How To Investigate a Reported Problem
Observability Deepti BhutaniGetting to the root cause of a problem in cloud-native environments requires engineers to navigate through immense complexity within a distributed system. Oftentimes, you didn’t write the code and you lack the background and context to quickly understand what’s going on when a problem occurs. The stakes are even higher when a problem is reported - meaning it’s already started to impact the business and the executives and your customers are not pleased.
In the previous posts, we covered how to visualize your services and add global tags to speed up troubleshooting. In this post, we’ll bring all the pieces together and walk you through how Splunk Observability Cloud can help you proactively detect and prioritize incidents that impact the business for faster triage and reduced repair times.
An Alert to Start The Troubleshooting Workflow
Let’s pretend you are an SRE for an e-commerce platform. Your business is seasonal, and, since it’s the end of year, you know you are going to get an influx of traffic from holiday shoppers. You’ve prepared for this increase in traffic but, unfortunately, you get notified that there is a slowness with the checkout service. This could be bad for business. It could cause the business to lose customers to a competitor and lose revenue, and it could also damage your reputation.

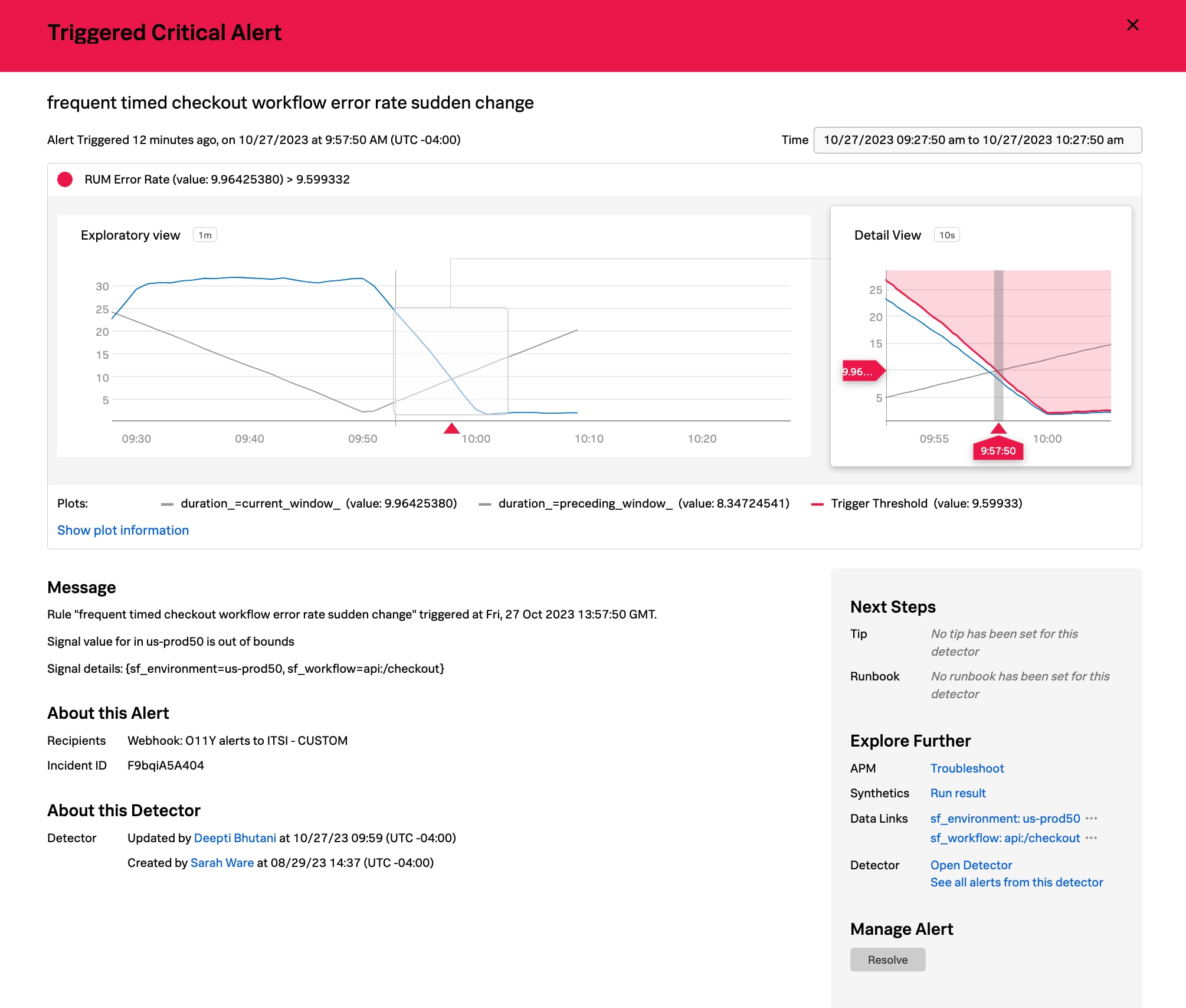{kind=link}
With Splunk Observability Cloud’s real-time alerts, you would be alerted to this issue in a matter of seconds so that you could start repairing the issue. You’d see in the alert window that there is already a ton of context on what is happening with the issue, making it easier to start investigating. As a next step, you select Troubleshoot to navigate to Splunk Application Performance Monitoring’s dynamic service map view.

