The Network Is Talking, Nobody Is Listening
Observability Mahamudul ChowdhuryKey takeaways
- Modern networks generate massive amounts of data, but outages drag on for hours because each team only sees their own slice—no one has a unified view across all domains.
- Splunk ITSI solves this by combining telemetry from all infrastructure layers into a single service health score, turning thousands of raw alerts into one actionable incident with a clear root cause.
- This unified approach shifts teams from reactive firefighting to proactive problem detection, catching issues before users notice—and cutting resolution time from over an hour to minutes.
Let me paint you a picture. It's 11pm. A critical application is down. The on-call engineer opens a bridge call, and within twenty minutes there are six teams on the line—networking, data center, security, virtualization SREs, cloud, application. Everyone has their own tool open. Everyone checks their own slice of the infrastructure. And everyone—every single team—comes back with the same answer.
Not us.
Here's the thing: they're not wrong. The firewall team looks at their platform and traffic looks fine. The data center team checks ACI and the fabric health is green. The WAN team sees BGP sessions up. Nobody is lying. The problem is that each team is accurately describing one piece of a puzzle that only makes sense when you see all the pieces together. And nobody has that view.
So the bridge call drags on for an hour. The root cause—a single Cisco ACI bridge domain that was withdrawn, pulling a subnet out of BGP, making a web server unreachable—was sitting in the telemetry the whole time. Completely invisible. Not because the data didn't exist. Because nobody had built the right way to see it.
That's not a technology problem. That's an operational model problem. And it's costing enterprises real money, real sleep, and real credibility every single week.
More Data, Less Clarity—Welcome to Modern Networking
Here's what's genuinely wild about this situation. Networks today generate more telemetry than ever. Cisco NCS 5500 routers push sub-second metrics across every protocol and forwarding layer. Catalyst Center runs AI-driven issue detection on campus infrastructure. SD-WAN makes path selection decisions faster than a human can blink. Thousand Eyes watches your network from the outside, constantly testing whether real users can actually reach your services.
All of that intelligence. All of that data. And operations teams are still running war rooms.
To be honest, the technology isn't the bottleneck anymore. The bottleneck is correlation. Every monitoring platform does its domain well. None of them talk to each other. When an outage crosses domain boundaries—and most significant ones do—you're not just debugging a network. You're debugging a communication breakdown between teams. The fix isn't more tools. It's a platform that sits above all of them and surfaces the answer before the bridge call needs to happen.
What 'Fixed' Actually Looks Like
I didn't start with a grand strategy here. I kept running into the same problem in the field—teams with great tools, no shared view. So I started building out what it would look like to flip the troubleshooting sequence—starting at the service instead of the device—and when I showed customers, the reaction told me the gap was real.
Splunk IT Service Intelligence (ITSI) gives you a composite health score for each service—a single number reflecting every infrastructure layer simultaneously. When it drops, the contributing KPIs tell you which domain is driving it. You drill from service to domain to device to root cause in order, not chaos. The ACI event and the Thousand Eyes failure share the same timestamp. In a unified platform, that correlation is a query. In a war room with six teams, it's a forty-five minute conversation.
But wait, this isn't just about outage response. The teams that run this model also catch problems earlier. Splunk's adaptive thresholding learns what normal looks like for your specific infrastructure and fires when the trajectory changes—not when a hard threshold finally cracks. That's the shift from reactive to proactive that every VP of Operations says they want but most monitoring setups never deliver.

