Service Resilience - What Is It And Why Is It Needed?
Service resilience has become one of the most important topics today in the world of observability and for good reason; businesses need their services to be up and working, performant and fixed quickly, ideally through automatic remediation, when there is an issue. Adding into this is the wonders of artificial intelligence and machine learning, which can drive some amazing advancements in this world. But, peeling back the covers, there are a number of key challenges in achieving service resilience. This five minute read quickly goes into the ‘why’ resilience is important for observability today, the various definitions and misconceptions surrounding it, the challenges and outlines a key methodology in delivering service resilience in your organisation.
What Is Service Resilience?
Before we dig into the details, let’s understand what service resilience is and for that let’s define the word resilience. The dictionary defines the term resilience as “the capacity to withstand or to recover quickly from difficulties; toughness” and this is exactly what is needed when looking at your services within your business. They need to work, perform, meet users’ expectations, be available and for you to help them withstand and recover from difficulties, such as slowness, poor performance and bad customer experiences. Now let’s define a service and here is where there is confusion as the definition of a service is very different across the industry and with each vendor in this space. In fact, the definition of a service differs from business to business and can also be interpreted differently by teams, depending on where they sit within the organisation and their sphere of control and influence. It is safe to say that it is a term that offers up many different definitions! From our experience here at Splunk and working with our customers, a service is a functional pillar of the business, typically owned by a stakeholder and specialist team to deliver value to the organisation. The service can be low-level, such as compute or connectivity, which delivers foundational business capability, up to fulfilling strategic business outcomes, such as revenue generation, providing customer satisfaction and/or a business process.
What Are The Typical Challenges?
It is here, within the definition of the service, where we see some typical challenges as it is easy to define a service by starting with the existing silo monitoring that is in place and then leveraging the existing metrics to be the KPIs of that service. A typical view from an APM tool, for example, is to just look at the application, not the broader service or process that application is part of or name the API calls and logical processing elements within them a service. Adding to this is the difficulty in correlating this data together across the silo tooling which leads to relying on only a few subsets of technical related KPIs from them. The result? A failure to deliver a service resilience view as it lacks the necessary business focus and has multiple data gaps which makes any troubleshooting or impact analysis very hard to achieve.
Putting This Into Practice:
So, how do we combat this? Let’s walk through an example of service resilience for a large insurance company. From a technology perspective, they have a multitude of apps, some in the traditional three tier space and others that have been migrated over to cloud native tech. They offer their customers a range of services starting from a quote & buy engine, cross selling and tailored products, services and discounts through to claims processing and call center services. The customers they serve only care about the service they are receiving and have no interest or knowledge in the sheer complexities of the service and the technology, apps, processes and people that sit behind and power it. The business only cares about the output and in this case the number of quotes being fulfilled, claims being processed, products being cross sold etc. and not the underlying technology. With this in mind, and as an example, let’s look at a customised service resilience view for the claims process service of the insurer, provided by Splunk’s ITSI engine.

What Does This Service Resilience View Show?
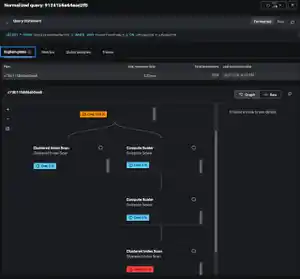
1. The customised view above maps out the complete claim process and highlights the key business KPIs that need to be measured so that both the business, as well as the technical teams, can see how the service is performing. The technical KPIs can also be integrated alongside the business ones, thus allowing tech teams to understand the impact of the technology they are supporting on the service that is being delivered. As this is customisable, you can have any KPI detailed on here.
2. KPIs that demonstrate the quality of the claims process service. In this example, these are focused on the key business process, steps and outcomes of the service, so that the quality of it can be quickly determined. For example, we can understand:
- Are we within the SLA? Are claims being processed successfully? Are any claims outstanding? Here we can define business level rather than just simply tech SLAs such as the expected number of claims processed per day compared to the norm or how many people have dropped out of the process. The key thing to remember here is that this can include the whole claims process including the notification and submission of a claim, the booking of the vehicle to be repaired, any rental cars to be arranged etc. Most service resilience views, however, are focused on app performance data, such as the performance of the online claims form, which is at the technical rather than the business process level. Therefore, this does not provide the complete service resilience view of the claims process.
- Are there errors in the process which is making their customers call the call center instead which is an additional cost to the business? If so, how many and is this inline with the SLA? We can also go further and calculate the additional cost to the business with customers having to call the call centre. More info could then be obtained as to why they are calling and this intelligence can then be used to improve the online experience. By allowing customers to complete these activities online rather than make the call, the business can reduce costs by reducing calls to the call centre and also improves the overall experience to their customers.
3. RAG status on the KPIs - we can also put a RAG status on the KPI numbers too, which provides quick visibility into whether the service or process is in a degraded state. Artificial intelligence and machine learning (AI/ML) is used to predict where that number will be in the near future and thus allowing teams to take preemptive action now.