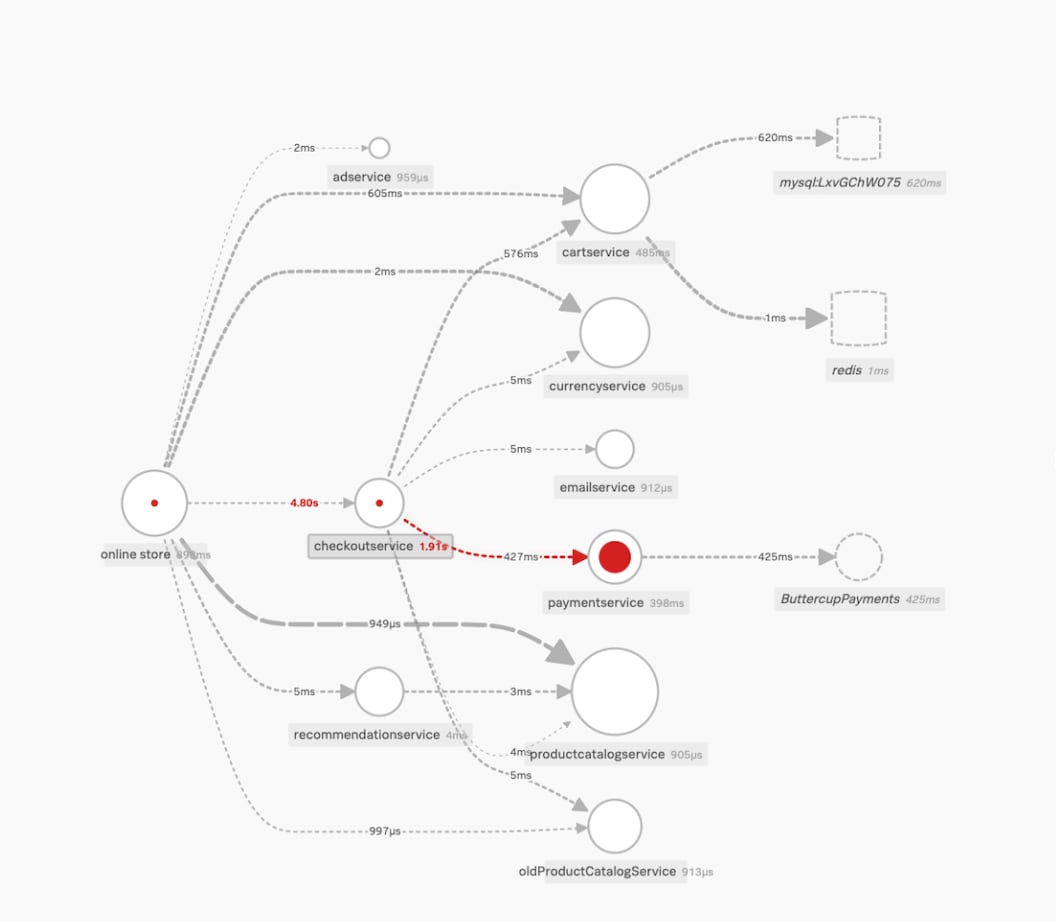{kind=link}
Even if you are moving your monolithic product catalog service into microservices, this view helps to easily spot a call being made from the online store to the old catalog service. The service map makes it very easy to share data across teams because it’s a color-coded common data view, unlike individual metrics dashboards. Additionally, because Splunk APM’s service map is powered by full-fidelity traces, you have the ability to pinpoint issues across the entire transaction at scale. You can easily share the details about the problematic downstream service for checkout with the developer, narrowing your view and shortening the time spent in war rooms.