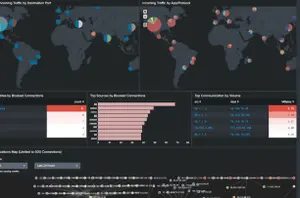
The ACME Service Health Command Center — ThousandEyes, BGP, Core, APIC, ESX, and Firewall all visible in one view. This is what the network looks like when nothing is hidden.
Six Domains, Six Ways the Network Can Surprise You
Networks are complex because they're built in layers and each layer has its own failure modes, its own telemetry, and its own way of silently messing with the layers above it. I've put together six deep-dive posts on Lantern that each tackle one domain. Think of this as the map.
01 · When Six Teams All Say 'Not Us' — End-to-End Service Visibility
The ACI bridge domain scenario I described above? That's this post. It walks through exactly how Splunk correlates telemetry from ACI, Thousand Eyes, Cisco Firepower, VMware ESX, and IOS-XR BGP into one service health view — and how ITSI turns 6,000 raw alerts into a single actionable incident. If you've ever sat on a bridge call where every team claimed innocence, this one's for you.
Read on Lantern → Troubleshooting cross-domain network problems in minutes
02 · The Wi-Fi Problem That Started With a Switch Port — Meraki Branch Networks
CRC errors on a single switch port at the Toronto hub. Silent frame corruption—not enough to bring the link down, just enough to cause TCP retransmissions and make everything feel slow. The wireless team checked the APs. Checked out fine. Nobody checked the switch. This post covers how Splunk gives you estate-level health scoring across hundreds of Meraki sites simultaneously, connecting physical-layer switching faults to wireless service degradation before the first help desk ticket is filed.
Read on Lantern → Operating Meraki branch networks at scale
03 · Your WAN Is Smarter Than Your Monitoring — Cisco SD-WAN
SD-WAN troubleshooting is harder than people expect. A site goes dark and the cause could be a BFD timeout, an OMP route withdrawal, or a physical interface failure—each with a different fix. vManage shows device alerts. Splunk shows service impact and root cause in a structured drill-down from health score to interface. This post also covers UTD security events and NetFlow analysis—what's actually crossing the WAN versus what your policy says should be.
Read on Lantern → Assuring enterprise WAN services with Splunk
04 · The Wired Problem Behind the Wireless Complaint — Campus Networks
Access layer interface errors cause AP uplink instability. AP instability causes wireless onboarding failures. Wireless onboarding failures generate help desk tickets about 'bad Wi-Fi.' Two teams, two tools, zero connection between them—until Splunk maps the wired fault to the wireless impact automatically. This post covers Catalyst Center integration and how ITSI's predictive episodes catch the degradation thirty minutes before users start complaining.
Read on Lantern → Creating cross-domain visibility in campus infrastructure
05 · What Five-Minute Polling Will Never Show You — SR-MPLS Backbone
A BGP session flaps and recovers in thirty seconds. Gone between SNMP polls. An IS-IS SPF storm causes a brief forwarding disruption. Never captured. A gray failure — packet loss with no link-down event — silently degrades service with no alarm. Cisco MDT streamed to Splunk at sub-second intervals catches all of it across eight protocol layers on NCS 5500 hardware. This post is for anyone who has ever closed a post-incident review with 'we couldn't reproduce it.'
Read on Lantern → Monitoring MPLS backbone infrastructure in real time
06 · The Migration Failures Nobody Warned You About — SRv6
Zombie SIDs. Silent ASIC limit exhaustion. Locator process restarts with no alarm. Real failure modes in SRv6-MPLS interworking environments—and completely invisible to traditional monitoring. The NCS 5500's 16,000-SID limit gets hit silently: no alert, traffic just drops. Splunk detects these through cross-layer telemetry correlation using Cisco-IOS-XR-segment-routing-srv6-oper. If you're planning an MPLS-to-SRv6 migration, read this before the network finds the failure modes for you.
Read on Lantern → Providing real-time assurance for MPLS-to-SRv6 transitions
📖 Dive deeper — the full technical series is on Lantern
Six posts. Six domains. Real KPIs, SPL queries, ingestion architecture, and YANG telemetry paths.
→ Troubleshooting cross-domain network problems in minutes
→ Operating Meraki branch networks at scale
→ Assuring enterprise WAN services with Splunk
→ Creating cross-domain visibility in campus infrastructure
→ Monitoring MPLS backbone infrastructure in real time
→ Providing real-time assurance for MPLS-to-SRv6 transitions
One More Thing Worth Saying
None of this replaces the tools your teams already use. Catalyst Center, vManage, the Meraki Dashboard—they're good at what they do. They stay. What Splunk adds is the operational layer above them: one timeline, one service health view, and the SPL to ask any question across all of it at once.
Operations VPs ask me how they measure the impact. Here's the honest answer: the first time your team resolves a multi-domain outage in twelve minutes instead of an hour and fifteen—and can show, in a single dashboard, exactly which domain caused it, when it started, and which six other domains were confirmed clean—that's when the value becomes obvious. Not a metric. A moment.
The network has been trying to tell you what's wrong for years. The question is whether your monitoring platform is actually listening.
Related Articles

Active Directory Lateral Movement Detection: Threat Research Release, November 2021

Imposters at the Gate: Spotting Remote Employment Fraud Before It Crosses the Wire