Monitor the Health, Performance, and Security of Your AI Application Stack with AI Agent and AI Infrastructure Monitoring
At this year’s .conf25, we introduced an exciting new chapter in observability at Splunk — one that is unified, AI-powered, and agentic — to ensure ITOps and engineering teams are digitally resilient in the AI era. Defined by the large volume and complexity of AI and LLM (large language model) workloads into production, this AI era has led to rapid efficiencies across industries and functions, automated workflows, and “vibe coding.” While incredible, this growth has also led to the subsequent rise in app performance, compliance, behavioral, usage, and accuracy issues. The frequency and intensity of these issues are highly dependent on the strength and stability of their underlying infrastructure. That’s why we are introducing AI Infrastructure Monitoring (now generally available) and AI Agent Monitoring in Splunk Observability Cloud (coming soon in Alpha) and AI Agent Monitoring in AppDynamics (now generally available) to provide visibility and protection across your AI stack.
AI Infrastructure Monitoring
In the AI era, infrastructure has transformed. It no longer includes just cloud compute, hosted servers, and other traditional infrastructure components. To manage AI workloads and resource utilization, more layers and complexity is required and focusing mostly on maintenance isn't enough to compete in the market and keep up with customer demands.
Now more than ever, ITOps and engineering teams must quickly and cost-effectively detect and respond to performance threats, degradations, and inefficiencies in real-time across large language models (LLMs), vector databases, and AI frameworks and libraries, additional layers to the infrastructure stack. Having this deep visibility allows teams to build future-proof LLM and agentic apps while confidently knowing that their systems are reliable, secure, and scalable.

With AI Infrastructure Monitoring, teams can view data-dense dashboards and monitor their AI infrastructure components such as active and pending nodes, GPU/CPU usage and utilization, and resource allocation. With support for AWS Bedrock, Azure OpenAI, GCP VertexAI, LangChain, Nvidia GPU, Nvidia NIM, OpenAI, Ray, Weaviate, and many others AI components, teams can build, deploy, monitor, and govern AI systems to meet workload demands more efficiently. This helps customers scale and meet their compliance requirements throughout the model and incident management lifecycle. Therefore, when issues such as noisy neighbors, limiting errors, resource contention, or filed training jobs inevitably arise, teams can perform root cause determination, accurately troubleshoot, and alert on operational metrics.
With end-to-end visibility, teams can quickly find offending AI infrastructure components that impact stability, availability, and security, and correlate them with business health, usage trends, patterns, and outliers to help mitigate performance and reputational risks.
For example, your AI infrastructure may be based on Cisco AI PODs. Cisco AI PODs are pre-validated, full-stack data center infrastructure solutions designed to support the entire AI lifecycle, including training, fine-tuning, and inferencing workloads. They are built on validated architectural stacks and fabric designs, providing a referenceable, “off-the-shelf” blueprint for rapid deployment. The infrastructure includes Cisco UCS servers with the latest NVIDIA and AMD GPUs, Nexus 9000 Series switches for high-performance networking, and integrated software components such as Cisco Intersight for management and Red Hat OpenShift for container orchestration. Cisco AI PODs offermodular scalability from small edge deployments to large-scale data center clusters, enabling flexible, secure, and efficient AI operations. They also include extensions for observability and security.
Therefore, with Cisco AI Pods, you can leverage AI Infrastructure Monitoring to have unified, real-time visibility into critical AI Infrastructure components to maintain optimal AI workload efficiency, including, but not limited to, the health and performance of NVIDIA GPUs as well as containerized AI applications running on Red Hat OpenShift, power utilization, storage performance, network, and much more. With AI Infrastructure Monitoring, teams are empowered to detect anomalies swiftly, optimize resource usage, and maintain seamless AI operations with actionable insights and predictive analytics. By having reliable AI infrastructure, teams lay the foundation for delivering fast, high-quality application performance.
AI Agent Monitoring in Observability Cloud
In this new era, AI agents and apps are unlocking new levels of automation, productivity, and cost mitigation for organizations to compete across industries. However, unlike traditional applications of the past, the non-deterministic and generative behavior of LLMs can lead to outputs with frequent inaccuracies, biases, and fallacies. Deviating from its intended use, these issues can ultimately lead to decreased customer trust, poor end-user experiences, and increased costs.
To build and maintain highly performant LLM and agentic applications, deep, unified visibility is required to quickly pinpoint, understand, and resolve reliability, accuracy, quality, and security issues. With AI Agent Monitoring, ITOps and engineering teams will be able to proactively identify the performance, cost and behavior of their LLM powered Agentic applications, that impact user experience. AI Agent Monitoring is also built on industry standards—OpenTelemetry and Cisco AGNTCY—to provide AI monitoring without vendor lock-in.