Business Context to Aid Prioritization
The service map also stitches in Business Workflows, so you could take a closer look at the ‘API checkout’ business workflow you were alerted to for even more insight. You can configure Business Workflow rules to group logically related traces by services or global tags. From the service map, you could select Overview to navigate to the APM page. There you’d be able to see business workflows filtered for active alerts. You’d see here that the cart service has been marked as a critical in this view as well.

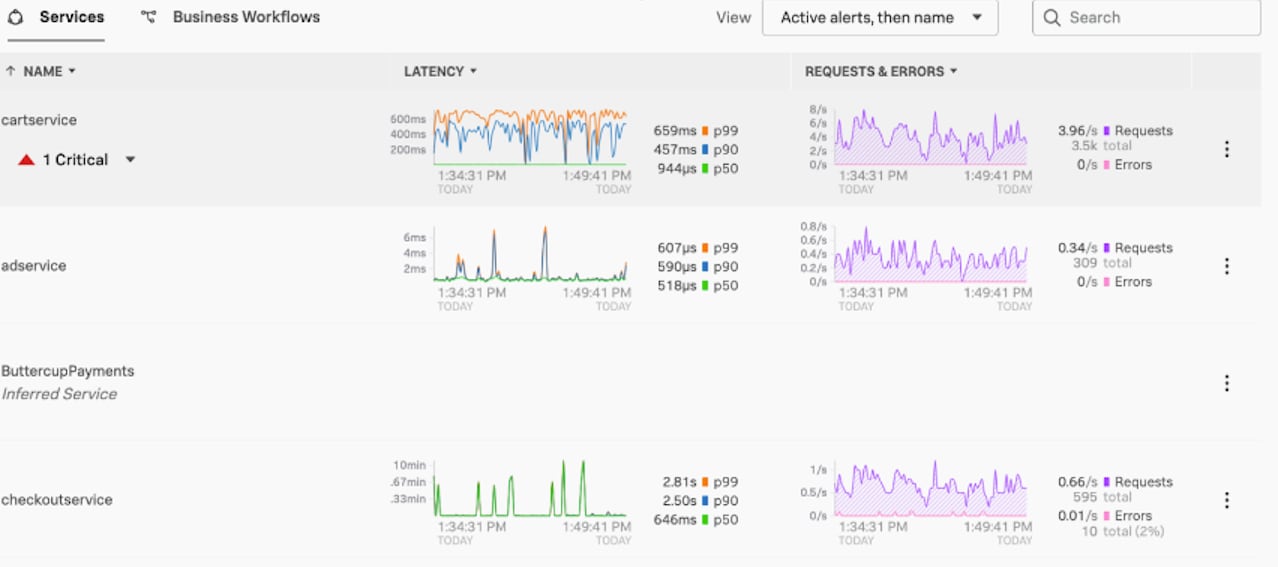{kind=link}
Clicking on this critical alert from this screen would take you back to the service map where you could continue the investigation.
