
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

When last I blogged I wrote up this light and fun piece on Splunking my family refrigerator activity, so that I could stay out of the grocery store and comply with local social distancing guidelines. Since then, I’ve spent the last few weeks in my basement, working remotely like much of the world, and going a little crazy. Time to blog for a change of pace!
My colleagues at Splunk have been hard at work releasing some Remote Work Insights solutions during these unprecedented1 times. One of those solutions is the very pretty “Remote Work Insights Executive Dashboards” app that aggregates utilization and availability trends for the important work systems that remote employees use. The app has been available for a few weeks now, but we just recently posted it to Splunkbase. It does a nice job of showcasing executive-level metrics about Okta, Zoom, and Palo Alto GlobalProtect VPN activity in a series of flashy, dark-mode dashboards.
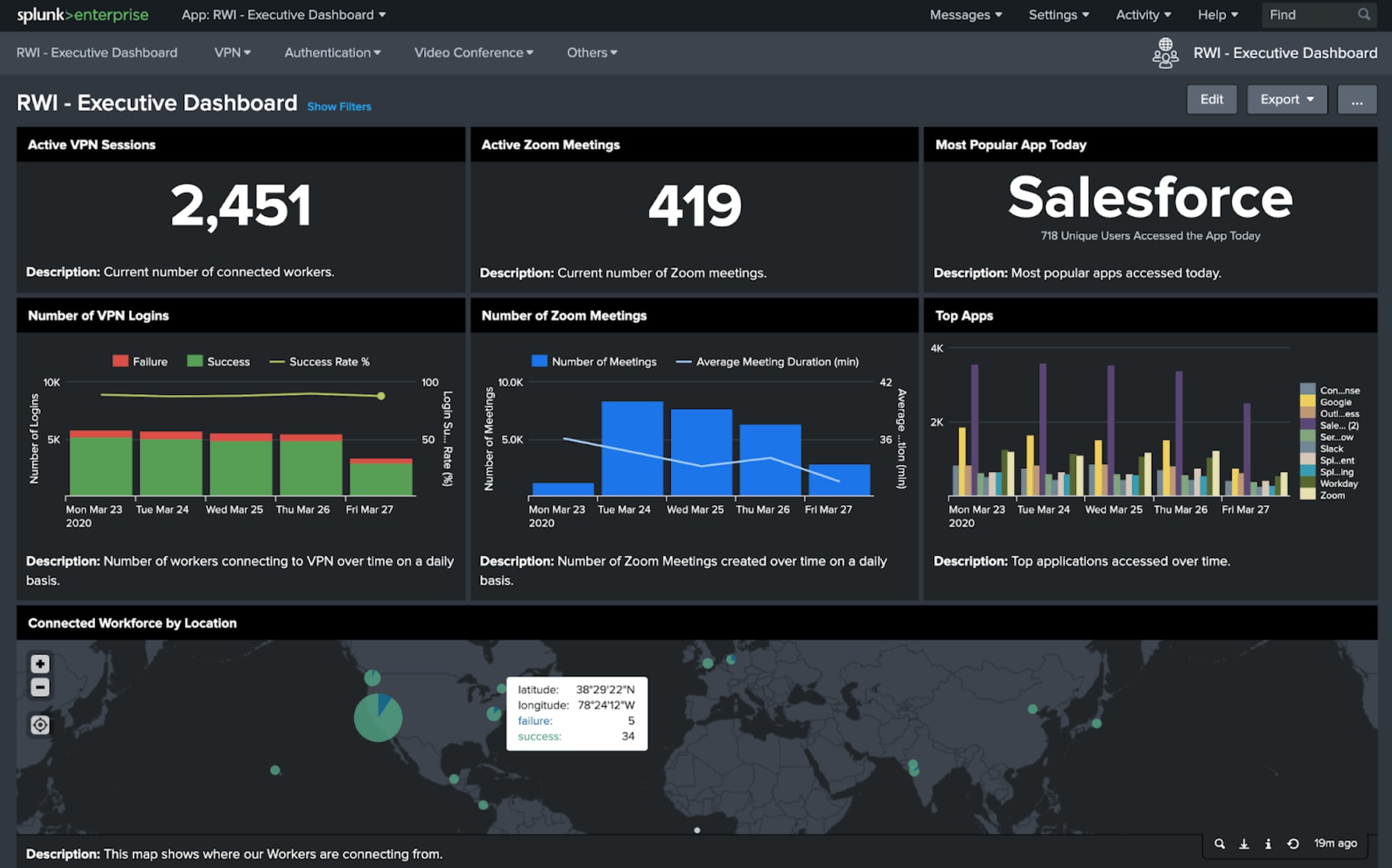
About six seconds after we made the app available, we started fielding questions internally and externally.
