
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Imagine you are living in a townhome complex where expenses like water, landscaping and parking lots are managed by the Homeowners Association (HOA). All is well in the world until one day, the HOA instructs you to get rid of your hot tub because they have found that the meter you share with your neighbor is consuming significantly more water than any other townhome in the complex and they suspect because you have a hot tub, it must be your fault!
If this sounds a little too specific to be a consequence (or a particularly nasty case of hot tub jealousy), that is because this nightmarish situation was exactly what my friend Sadie faced in 2017. Sadie fought the good fight and persevered to where she ultimately kept her hot tub after proving her neighbor had not one, but TWO leaking toilets that had been gradually getting worse and worse (for YEARS).
Upon hearing of this — as an unabashed data nerd — I was of course thinking, “how could data from Sadie’s meter have been used to detect and prevent this!?” So after demonstrating an appropriate level of shock and dismay, I was quick to ask Sadie if she could share her meter data with me; after just one eye roll, I had years’ worth of meter reads to play with!
The remainder of this blog shows how to easily plug consumption data — like Sadie’s meter data — into the Splunk Machine Learning Toolkit to proactively report and alert for abnormal consumption like when an air conditioner is on the fritz, toilet(s) are leaking, or more frightening, when there is a gas leak.
For readers interested in digging in further, be sure to check out the companion app to my "Maintaining a State of Good Repair with Predictive Analytics" session at .conf19 that covers this use case and two others with sample data and searches to get you started.
Similarly, you can watch this short 3-minute video that summarizes the use case.
After giving our friend Sadie a high-five for her victory over her HOA issue and getting her meter data into Splunk, we are ready to go to the Machine Learning Toolkit to see how years’ worth of water waste could have been detected and prevented.
