
Lagebericht Observability 2025
Hier erfahrt ihr, warum Observability-Leader mit ihren Praktiken 53 % mehr ROI erzielen als ihre Mitbewerber.
Das Wichtigste im Überblick
Bei Observability geht es seit jeher darum, auch unter Druck den Durchblick zu behalten. Doch der Druck hat sich verändert.
Anwendungen sind stärker verteilt. Kubernetes-Umgebungen werden stetig erweitert. Digitale Erfahrungen hängen von Services, APIs, Netzwerken, Drittanbietern und jetzt auch von KI-Modellen und -Agenten ab, die schneller Entscheidungen treffen können als ein Mitarbeiterteam, das jedes Signal prüfen muss. Gleichzeitig sollen Operations-Teams noch immer Ausfallzeiten senken, die Kosten unter Kontrolle halten, das Kundenvertrauen sichern und die geschäftlichen Auswirkungen jedes Incidents erklären.
Daher brauchen wir für die nächste Observability-Generation mehr als nur ein weiteres Dashboard. Es bedarf einer Intelligenz, die Signale miteinander verknüpfen, den Service-Kontext verstehen und Teams dabei unterstützen kann, schneller zu handeln. Außerdem muss sie dafür sorgen, dass komplexe Systeme weniger bedrohlich erscheinen.
Bei der Cisco Live kündigen wir innovative Neuerungen von Splunk Observability an, die genau auf diesen Wandel ausgelegt sind: agentenbasierte Observability. Das Ziel ist leicht formuliert, schwieriger zu realisieren und absolut kritisch für moderne Operations-Teams. Es geht darum, Probleme mit KI-Agenten zu beheben und zu verhindern, den gesamten KI-Stack zu überwachen und jedes Signal mit realen geschäftlichen Auswirkungen zu verknüpfen.
Die Ankündigungen basieren auf Splunks Rolle als Intelligenzschicht für einen vertrauenswürdigen agentenbasierten Betrieb im gesamten Unternehmen. Einfach ausgedrückt: Der Ansatz wechselt von „Irgendetwas ist kaputt“ zu „Was ist passiert, warum ist es wichtig und was ist als Nächstes zu tun?“. Schnellere Triage. Besserer Kontext. Weniger Spekulation.
