergbau-Übung sagt ihr vielleicht: „Das war zu einfach. Ich sehe außerdem noch keinen Diamanten – nur ein großes Knäuel!“ Natürlich habt ihr recht. Wir müssen unseren Rohdiamanten nun weiter bearbeiten. Machen wir uns also daran, ihn zu schleifen!
Schleifen des Diamanten
In der Regel geht es darum, bestimmte Erkenntnisse aus einem Graphen zu gewinnen. Das sind die echten Diamanten, nach denen wir suchen:
- Wer ist der einflussreichste Akteur in einem Netzwerk?
- Wer hat eine Brückenfunktion zwischen Gruppen und wird daher eher Entitäten miteinander verbinden?
- Welche Communitys sind in dem Graphen vorhanden und wer gehört ihnen an?
- Welches sind die kürzesten Wege zwischen ihnen?
- Was passiert, wenn Knoten oder Verbindungen ausfallen?
- Und wie verändern sich all diese Eigenschaften im zeitlichen Verlauf?
Jede dieser Fragen kann mithilfe von Graphalgorithmen beantwortet werden und in Bereichen wie Cyber Security Analyse, Betrugserkennung oder Social Network Analyse zu ganz wichtigen Ergebnissen führen. Klingt immer noch zu abstrakt? Okay, dann lasst uns über Algorithmen sprechen.
Tanz mit den Algorithmen
Um euch ein konkretes Beispiel an die Hand zu geben, betrachten wir ein simples Beispiel-Dataset, das zum Lieferumfang des Machine Learning Toolkits von Splunk gehört: Bitcoin-Transaktionen. Einfach ausgedrückt überweist ein User (Quelle / Source) einen Wert an einen anderen User (Ziel / Destination). Aus allen Transaktionen wird im Laufe der Zeit ein Graph aufgebaut.