All good questions! The first two are because those are the data sources we monitor internally, at Splunk, that we use to get our business done remotely. So we offered this app up to the public as an example that can be modified and used free of charge.
And question three? Here’s the really cool thing. The Dashboards app will work with other VPN and Authentication data sources, quite easily, as long as those data sources map to Splunk’s Common Information Model. So the rest of this post will show you how I took some VPN and Authentication data from my lab environment, and mapped it in a way that the panels in the Dashboard app light up. The TL; DR: If your data sources populate the Authentication and Network_Sessions Data Models, you are well on your way to success. If not — “success” is actually part of what you need to focus on. I shall explain! (Actual Splunk documentation on how to map fields to data models in the Splunk CIM is here.)
When I first installed the Dashboards app in my home lab, I was very sad. It looked like this:
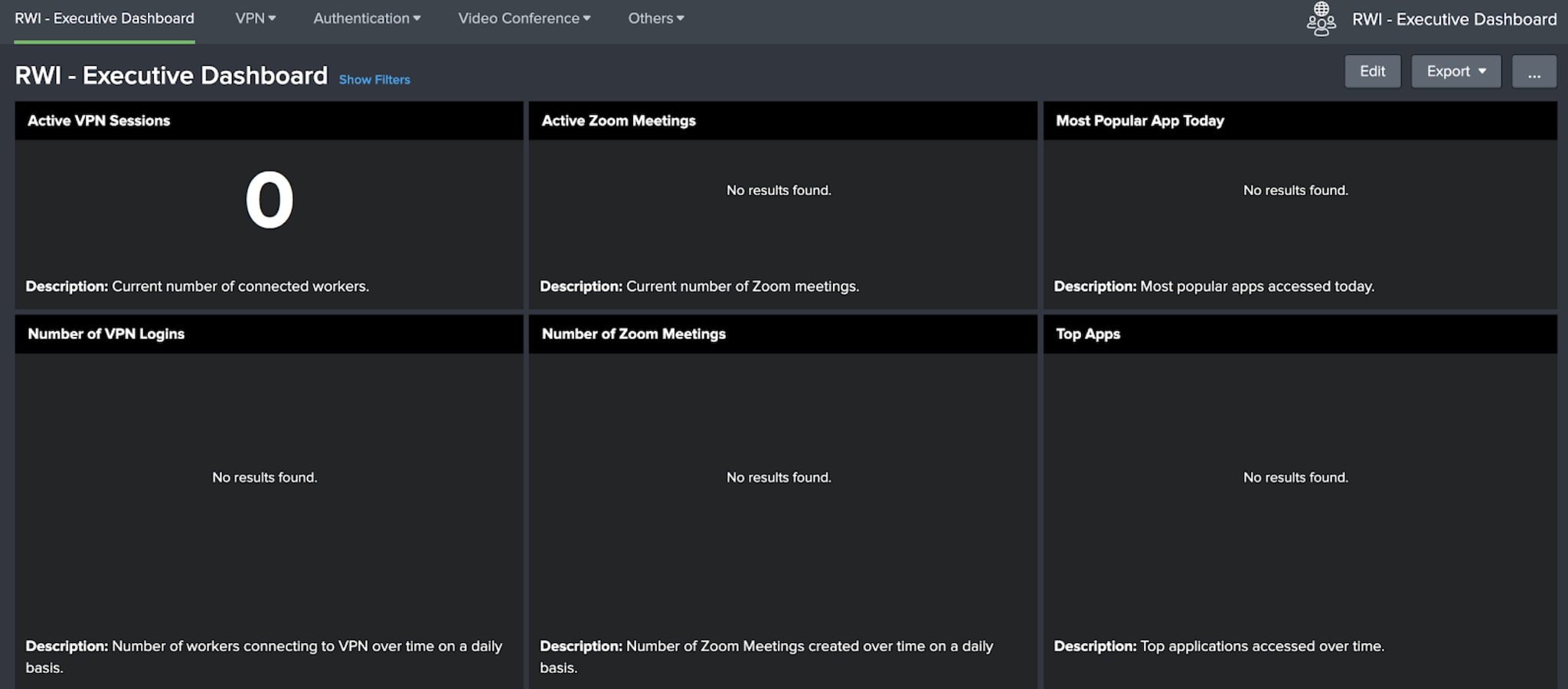
Fail. That’s a far cry from the lovely, fully populated dashboards from our CTO Tim Tully’s blog. He must have more alliteration in his name and be better looking than me, because his dashboard works. OK —let’s fix it! I want this dashboard to light up, and never go out. Now, to keep this blog manageable I’ll concentrate just on the two panels on the left: Active VPN Sessions and Number of VPN Logins.