Splunk Observability hilft durch Innovationen in zwei zusammenhängenden Bereichen beim Schließen der entstandenen Lücke:
KI-gestützte Observability: Durch den Einsatz von AI SRE-Agenten und KI-gestützten Workflows beim Erkennen, Untersuchen, Zusammenfassen und Empfehlen von Maßnahmen können Probleme schneller gelöst werden.
Observability für KI: Monitoring von KI-Agenten, KI-Infrastruktur, Kubernetes-Inferenz-Workloads und kritischen KI-Umgebungen, damit die zuständigen Teams verstehen, wie KI-Systeme sich in der Produktionsumgebung verhalten.
Einheitliche Observability: Verknüpfen von Metriken, Events, Logs, Traces, Netzwerkerkenntnissen, Signalen der Anwendungssicherheit und Geschäftskontext, damit die Verantwortlichen die wirklich wichtigen Dinge sehen und souverän handeln können.
Denn eine zukunftsträchtige Observability-Lösung braucht nicht nur mehr Telemetriedaten. Sie braucht Telemetriedaten kombiniert mit Urteilsvermögen. Kontextinformationen und entsprechendes Handeln. Und eine KI, die den Übergang von der bloßen Reaktion zur Resilienz ermöglicht.
Hier kommen die Neuerungen bei Splunk Observability von der Cisco Live.
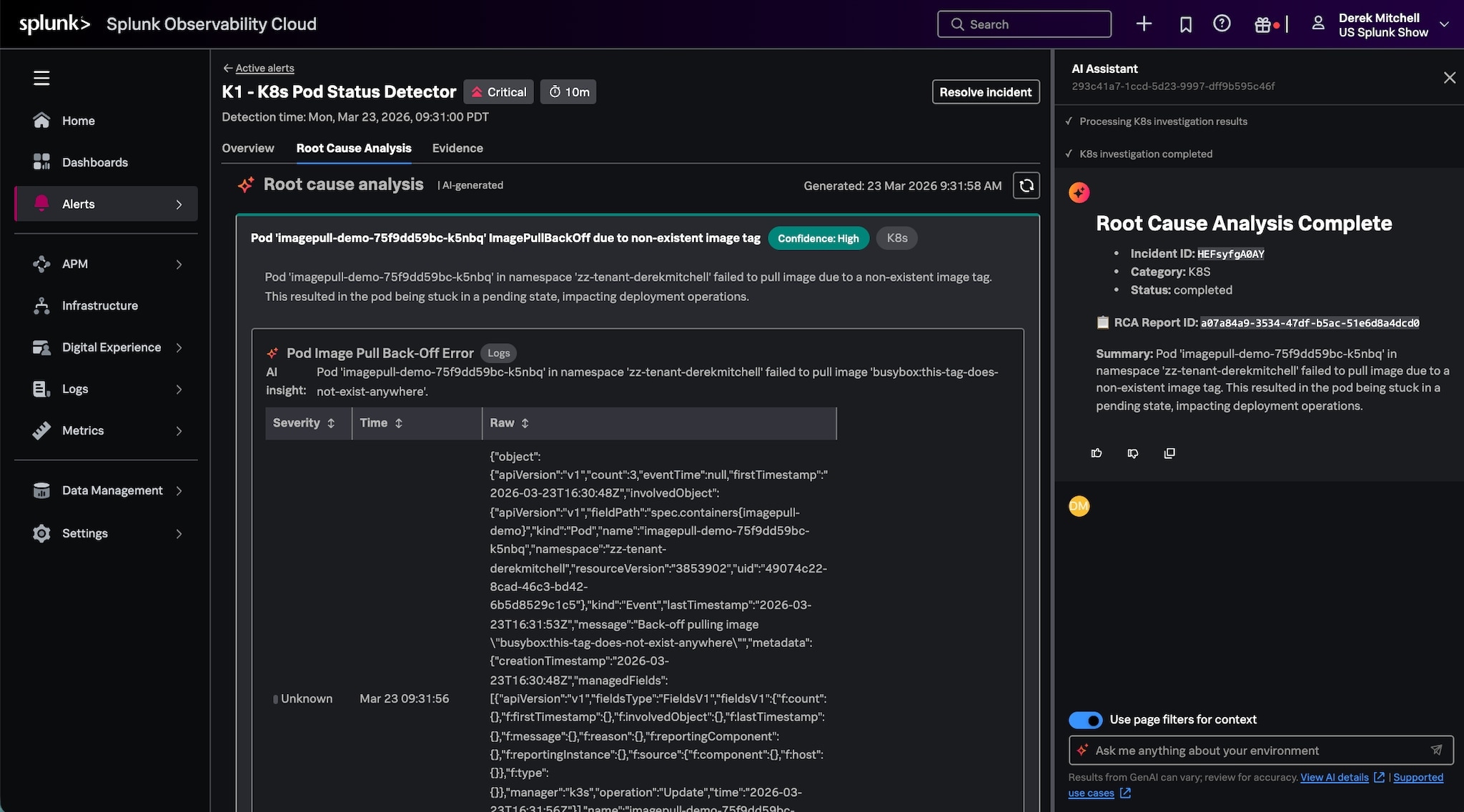
Der Trend zu generativer KI und großen Sprachmodellen (LLMs) hat den Observability-Ansatz grundlegend verändert. Wir warten nicht mehr, bis auf dem Dashboard das rote Licht angeht, sondern gehen von einem passiven Monitoring zu proaktiver, agentenbasierter Observability über. Wollt ihr wissen, wie AI SRE zu eurem neuen Arbeitskollegen wird, Probleme automatisch erkennt, wahrscheinliche Kernursachen ermittelt, einen Plan erstellt und euch eine schrittweise Anleitung für die Problembehebung liefert? Mehr dazu erfahrt ihr hier.