Aber was ist, wenn es in diesem Graphen eine Entität gibt, die besonders einflussreich ist. Vielleicht einen versteckten Broker, der sich einen unfairen Vorteil verschafft oder einen Betrüger, der einer kriminellen Gruppe angehört? Typische Grapheigenschaften wie Zentralitätsmaße, Pfadanalyse, Clusterkoeffizient oder Erkennung von Gruppen können nützliche Erkenntnisse liefern. Außerdem ist zu bedenken, dass diese Eigenschaften klassische Machine-Learning-Ansätze erheblich verbessern können, indem solche graphenbezogenen Maße als zusätzliche Merkmale herangezogen werden.
Zentralitätsmaße
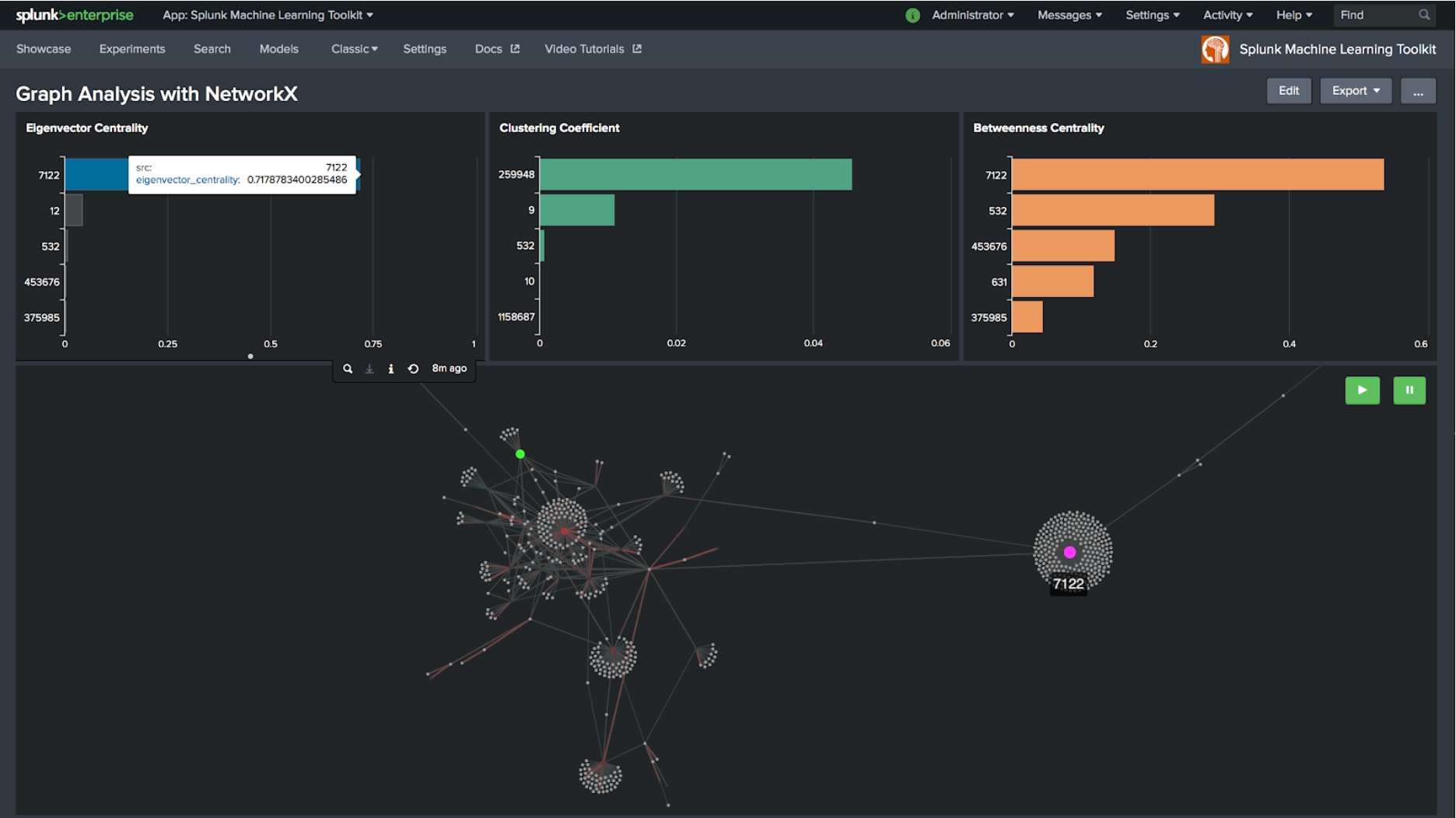
Das obige Beispiel zeigt eine Teilmenge der Bitcoin-Transaktionen und legt den Fokus auf die oberen fünf Knoten, die einen hohen Wert bei der Eigenvektor-Zentralität (Eigenvector Centrality), Betweenness-Zentralität (Betweenness Centrality) oder beim Clusterkoeffizienten (Clustering Coefficient) aufweisen. Der rosa dargestellte Knoten 7122 ist besonders auffällig. Er weist eine hohe Eigenvektor-Zentralität auf und verbindet darüber hinaus die Graphenstruktur auf der linken Seite mit einer anderen Struktur außerhalb des Bildschirms auf der rechten Seite, was gleichzeitig zur höchsten Betweenness-Zentralität führt. Für Analysten sind dies echte Diamanten, da sie wichtige Muster in einem großen Datensatz aufzeigen und Erkenntnisse für weitere Untersuchungen liefern.