The first thing I needed to do was to take an inventory of the data sources in my environment, and figure out which ones I would use to light up the dashboard. If I wanted the VPN panels to do something, I’d need...VPN usage data! Well, it just so happens I run one of the open-source consumer router distributions called FreshTomato (DD-WRT) to provide Internet connectivity to my household. FreshTomato implements OpenVPN as a feature - this allows me secure access to home network resources from whatever port-of-call I happen to be in (cries wistfully remembering glamorous business trips in months of yore).
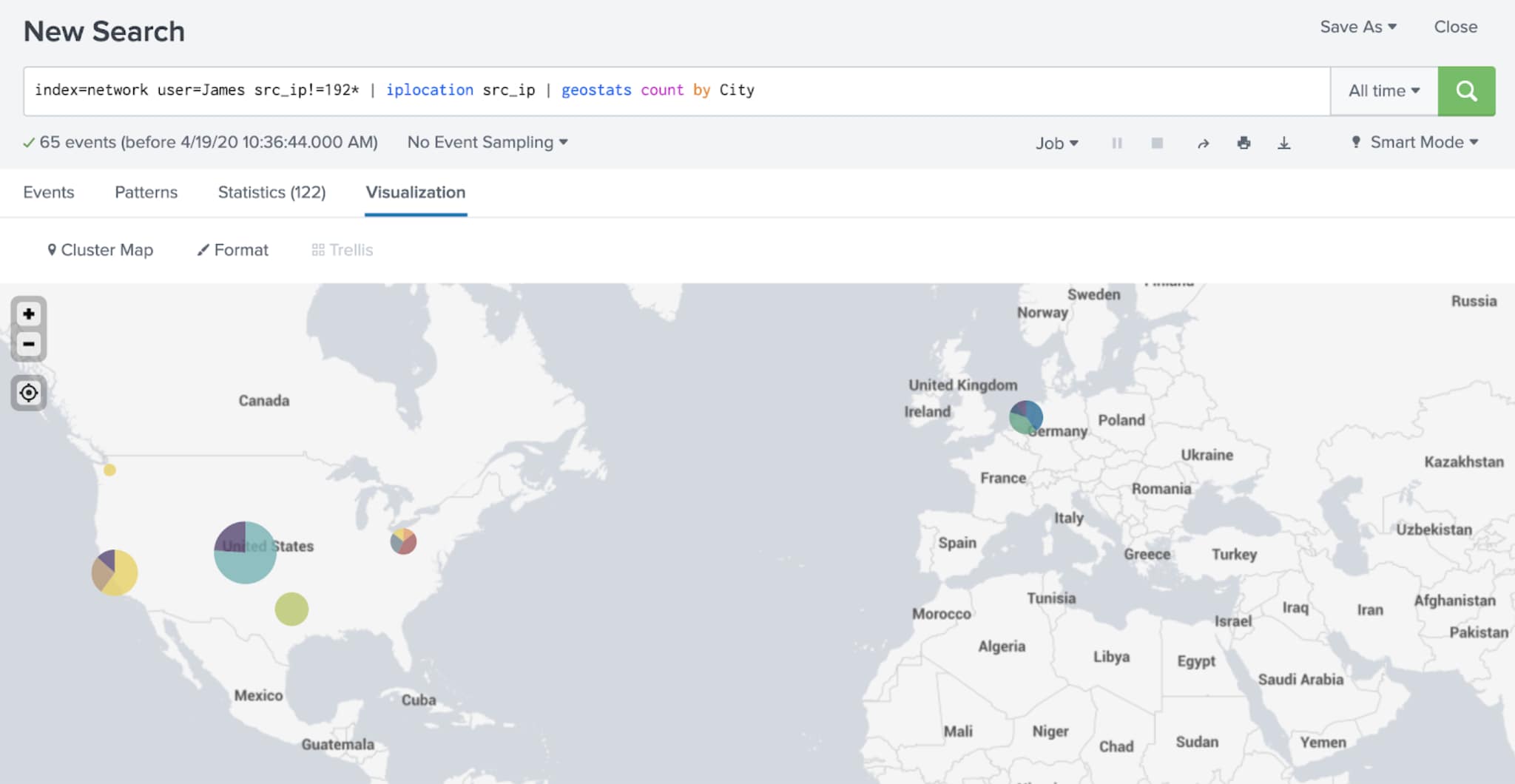
Now, years ago, I installed this Splunkbase TA (Technical Add-On) to onboard the data from my consumer router, via syslog, into Splunk. And it does a reasonable job “out of the box” with that task, providing field extractions and some CIM compliance too2. Yet, even though I knew I had VPN login data coming into Splunk (below are some of my travels, according to VPN connections) why wasn’t my RWI Executive Dashboard lighting up?