Kann euer Team beim Auftreten eines Incidents sofort mit der Untersuchung beginnen ober verbringt ihr die ersten Minuten mit dem Zusammentragen von Kontextinformationen? Mit Cisco AI Canvas in Splunk IT Service Intelligence kann eine ITSI-Episode direkt in AI Canvas geöffnet werden, und ihr seid sofort im Bilde. Services, wichtige Leistungsmetriken (KPIs), Entitäten, Warnmeldungen, ähnliche Episoden und verknüpfte Tickets werden automatisch eingebunden, ebenso wie auf den spezifischen Incident zugeschnittene Prompts. Kein hin und her kopieren mehr. Weniger Wechsel zwischen unterschiedlichen Tools. ITSI-Benutzer profitieren durch AI Canvas von einer schnelleren Incident-Untersuchung und Kernursachenanalyse. Für Teams, die mit AI Canvas befasst sind, bietet ITSI den Servicekontext, die Event-Korrelation und die geschäftlichen Auswirkungen, die sie brauchen, um aus der Warnmeldeflut die richtigen Maßnahmen abzuleiten.
Weitere Infos zur Integration von AI Canvas in ITSI und zu den jüngsten Innovationen in ITSI Version 5.0 findet ihr hier.

Event iQ Detect nutzt bereits Machine Learning, um die richtigen Felder für das Korrelieren von Warnmeldungen zu identifizieren. Jetzt kann es auch von euren Analysten lernen. Wenn Response-Teams eine Episode aufteilen, in der nicht zusammenhängende Warnmeldungen gruppiert waren, oder Episoden zusammenführen, die eigentlich ein einziger Incident hätten sein sollen, dann wird dieses Feedback direkt in der Episodenüberprüfung erfasst und beim Neutrainieren wieder in das Event iQ-Modell eingespeist. Mit der Zeit werden Warnmeldungen so ohne die übliche manuelle Anpassung immer präziser gruppiert. Administratoren behalten die Kontrolle durch Zeitpläne für das Neutrainieren, Genehmigungseinstellungen und Optionen für automatisches Training in der Richtlinienkonfiguration. Das Ergebnis wird in der Praxis direkt deutlich: klarere Episodentitel, bessere Korrelationszusammenfassungen, weniger Gruppierungsfehler und eine Ereigniskorrelation, die sich mit der Nutzung verbessert, selbst bei hohem Volumen.
Auf Benutzer-Feedback basierendes Lernen steht ab Juni 2026 im Rahmen der ITSI-Version 5.0 zur Verfügung. Weitere Infos zu den innovativen Neuerungen in ITSI Version 5.0 findet ihr hier.

Wie viele Klicks sind derzeit erforderlich, um einen Incident zu verstehen? Viele Teams müssen sich durch relevante Events, KPI-Trends, den Servicezustand und Details zu den Entitäten arbeiten, um sich ein klares Bild zu machen. Mit Event iQ Diagnose ändert sich das. Mithilfe eines großen Sprachmodells (LLM) wird eine Zusammenfassung einer ITSI-Episode in natürlicher Sprache erstellt, die eine Übersicht darüber gibt, was passiert ist, wann es begann, welche Ereignisse im Wesentlichen dazu beigetragen haben, welche Kernursache wahrscheinlich dahintersteckt und welche Schritte als nächstes empfohlen werden – alles in einer Ansicht.
Die Zusammenfassung wird auf der Registerkarte „Impact“ der Episodenüberprüfung angezeigt und kann mit Kollegen geteilt oder an Tools wie ServiceNow gesendet werden. Event iQ Detect gruppiert die Warnmeldungen. Event iQ Diagnose erklärt die Episode. Das beschleunigt die Incident-Sichtung für Level-1-Analysten, verbessert die Eskalation von Vorfällen mit hoher Priorität und gibt erfahrenen Engineering-Mitarbeitern mehr Zeit, sich auf die Lösung statt auf die Rekonstruktion des Problems zu konzentrieren.
Event iQ Diagnose steht ab Juni 2026 im Rahmen der ITSI-Version 5.0 zur Verfügung. Weitere Infos zu den innovativen Neuerungen in ITSI Version 5.0 findet ihr hier.

