Vous avez plusieurs sources de données AWS dans le même bucket S3 mais vous avez des difficultés à obtenir des notifications SNS efficaces basées sur des préfixes à caractère générique ? Rassurez-vous, nous avons la solution.
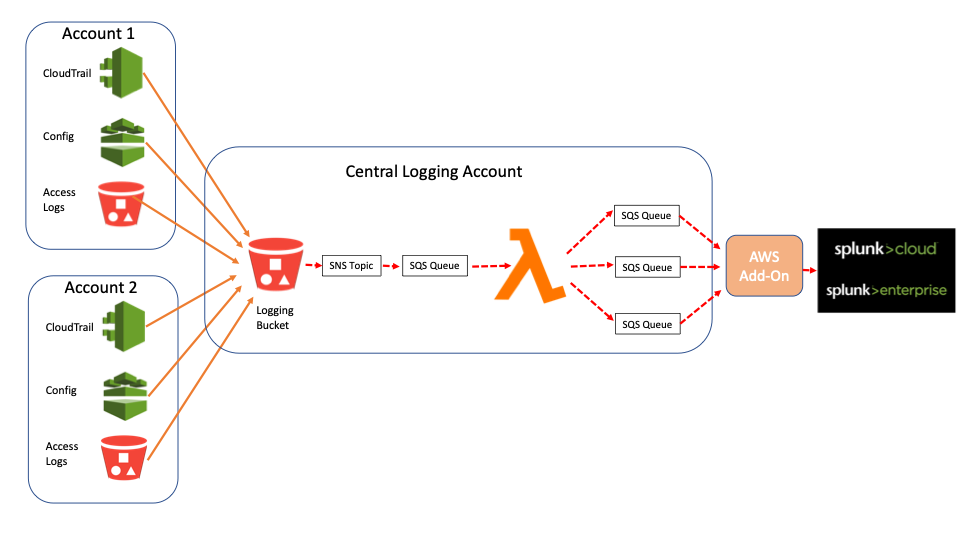
Beaucoup de nos clients utilisent un bucket S3 centralisé pour collecter les logs de multiples sources et comptes. Tous les logs Config, CloudTrail et Access Log d’une entreprise peuvent ainsi être acheminés vers un même bucket central. Le préfixe clé de ces objets de log permet généralement de naviguer simplement parmi les comptes et les types de logs : les clés d'objet, par exemple, présentent généralement le format :
Bucket/AWSLogs/numéro de compte/type de log/région/année/mois/jour/log
Pour importer ces logs dans Splunk, une bonne pratique consiste à utiliser l’Extension Splunk pour Amazon Web Services avec l’entrée « SQS Based S3 ». Cette entrée utilise essentiellement une notification SNS sur le bucket et des messages SQS utilisés par l’extension pour identifier les nouveaux fichiers du bucket qui sont ensuite lus dans Splunk.
Bien que cette solution soit hautement évolutive, cette méthode de journalisation présente un problème lorsqu’on dépose plus d’une source de logs dans un bucket, comme CloudTrail et Config. En effet, les notifications SNS ne peuvent être déclenchées qu’en utilisant un caractère générique à la fin du préfixe, par exemple /bucket/compte/*. Lorsqu’on utilise un bucket de journalisation centralisé, il n’est pas possible d’obtenir une notification distincte pour les CloudTrails, car il faudrait la définir comme bucket/AWSLogs/*/CloudTrail/*, ce qui n’est pas une formulation valide.
On peut bien sûr contourner ce problème en créant plusieurs rubriques de notification, les files SQS correspondantes et une entrée d’extension pour chaque compte, mais cela peut, à terme, s'avérer complexe et difficile à gérer et à maintenir. Imaginons par exemple qu’il y ait 100 comptes ayant chacun 3 types de log, ce qui devrait produire 300 rubriques SNS, 300 files SQS (chacune s'accompagnant d’une file de lettres mortes) et 300 entrées d’extension.
Il existe toutefois une approche bien plus simple qui exploite les fonctions Lambda. Au lieu d'avoir des notifications SNS distinctes pour chaque compte, une seule rubrique SNS, couvrant le bucket complet, pourrait déclencher une fonction Lambda via une file SQS, qui à son tour « acheminerait » la notification vers d'autres files SQS en fonction de la source de log, files qui seraient ensuite liées à une entrée d’extension du « sourcetype » correct. Avec une telle approche, un bucket peut avoir plusieurs comptes et sourcetypes sans qu'il faille mettre en place une grande quantité de rubriques SNS, files SQS et entrées d’extension. En reprenant l’exemple des 100 comptes et des 3 logs, il suffirait d’une seule rubrique SNS et de 4 files SQS seulement (chaque file étant accompagnée d’une file de lettres mortes).
(Vous pouvez également passer directement de SNS à une fonction Lambda, ce qui évite 1 file SQS de plus, mais en cas de défaillance de la fonction, vous n’auriez plus aucun moyen de récupérer la notification SNS alors que la file contiendrait encore la notification.)
Vous trouverez des instructions détaillées sur la mise en place de cette approche ici sur Github, ainsi qu’un exemple de fonction Lambda.
Cette fonction prévoit un scénario d’utilisation dans lequel trois sources différentes peuvent être disponibles dans un bucket S3. Elle utilise des variables d’environnement pour définir le nom des files de chaque source différentes ainsi qu'une file par défaut pour tout autre objet qui pourrait s’y trouver. La fonction peut également prendre une variable d’environnement de liste d’exclusion afin d’ignorer certains objets pouvant également se retrouver copiés dans le bucket sans qu’il faille les envoyer dans Splunk.
On peut ajouter d'autres scénarios d’utilisation à la fonction, comme l’envoi vers différentes files en fonction du numéro de compte. Cela permettrait d’envoyer les logs provenant de certains groupes de comptes vers des index Splunk différents à des fins de sécurité ou de conservation.
Bon Splunking !
*Cet article est une traduction de celui initialement publié sur le blog Splunk anglais.
