Defending at Machine-Speed: Accelerated Threat Hunting with Open Weight LLM Models
Artificial intelligence is accelerating the pace of cyber operations through the improved convenience, scale, and automation of tasks. To keep parity with efficiencies attackers will gain, defenders must employ AI to equal effect. The core of this challenge in a Security Operations Center (SOC) is applying human analysts to the tasks where their attention is most needed. With their ability to quickly and accurately process and interpret human language, Large Language Models (LLMs) are well-suited to address some of these topics, and reduce the overall cognitive burden of analysts when applied strategically. By identifying high-value use cases and engineering effective solutions, we can streamline defensive operations to keep pace with the accelerating threat landscape.
With Splunk DSDL 5.2, the engineering task is now much easier. We can test and deploy locally-hosted LLMs alongside Splunk to directly support inference on our data, without the security or privacy concerns of internal data leaving the network boundary. To identify a high-value use case, we want to determine the bottlenecks that currently require in-depth analyst attention.
With the rise of living-off-the-land attack techniques, attackers perform actions using tools that are allowed, and already present, inside the environment. PowerShell, for example, is often as legitimately useful for administrators as it is for ill-intentioned attackers, and its use requires an analyst to investigate context before making a final determination on the nature of the code’s intent. This challenge also aligns well with one of the strengths of LLMs derived from understanding human language – code interpretability. By deploying multiple local LLMs alongside a Splunk environment, we will test their ability to classify the intent of PowerShell scripts. We can use this as a pre-screening step by applying a prediction label of ‘malicious’ or ‘benign’ on each event. By injecting a language model into later stages of a threat hunting workflow, we can reduce the initial classification time of an event by up to 99%[1]!
The Setup
The first step in evaluating the feasibility of this idea is to assess the out-of-the-box ability of Language Models to accurately classify the intention of PowerShell scripts. After installing DSDL 5.2, we created a deduplicated, labeled dataset with balanced classes, compiled from samples of prior research. We used a constant seed value to create a reproducible, pseudo-random sample from the dataset, to ensure a comparable evaluation of each model.
To get a baseline we tested three medium-sized, open-weight models (Llama3-8B, Gemma-7B, Mistral-7B), with the prompt: “You are a cybersecurity expert. Classify the intent of the PowerShell script. Choose from 'malicious' or 'benign'. Output only the category name in your answer.” This can be done via the LLM-RAG Assistant dashboards, or directly in SPL using the fit command.
To classify a large sample, you may need to increase the number of seconds for the fit algorithm in MLTK, by increasing the value of the max_fit_time setting.
The Result
On an identical random sample of 2,000 PowerShell Scripts (1k malicious / 1k benign), these off-the-shelf models performed quite well. High precision (few false positives), very high recall (very rare false negatives), and an average response time of <2 seconds per event are all promising metrics for implementing a local-model as an assistant to pre-classify interesting PowerShell events for our analysts.
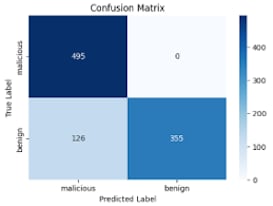
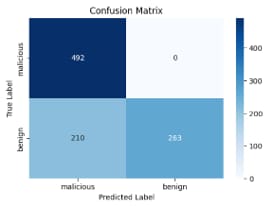
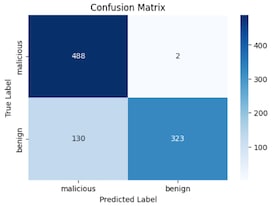
*This percentage represents dropped samples that could not be definitively labeled based on the output
Key Findings
- Off-the-shelf models demonstrated high accuracy with no fine-tuning required. In addition, the low recall gives confidence that we can employ the LM in a filtering scenario close to no false negatives.
- Local LMs cannot explicitly handle base-64 encoding. In rare cases, if the encoded string corresponds to common words or characters in the model’s vocabulary, or there is other context surrounding the encoding, it may still be able to infer a classification. Typically however, this is a limitation for local models – online models rely on calling external tools to first decode the base64, before interpreting the script.
- Time-to-classify was typically between .75 and 3 seconds – if the model follows directions. This is much faster than human analysis, but would take more work to scale to the high volume of the number of events in large enterprises. Some prior filtering is needed for best results, which suits a threat hunting workflow.
- Models are non-deterministic, i.e., there is randomness underlying each of the model’s responses. While they will very often follow directions, over a large sample, they will sometimes not, and your logic for the next step of processing should take this into account. For example, models would often classify an event as ‘malicious’, but then continue with an explanation of why, preventing simple filtering on the string “LLM_result = malicious”. Events that could not be clearly simplified into a specific class were dropped at the percentage represented in the ‘Unclassified’ column of the table above. This issue can be resolved by using structured data extraction which will enforce a labeling schema, and if needed, automatically re-prompt the model for clarification.
- Alternative machine-learning based classification methods have demonstrated higher accuracy in research scenarios [1][2] , but these methods often require manual feature engineering or pre-processing of samples prior to classification. Additionally, LLMs can offer benefits in terms of explainability of classification decisions, low maintenance, ease-of-deployment, and flexibility of model choice. It is also reasonable to expect that these models will continue to improve over time.
Model-in-the-Loop Hunting
To demonstrate the model-in-the-loop concept, we will create a set of ‘grey-area’ results that would require threat hunting, i.e., PowerShell activity that requires human-in-the-loop interpretation. We accelerate the threat hunting process by tagging events via LLM classification prior to analyst review. High model accuracy gives us confidence to expect limited false positives, and near-perfect recall leads us to expect few, to no, false-negatives.
To start we will adapt a PowerShell 4104 Hunting query from Splunk’s Threat Research Team, modifying the end of the query to select the field we want to submit for inference, and including the model prompt right in our SPL!:
index="powershell_class"
| eval DoIt = if(match(Content,"(?i)(\$doit)"), "4", 0)
| eval enccom=if(match(Content,"[A-Za-z0-9+\/]{44,}([A-Za-z0-9+\/]{4}
|[A-Za-z0-9+\/]{3}=
|[A-Za-z0-9+\/]{2}==)") OR match(Content, "(?i)[-]e(nc*o*d*e*d*c*o*m*m*a*n*d*)*\s+[^-]"),4,0)
…| stats sum(Score) AS hunt_total by Filename, DoIt, enccom, compressed, downgrade, iex, mimikatz, rundll32, empire, webclient, syswow64, httplocal, reflection, invokewmi, invokecmd, base64, get, suspcmdlet, suspkeywrd, Content
| search hunt_total > 10
| sort -hunt_total
| rename Content as text
| fit MLTKContainer algo=ollama_text_processing model="llama3" prompt="You are a cybersecurity expert. Classify the intent of the PowerShell script. Choose from 'malicious' or 'benign'. Only output the category name in your answer." text into app:ollama_text_processing as LLM| table Filename, hunt_total, text, LLM_Duration, LLM_Result
The result of this extra processing inserts a field into each event called LLM_Result, with a classification prediction label, derived from the model’s interpretation of the PowerShell code:

