
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
I've been using the music service Last.fm for 10 years to track my listening behavior. I always liked having basic stats available about the music that I listen to, not to mention the "compatibility" feature that tells you what music listening habits you have in common with your friends.
Not only have I been tracking my listening behavior for the last 10 years, but I've also been keeping a list of all the concerts I've ever attended and keep my music predominantly in iTunes. I have three different sources of music data encompassing over 15 years of my life, and now I get to Splunk it.
Let's go!
Last.fm has an API that doesn't require authentication to pull recent tracks for a given user, making it easy to get the data out using the user.getRecentTracks endpoint. I built an add-on with the Splunk Add-on Builder; it took a lot of iterations, but it finally does exactly what I want it to. It's simple to build, but reach out to me if you want details about my add-on's configuration.
Depending on how much data you have, I'd recommend you backfill your data using a script. I used both the lastexport.py script and the NPM module to do this, but you could also write your own. Setting up the field extractions and source types for the backfill data was relatively straightforward. If you do backfill your data, make sure that the props.conf setting for MAX_DAYS_AGO is set to something longer than the default. I had 10 years of data for this source type, so I set it quite far in the past.
I also set up a `lastfm` macro in the Search and Reporting app to specify the different Last.fm source types so that when I was searching, I could use the macro rather than having to think about specifying the individual source types that had my Last.fm data.
After I got the Last.fm data in, I wanted to add my iTunes data and my concert data. I've been keeping a list of my concert data since I started going, so I used the Lookup File Editor app to upload the data and get it formatted in a useful way. I decided to add this data as a lookup rather than events so that I could update it easily.
iTunes data is accessible in a library.xml file, but that file isn't standard XML so it doesn't make sense to throw into the Splunk platform as-is. Instead, I relied on open-source scripts on Github again and used the iTunes_csv script to convert the XML data to CSV. This meant I was limited to the fields specified in that developer's script, rather than all the fields available in the XML. If you use that script, be careful to output the data to a file because it doesn't do that automatically.
