Splunk は先日、Splunk Connect for Kafka をリリースしました。Apache Kafka Connect フレームワークを活用したこのコネクターは、Kafka と Splunk の公式な統合手段として長期にわたって使用されてきた Splunk Add-on for Kafka に代わるものです。詳しくは、Michael Lin のブログ記事「Unleashing Data Ingestion from Apache Kafka (Apache Kafka からのデータ取得を活用する)」を参照してください。
この記事では、Splunk Connect for Kafka の概要とそのインストール、設定、デプロイ方法についてご説明します。
Kafka Connect とは
まず、Apache Kafka とは、データ中心のアプローチが浸透しつつある今日のビジネス界で大きな注目を集めている分散データストリーミングプラットフォームです。このプラットフォームは、Pub/Sub (出版/購読) メッセージバスの概念を、サービス間のデータパイプライン構築とデータストリーミングを実現する高速なフォールトトレラント技術によって進化させました。Apache Kafka を利用すれば、次世代型のストリーミングアプリケーションを開発できます。Kafka Connect は、こうしたさまざまなサービスを、再利用可能かつ拡張性の高い方法で Kafka と統合したいというニーズを受けて誕生しました。統合の構築、デプロイ、管理のための使いやすいツールが用意されているため、Kafka のトピックデータを簡単に受信できます。
シンクコネクターとソースコネクター
ごく単純に言えば、Kafka はデータを受け取り、別の場所に配信します。Kafka Connect でこの概念を実装するのがソースコネクターとシンクコネクターです。ソースコネクターはシステムから Kafka にデータをインポートし、シンクコネクターは Kafka からシステムにデータをエクスポートします。
Splunk Connect for Kafka とは
Spunk Connect for Kafka は、Kafka Connect フレームワークに基づいて構築された、Kafka トピックのデータを Splunk にエクスポートするための「シンクコネクター」です。速度と信頼性を重視して、このコネクターには、大規模な Splunk 環境へのメッセージ送信に対応した、拡張性が高くカスタマイズ性に優れた Splunk HTTP イベント コレクター クライアントが内蔵されています。
入手先
- 最新リリースは Splunkbaseからダウンロードできます。
- オープンソースの GitHubでも公開されています。
ハウツー:手順
概要説明はこのくらいにして、コネクターの設定とデプロイ方法に移りましょう。
- デプロイにおける考慮事項 (ACK ありか ACK なしか、HEC Raw エンドポイントか JSON Event エンドポイントか)
- Splunk の設定
- コネクターのインストールと設定
- コネクターのデプロイ
デプロイにおける考慮事項
Splunk へのイベントの送信方法について、次の点を検討する必要があります。
- ACK ありか ACK なしか
- HEC Raw エンドポイントか JSON Event エンドポイントか
ACK ありか ACK なしか
コネクターには、配信が少なくとも 1 回完了したことを保証するエンドツーエンドの ACK (Acknowledgement) が組み込まれています。ACK 層の追加は、HTTP イベントコレクターの信頼性を向上させ、実装環境でのインデクサーの負荷やネットワークの信頼性に関する問題の解決にも役立ちます。速度を優先する場合は、ACK を無効にすることもできます。
HTTP Event Collector Raw エンドポイントか JSON Event エンドポイントか
HTTP イベントコレクターには、イベントを取り込むためのエンドポイントが 2 つ用意されています。一方の Raw エンドポイントは、処理能力が高く高速です。もう一方の JSON Event エンドポイントは、イベントにメタデータフィールドを追加できるため、取り込んだイベントを Splunk で柔軟に検索できる利点があります。
これらのオプションについては、設定手順の中でもご説明します。
Splunk の設定
HTTP イベントコレクター (HEC)
Kafka トピックデータを取り込むように Splunk を設定するには、すべての Splunk 受信ノードに、有効な HEC トークンを設定するだけです。HEC の設定には一般に、ヘビーフォワーダーを使って収集層を経由して HEC にイベントを送信する方法や、Splunk のインデックス層に直接送信する方法など、さまざまなものがあります。いずれも有効な設定ですが、Kafka イベントに最適なのはインデックス層に直接送信する方法です。
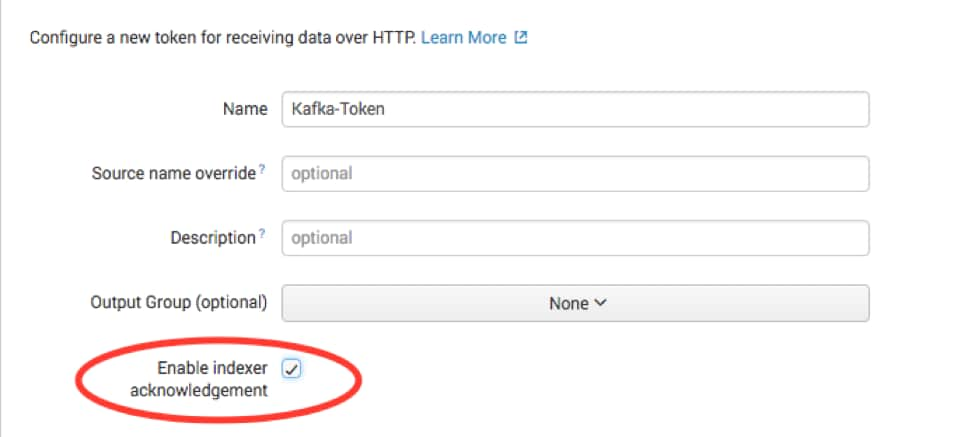