Vernetzte Komponenten und Communitys
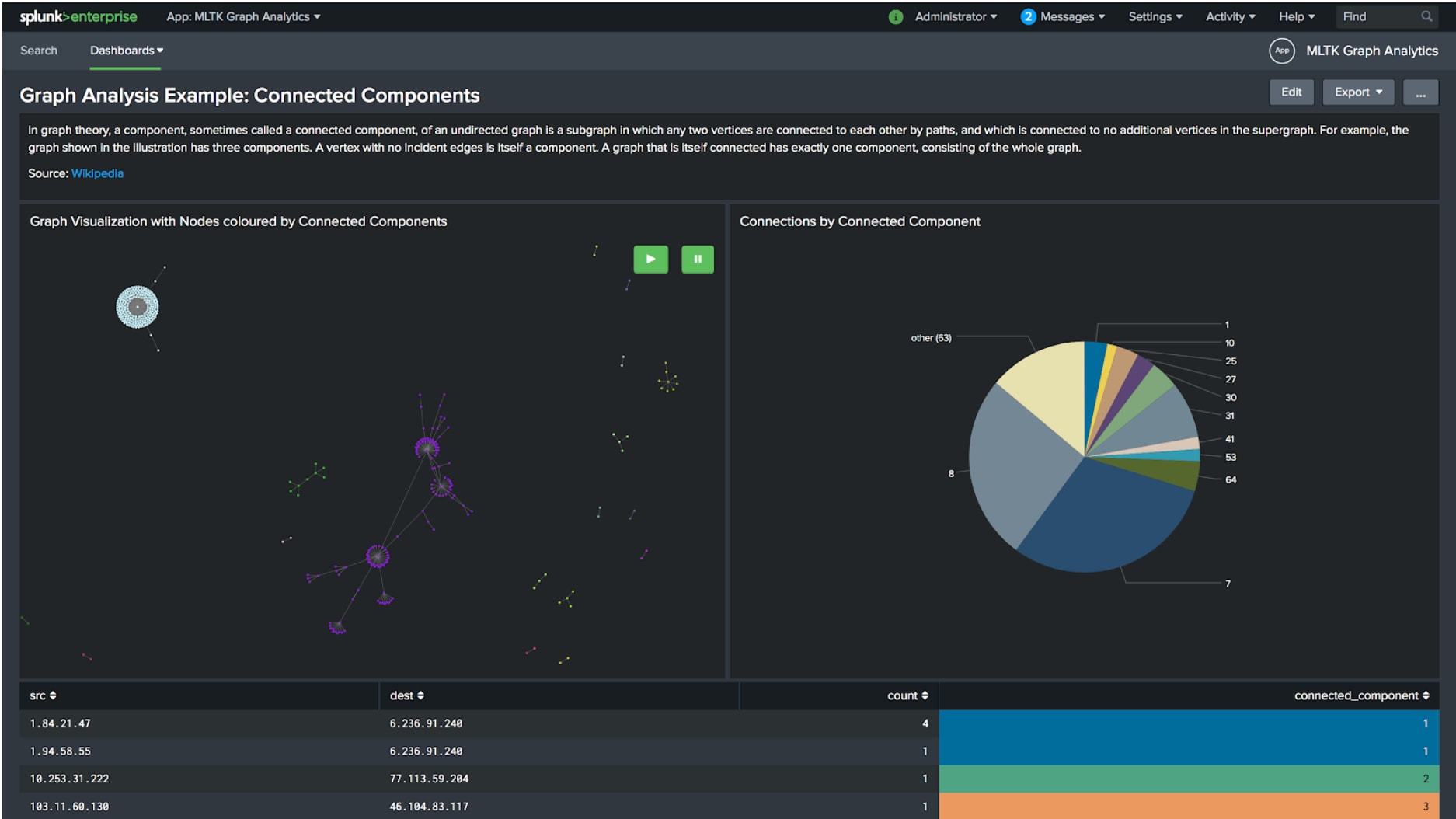
Daraus könnte sich die Frage ergeben, ob der Graph separierte Teile aufweist. Sie weisen gewöhnlich auf isolierte Gruppen von Entitäten hin, die nur innerhalb ihrer Gruppe, aber nicht mit anderen Gruppen im Graphen verbunden sind. Mithilfe des Algorithmus für Zusammenhangskomponenten (Connected Components) können diese Gruppen automatisch erkannt und klassifiziert werden. Diese Technik wurde letztes Jahr bei der .conf19 in einem von Siemens vorgestellten Security Use Case angewendet, um Anomaliewerte im Zusammenhang mit verbundenen Systemen und Entitäten zu berechnen.