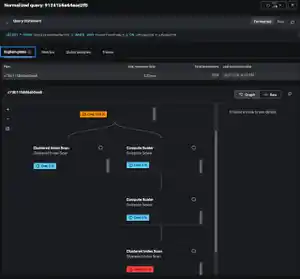
Teams can filter and search for transaction traces to identify and pinpoint when, where, how, and why performance, quality, or cost issues occur. These insights will help accelerate anomaly detection and troubleshooting.
By using out-of-the-box visualizations to track user interactions, teams will be able to get visibility into agentic workflows including tool calls and system prompts in context of users’ interactions with their agentic applications. This enables them to investigate LLM specific problems such as model drift and hallucinations, in addition to traditional performance issues such as errors and latency.


Finally, Cisco AI Defense will be integrated with AI Agent Monitoring so that teams can detect and mitigate AI risks such prompt injection, data leakage, harmful content. By connecting AI security risks to related infrastructure and services, teams can prevent breaches, ensure compliance, and maintain operational resilience.
AI Agent Monitoring in AppDynamics
AppDynamics now also offers LLM Monitoring, providing a single, unified interface to monitor AI agents, their integrations, and supporting infrastructure in real time.
With AI Agent Monitoring in AppDynamics, teams can ensure compliance by tracking LLM usage and aligning with internal policies and regulatory requirements, which reduces the risk of violations. Teams gain clear visibility into resource consumption and operational expenses, making it easier to optimize costs, allocate resources efficiently, and identify the main drivers of spend.
Health and performance monitoring is also streamlined, allowing teams to quickly detect anomalies and address issues before they affect end users or business-critical applications. Customizable dashboards and business journey mapping further enhance visibility into how AI agents impact application performance and business transactions.
With AI Agent Monitoring in AppDynamics, you can confidently manage and scale AI initiatives, aiding in compliance, controlling costs, and maintaining the health of mission-critical services.

Splunk & AGNTCY: Unlocking the Future of AI Observability
Last month, AGNTCY—an open-source collective with a bold mission: to establish the specifications, code, and services that will power the 'Internet of Agents’-announced its move to the Linux Foundation. This visionary initiative envisions a future where agents from any vendor or organization can seamlessly and securely collaborate. AGNTCY project has attracted over 75 members, including industry leaders like Cisco, Google, RedHat, Dell, and Oracle.
Aligning with our commitment to empower ITOPs and engineering teams with open standards, Splunk is now collaborating with AGNTCY, a Linux foundation project, to accelerate the development of semantic conventions and instrumentation in OpenTelemetry (OTel) for GenAI and multi-agent system (MAS) metrics, events, logs, and traces (MELT). By championing these shared standards, Splunk ensures its customers benefit from consistent, vendor-neutral telemetry capture for large language models (LLMs) and agentic applications, strengthening our AI Agent Monitoring capabilities.
Splunk is both contributing to and leveraging components of AGNTCY, such as AGNTCY’s Metrics Compute Engine to provide advanced quality metrics such as factual accuracy and coherence, and foundational metrics like latency and error rates, for their LLM and agentic applications in an open standard manner.
"We built AGNTCY to solve problems every team faces with multi-agent software - agent discovery, identity management, secure messaging, and observability across frameworks. Splunk is bringing AGNTCY standards into OTel, giving developers consistent telemetry to understand agent performance." — Vijoy Pandey, GM and SVP, Outshift by Cisco
Splunk and AGNTCY are unlocking actionable insights for agentic application developers and operators at scale, pioneering next-gen agentic monitoring and evaluation metrics and capabilities to help businesses measure quality and detect drift in "agent workflows, tools invocations, behavior, and performance." Read this blog to learn more about Splunk and AGNTCY.
Get Started Today
Set up AI Infrastructure Monitoring (GA) today and join the alpha for AI Agent Monitoring in Observability Cloud to get hands-on and provide our product teams with feedback.
Many of the products and features described herein remain in varying stages of development and will be offered on a when-and-if-available basis. The delivery timeline of these products and features is subject to change at the sole discretion of Cisco, and Cisco will have no liability for delay in the delivery or failure to deliver any of the products or features set forth in this document.
Follow all the conversations coming out of #splunkconf25!
Related Articles
What the North Pole Can Teach Us About Digital Resilience

The Next Step in your Metric Data Optimization Starts Now

How to Manage Planned Downtime the Right Way, with Synthetics

Smart Alerting for Reliable Synthetics: Tune for Signal, Not Noise

How To Choose the Best Synthetic Test Locations
Advanced Network Traffic Analysis with Splunk and Isovalent

Conquer Complexity, Accelerate Resolution with the AI Troubleshooting Agent in Splunk Observability Cloud

Instrument OpenTelemetry for Non-Kubernetes Environments in One Simple Step