Splunk Connect for Kafka を使って Splunk にデータを配信するには、まず、Splunk HEC でデータを受信するように設定する必要があります。Splunk Web にアクセスし、[Settings] メニューから [Data inputs] を選択して、[HTTP Event Collector] を選択します。[Global Settings] を選択して、[All tokens] が [enabled] になっていることを確認してから、[保存] を選択します。次に、[New Token] を選択して、新しい HEC エンドポイントとトークンを作成します。
事前に決めた ACK ありか ACK なしかに応じて、[Enable indexer acknowledgment] を設定します。ACK ありの場合はこのチェックボックスを選択し、ACK なしの場合は選択を解除します。
次の画面では、ソースタイプ、コンテキスト、インデックスに関するオプションの設定を求められます。
Kafka から取り込むデータに基づいてオプションを選択します。Splunk 側の設定は以上です。HEC トークンは、後で Splunk Connect for Kafka の設定時に使用するので、メモしておいてください。
Splunk のデプロイサーバーを使用した大規模分散環境では、複数のサーバーのトークンを作成するほうが、HEC トークンの設定方法として効率的な場合があります。分散環境について詳しくは、「High volume HTTP Event Collector data collection (HTTP イベントコレクターの大量データの収集)」を参照してください。
コネクターのインストールと設定
まずは、JAR ファイルパッケージを入手して (入手先は前述)、Splunk コネクターを実行するすべての Kafka Connect クラスターノードにインストールします。Kafka Connect には、スタンドアロンモードと分散モードの 2 つのモードがあります。以降の手順では、分散モードを対象に説明します。
Kafka Connect を起動するときは、$KAFKA_CONNECT_HOME ディレクトリから、ワーカー プロパティ ファイル connect-distributed.properties を指定して、次のコマンドを実行します。
./bin/connect-distributed.sh config/connect-distributed.properties
Kafka にはデフォルトのプロパティファイルがいくつか含まれていますが、Splunk Connector を適切に機能させるには、次のワーカープロパティを指定する必要があります。connect-distributed.properties を必要に応じて変更することも、新しいプロパティファイルを作成することもできます。
#These settings may already be configured if you have deployed a connector in your Kafka Connect Environment
bootstrap.servers=<BOOTSTRAP_SERVERS>
plugin.path=<PLUGIN_PATH>
#Required
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.flush.interval.ms=10000
#Recommended
group.id=kafka-connect-splunk-hec-sink
次の 2 つのオプションには追加の設定が必要です。
- bootstrap.servers – Kafka ブローカーの配置先をカンマ区切りで指定したリストです。
- plugin.path –JAR で Kafka Connect を認識できるようにするには、Kafka Connect の起動時に前述の手順でコネクターがインストールされたフォルダーのパスが、プラグインのパス変数で指定されている必要があります。
ワーカー プロパティ ファイルと追加設定について詳しくは、 こちらを参照してください。
注: 旧バージョンの Kafka Connect 0.10 を使用している場合は、コネクターの設定手順が異なります。システムの Java クラスパスにファイルを追加する必要があります。詳しくは、こちらを参照してください。 こちらを参照してください。
プロパティファイルを設定したら、準備完了です。Kafka Connect をデプロイしましょう。プロパティファイル名をそのまま使用する場合、Kafka Connect をデプロイするには、次のコマンドを実行します。
./bin/connect-distributed.sh config/connect-distributed.properties
この手順を、Kafka Connect クラスターに含めるすべてのサーバーで実行します。
ここで、Splunk Connect for Kafka が正しくインストールされ、デプロイされていることを確認しましょう。次のコマンドを実行して、結果をメモします。
curl http://<KAFKA_CONNECT_HOST>:8083/connector-plugins
応答には次のエントリーが含まれるはずです。
com.splunk.kafka.connect.SplunkSinkConnector.