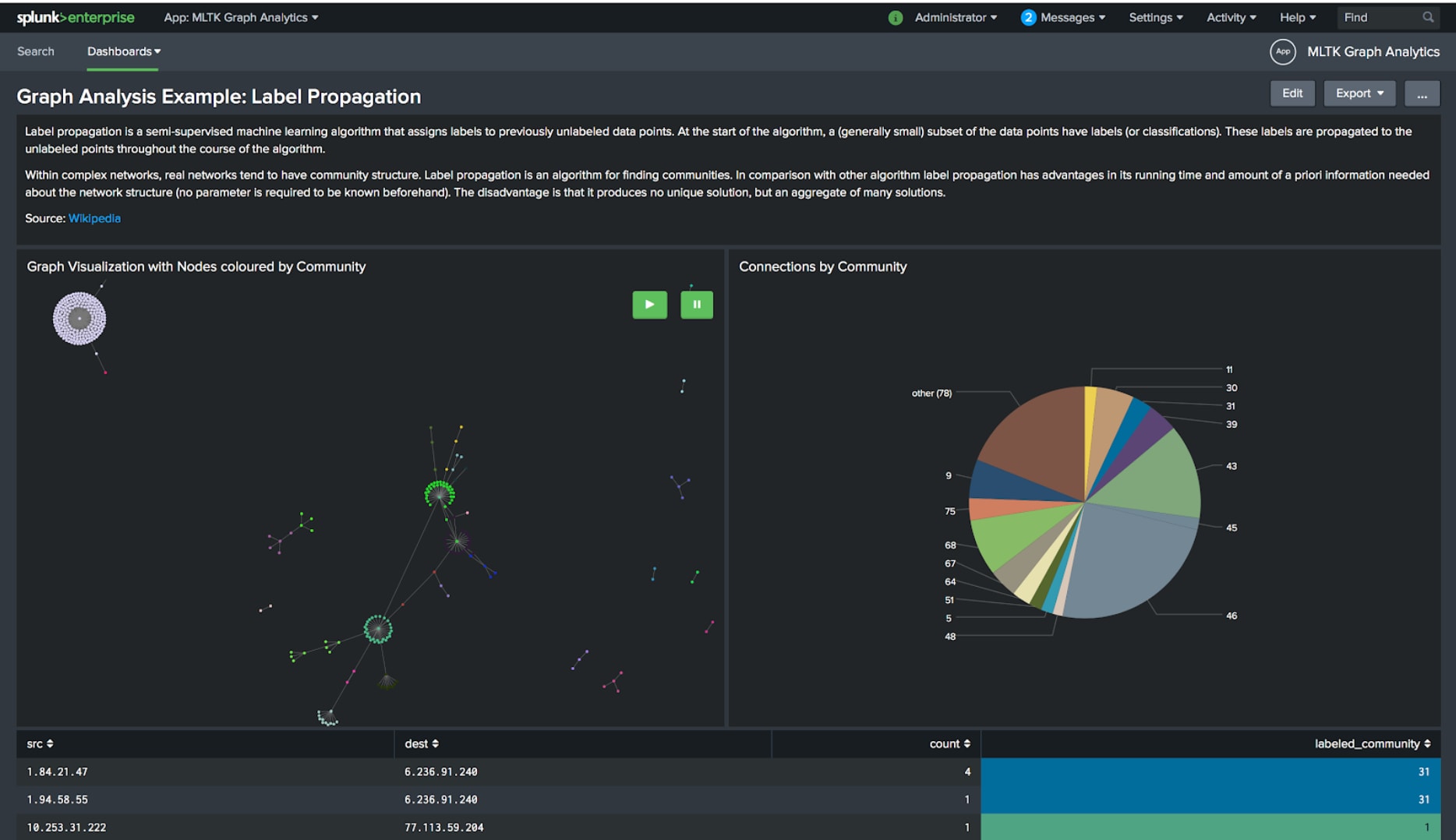
Ein weiterer interessanter Ansatz ist „Label Propagation“, ein teilüberwachter Machine Learning-Algorithmus. Er generiert Klassifizierungen zur Identifizierung von Gruppen in einem Graphen und bietet Analysten eine Struktur, die weiterverarbeitet und analysiert werden kann.
