
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
![]() Splunk User Behavior Analytics 3.0 (UBA) introduces significant advancements to Splunk UBA and drives Splunk’s Security Analytics to the next level. This is evident with Gartner placing Splunk in the leader’s quadrant and positioning Splunk furthest overall for completeness of vision.
Splunk User Behavior Analytics 3.0 (UBA) introduces significant advancements to Splunk UBA and drives Splunk’s Security Analytics to the next level. This is evident with Gartner placing Splunk in the leader’s quadrant and positioning Splunk furthest overall for completeness of vision.
Splunk UBA 3.0 makes an architectural shift by decoupling platform from content, thereby, providing customers with an ability to update detection footprint with zero downtime and without the hassle of upgrading the entire platform. Content includes the following: machine learning models, threat models, anomaly classifications, data sources, and intelligence. The goal for this architectural shift is two-fold – improve operational efficiency and keep up with the ever-changing threat landscape by delivering regular updates.
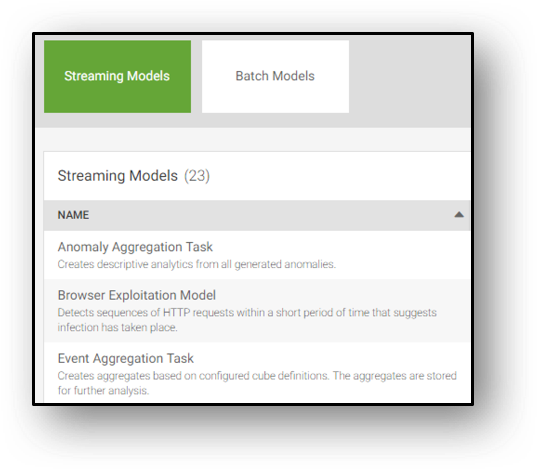
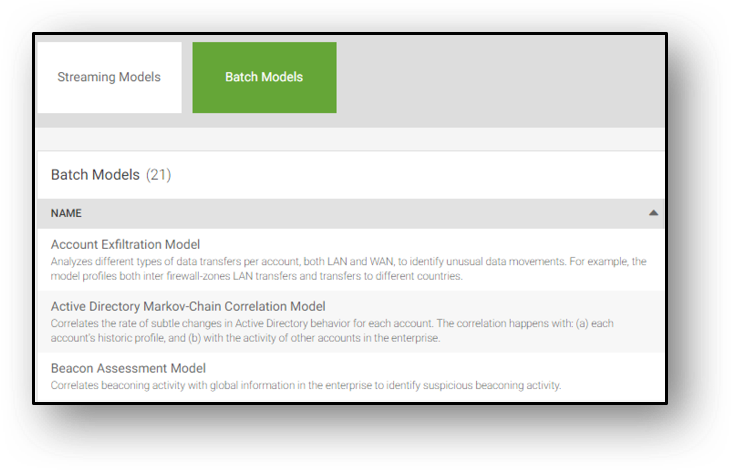
Attack coverage – insider or external – is dependent on the amount of intelligence within the product. Ultimately it boils down to one primary fact – the depth and breadth of machine learning models a product has. Splunk UBA’s primary focus is to continue broadening its detection coverage and the latest release supports over forty machine learning models. The models are categorized as either streaming or batch. Streaming models analyze data in real-time, whereas batch models process data or compute aggregates at a scheduled interval; an example of a batch model would be as follows: identify any outliers on Active Directory data with Peer Group in consideration (Active Directory Markov-Chain Correlation Model).
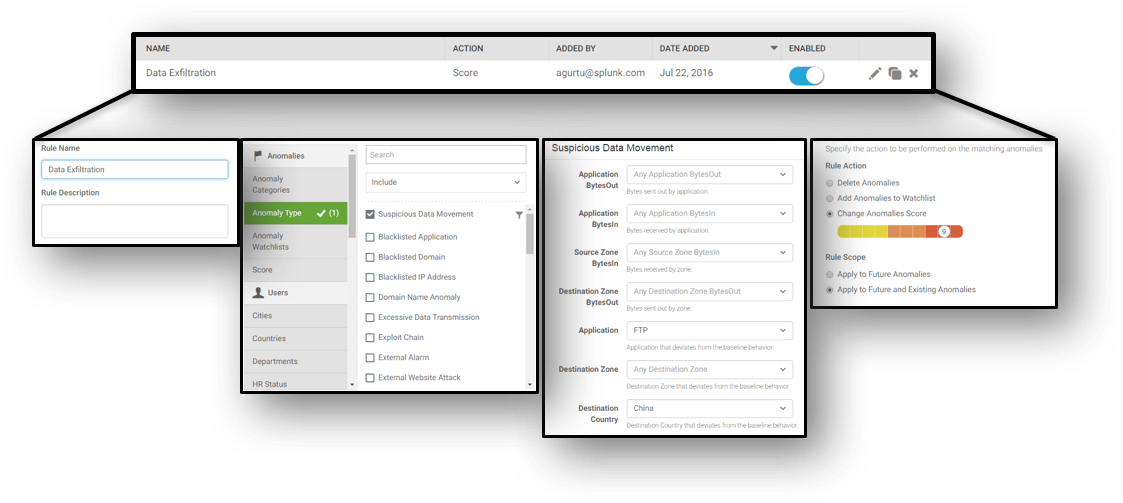
Customers desire accelerated detection and high fidelity alerts. To accomplish these results, particularly from a solution that is entirely driven via machine learning, there is a need to provide feedback to the underlying sub-system. That’s exactly what Splunk UBA 3.0 facilitates – customizing the output of machine learning models: changing scores, prioritizing alerts, de-prioritizing events and adding exceptions.