Now that I have data from all three of the data sources I want to start with, it's time to start searching!
I started by writing searches to verify that my add-on was working. I wanted to be sure that data was actually streaming in as I listened. I made a table and sorted it by time so that I could see the basic data right away.
`lastfm` | table track_name artist _time | sort _time
Then I wanted to find out my artist distribution over the last day.
`lastfm` | timechart count by artist useother=f
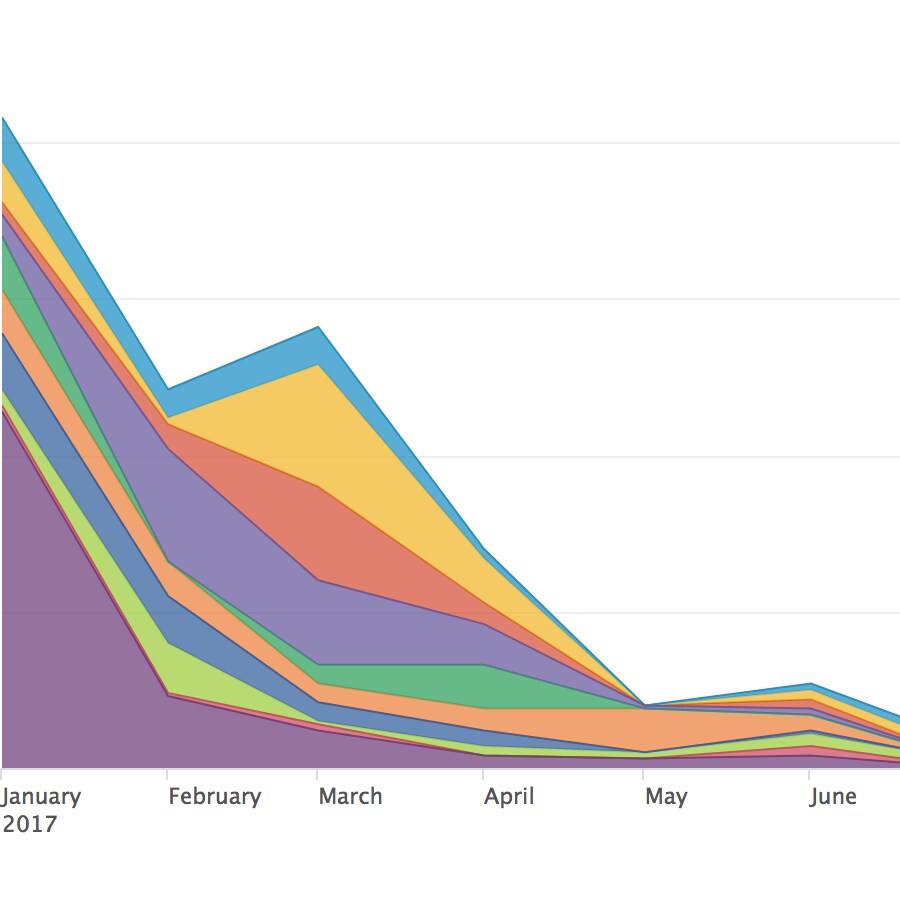
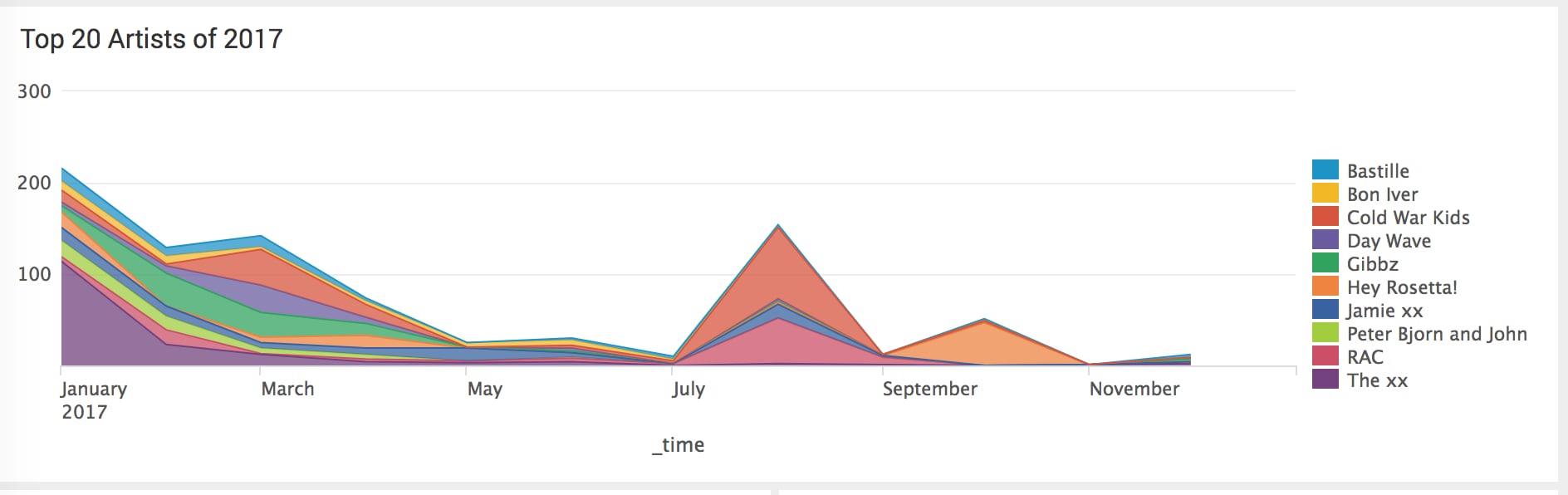
Now it's time to get ambitious. What are my top 20 artists of 2017 based on listens?
`lastfm` | timechart count(artist) by artist useother=f usenull=f| sort -count(artist) limit=20
By stacking my area chart, I can also see at-a-glance that my overall listens of these top 20 artists increased over time as well.
The drilldown behavior for this search isn't very pretty by default, however. It limits to the time range perfectly, but displays raw events, which includes extraneous field information like the mbid (MusicBrainz Identifier) for various fields, and the source and source type. I wanted it to be better, so I built a dynamic drilldown.
The latest version of the Splunk platform includes UI-based drilldown editing so that I can specify my own search. However, I want to specify drilldown tokens—which I can't yet do in the UI—so I reference the documentation about Token usage in dashboards in the Dashboards and Visualization manual. I determined which token to reference to display data about an artist and also discovered which tokens to use for earliest and latest times to specify the time range for the panel.
<drilldown>
<set token="artist">$click.name2$</set>
<link target="_blank">search?q=`lastfm` artist="$artist$" | stats count(track_name) by artist track_name album | sort -count(track_name)&earliest=$earliest$&latest=$latest$</link>
</drilldown>
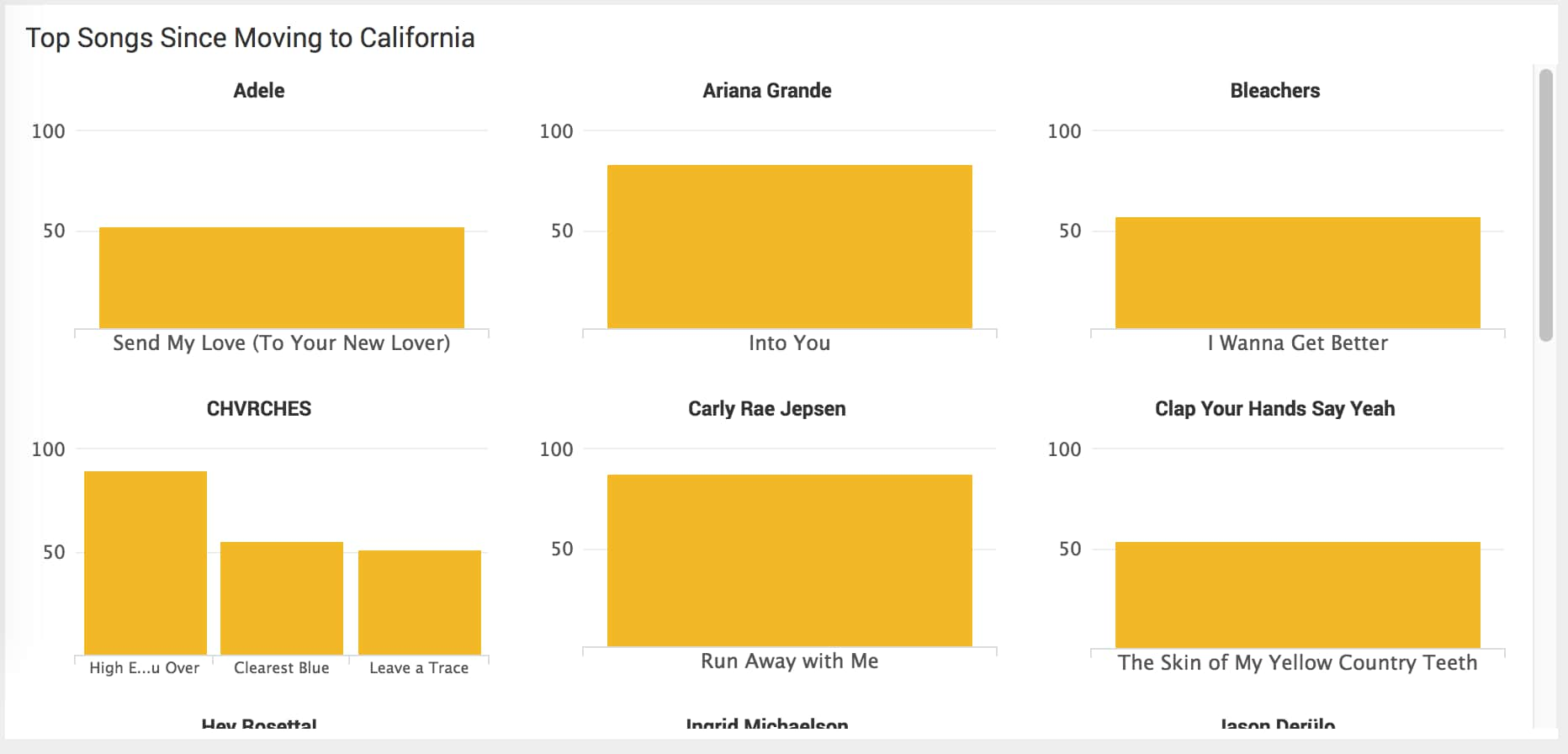
I'm feeling accomplished already, but I want to set up another search to show me the top 20 songs I've listened to after moving to California. Sort of my "California era" of music listening.