To start, have a look at the searches underneath those RWI panels. Here’s the one from “Number of VPN Logins”:

I’ve highlighted the important bits above. This search looks at the Authentication data model, just for events scoped to whatever indexes your VPN data resides in. Then it counts up the number of action=success or action=failure events it finds there, and plots that on a timechart. So this means, to get data on the dashboard panel:
Here’s the good news! All Splunk TAs that properly support the Authentication data model will have the “action” field properly populated and therefore that panel on the RWI dashboard will just work. In other words, you might not have to worry about any of the rest of this blog and you can go catch up on Tiger King! But if it doesn’t, here’s what you do...
First, see if your Authentication data model has data, and if it has the right values in the fields. So, go to Settings->Data Models in the Splunk web UI, and hopefully you see something like this:
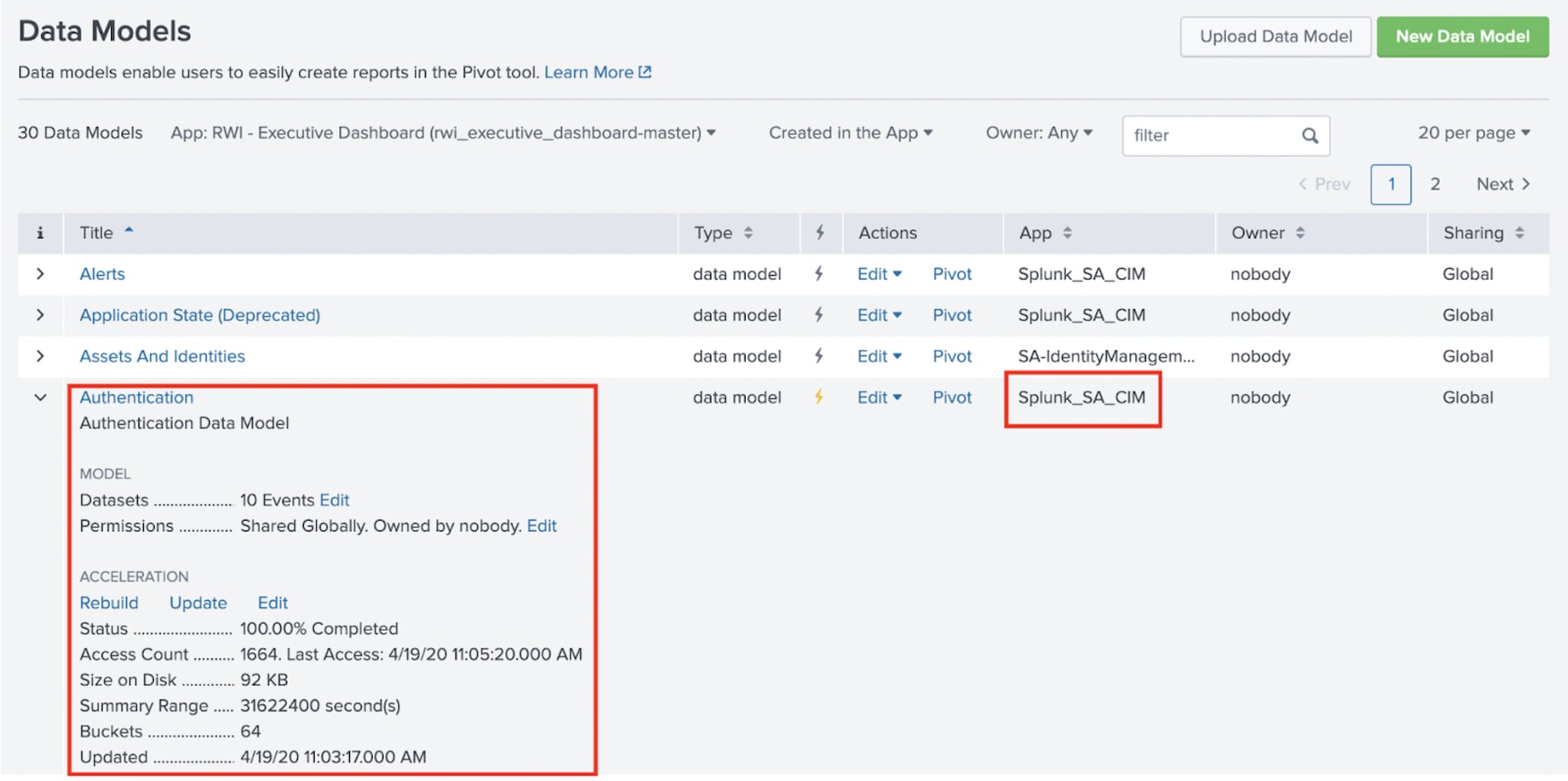