In our case we are looking for anomalies, so we head to the “Detect Numerical Outliers” assistant by navigating to Classic --> Assistants --> Detect Numerical Outliers and populate the assistant with a base search and metrics as per those shown in the screenshot below:
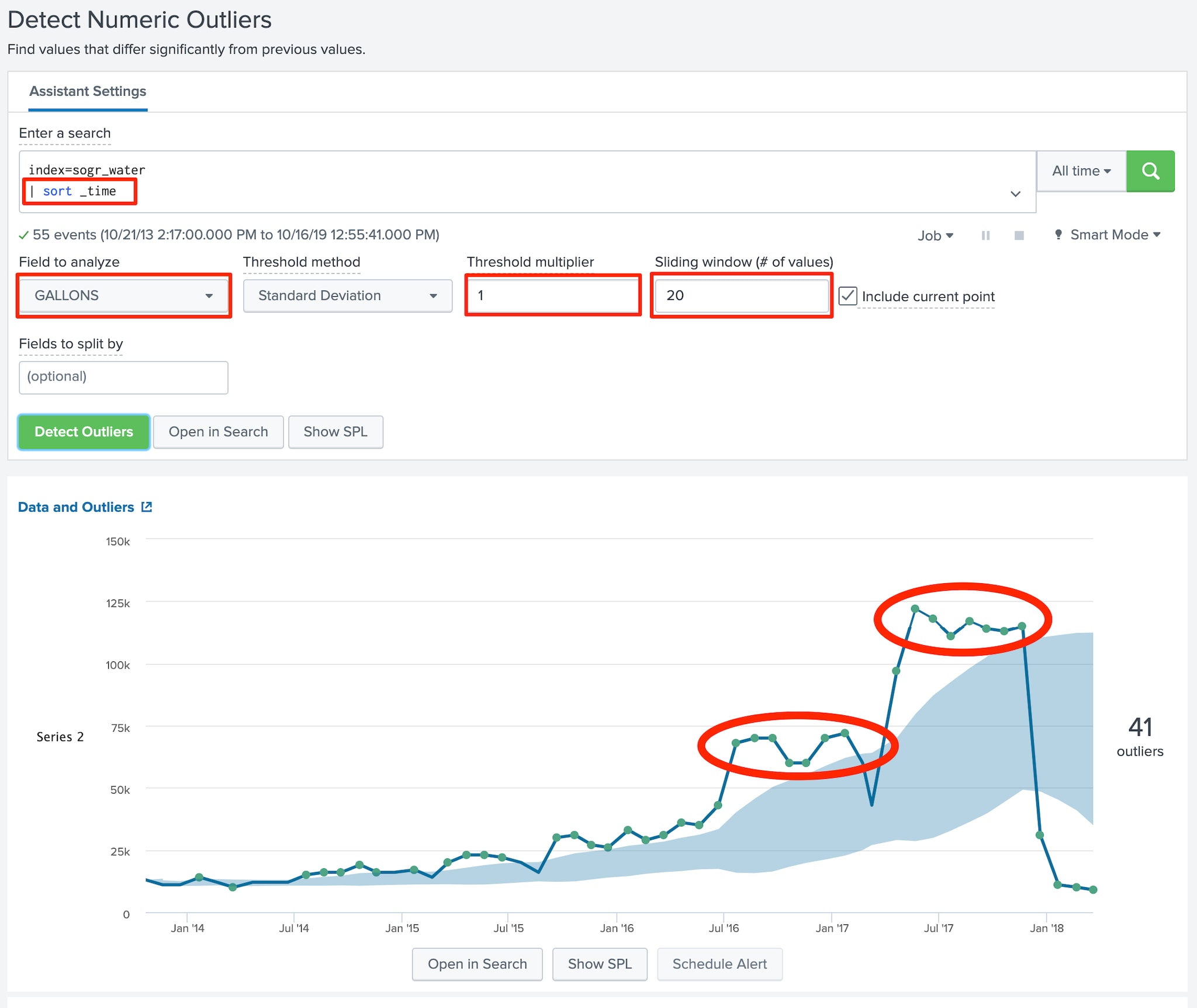
Something to note in this screenshot is the | sort _time of the base search. The “Detect Numerical Outliers” does not care what order the events happen, but rather if there are anomalies relative to the measures of whatever field you're analyzing. In our case, we DO care about the order of events relative to time so by sorting by _time we can tell Splunk to take this into consideration.
After populating the search criteria and clicking the “Detect Outliers” button, Splunk shows us a light blue range of “normal” consumption that expands as consumption climbs from one reading to the next. The “dots” above and below this range represent upper and lower bound statistical anomalies as per standard deviation specified in the “Threshold multiplier”.
For me, one of the most striking aspects of this visualization is how the two leaking toilets are clearly seen in the clusters of upper bound deviations I have circled in red. Looking at these clusters and the 36 upper bound deviations that preceded the eventual decline in water consumption as the toilets are fixed, I find myself asking “how can we learn from this to prevent this kind of situation from happening in the future?”.
To answer this, let’s see how to take the search provided by the “Detect Numerical Outliers” assistant and take things a step further by modifying it for the purpose of ongoing monitoring & alerting.
The screenshot below shows a modified version of the search provided by the “Detect Numerical Outliers”assistant. The specifics of note in this search include;
NOTE: The example below shows a specific range for both the inner and outer search because it is being exercised against historical data. In the wild, you will want to use something more like earliest=-365d@d latest=now for the inner search to train the data and Last x days from the time picker for the outer search to reference the model created in the inner search for whatever period of time you are looking to determine if there are anomalies.
