Im ersten Teil dieser Blogserie haben wir euch einen Use Case präsentiert, der gezeigt hat, wie Machine Learning (ML) zur Verbesserung von Polizeiarbeit eingesetzt und die Einsatzplanung mithilfe von ML-Verfahren optimiert werden kann. Grundlage dafür waren Verbrechensdaten der Stadt Chicago. Aber dies ist nicht die einzige Möglichkeit, Verbrechen vorherzusagen und zu verhindern. Unser nächstes Beispiel führt uns nach London, wo wir uns die Arbeit von Paul McDonough und Shashank Raina von der NCCGroup ansehen.
Wir prognostizieren die Londoner Verbrechensrate
Damit Predictive Analytics funktionieren kann, brauchen wir zuerst ein paar Daten. Nehmen wir also an, wir hätten Zugriff auf Daten, mit denen verschiedene Aspekte erfasster Verbrechen nachverfolgt werden. Glücklicherweise geben viele Regierungen und Verwaltungsorgane Zugriff auf öffentlich einsehbare Daten wie beispielsweise data.police.uk. Wir laden diese Daten in Splunk, um den Ball zum Rollen zu bringen. Genau diese Methode setzten auch Paul und Shashank bei ihrer Präsentation auf der .conf18 ein.
Auf der Konferenz wollten sie demonstrieren, dass Splunks Machine Learning Toolkit für reale Probleme eingesetzt werden und uns helfen kann, klarere Antworten zu erhalten. Dabei führten sie typische Schritte vor, die zeigen, wie man Splunk ganz leicht für Prognoseprobleme nutzen kann. Sie führten einige grundlegende Aufgaben durch, die auf jedes ML Toolkit-Beispiel anwendbar sind:
- Erstellen des Datasets: Es wurden öffentlich verfügbare, für London geltende Daten aus Regierungs-Webseiten verwendet, wie etwa Verbrechensstatistiken, Volkszählungsdaten, Angaben zu Kinderarmut, Einkommensverteilung usw.
- Vorverarbeitung der Daten: Um Probleme mit Datenabweichungen im Modell zu verhindern, wurden in Splunk verschiedene Befehle ausgeführt, wie z. B. kmeans, analyzefields und anomalousvalue.