Juwelen zutage fördern
Jetzt solltet ihr so langsam die verborgenen Juwelen in euren Daten sehen. Und vielleicht konnte ich euch damit für diesen neuen Analysetyp begeistern, den ihr in Splunk auf eure Daten anwenden könnt. Vermutlich fragt ihr euch nun, wo ihr denn diese Algorithmen und Funktionen findet. Hier kommt die gute Nachricht: Die neueste Version (Version 2.0) des Python for Scientific Computing Package beinhaltet NetworkX, eine Bibliothek für die Graphanalyse. Damit habt ihr all diese Funktionen direkt zur Hand und könnt sie ganz einfach in Splunk anwenden! Ihr müsst die Algorithmen eurer Wahl nur über die MLSPL API in das Machine Learning Toolkit packen und es kann losgehen. Um das Ganze zu beschleunigen, habe ich die im Deep Learning Toolkit enthaltene Jupyter Notebook-Schnittstelle verwendet, um die oben erwähnten Algorithmen schnell zu skizzieren und innerhalb weniger Minuten wieder in das MLTK zu portieren. Damit die Sache noch etwas komfortabler wird, findet ihr die Beispiel-Dashboards und einige Graphalgorithmen fertig vorbereitet in der App für 3D-Graphvisualisierungen (3D Graph Network Topology Visualization App) auf Splunkbase.
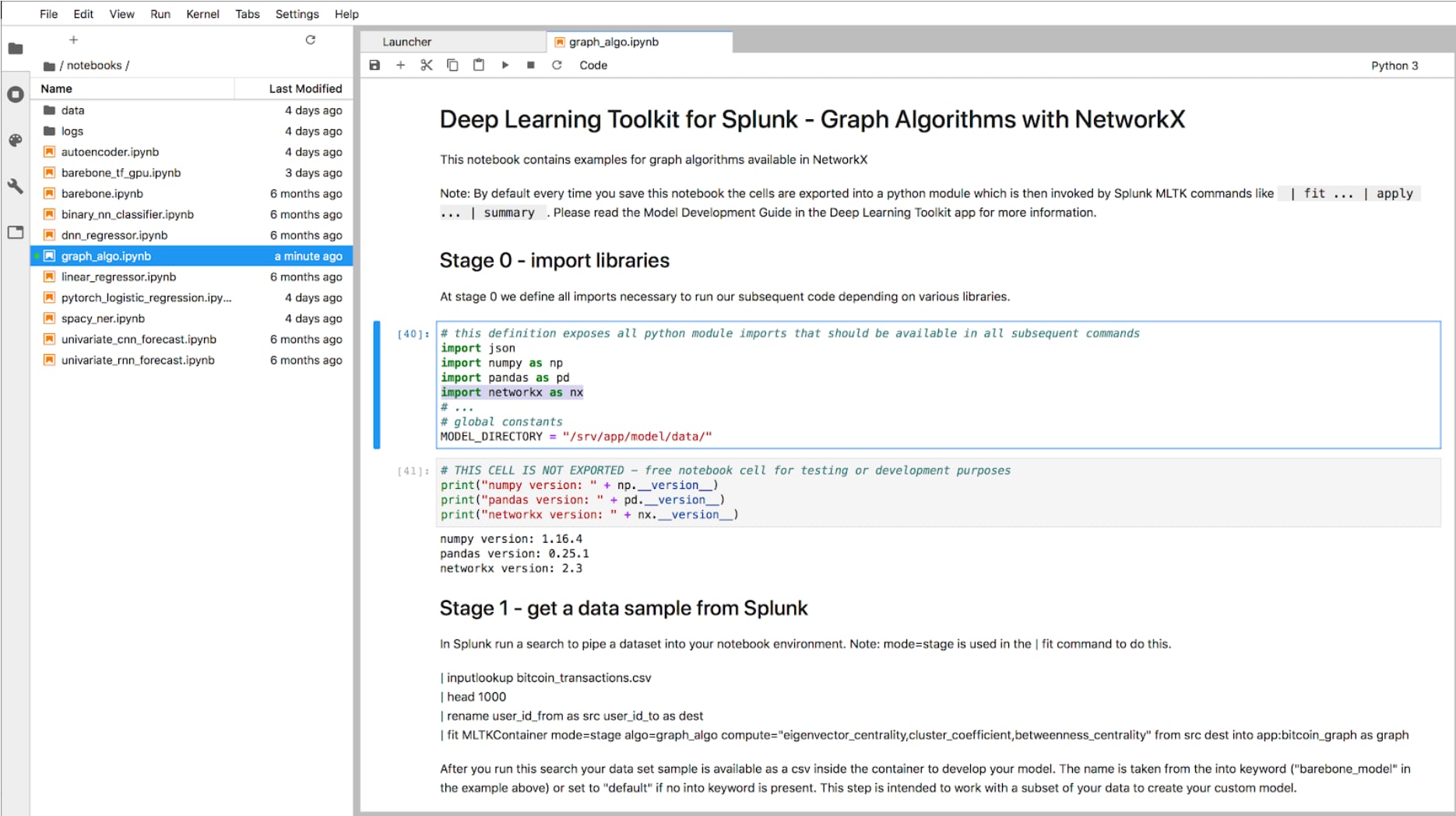
Und wenn der Graph wächst?
Was nicht vergessen werden sollte: Mit Graphen könntet ihr unter Umständen auf ein ernstes Problem stoßen: die Größe.
Wenn Graphen wachsen, kann die Berechnung ungemein komplex werden. In solchen Fällen seid ihr normalerweise mit drei Szenarien konfrontiert:
