Nutzt ihr einen S3-Bucket für mehrere AWS-Datenquellen und kämpft mit effizienten SNS-Benachrichtigungen auf der Grundlage von Präfixplatzhaltern? Dann keine Sorge – wir haben die Lösung für euch.
Viele unserer Kunden verwenden einen zentralisierten S3-Bucket für die Log-Erfassung aus mehreren Quellen und Accounts. Es können beispielsweise sämtliche Config-, CloudTrail- und Access Log-Logs in einen zentralen Bucket eines Unternehmens weitergeleitet werden. Das Schlüsselpräfix für diese Log-Objekte erleichtert im Allgemeinen die Navigation zu den einzelnen Account- und Log-Typen – die Objektschlüssel haben meist folgende Form:
Bucket/AWSLogs/Account_Nummer/Log_Typ/Region/Jahr/Monat/Tag/Log
Eine Best Practice-Methode, um diese Logs in Splunk zu erfassen, ist das Splunk Add-On für Amazon Web Services mit der Eingabe „SQS Based S3“ zu verwenden. Diese Eingabe nutzt im Wesentlichen eine SNS-Benachrichtigung für den Bucket sowie eine SQS-Meldung, mit der das Add-On neue Dateien im Bucket identifiziert, die es dann in Splunk einliest.
Auch wenn sich diese Lösung sehr gut skalieren lässt, gibt es bei dieser Logging-Methode jedoch Probleme, wenn mehr als eine Log-Quelle in einem Bucket abgelegt wird, also etwa CloudTrail und Config. Dies liegt daran, dass die SNS-Benachrichtigungen nur mit einem Platzhalter (Wild Card) am Ende des Präfixes (z.B. /Bucket/Account/*) ausgelöst werden können. Es ist daher bei einem zentralisierten Bucket nicht möglich, eine einzelne Benachrichtigung für alle CloudTrails im Bucket herauszufiltern, da dazu die Benachrichtigung auf „Bucket/AWSLogs/*/CloudTrail/*“ eingestellt sein müsste, was nicht zulässig ist.
Man könnte dies natürlich durch Einrichten mehrerer Benachrichtigungsthemen (Notification Topics), zugehöriger SQS-Warteschlangen und einer Add-On-Eingabe für jeden Account umgehen, doch dies würde mit der Zeit ziemlich komplex und ließe sich nur schwer verwalten und pflegen. Bei einem solchen Konstrukt würden beispielsweise 100 Accounts mit je 3 Log-Typen zu 300SNS-Themen, 300SQS-Warteschlangen (mit je einer weiteren Warteschlange für unzustellbare Nachrichten) und 300Add-On-Eingaben führen.
Es gibt aber eine viel einfachere Methode und Einrichtung mithilfe von Lambda-Funktionen. Anstelle separater SNS-Benachrichtigungen für jeden Account, könnte ein SNS-Topic für den gesamten Bucket eine Lambda-Funktion über eine SQS-Warteschlange auslösen, welche die Benachrichtigung wiederum abhängig von der Log-Quelle in andere SQS-Warteschlangen „weiterleitet“, die dann mit einer Add-On-Eingabe vom richtigen „Sourcetyp“ verknüpft sind. Bei dieser Methode könnte ein Bucket mehrere Accounts und Sourcetypen aufweisen, ohne dass eine Vielzahl von SNS-Themen, SQS-Warteschlangen und Add-On-Eingaben eingerichtet werden müssten. Im Fall unseres obigen Beispiels mit 100 Accounts und 3 Logs bräuchte man nur ein SNS-Topic mit nur 4SQS-Warteschlangen (mit je einer Warteschlange für unzustellbare Nachrichten).
(Man könnte auch den direkten Weg vom SNS-Thema zur Lambda-Funktion wählen und damit eine weitere SQS-Warteschlange einsparen. Bei einem Funktionsfehler gäbe es in diesem Fall allerdings keine Möglichkeit, die SNS-Benachrichtigung abzurufen, während die Benachrichtigung weiterhin in der Warteschlange enthalten wäre.)
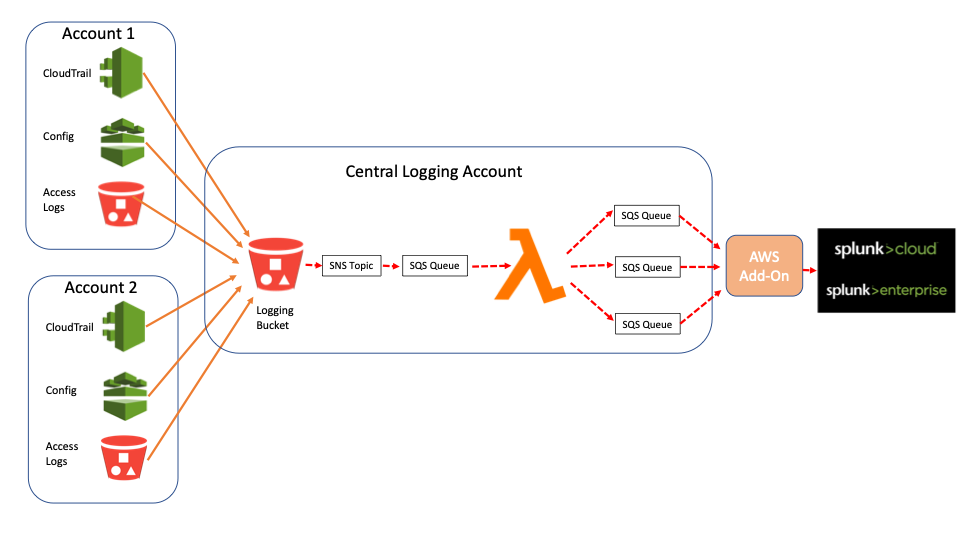
Eine detaillierte Einrichtungsanleitung, zusammen mit einer Lambda-Beispielfunktion, findet ihr übrigens in GitHub.
Die Beispielfunktion bietet einen Use Case, bei dem ein S3-Bucket drei verschiedene Quellen enthalten kann. Es werden Funktionsumgebungsvariablen verwendet, um die Warteschlangennamen für die einzelnen Quellen sowie die Standardwarteschlange für andere, dort abgelegte Objekte festzulegen. Die Funktion akzeptiert zudem eine Umgebungsvariable mit Ausschlussliste, damit bestimmte Objekte „ignoriert“ werden, die eventuell ebenfalls in den Bucket kopiert werden, jedoch nicht an Splunk übertragen werden müssen.
Es können weitere Use Cases zu der Funktion hinzugefügt werden, beispielsweise die Übertragung an andere Warteschlangen auf Grundlage der Account-Nummern. Damit könnten Logs aus bestimmten Account-Gruppen an unterschiedliche Splunk-Indizes übermittelt werden, um Sicherheits- oder Speicherungsanforderungen zu erfüllen.
Viel Spaß beim Splunken!
Paul
*Dieser Artikel wurde aus dem Englischen übersetzt und editiert. Den Originalblogpost findet ihr hier: Making the Collection of Centralised S3 Logs into Splunk easy with Lambda and SQS (10. Juni 2020).