index=music | stats count(track_name) by track_name,artist | sort -count(track_name) limit=20
However, I'd originally chosen to display that information in a bar chart...and it was ugly. You could barely read it, it didn't communicate information clearly, and it didn't even have room to list the artists or track names I was listening to. It was time for a new visualization. Enter: trellis.
A simple flip to a column chart with a trellis layout split by artist, and I was almost there. It defaulted to a shared scale that chopped off the y-axis, so I specified a minimum y-axis value of 0 and I'm back in action.
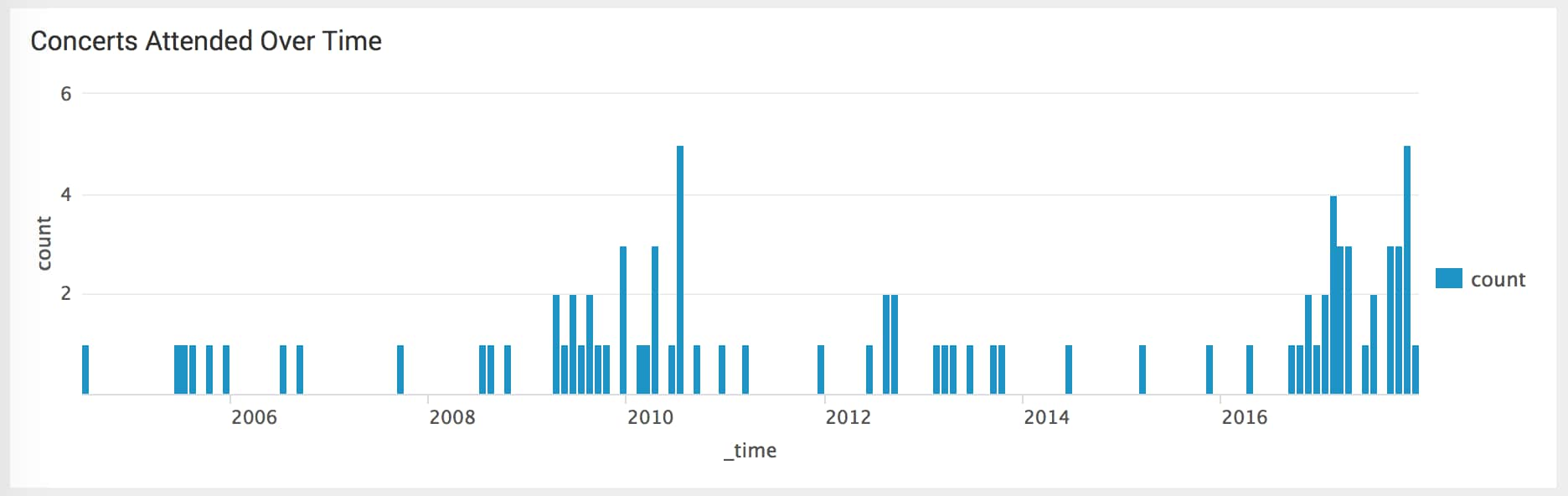
I want to keep going and start looking at another data source: concert data. I have this lookup of concert data and I want to analyze it across time. However, because this is a lookup, I can't just write this search:
| inputlookup concerthistoryparse.csv | timechart span=1mon count
Sure, I have a date field in there, but timechart doesn't know it's a time field, nor does it know what format it's in. Because timechart requires a _time field to perform statistical analysis over time, I have to convert the date field from the lookup into the _time field. Luckily, I can use the convert search command to do just that.
| inputlookup concerts.csv | convert timeformat="%B %d %Y" mktime(date) AS _time | timechart span=1mon count
If I specify the format of the time using strftime then I can convert my date field from the lookup in to a _time field that timechart recognizes.
But wait, I want a drill down in this panel too. I want it to show me exactly which five concerts I attended in the month I clicked in the chart.
<drilldown>
<set token="clicktime">$click.value$</set>
<link target="_blank">search?q=| inputlookup concerthistoryparse.csv | convert timeformat="%B %d %Y" mktime(date) AS _time | eval month = strftime(_time,"%m"), year = strftime(_time,"%Y"), clickmonth = strftime($clicktime$,"%m"), clickyear = strftime($clicktime$,"%Y") | where month=clickmonth and year=clickyear | table date, opener1,opener2, headliner, venue, city, state</link>
</drilldown>
I had a really eventful November, so let's open the drilldown for that month and see what we get.

Let's make more fun visualizations, like a choropleth map because I have location data for these concerts!