- Ihr möchtet rechnerisch sehr anspruchsvolle Algorithmen anwenden, daher ist die Rechenleistung der limitierende Faktor.
- Euer Graph ist so groß, dass ihr ihn über mehrere Knoten verteilen müsst. In diesem Fall ist der Speicher der limitierende Faktor.
- Es handelt sich zum eine Kombination aus beidem, mit verteilter Rechenleistung und verteiltem Speicher.
Im ersten Szenario lässt sich das Problem möglicherweise durch eine Beschleunigung der Berechnungen lösen, d. h. durch Parallelisierung auf GPUs mit Frameworks wie rapids.ai. In diesem Fall solltet ihr Anthonys Blogbeitrag zum Erstellen eines GPU-beschleunigten Containers für das Deep Learning Toolkit mit rapids.ai lesen. In den beiden anderen Fällen braucht ihr vermutlich moderne verteilte Computing-Architekturen wie Sparks GraphX, die mit Splunk verbunden werden müssten wie in diesem .conf17-Beitrag von Raanan und Andrew vorgestellt.
Wenn ihr die Graphanalyse weiter vorantreiben müsst, werdet ihr euch vermutlich für einen Graphspeicher (Graph Store) oder eine Graphdatenbank (Graph Database) wie Neo4j entscheiden, die ihr wieder mit Splunk verbinden könnt, beispielsweise mit der Neo4s App aus Splunkbase. Ich hoffe, ihr habt angesichts dieser zahlreichen Möglichkeiten genug Tipps für den Einstieg in diesen neuen Typ von Analyse Use Cases erhalten, die Ihr jetzt mit Splunk in Angriff nehmen könnt.
Happy Splunking!
Philipp
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Chasing a Hidden Gem: Graph Analytics with Splunk’s Machine Learning Toolkit (20.03.2020).
