Wenn ihr bereits Daten aus der Google Cloud Platform (GCP) erfasst habt oder dies plant, habt ihr sicherlich bemerkt, dass zur Aufnahme der Daten das Google Cloud Platform Add-On von Splunk verwendet wird.
Viele Kunden nutzen derzeit jedoch „serverless“ Cloud-Services für die Bereitstellung ihrer Cloud-Lösungen. Dafür gibt es viele Gründe, aber vor allem spricht dafür, dass man dadurch Lösungen erhält, für die kein Overhead an Server- oder Container-Management notwendig ist, die skalierbar sind und als Teil der Cloud-Plattform bereitgestellt werden. Das Add-On kann Daten zwar aus GCP extrahieren (Pull), doch eine neue Funktionsbibliothek bietet eine serverlose Push-Funktion, die die Add-On-Funktionalität zum Senden von Daten an Splunk via HEC repliziert und erweitert. Diese Push-Funktion gibt GCP-Kunden ähnliche Möglichkeiten, wie sie AWS-Kunden bei der Verwendung von Kinesis Firehose- oder Lambda-Funktionen haben.
Vorteile dieser serverlosen „Push to Splunk”-Option:
- Kompatibilität: Die bereitgestellte Datensammlung ist mit dem Splunk Add-On kompatibel, sodass ihr entsprechend eurer Vorlieben zwischen Add-On und Funktionen wechseln könnt.
- Keine Infrastruktur: Dies kann besonders nützlich sein, wenn ihr eine Möglichkeit entwickelt, testet und bereitstellt, mit der Daten ohne Heavy Forwarder aus GCP integriert werden können. Außerdem ist dies für Splunk Cloud-Kunden ideal.
- Effizienz: Die neuen Funktionen für das Projekt bieten zudem eine in puncto Lizenz und Suche effizientere Option für Metriken, da für sie jetzt der Metrikindex (Metrics Index) verwendet werden kann, der sich an Splunks Application for Infrastructure und anderen Infrastrukturmetriken orientiert. Derzeit werden verfügbare Metriken aus dem Add-On nur bei Events bereitgestellt.
- Flexibilität: Die Bibliothek bietet eine Funktion, mit der Daten aus jedem Objekt gelesen werden können, das in einen GCS-Bucket geschrieben wird, einschließlich GCS Asset-Dateien (die von einer anderen Funktion erstellt werden können). Beim derzeitigen Add-On ist das Einlesen aus GCS beschränkt (Billing). Die Funktionsbibliothek bietet daher die Möglichkeit, die meisten eurer GCP-Monitoring-Anforderungen aufzunehmen – von Logs über Assets bis hin zu Metriken – ganz ohne Heavy Forwarder!
- Stressfrei: Dies ist der ideale Einstieg in die Aufnahme von Daten aus GCP.
Da diese Funktionen als Service innerhalb von GCP ausgeführt werden, skalieren sie automatisch entsprechend den Workload-Anforderungen und werden nur nach Nutzung berechnet (d. h. sie sind nicht immer eingeschaltet). Da der Haupt-Service zudem fehlertolerant ist, müsst ihr auch kein Failover- oder Hochverfügbarkeits-Setup für eure VMs konfigurieren, auf denen das Add-On ausgeführt wird. Ein weiterer Vorteil ist, dass keine Service-Konten oder -Schlüssel außerhalb eurer GCP-Umgebung gemeinsam genutzt werden müssen.
WAS GENAU DÜRFT IHR ERWARTEN?