適切な応答が返ったことを確認したら、次はコネクターをインスタンス化します。
コネクターのインスタンス化
プロパティファイルで必要な設定をして Kafka Connect クラスターを稼働させたら、REST インターフェイスからコネクターとタスクを管理します。REST 呼び出しは常に 1 台のホストに対してのみ実行します。これにより、変更がクラスター全体に伝播されます。
この記事の前半で、Splunk Connect for Kafka の運用について、ACK の有無と使用するエンドポイントの 2 つの設計上の選択が重要だと説明しました。これらを設定するパラメーターが、splunk.hec.raw と splunk.hec.ack.enabled です。
以降の手順では、ACK ありで、イベントエンドポイントを経由してデータを取り込むようにコネクターを設定します。
ACK ありで HEC/event エンドポイントを使用する場合の Splunk インデックス設定:
curl <hostname>:8083/connectors -X POST -H "Content-Type: application/json" -d'{
"name": "splunk-prod-financial",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
“tasks.max": "10",
"topics": "t1,t2,t3,t4,t5,t6,t7,t8,t9,t10",
"splunk.hec.uri":"https://idx1:8089,https://idx2:8089,https://idx3:8089",
"splunk.hec.token": "1B901D2B-576D-40CD-AF1E-98141B499534",
"splunk.hec.ack.enabled : "true",
"splunk.hec.raw" : "false",
"splunk.hec.json.event.enrichment" : "org=fin,bu=south-east-us",
"splunk.hec.track.data" : "true"
}
}'
こちらが今回の設定オプション設定です。1 つずつ簡単にご説明します。Splunk Connect for Kafka のすべての設定パラメーターとその詳細については、 こちらを参照してください。
- name:コネクターの名前です。この名前でコンシューマーグループが作成され、コネクタークラスターの各ノードにタスクが均等に分散されます。
- connector.class:コネクターのジョブを実行する Java クラスです。コネクターを変更する必要がない限り、デフォルトのままにします。
- tasks.max:データ収集ジョブを並行して処理するために生成するタスク数です。これらのタスクは、各 Splunk Kafka コネクターノードに均等に分散されます。
- topics:Splunk が受信する Kafka トピックのカンマ区切りのリストです。
- splunk.hec.uri:Splunk HEC の URI です。すべての Splunk インデクサー、またはロードバランサーの、FQDN または IP をカンマ区切りで指定します。インデクサーを使用する場合は、コネクターによってラウンドロビン方式で各インデクサーに負荷が分散されます。
- splunk.hec.token:Splunk HTTP イベントコレクターのトークンです。
- splunk.hec.ack.enabled:true または false を指定します。true に設定すると、Splunk Kafka コネクターによって、Kafka オフセットのチェックポイント設定前に POST イベントに対して ACK がポーリングされます。これによって配信が保証されるため、データ喪失を防ぐことができます。
- splunk.hec.raw:Splunk ソフトウェアでのデータの取り込みに /raw HEC エンドポイントを使用する場合は true に設定し、/event エンドポイントを使用する場合は false に設定します。
- splunk.hec.json.event.enrichment:/event HEC エンドポイントを使用する場合にのみ設定します。この設定を使って、raw データにメタデータフィールドを追加できます。キーと値のペアをカンマ区切りで指定します。追加したメタデータは、Splunk ソフトウェアで raw イベントデータとともにインデックス化されます。注:この /event HEC エンドポイントのデータ補強機能は、Splunk Enterprise 6.5 以降でのみ使用できます。
- splunk.hec.track.data:true または false を指定します。true に設定すると、データ喪失とデータ挿入の遅延が raw データとともにインデックス化されます。
おめでとうございます!これで、デプロイが完了し、Splunk でイベントを検索できるようになりました。
フィードバックと質問
Splunk Connect for Kafka に関するご意見・ご感想をお待ちしています。フィードバックやご質問がございましたら、遠慮なくお知らせください。GitHub で、問題の報告やプルリクエストを受け付けています。コミュニティへの積極的なご参加も大歓迎です。