Cisco hat die Übernahme von Galileo abgeschlossen. Splunk Agent Observability nutzt die leistungsstarken, out-of-the-box verfügbaren Bewertungen, Echtzeit-Leitplanken und latenzarmen kostengünstigen Bewertungen von Galileo, um KI-Agenten während ihres gesamten Entwicklungslebenszyklus zu bewerten, zu beobachten und in Echtzeit zu schützen. Damit werden die bereits in Splunk Observability verfügbaren KI-Observability-Funktionen weiter optimiert, um Ungenauigkeiten zu minimieren, schädliche Ausgaben zu blockieren und die Kontrolle über die Kosten zu behalten. Lest den Blog, um mehr zu erfahren.

Splunk Observability Cloud – Free Edition bietet uneingeschränkten Zugriff auf Funktionen auf Unternehmensniveau – ganz ohne den Druck herkömmlicher 14-tägiger Testversionen oder Beschaffungszyklen. Splunk begrenzt die Schicht auf 15 Hosts, anstatt bestimmte Funktionen zu sperren, und ermöglicht Entwicklern, Startups und KI-Ingenieuren damit das Entwickeln tiefgehender Integrationen und sinnvoller Dashboards, die auch beim Skalieren ihrer Projekte konsistent bleiben. Letztendlich avanciert Observability durch dieses Modell von einem Luxusgut zu einem grundlegenden architektonischen Element, mit dem Benutzer von Beginn an fundierte Erkenntnisse ableiten können. Holt euch Splunk Observability Cloud kostenlos.

Die End-User-Experience ist ein kritischer und gleichzeitig fragiler Faktor, mit möglichen Schwachstellen am Frontend, Backend und in den Netzwerkschichten. Problematisch wird es, wenn Anwendungs- und Netzwerktelemetriedaten isoliert bleiben, da dies häufig eine längere MTTR und ineffiziente Schuldzuweisungen beim Troubleshooting nach sich zieht.
Wir stellen ThousandEyes Network Insights in Synthetic Monitoring vor, eine neue Integration zwischen Synthetic Monitoring in Splunk Observability Cloud und ThousandEyes, mit der ein übergreifendes Monitoring der User Experience in Anwendungs- und Netzwerkschichten möglich wird.
Dank dieser Integration können die zuständigen Teams Tests für Splunk (App-Schicht) und ThousandEyes (Netzwerkschicht) an einem zentralen Ort erstellen und verwalten und profitieren von einer umfassenden Transparenz von mehr als 1000 Cloud-Agenten in 271 Städten und 69 Ländern. So können sie schnell feststellen, ob Probleme von der Anwendungs- oder Netzwerkschicht verursacht werden, Drilldowns in die Anwendungstelemetriedaten vornehmen oder eine eingehende Netzwerkdiagnose in ThousandEyes durchführen, einschließlich DNS-Auflösung, BGP-Routing und Hop-by-Hop-Pfadanalyse, um Problemen schneller auf den Grund zu gehen.
Die Integration geht im Juli ins Alpha-Stadium. Die erste Alpha-Version unterstützt vor allem HTTP-Tests mit ThousandEyes, weitere Testtypen werden folgen. Hier könnt ihr euch registrieren.

KI sorgt dafür, dass Software schneller geschrieben wird, schafft aber auch mehr Sicherheitslücken und gibt Angreifern damit Gelegenheit, Schwachstellen im Code auszunutzen. Splunk Secure Application macht bestehende Observability-Tools sicherer. Mit Secure Application in Splunk Observability Cloud könnt ihr Bedrohungen auf Anwendungsebene und Schwachstellen auf der Basis von kritischem Geschäftskontext proaktiv priorisieren. Die Daten zu Bedrohungen während der Anwendungslaufzeit werden direkt in Splunk Enterprise Security eingebunden. Anwendungs- und Sicherheitsteams bekommen damit eine einheitliche Grundlage, die Warnmeldeflut wird eingedämmt und kritische Services werden ohne Ausbremsen von Innovationen sicherer.
Die Erkennung von Angriffen auf Anwendungen während der Laufzeit in Observability Cloud ist jetzt allgemein verfügbar. Mehr dazu erfahrt ihr im Blog Von Erkennungslücken zu aktiven Abwehrmaßnahmen: Mehr Sicherheit für Code im Mythos-Zeitalter.