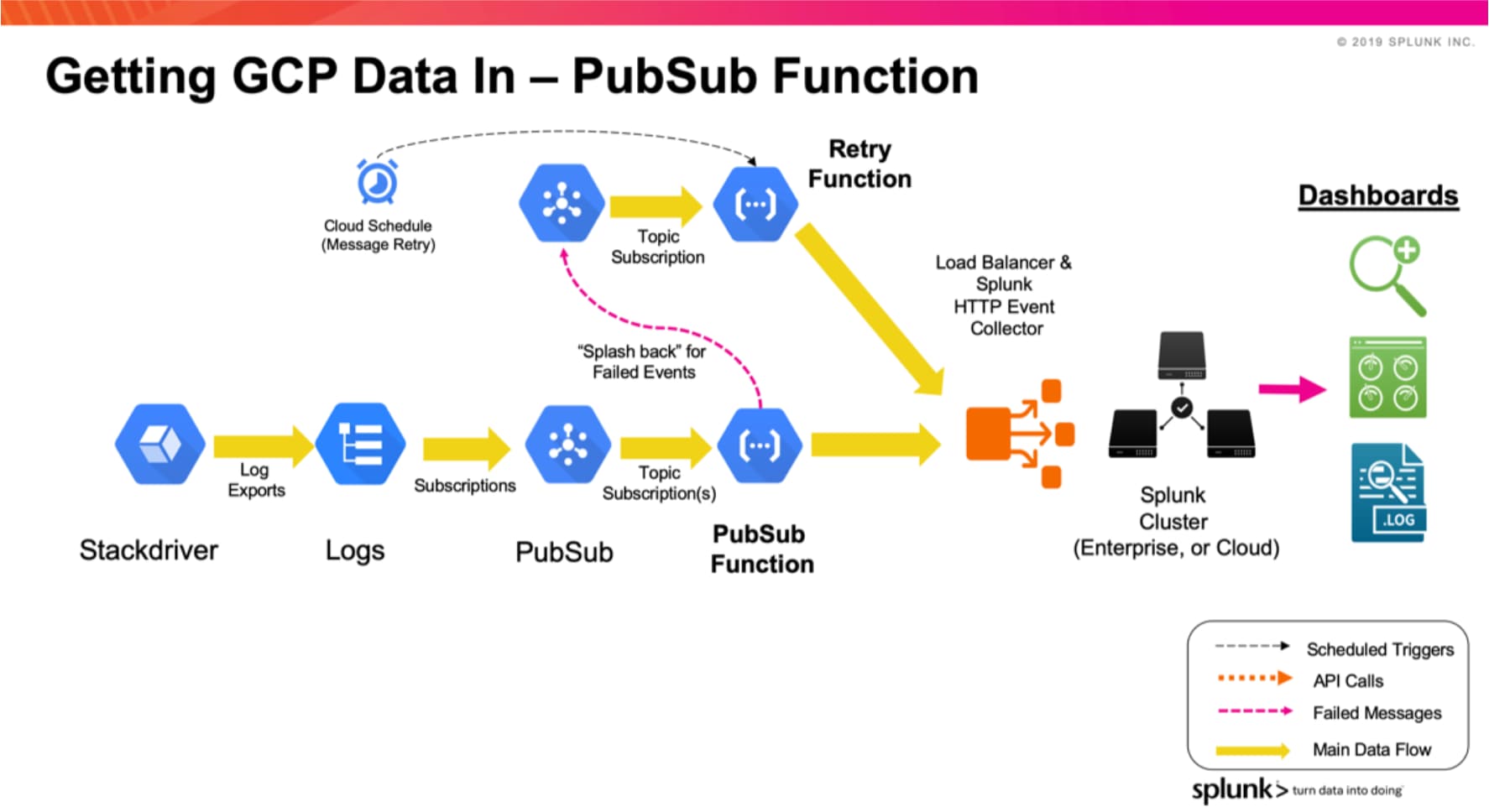
PubSub-Funktion – Streamt eure Logs in HEC
Die PubSub-Funktion ist so konfiguriert, dass sie jede Nachricht erfasst, die in einem von ihr abonnierten PubSub-Thema platziert wird. Im Allgemeinen handelt es sich bei diesen Nachrichten um Protokolle, die aus Stackdriver exportiert werden, der Service-Monitoring-, Audit- und Aktivitätslogs aus GCP bereitstellt. Das nachfolgende Diagramm zeigt die Abläufe bei dieser Funktion.
Die Logs werden über „Log Export“ aus Stackdriver erfasst, und danach wird das Log-Abonnement in einem PubSub-Thema platziert. Es kann bei Bedarf mehr als ein Log Export in einem PubSub-Thema platziert werden. Diese Konfiguration ist mit der des Add-Ons identisch. Sobald die Funktion in eurem GCP-Projekt installiert wurde, kann sie das PubSub-Thema abonnieren. Beim Empfang einer PubSub-Nachricht sendet die Funktion den Inhalt über HEC weiter an Splunk. Tritt bei der Übertragung des Events an HEC ein Fehler auf, wird die Nachricht an ein PubSub-Thema namens „Retry“ gesendet. In regelmäßigen Abständen werden die Events im PubSub-Thema „Retry“ an Splunk HEC übertragen (oder später gesendet, falls erneut ein Fehler auftritt).