The geo_us_states lookup included with the Splunk platform to use with the geom command expects the featureId to be the full state name, so I make sure my concert lookup data is prepared to work with that format and start writing my search. I can specify which field to use from the lookup as the featureId field that contains the state in my search.
| inputlookup concerthistoryparse.csv | stats count(state) by state | geom geo_us_states featureIdField="state"
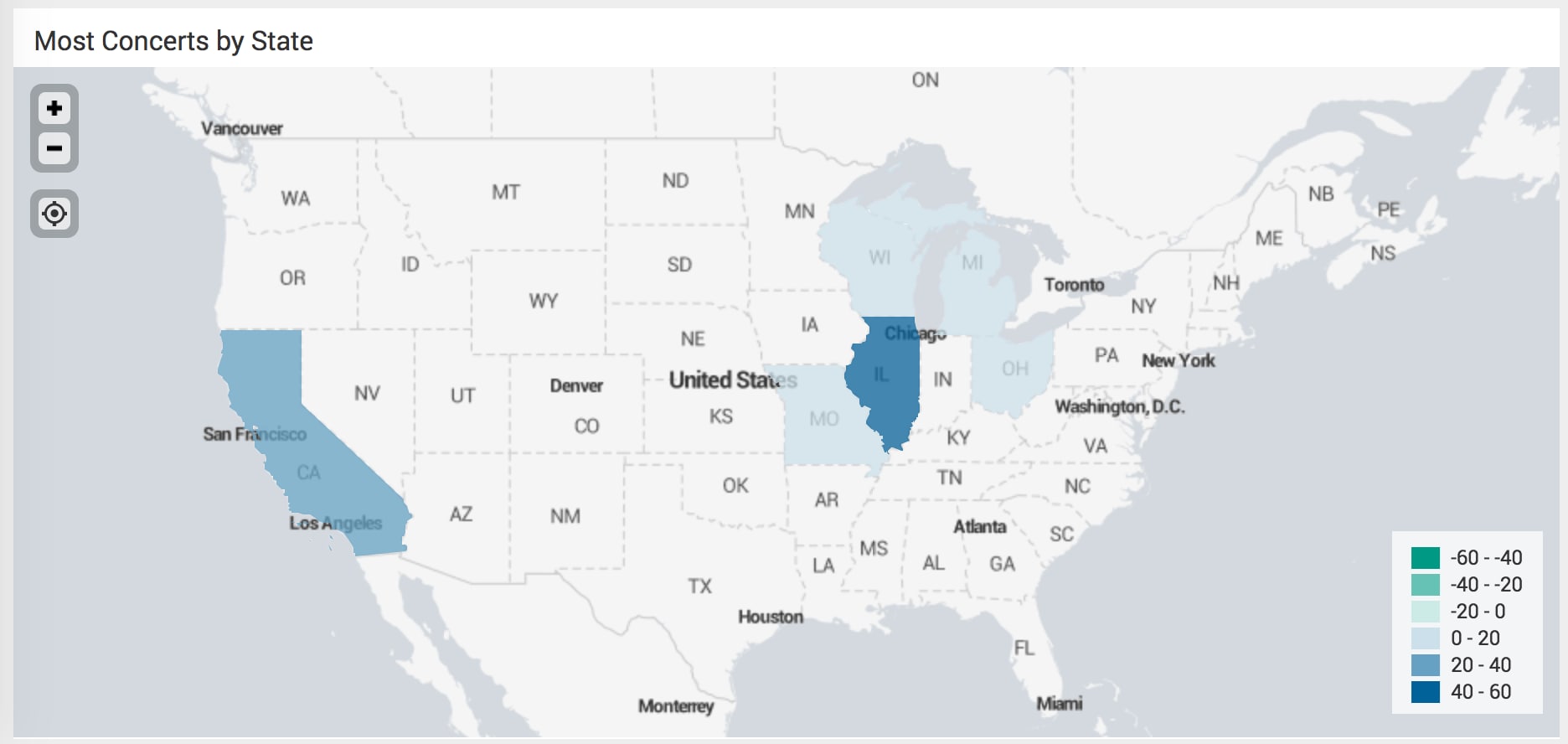
I formatted the choropleth map so that it would focus on the United States and show the states with just a few shows as a discernible color. A little bit of viz-hacking brought to you by the latitude and longitude of Kansas City and a zoom level of 4. I played around with the available colors and tiles as well to find a look that fit what I wanted.