Red Marks the Spot

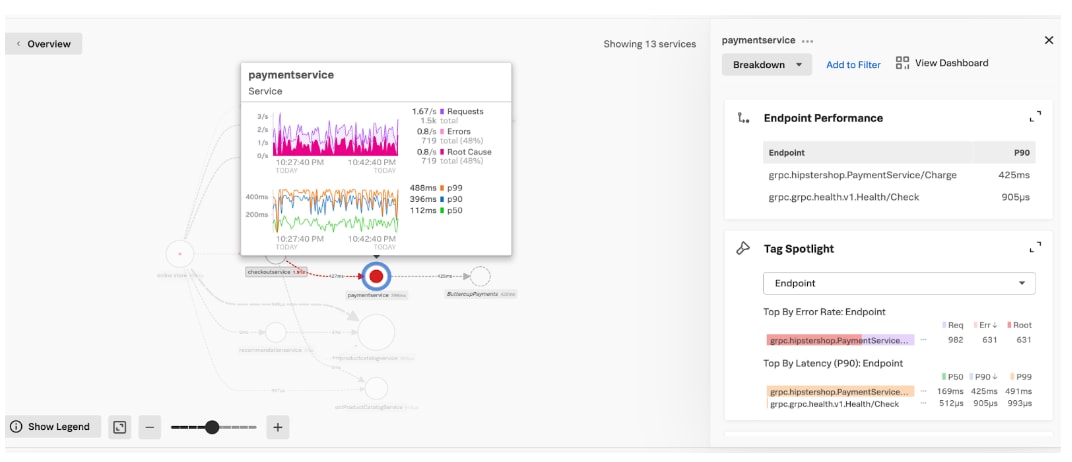{kind=link}
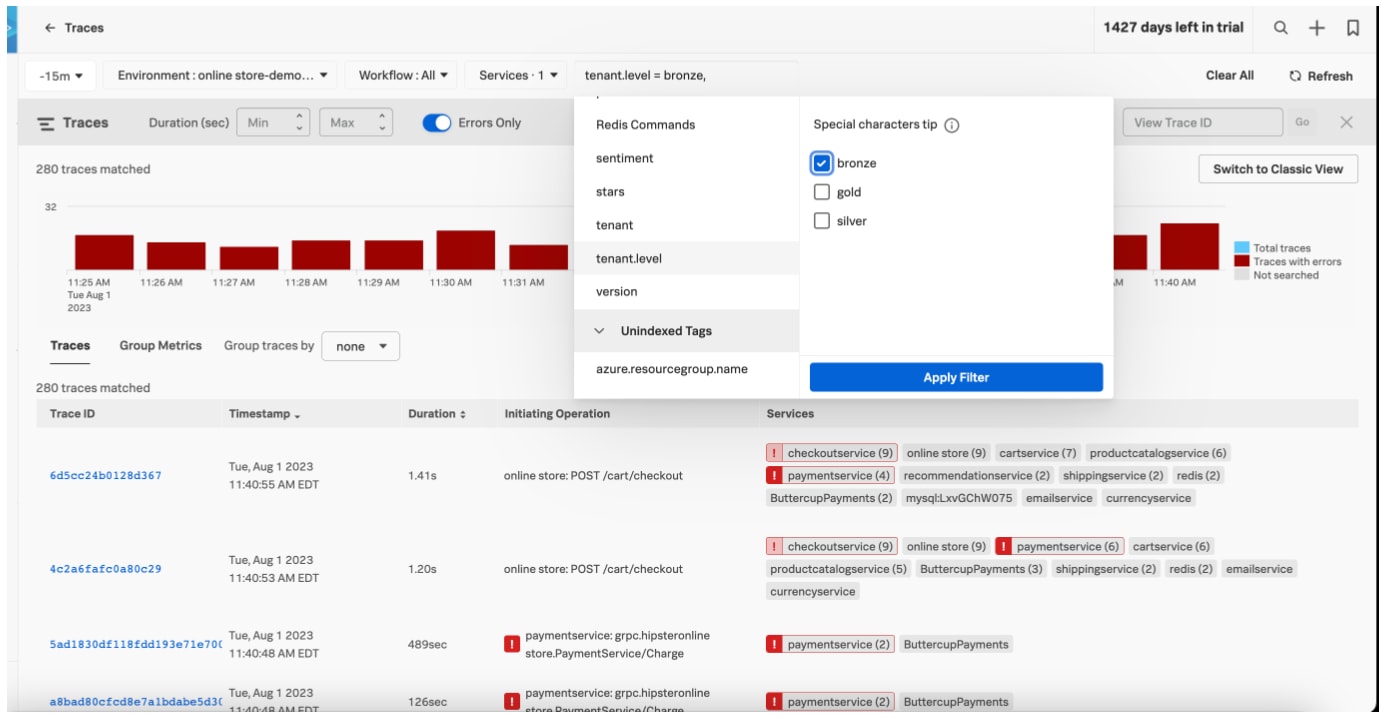
You’d immediately notice the conspicuous solid red dot on the payment service in the service map, since Splunk APM has root cause color coding. This is where you want to investigate! In order to further triage this issue, you’d click on the payment service. When you click on the payment service, you can see all the RED metrics for that service, and you can explore it further by selecting Tag Spotlight. For every service, Tag Spotlight provides request, error, and duration (RED) metrics time-series charts for every value of each indexed span tag within the specified time range in the navigation menu. Here, narrowed into the payment service, you’d be able to see that the number of requests and errors is high; clearly indicating that there is an issue that needs to be addressed right away.