To put this into context, imagine you have 1,000 unique powershell execution alerts in your review queue. For an advanced, well-caffeinated analyst, this would take 83 hours to review at a pace of 5 minutes per alert with no breaks! With a model-in-the-loop, we could pre-screen this data and label every event (averaging 2 seconds per event), prior to analyst review – in 33 minutes!
Final Thoughts
The potential here is transformative. Not light speed, but 250x faster than a human analyst! By offloading the dense, detail-oriented, human language interpretation of code analysis to a fast model that never gets tired or mis-reads a line – threat hunting with a model-in-the-loop will improve accuracy, increase speed, and dramatically reduce the analyst’s workload.
Happy Hunting!
As always, security at Splunk is a team effort. Credit to authors and collaborators: Huaibo Zhao, Philipp Drieger
[1] Assuming a conservative average analysis time of 8 minutes/alert, improving to an initial LLM classification at <3 seconds.
Related Articles

Predicting Cyber Fraud Through Real-World Events: Insights from Domain Registration Trends

When Your Fraud Detection Tool Doubles as a Wellness Check: The Unexpected Intersection of Security and HR

Splunk Security Content for Threat Detection & Response: November Recap

Security Staff Picks To Read This Month, Handpicked by Splunk Experts

Behind the Walls: Techniques and Tactics in Castle RAT Client Malware

AI for Humans: A Beginner’s Field Guide

Splunk Security Content for Threat Detection & Response: November 2025 Update

Operation Defend the North: What High-Pressure Cyber Exercises Teach Us About Resilience and How OneCisco Elevates It