Great. I know I have an Authentication data model. It came from an app called Splunk SA_CIM. It appears to have data in it. If you don’t have something similar to this, you probably have to a) install the CIM app, b) point it to the indexes containing Authentication data, c) ensure that the Authentication data model maps to the data you want to put into the model (in this case, data tagged as “authentication” as seen below3):
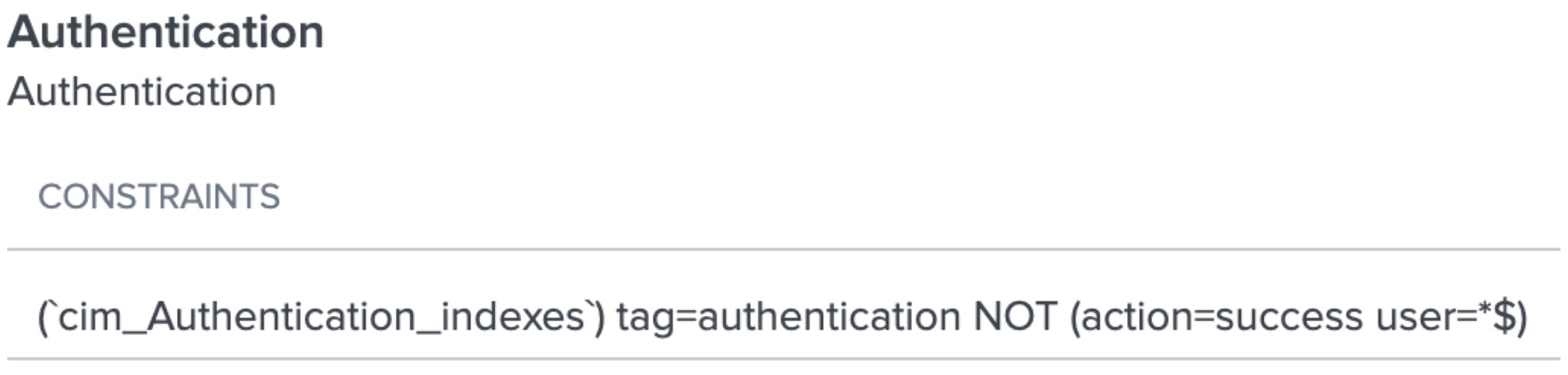
OK, so now I know that all data, tagged as “authentication” should map into this model, as long as it doesn’t have both an action value of “success” AND a user value ending with a dollar sign. But this also means that “authentication” must have the “user” field in it, too!
Next, run a search like this, to see what the raw data underneath the Authentication data model looks like:
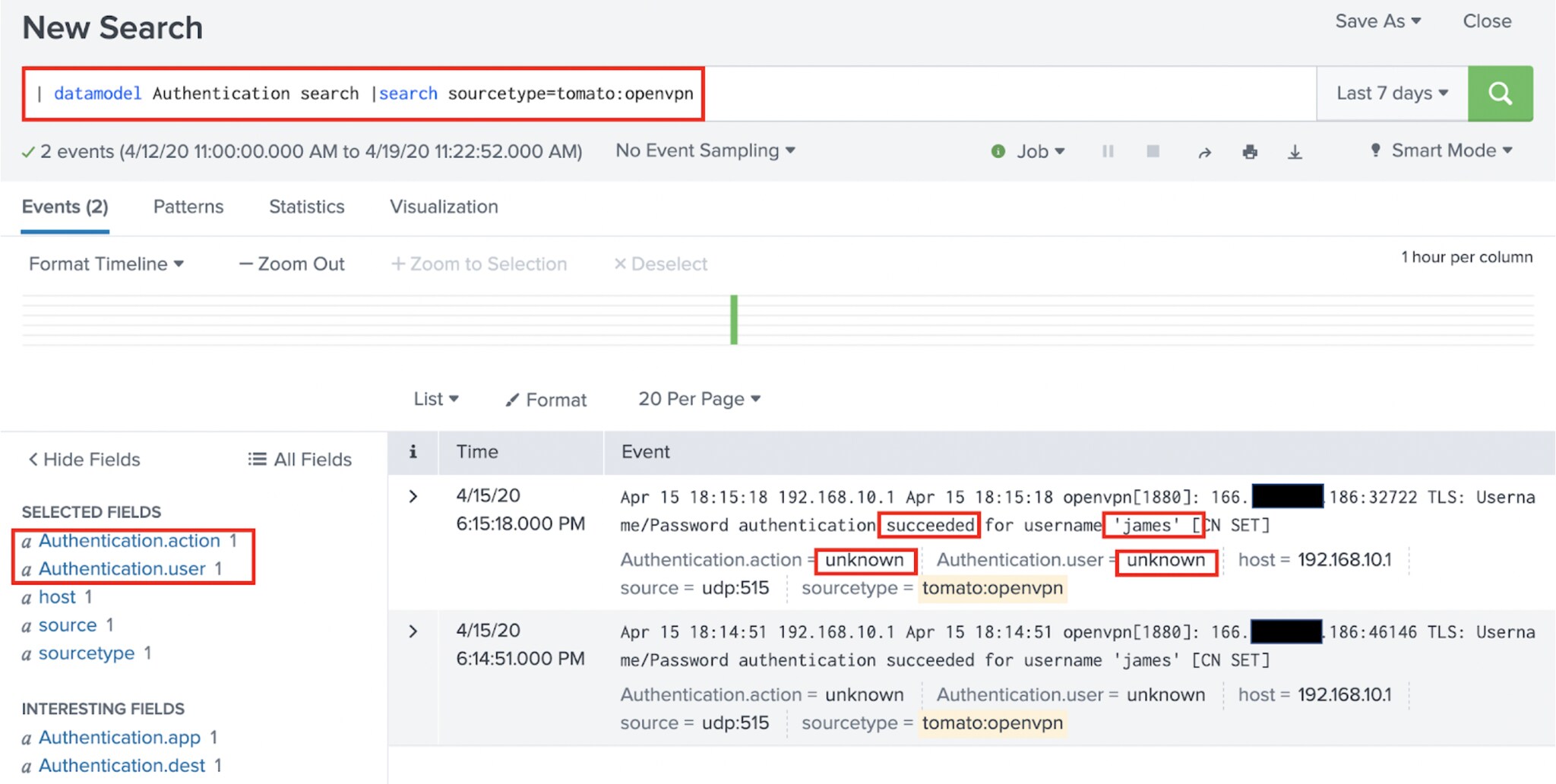
This leverages the convenient datamodel command. And at first, it looks great! I have data, and it has the fields Authentication.action and Authentication.user in it. Perfect, right? But look closer. The “action” field contains a value of “unknown” and so does the user field. Remember from above: that action field needs to contain “success” or “failure.” Also, we probably want the “user” to populate correctly, because the username is clearly in our raw data. Further down the rabbit hole we go!
The props.conf file provided in TA-Tomato has several lines in it to perform proper field extractions against the tomato:openvpn events. However, if you open it up, it isn’t by default mapping the value “success” or “failure” to the action field (it just returns ‘end’ and ‘start’ as values), and it also doesn’t set a user field, at all (see the line in red):
After some editing of this props.conf file (remember to always move it to local, from default!) my props.conf for the tomato:openvpn section looks like this:
The orange modified line above adds two more field values to my “action” field - “success” if the event contains authentication succeeded and “failure” if the event contains AUTH_FAILED. The four green lines were added, and provide a proper value for the field “user” (or unknown, if not in the event) and “src_ip” and then finally alias “src_ip” to “src.”
