
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

That’s a wrap on SignalFx’s first visit to Elastic{ON}. We spent three days giving demos on monitoring modern infrastructure, talking to customers and prospects about alerting for higher performance from the Elasticsearch stack, and, of course, giving away snazzy socks.
We heard tons of compelling use cases from Elasticsearch practitioners in the wild. Like how the Mayo Clinic enriches its event data prior to storage and indexing to make it easier for physicians to match symptoms against past interventions and determine the best course of action with what-if scenarios. Cisco’s Talos security analytics team uses Elasticsearch for pattern matching on persistent threat behavior to identify and take down hackers like the SSHPsychos (a.k.a. Group 93). In a complementary use case, FireEye evolved its Elasticsearch storage, speed, and performance to enable customers’ more complex queries and find more advanced security threats. And companies like HotelTonight and Eventbrite use Elasticsearch to build better discovery and recommendation engines for an improved customer experience.
 |
Along with these business cases, we loved having the chance to discuss the operations that underlie Elasticsearch availability and growth, and how it comes together with the rest of the services used to build today’s apps. We know from our own experience the important role Elasticsearch plays in modern infrastructure, providing easy integration and setup with a great API. We’ve also found that scaling, alerting on, and capacity planning for Elasticsearch can sometimes be challenging.
Based on our conversations with hundreds of Elasticsearch users in the SignalFx booth last week, we’ve learned that pre-built dashboards and an automatic cluster-level read out of performance and resource availability—days left of disk space, query latency, top clusters by index growth—are key to getting a fast start towards running Elasticsearch in production. From there, you can dive deeper to explore your implementation by index or shard or node, even proactively determining when and how to reshard with zero downtime (hint: add a “generation” concept to documents).
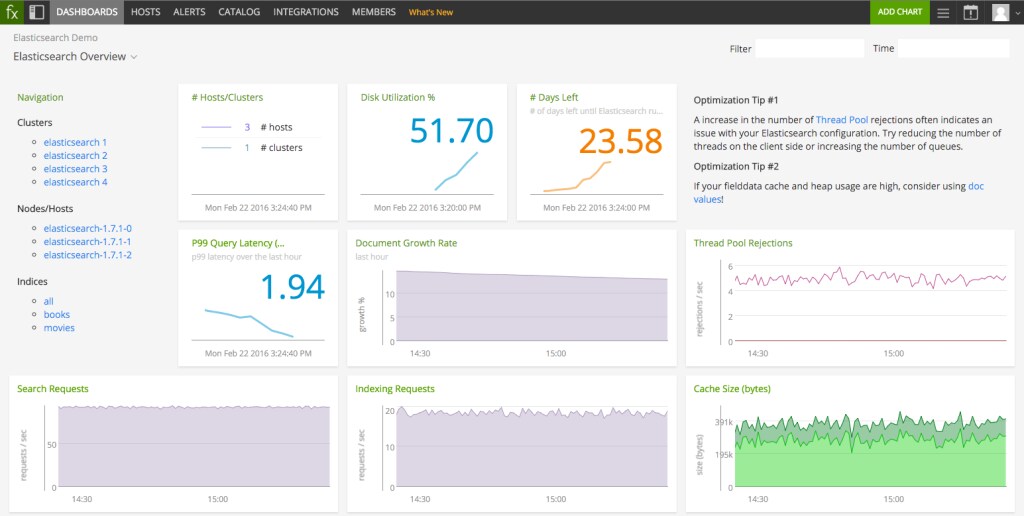
We also heard loud and clear that intelligent alerting is high on most people’s wish lists. Alerting on Elasticsearch at the node level can be painful, especially when you’re dealing with a service sitting on cloud infrastructure. With SignalFx, we’ve been able to eliminate noise by alerting exactly once, for example, on cluster health that not only passes a critical threshold, but also meets a duration condition beyond typical self-recovery period (instead of creating an alert for every node that reports yellow or red).
At SignalFx, every engineer or team that writes a service also operates that service—running upgrades, doing instrumentation, monitoring and alerting, establishing SLOs, performing maintenance, etc. The challenges we face are largely universal to everyone who uses Elasticsearch at any scale. Mahdi Ben Hamida, who oversees the search and metadata persistence layers of SignalFx, has been sharing his insights and experiences monitoring Elasticsearch both at Elastic{ON} and in a recent webinar.
|
----------------------------------------------------
Thanks!
ryan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