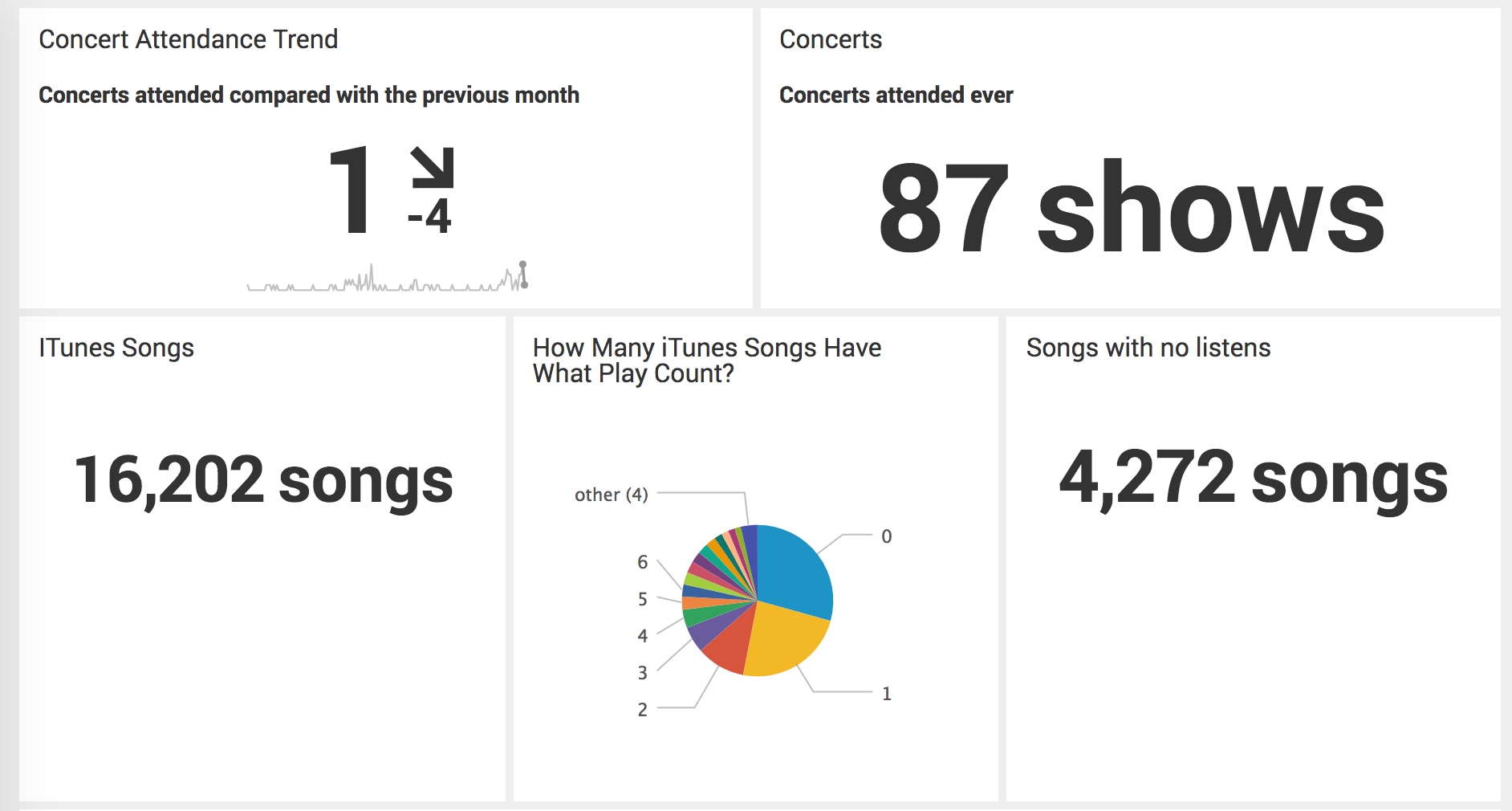
That was almost all of the fun visualizations I could think of. I set up some single value indicators to get some good statistics on my data. I wanted a concert attendance trending indicator, alongside the total count of concerts I'd been to; I also wanted to review the count of total iTunes songs alongside the count of iTunes songs I've never listened to. The pie chart showing the most common play_counts in my iTunes library make it clear: I haven't listened to nearly 30% of the songs in my iTunes library. Even worse, I've only listened to another 24% of the library just one time.
I wanted to figure out how my discovery and listening diversity was faring over time as well.
`lastfm` | timechart span=3mon dc(artist)
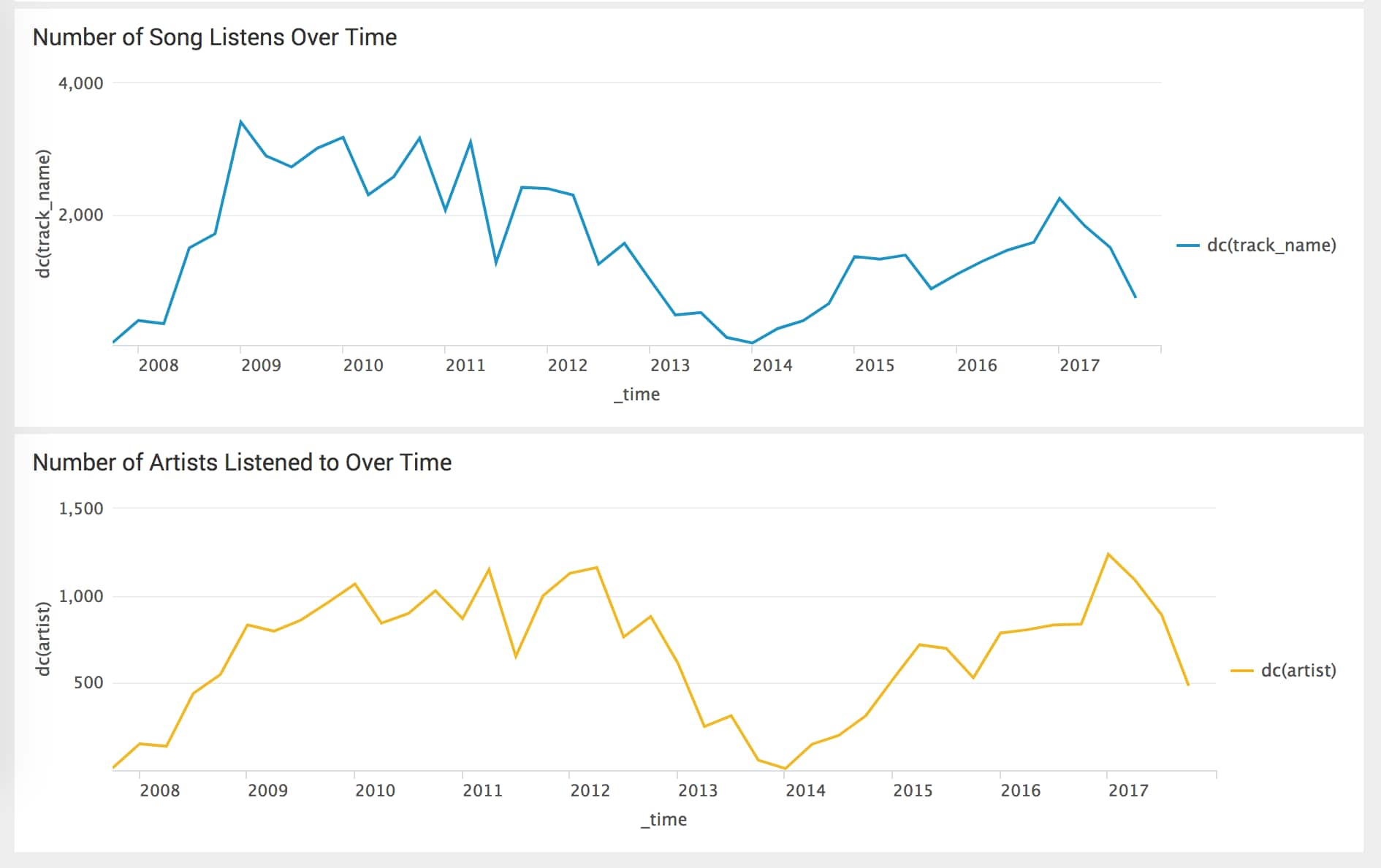
Working in a radio station in college meant that I was exposed to a lot of new music—something hard to replicate in other environments. However, by the looks of my data analysis, I'm doing okay again. Perhaps unsurprisingly, the distinct count of songs and distinct count of artists I've listened to over time hasn't been too different in terms of trend lines. The diversity of artists that I'm listening to nowadays is similar to where it was in 2010 and 2011 when I was working at the radio station, but the distinct count of songs is much lower, likely indicative of the fact that I've been busy doing things like working.