- Erstellung eines prädiktiven Modells: Es waren sechs verschiedene Modelltypen zur Erstellung verfügbar: Numerisch, kategorisch, numerische Ausreißer, kategorische Ausreißer, Zeitreihenprognose und numerischer Cluster.
- Prognose künftiger Werte: Das im vorherigen Schritt erstellte Modell wurde anschließend zur Prognose künftiger Werte verwendet.
McDonough und Raina folgten den obigen Schritten und erstellten mithilfe der Splunk ML Toolkit-App ein Modell zur Verbrechensvorhersage. Damit erhielten sie interessante Erkenntnisse zu den Faktoren, die sich auf die Verbrechensrate in London auswirken. Im Folgenden findet ihr die Präsentation der beiden und einen Blogartikel, in dem die durchgeführten Schritte detailliert beschrieben werden.
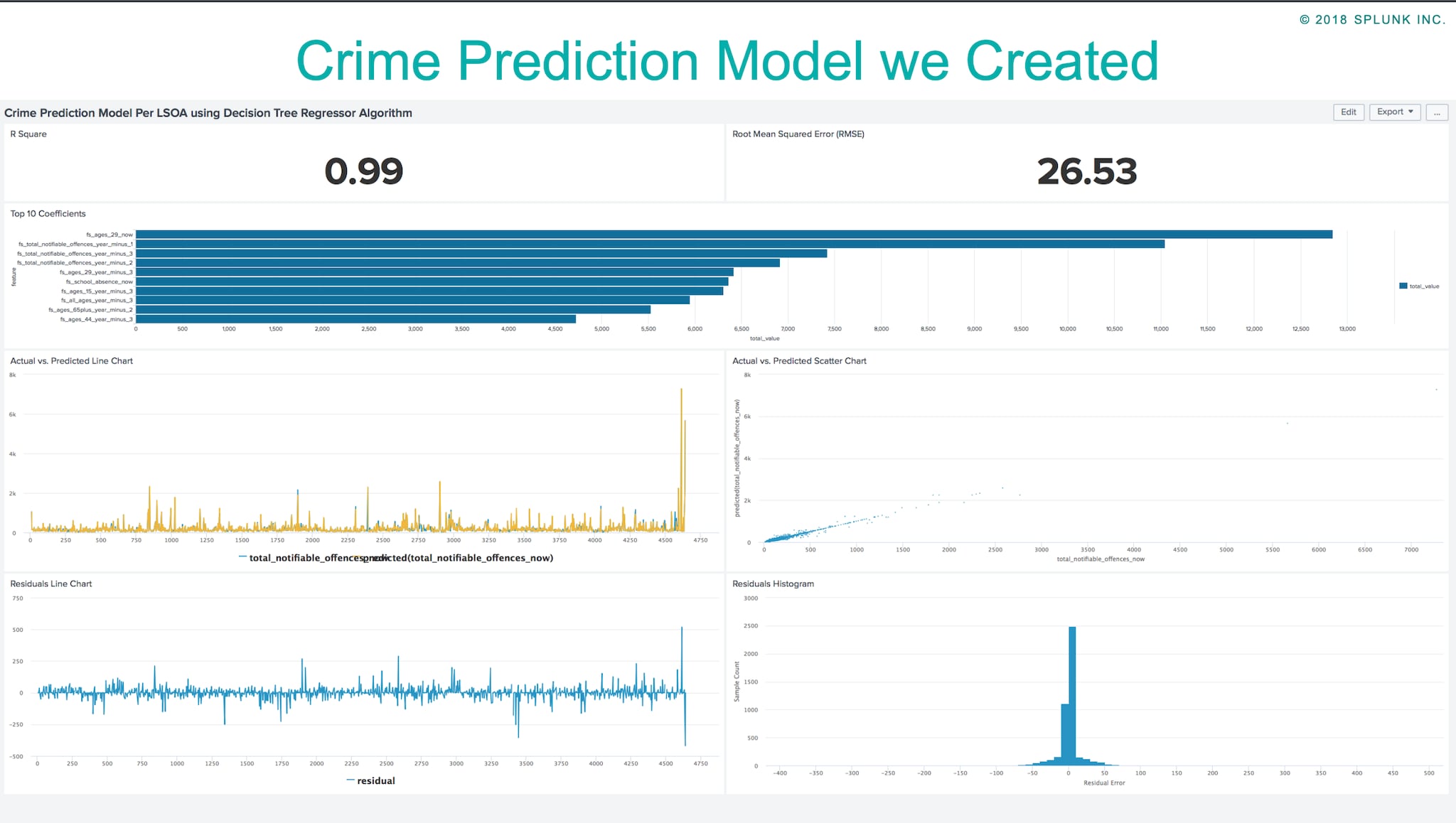
Analyse von Verzerrungen bei Machine Learning-Modellen
Wie bereits erwähnt, hielten McDonough und Raina einen Vortrag auf der Splunk .conf18 und stellten dabei vor, wie man das Splunk ML Toolkit zum Erstellen von Machine Learning-Modellen einsetzen kann. Da Machine Learning seit geraumer Zeit in aller Munde ist, haben sie das Ganze mit etwas Abstand betrachtet und versucht, die Wirkung der entwickelten Modelle und ihre Anwendung in der realen Welt zu verstehen. Aufgrund der fortschreitenden technologischen Entwicklung konnten sie einerseits eine zunehmende Nutzung prädiktiver Techniken beobachten, andererseits gab es aber auch viele Meldungen über Verzerrungseffekte bei ML-Modellen. Hier einige Beispiele dazu:
- Amazon beendet die Verwendung seines Modells zur Bewertung von Stellenbewerbern, nachdem klar wird, dass es Frauen abwertet.
- Prädiktive Systeme für die Polizeiarbeit wurden genau unter die Lupe genommen und ihr Einsatz wurde schließlich aufgrund festgestellter Verzerrungen eingeschränkt.
- Systeme zur Personalisierung von Inhalten erzeugen Filterblasen, und gegen Ad Ranking-Systeme werden Vorwürfe wegen rassen- und geschlechtsspezifischer Profilerstellung erhoben.