Did it work? Here’s what was returning from the Authentication data model before my changes:
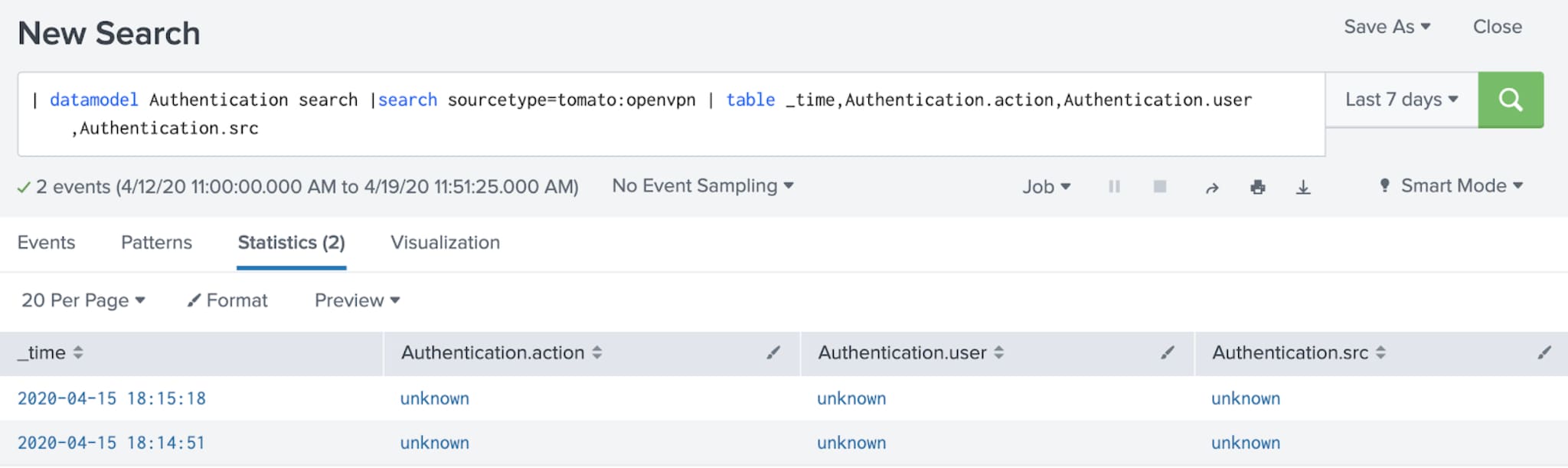
And after4:
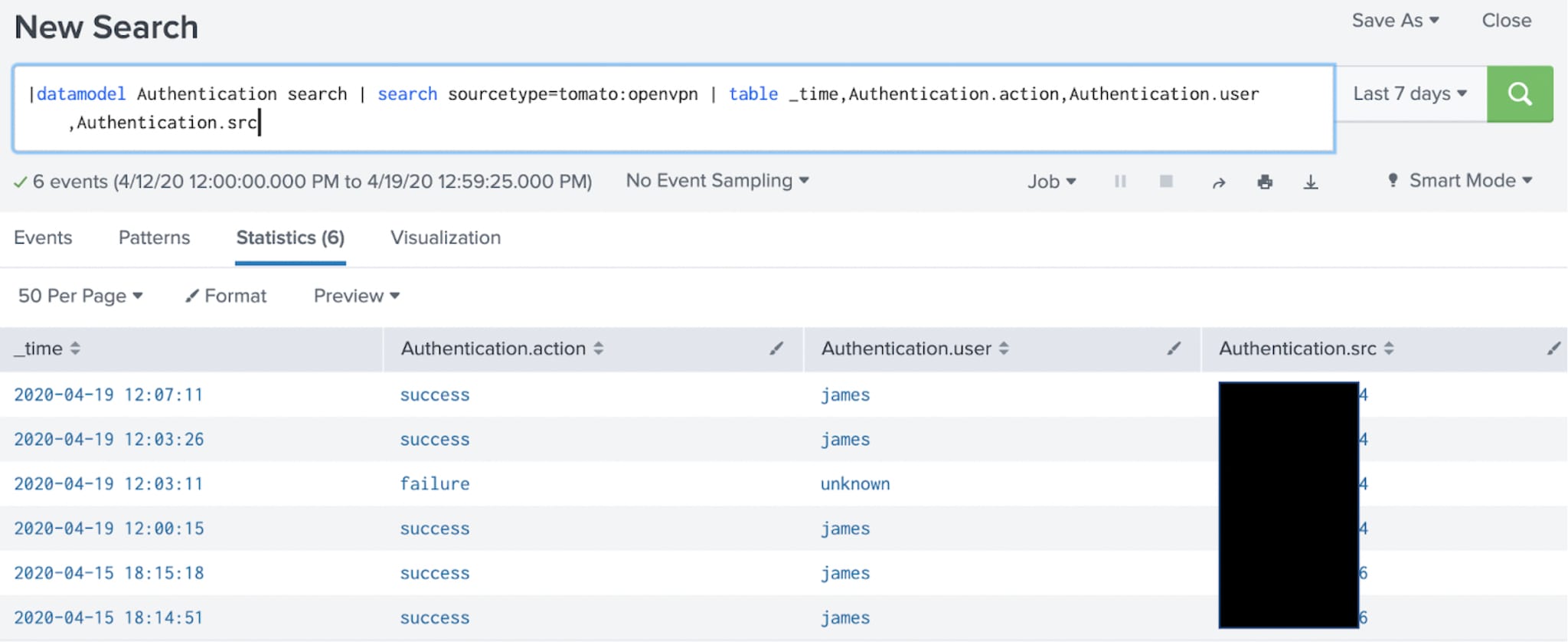
But the proof is in the pudding, dear reader. At this point during the writing of this blog, I had my son, as penance for eating too many midnight pickles, grab his laptop and hop on his bike and head over to the local coffee shop. Thumbing his nose at shelter-in-place directives, he crouched on the sidewalk, connected to their WiFi, and VPN’d into our home network:
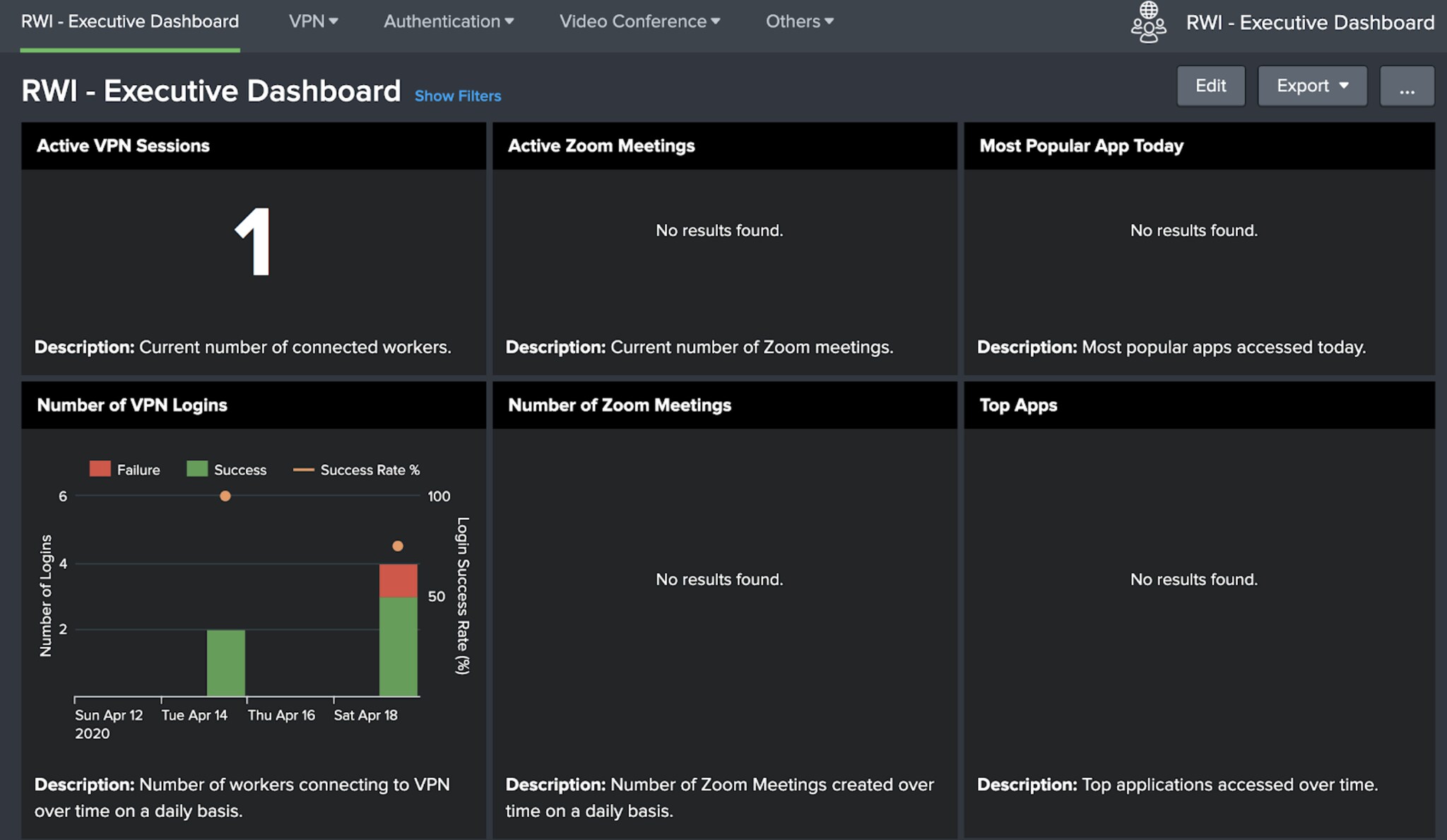
Success!
If you’d like some casual assistance getting your production data sources to light up your own copy of the RWI Executive Dashboards, contact your Splunk account team, and you can always DM me at james_brodsky. Happy remote working!
1: Two for two!
2: TA-pfsense is another possibility for CIM-compliant examples as that firewall also implements OpenVPN.
3: I did need to manipulate the eventtypes.conf and my tags.conf files in the TA in order to get this far, and I mapped certain tomato:openvpn events to the Authentication tag. For a documented example of how to do this, check out step 3 here
4: If the data model is accelerated, which it should be, you’re going to want to rebuild the summaries after making this change to re-accelerate the old data.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