I took some more steps to analyze my concert data, figuring out which artists I've seen more than once and the list of most visited venues.
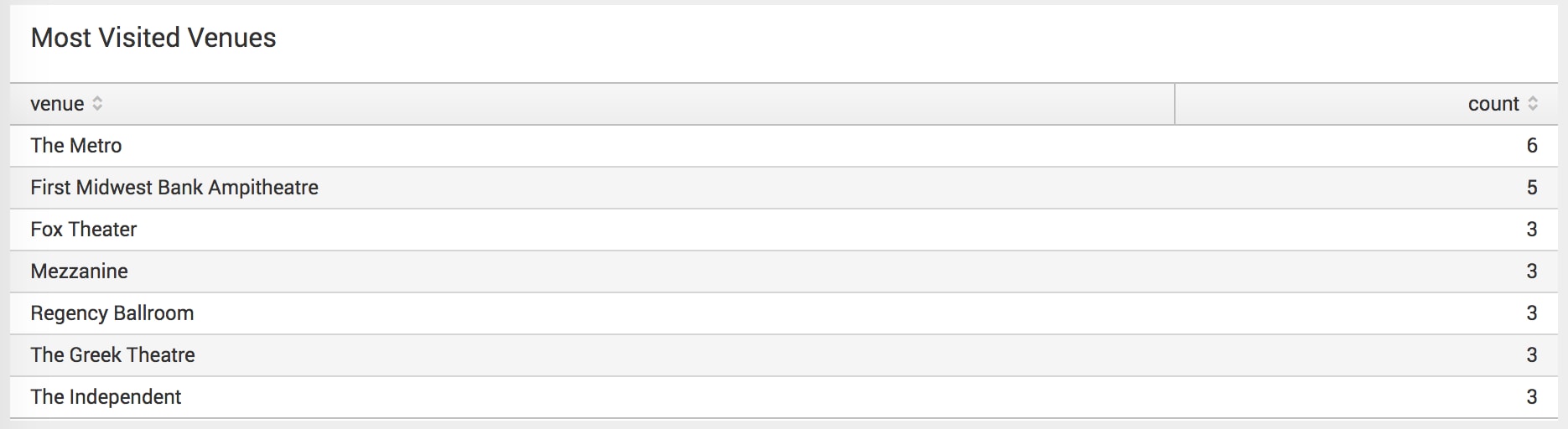
To make the list of most visited venues more interesting, I added a quick drilldown that would search the venue name in Google Maps.
<drilldown>
<set token="venue_name">$click.value$</set>
<link target="_blank">https://www.google.com/maps/search/$venue_name$</link>
</drilldown>
Lastly, I decided to play around with the Machine Learning Toolkit, because machine learning!
Using the assistants for detecting numeric outliers and detecting categorical outliers, I played around with getting interesting and understandable outliers. I ended up using the assistant to detect categorical outliers; I started with a basic search to identify track listen outliers in my data.
`lastfm` | stats count(track_name) by artist,track_name
Using the count(track_name) as the outlier field, I'm able to get interesting and understandable outliers. I open up the Data and Outliers table in search to figure out what else I can see that might explain why these are outliers.