Durch die direkte Integration von Log-basierter visueller Aufbereitung und Warnmeldungen in Splunk Observability Cloud können Unternehmen die operativen Reibungspunkte eliminieren, die durch fragmentierte Tools und schwerfällige Workflows mit einer Trennung von Logs, Metriken und Traces verursacht werden. Diese Funktionen bieten ein einheitliches Observability-Erlebnis, bei dem die zuständigen Teams auf einer einzigen abgestimmten Oberfläche Log-Daten visualisieren und suchbasierte Warnmeldungen verwalten können. Die Folge ist eine beträchtliche Reduzierung von Tool-Wildwuchs und Over-Alerting. Durch die Nutzung von vorhandener SPL-Expertise und KI-Unterstützung profitieren Kunden von einer umfassenderen Transparenz und schnelleren Reaktionszeiten bei Incidents (MTTD/MTTR). Dadruch können sie MELT-Daten effektiver korrelieren und gleichzeitig eine schlanke, hocheffiziente Betriebsumgebung aufrechterhalten.
Log-basierte visuelle Aufbereitung und Warnmeldungen in Splunk Observability Cloud sind allgemein verfügbar. Mehr dazu findet ihr hier in unseren Dokumenten.

Observability tritt in eine neue Phase ein. Sehen, was passiert ist, ist nur der Anfang. Die größeren Chancen liegen darin, schneller zu handeln, und zwar mit präziseren Kontextinformationen, gezielterer Anleitung und mehr Zuverlässigkeit in allen Schichten des digitalen Stacks.
Die jüngsten Innovationen in Splunk Observability bringen uns dieser Zukunft ein Stück näher: KI, die beim Erkennen, Untersuchen und Zusammenfassen unterstützt und Maßnahmen empfiehlt; Transparenz für KI-Agenten und Infrastruktur; einheitliche Erkenntnisse, die technische Signale mit geschäftlichen Auswirkungen in Zusammenhang bringen. Weniger Rauschen. Schnellere Antworten. Bessere digitale Erlebnisse.
Jetzt kostenlos testen oder eine Demo buchen, um euch ein Bild davon zu machen, wie ihr mit Splunk Observability schneller agieren, Fehler smarter beheben und noch rascher eine solide Grundlage für einen vertrauenswürdigen agentenbasierten Betrieb schaffen könnt.
Dieser Text wurde aus dem englischen übersetzt. Viele der hier beschriebenen Produkte und Funktionen befinden sich noch in unterschiedlichen Entwicklungsstadien und werden nur angeboten, sofern und sobald sie verfügbar sind. Der Zeitplan für die Bereitstellung dieser Produkte und Funktionen kann nach alleinigem Ermessen von Cisco geändert werden, und Cisco übernimmt keine Haftung für Verzögerungen bei der Bereitstellung oder die Nichtbereitstellung der in diesem Dokument genannten Produkte oder Funktionen.

Die führenden Unternehmen der Welt vertrauen auf Splunk, einem Unternehmen von Cisco, um ihre digitale Resilienz mit der einheitlichen Sicherheits- und Observability-Plattform, unterstützt durch branchenführende KI, kontinuierlich zu stärken.
Unsere Kunden setzen auf die preisgekrönten Sicherheits- und Observability-Lösungen von Splunk, um die Zuverlässigkeit ihrer komplexen digitalen Umgebungen zu sichern und zu optimieren – in jeder Größenordnung.

Die neuesten Artikel von Splunk, direkt im eigenen Posteingang.
© 2005 - 2026 Splunk LLC All rights reserved.
© 2005 - 2026 Splunk LLC All rights reserved.