Another powerful feature of Splunk Observability Cloud is that it highlights root cause errors. To get to root cause, you’d select Traces so you can further explore the trace for the payment service. Here, you’d be able to see all the traces associated with the workflow. Luckily, with Splunk, it’s super easy to isolate an application issue without having to recreate the issue in an alternate environment. And thanks to no sampling, all the traces are retained.

{kind=link}
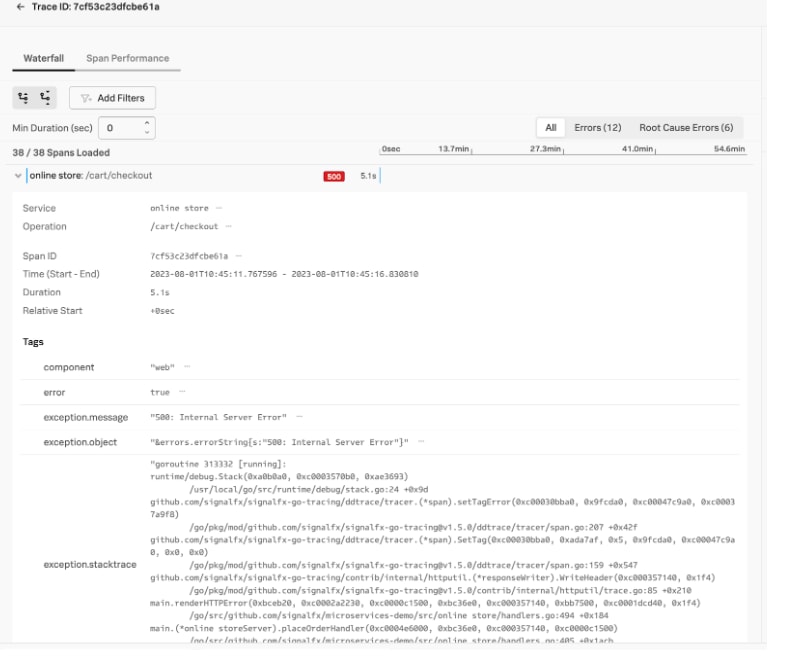
By selecting the trace with the longest duration, you’d notice that there are 12 errors tied to six root cause errors. This further helps you with the isolation of the root cause, which is critical when debugging microservices. Splunk’s intuitive color coding used in the service map is carried over in Tag Spotlight. Here the request and error graph differentiates root cause errors from total errors with a darker red color to further direct triage.

{kind=link}
Eureka! You find the needle in the haystack! With these details, you identify that the root cause of the issue is an invalid request. You share the trace details with the developer who can also take a look at the logs in context for this service for further root cause analysis. Your job is done!
Conquer Troubleshooting in a Complex Environment
Thanks for sticking with us to learn how Splunk Observability Cloud makes it easy for you to quickly find what’s broken in case of failure in complex, cloud-native environments. You’ve explored how to visualize your services, add global tags to speed up troubleshooting and investigate a reported problem to find the root cause.
Splunk brings teams and data together to help you isolate problems across any environment and spend less time in war rooms, even as you scale. Explore our product documentation for a closer look at some of the features we covered and get started with a trial today!