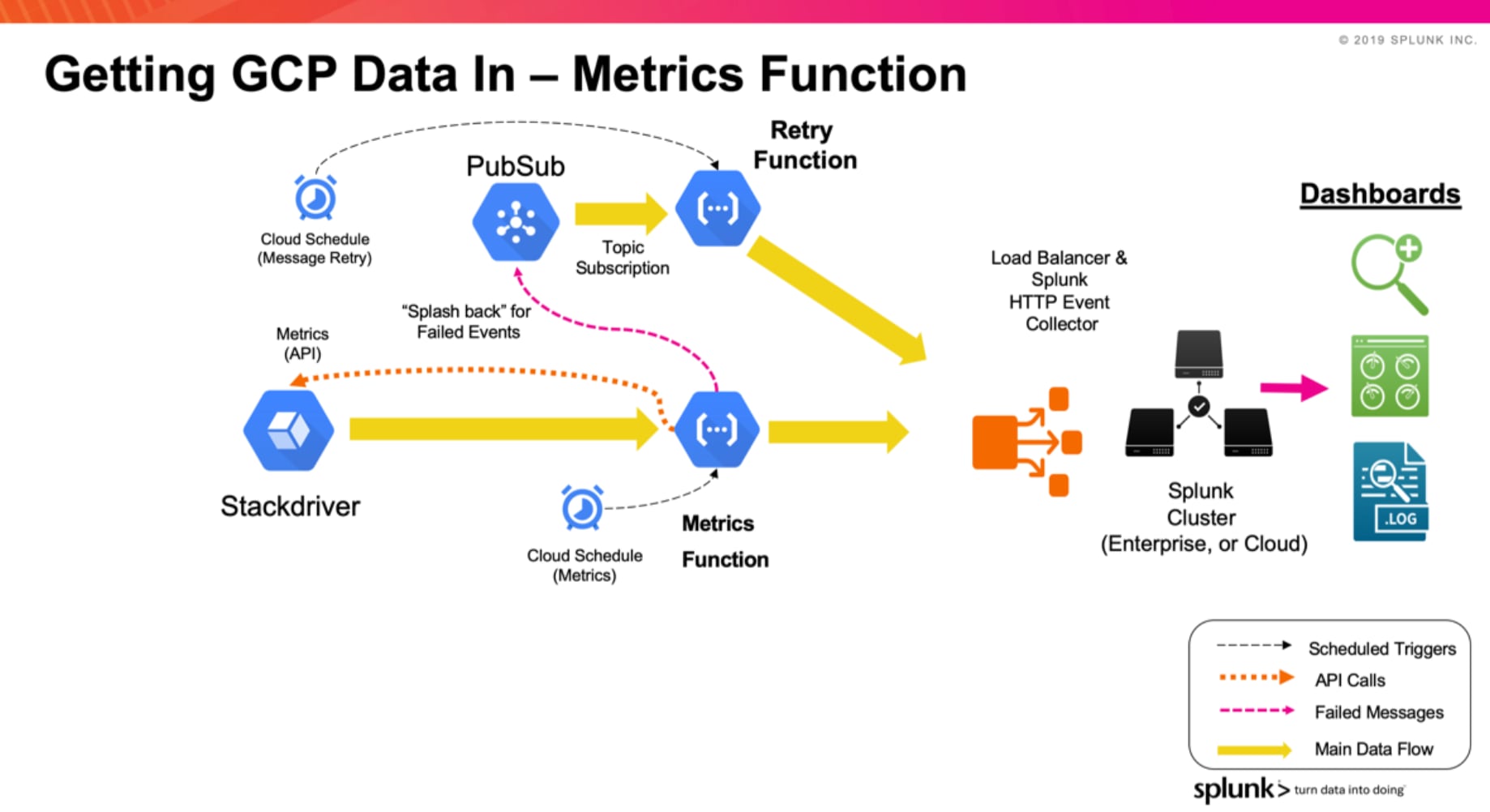
Metrics-Funktion – Sammelt Metriken in HEC
Die Metrics-Funktion ist dafür konfiguriert, Metriken für eure Infrastrukturkomponenten von Stackdriver anzufordern. Pro Funktion können eine Metrikliste sowie die Häufigkeit bzw. das Intervall der Metriken konfiguriert werden. Wie auch bei der PubSub-Funktion werden fehlgeschlagene Nachrichten an das PubSub-Thema „Retry“ gesendet, von wo aus sie später in regelmäßigen Abständen an Splunk übermittelt werden.