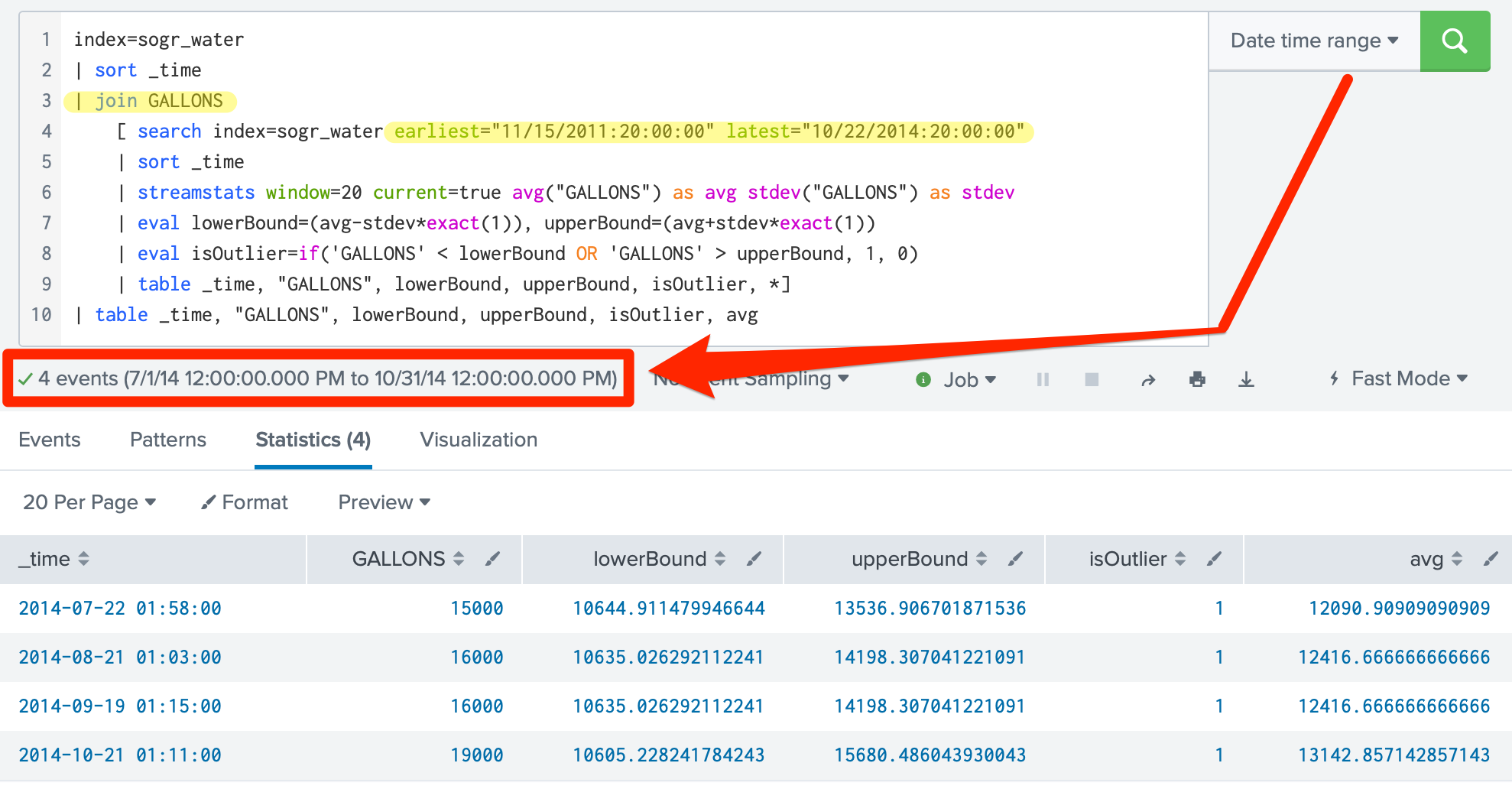
The table below breaks down this simple sub-search using these more common earliest / latest values for further clarification.