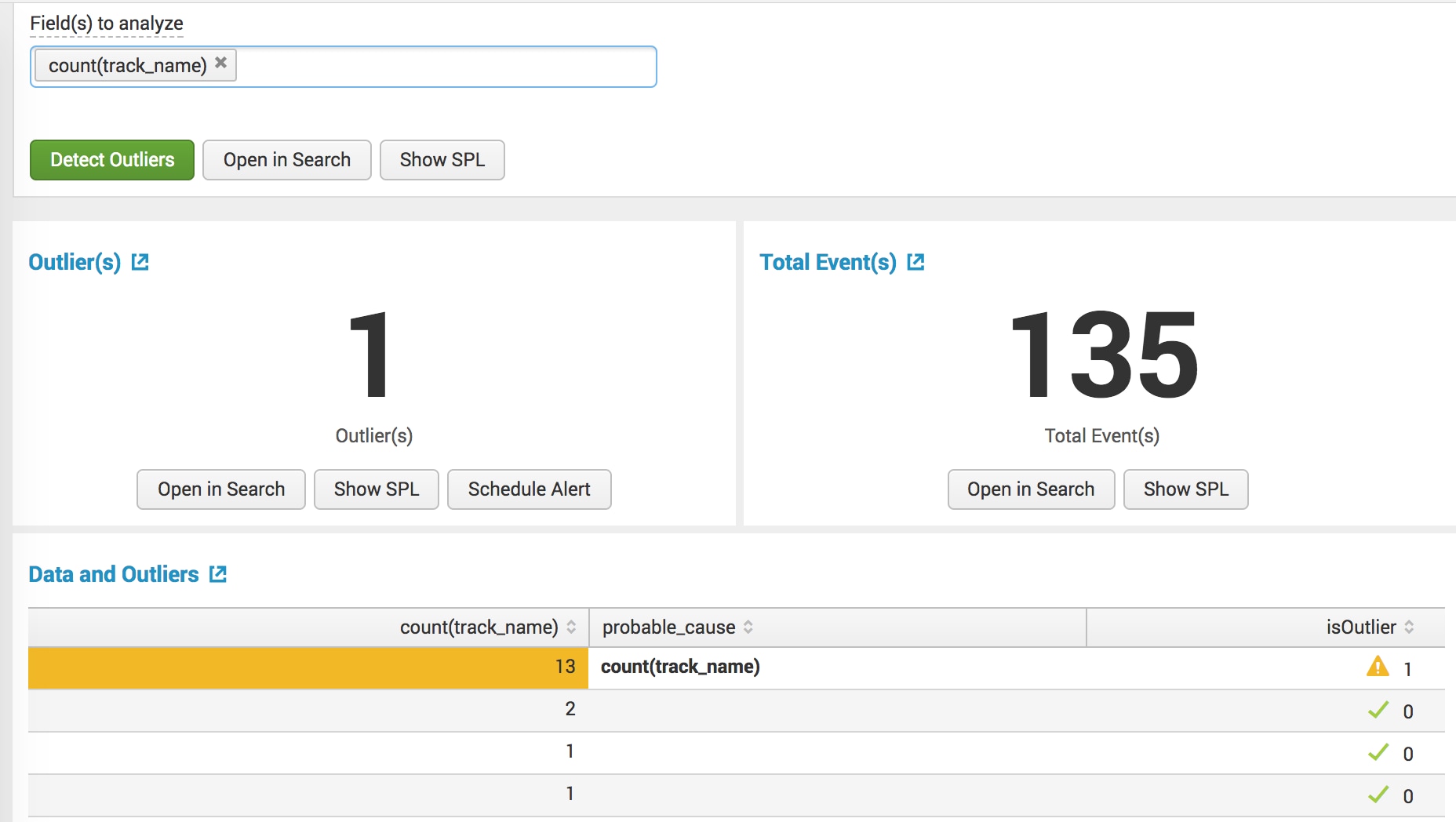
I cleaned up the table and added some extra fields to make it prettier and limit it only to outliers.
`lastfm` | stats count(track_name) by track_name, artist | anomalydetection "count(track_name)" action=annotate | eval isOutlier = if(probable_cause != "", "1", "0") | where isOutlier=1 | table artist, track_name, "count(track_name)"
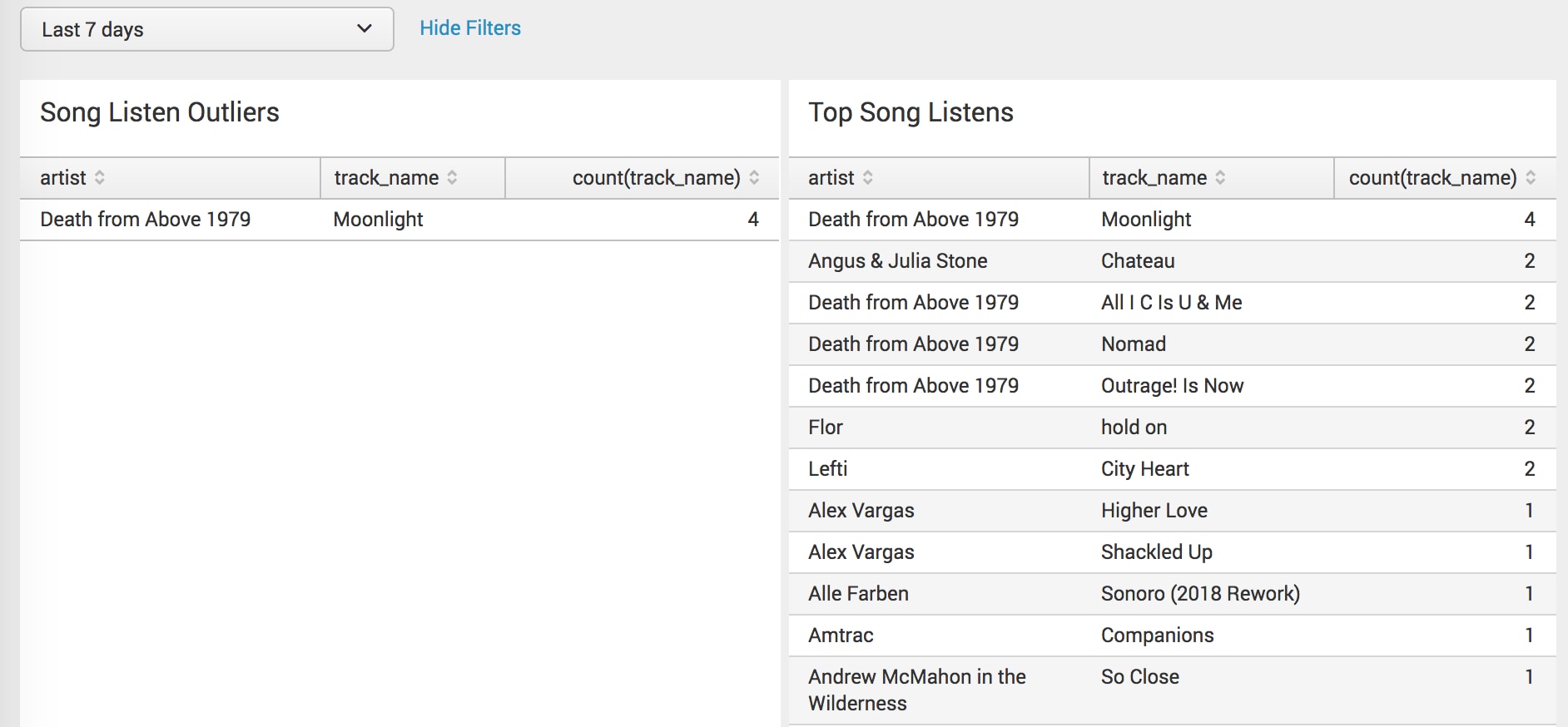
I put it on a dashboard next to a panel that shows the top song listens, then wire both of those panels up to the same time input so I can compare what the MLTK says is an outlier in terms of listens and how that compares with the top listens over the same period of time.