Bei der Konfiguration der Metrics-Funktion stehen zwei Formate für die Übertragung der Metriken an Splunk zur Auswahl:
- Event Format: Dieses Format entspricht dem Metrik-Sourcetyp des GCP Add-Ons (google:gcp:monitoring).
- Metrics Index Format: Dieses Format nutzt Splunks Metrics Index zum Speichern der Metriken.
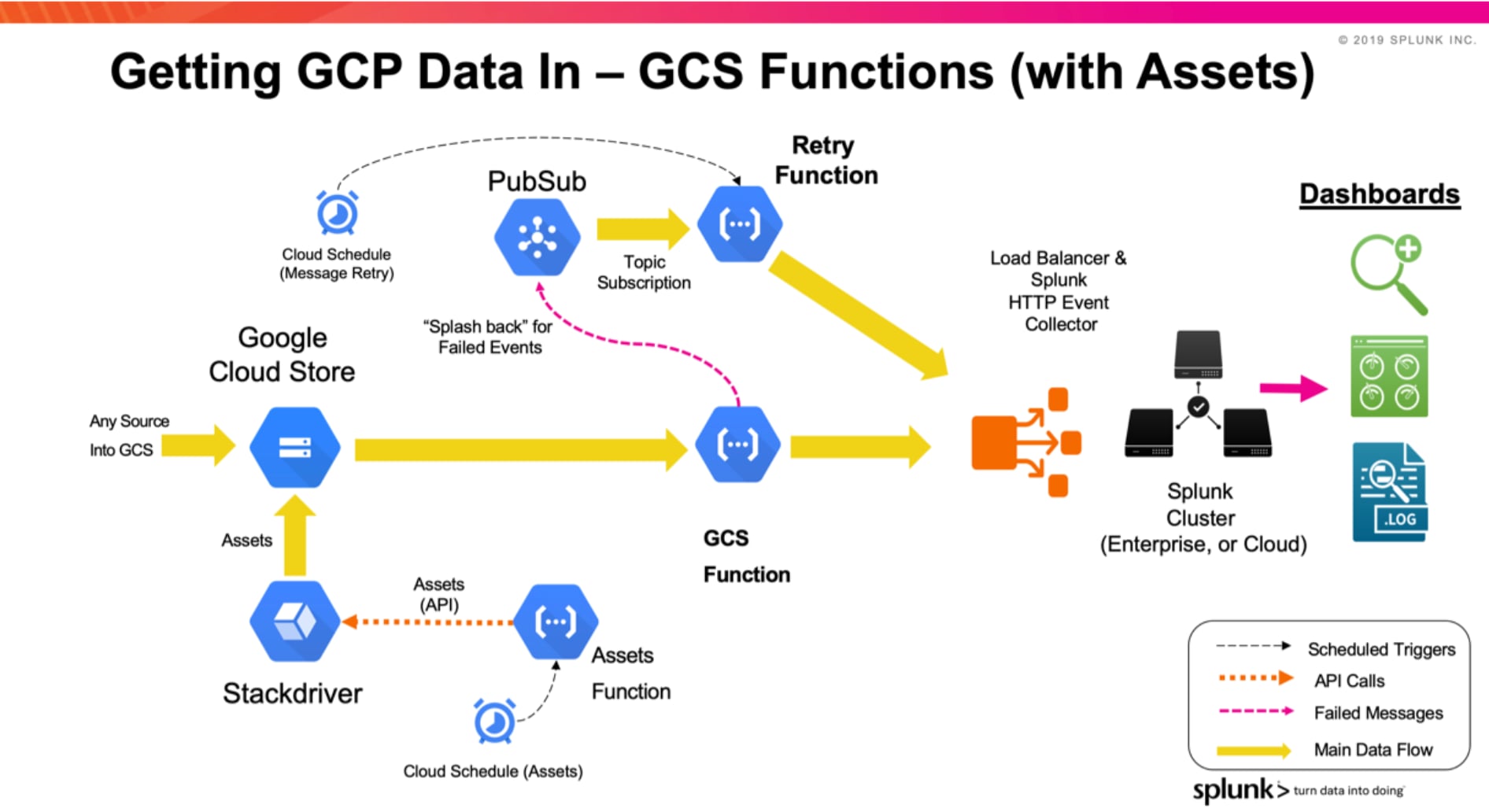
GCS- und Asset-Funktionen – Abrufen von (beliebigen) Daten aus Google Cloud Storage
Die GCS-Funktion sendet Daten über HEC aus einem GCS-Bucket an Splunk. Die Funktion wird ausgelöst, wenn ein neues Objekt in einen Bucket eingefügt wird (durch Finalisieren/Erstellen). Die Funktion ist so konfiguriert, dass sie Events aus dem Objektelement liest und sie dabei nach den Einstellungen in der Sourcetyp-Definition in Splunk gliedert (Zeilenumbruch). Bei großen Objekten wird der Objektinhalt vor der Übertragung an Splunk in Event-Batches aufgeteilt. Aus diesem Grund ist die an Splunk übermittelbare Objektgröße unbeschränkt (abgesehen von GCS-Einschränkungen), und die Events im Objekt werden auf die Indexer verteilt (über den Load Balancer).
Diese Funktionalität steht im GCP Add-On derzeit nicht zur Verfügung.
Zusätzlich bietet die GCS-Funktion die Möglichkeit, eine andere Funktion für die Anforderung von GCP Asset-Informationen zu verwenden (Inventory). Diese Funktion kann für die Ausführung in einem Intervall geplant werden und die Asset-API für gcloud aufrufen, die die Asset-Informationen an einen GCS-Bucket sendet. Wird eine GCS-Funktion so eingerichtet, dass sie durch neue Objekte in diesem Bucket ausgelöst wird, kann sie die Asset-Daten an Splunk senden.
Retry-Funktion – Aufräumen, wenn etwas schief läuft