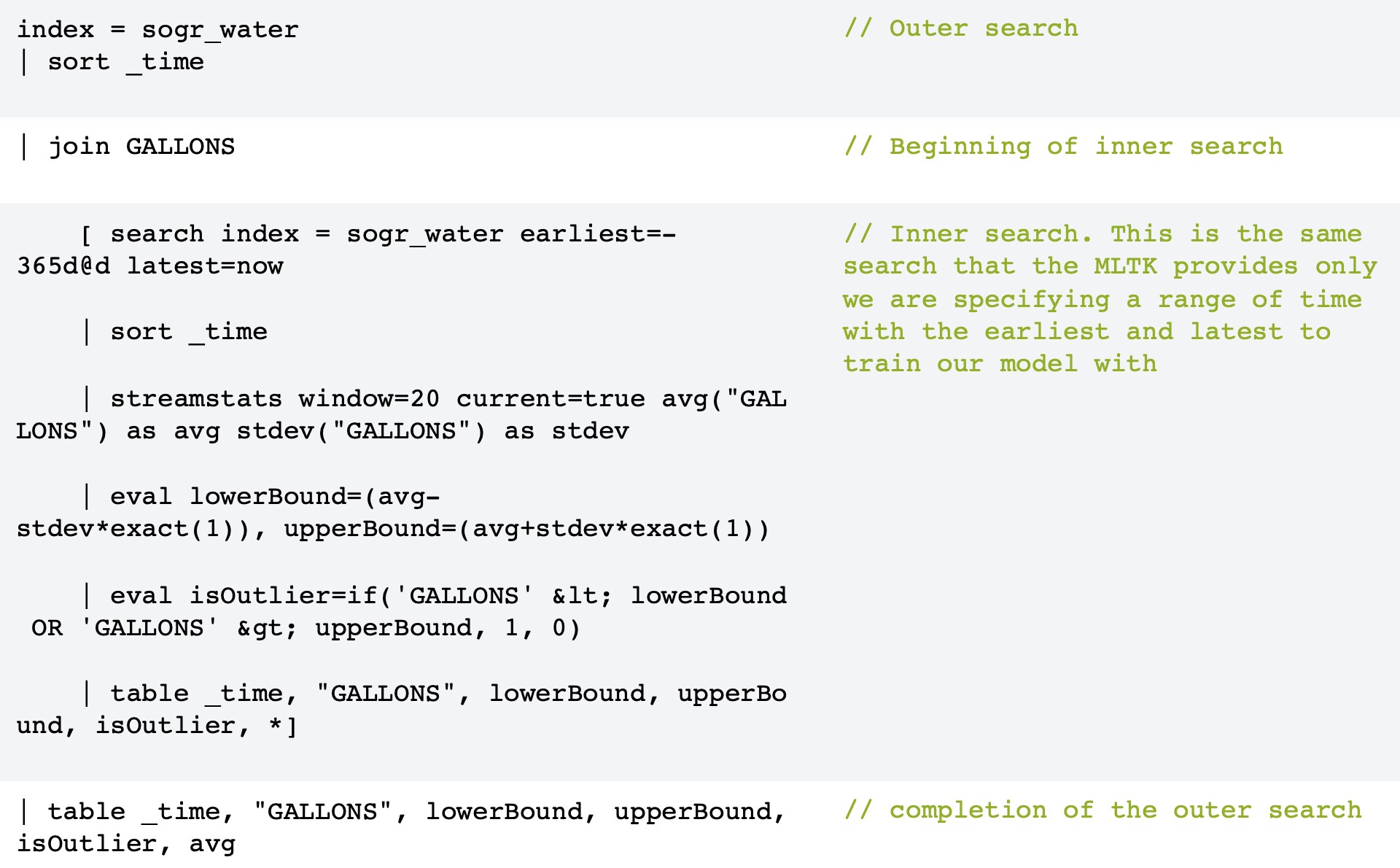
This sub-search is handy for demonstrating the concept of training a baseline of expected ranges and then comparing them against data from another time or even another customer. However, sub-searches are expensive…maybe not as expensive as leaking toilets, but expensive enough to avoid in most cases. That said, please be sure to check out this excellent 3-part blog series on Cyclical Statistical Forecasts and Anomalies that make clever use of lookups to scale / optimize this approach.
The technique of modeling, referencing and identifying anomalies discussed in this blog could have prevented years of water waste and saved Sadie from a lot of unnecessary heartburn. More specifically, the MLTK’s Numeric Outlier Assistant can be applied for forecasting, thresholding, and alerting on any kind of anomalies, be it water, gas, power, user-to-peer comparisons, abnormal authentication patterns, etc.
As mentioned earlier, stay tuned for part two and three of this blog where we explore two other use cases:
Until then, happy Splunking!
----------------------------------------------------
Thanks!
Tony Nesavich

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