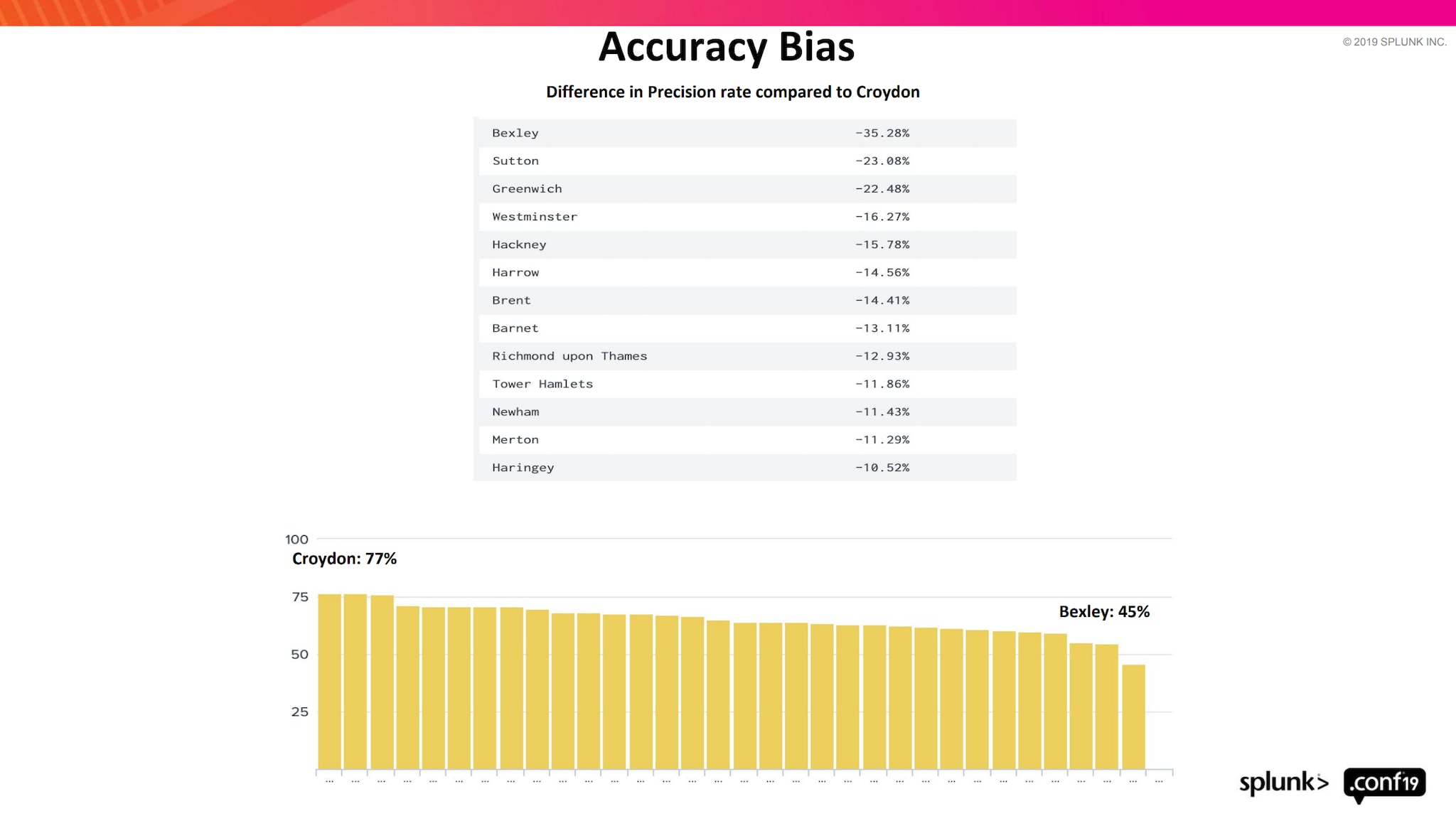
Verzerrungen bedeuten Voreingenommenheit, die als Vorurteil oder Diskriminierung gegenüber etwas, jemandem oder einer Gruppe definiert ist. Eine diskriminierende Verzerrung entsteht dann, wenn datengesteuerte Entscheidungen zu unausgewogenen Ergebnissen führen. Und leider ist die traurige Wahrheit, dass alle großen Datenmengen verzerrt sind. Die meisten Benutzer, die diese Modelle erstellen, sind sich dessen jedoch nicht bewusst, da das Phänomen der Verzerrung bei Machine Learning in der Regel kaum oder gar nicht diskutiert wird. Selbst wenn sich einige Wenige des Problems bewusst wären, wüssten sie nicht, was sie dagegen tun sollten. Aufgrund des großen Wirbels um Machine Learning verlegen sich Modellierer hauptsächlich darauf, immer komplexere und größere ML-Modelle zu erstellen, die ihnen zu einer größeren Abdeckung verhelfen. Dennoch sind nur wenige bereit, sich mit den inhärenten Problemen der Verzerrung von Daten bei den von ihnen entwickelten ML-Modellen auseinanderzusetzen.
Bei unserer Präsentation auf der Splunk .conf 2019 haben wir über das Phänomen der ML-Verzerrung und seine Auswirkungen gesprochen. Außerdem haben wir erläutert, wie diese Verzerrung minimiert werden kann. Seht euch mal die folgenden Zahlen genauer an:
Zusammenfassung
In dieser Blogserie wurden verschiedene Punkte bezüglich der Vorhersage und Verhinderung von Verbrechen behandelt. Die Ausführungen zur Verzerrung bei Modellen zeigen, wie wichtig es ist, aufmerksam und vorsichtig vorzugehen, besonders, wenn es um Modelle geht, die sich direkt oder indirekt auf Menschen auswirken. Wenn ihr euch näher mit diesem Thema beschäftigen möchtet, findet ihr hier weitere .conf-Vorträge dazu. Schaut euch außerdem auch mal die Präsentation Mind the Gap! von Dipock Das an.
Ich persönlich möchte mich noch mit einem herzlichen DANKESCHÖN bei Shashank von NCC und Paul von 13 Fields für ihre Mitarbeit an den beschriebenen Inhalten bedanken.
Macht weiterhin so tolle Arbeit und Happy Splunking,
Philipp