Die Funktionsbibliothek wird samt einer Retry-Funktion zur Verfügung gestellt, die in Verbindung mit einem PubSub-Thema und einem Cloud-Zeitplan verwendet wird. Im PubSub-Thema werden Events oder Metriken (oder Event-Batches) gesammelt, deren Übertragung an Splunk HEC fehlschlug. Übertragungsfehler werden meist durch Verbindungsprobleme zwischen GCP und dem Load Balancer bzw. Indexern verursacht. Tritt bei einer der Funktionen ein Fehler auf, sendet sie das Event an ein PubSub-Thema namens „Retry“. Dieses Thema kann für mehrere Funktionen gemeinsam verwendet werden (n:1 im Gegensatz zu 1:1). Ein Cloud-Zeitplan löst die Retry-Funktion nach einem festgelegten Zeitraum aus (definiert von einem Cron-Zeitplan). Die Funktion ruft die Events oder Metriken aus dem Thema ab und sendet sie an die ursprüngliche Kombination aus HEC-URL und Thema. Schlägt die Übertragung während des Retry-Vorgangs fehl, verbleiben die Events bzw. Metriken im Thema, bis beim nächsten geplanten Funktionsaufruf ein erneuter Übertragungsversuch unternommen wird.
Erste Schritte
Der Inhalt der Bibliothek steht hier zum Download bereit: https://github.com/splunk/splunk-gcp-functions
Das Repository enthält Dokumentation und eine Reihe von Beispielen zum Einrichten der Funktionen. Die Beispiele umfassen Skripte, die das Repository klonen und die Funktionen (mit gcloud CLI-Befehlen) in einer einfachen Beispielkonfiguration installieren bzw. einrichten. Die Beispielskripte können in euren Cloud-Automatisierungs- bzw. Orchestrierungs-Builds wiederverwendet werden, um die Bereitstellung der Funktionen in euren GCP-Projekten zu automatisieren.
Danke fürs Lesen!
Paul