4. Business specific data. As Splunk is a data platform, any data can be ingested, whether that is structured or unstructured, in different formats or stored in multiple locations and calculations can then be performed on this data to provide bespoke and correlated business KPIs. This enables you to ingest or create business specific data. The example below shows key business data for the claims process engine, each with a RAG status, so you can quickly see the state of this part of the process, the business impact of issues and identify any emerging trends.

5. Integrating and mapping the technology into the business process and KPIs. In a similar way to above, we can define the technical KPIs and use that visibility to understand its service performance, thus quickly identifying the root cause of issues and getting the problem to the right team. This is where you can also use existing siloed monitoring that might be deployed as well as highlighting monitoring gaps that need to be filled. The key here is the ability to ingest this data and provide unique correlations and insights across existing multiple tooling.
How Did We Get To The Service Resilience View Above?
Service resilience doesn’t have to be hard and here at Splunk, we follow this simple four step methodology. The key is that we start at the top level, with the business services, processes and internal and external customers in mind rather than starting at the tech and existing monitoring tool level.
- Identify the service or the business process that you need to have visibility on. We need to move away from the typical starting point of using isolated monitoring solutions to build a service view and instead look at what needs to be measured by the business. This could be a process that is delivered to your customers, a business process (and can be from start to finish, like a payment provider, for example), a customer journey that crosses multiple apps and systems or even tech services such as the network, cloud hosting services, the database engine or the engine that provides specific capabilities.
- Identify the key performance indicators - KPIs - that will be used to determine the quality of the service or business process. These should not be focused on what is already collected, at a technical level by silo monitoring tools but instead these KPIs should reflect the business service or process. The Splunk platform can process and perform calculations on any ingested data, thus allowing you to create customised KPIs that are pertinent to your business and service.
- Map the service identified and the KPIs to the underlying technologies - this aids in rapid troubleshooting and enables the problem area to be quickly identified in the event of an issue.
- Determine where and how to get the relevant data that powers the above - as Splunk is a data platform, ingesting any type of data into Splunk, structured or unstructured, is super easy, regardless of where and how that data is stored and in what format. This data is then processed and calculations can be performed in order to create the data and visibility needed. From a technical perspective, existing monitoring tools can be utilised by ingesting and correlating any required data from them and thus maximising existing investments, but also laying the foundations for tool and cost consolidation exercises in the future.
Utilizing The Power Of Artificial Intelligence (AI) And Machine Learning (ML) In Service Resilience:
We can strengthen service resilience by utilising AI and ML within Splunk ITSI by:
- Using ML to look for outliners and detecting issues much earlier, thus enabling faster identification and fixing of issues.
- Prioritizing responses based on business context. This is a key focus of service resilience and ensures that the impact to the business and the business context become at the forefront of responses.
- Reducing alert fatigue through ML correlation and noise reduction.
- Utilising historical data and applying machine learning to predict problems before they occur and so that preemptive action can be taken to ensure the problem doesn’t happen at all.
Taking this approach and using Splunk’s ITSI platform, you can build customised service resilience views for your business. Check out the links below for some great further reading:
- Learn all about Splunk’s service resilience platform and ITSI
- Take a guided tour of Splunk’s ITSI
- Getting started with ITSI guide
My thanks to our local Splunk subject matter experts John Murdoch, Marc Serieys, Rachel Bourne and Jaana Nyfjord for their input to this blog.
Related Articles
What the North Pole Can Teach Us About Digital Resilience

The Next Step in your Metric Data Optimization Starts Now

How to Manage Planned Downtime the Right Way, with Synthetics

Smart Alerting for Reliable Synthetics: Tune for Signal, Not Noise

How To Choose the Best Synthetic Test Locations
Advanced Network Traffic Analysis with Splunk and Isovalent

Conquer Complexity, Accelerate Resolution with the AI Troubleshooting Agent in Splunk Observability Cloud

Instrument OpenTelemetry for Non-Kubernetes Environments in One Simple Step