Splunk UBA’s machine learning-driven anomaly classification has over forty customizable anomaly types. Customers can change anomaly score, apply filters to suppress anomalies or prioritize anomalies, and detect anomalies for both historical and real-time data. This granular capability helps generate high efficacy threats, which does not require additional feedback to the threat modeling machine learning subsystem, however, you still have this functionality.
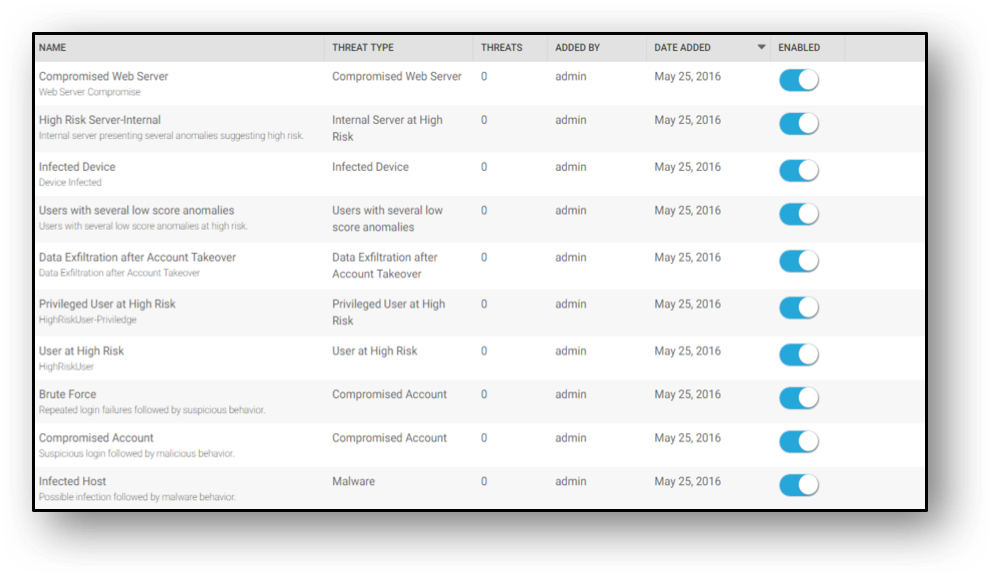
Splunk UBA 2.3 (released at RSA) delivered the ability to write custom threats, but with Splunk UBA 3.0, customer threat detection capabilities were elevated to the next level. Not only are new threat scenarios delivered via content subscription, our threat research team delivers blue prints of new use-cases that can be customized to address customer’s needs. All-in-all, twelve to over twenty out-of-the-box threat scenarios are now available at a customer’s finger tips. These new threat scenarios range from detecting low-and-slow attacks to detecting aggressive attacks such as Remote Account Take Over with Data Exfiltration.
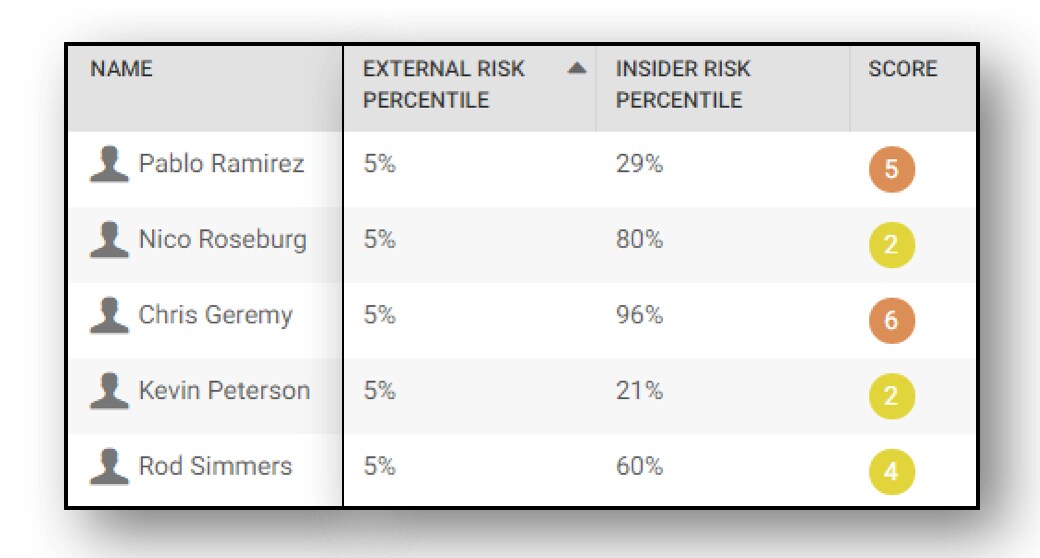
Splunk UBA 3.0 enhances its dynamic Peer Group Analytics feature to not only create peer groups based on role, but also on user’s behavior. This helps with identifying outliers across multiple peers and also helps with hunting; a hunter can pivot off a peer group to find a user probable as an insider or susceptible to an external attacker.
This feature becomes super critical when there are no associated anomalies or threats associated to an entity; however, actions of the entities deviate drastically from its peers.
Splunk UBA 3.0 will be generally available in October 2016.
Contact us to find out how customers are detecting insider threats and cyber-attacks using a machine learning-driven behavior detection solution.
Follow all the conversations coming out of #splunkconf16!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