Finally, I want to bring this to the dashboard panel that brought this blog post to life. My brother and I recommend music to each other, but as a lifelong radio listener and perpetually-in-denial hipster, I feel the need to defend my hipster credibility against the recommendations of a brother who used to listen to Hanson. What better way to do that than with a dashboard that shows the earliest track listens by artist?
`lastfm` | search artist="VHS Collection" |stats earliest(_time) AS earliestlisten by artist track_name | fieldformat earliestlisten = strftime(earliestlisten, " %m/%d/%Y %H:%M:%S") |sort earliestlisten
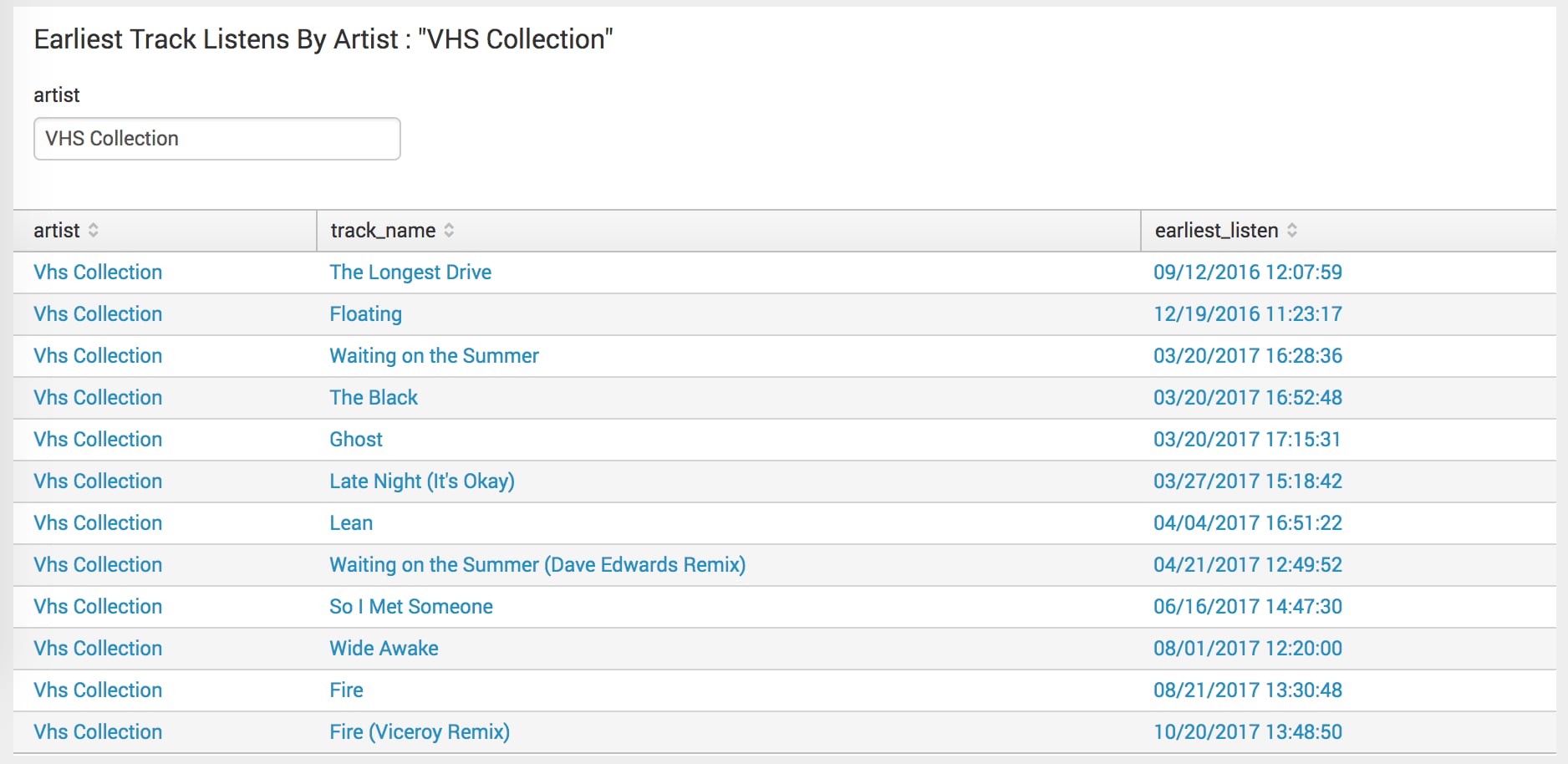
I chose to use the fieldformat command instead of convert this time around so that I could retain the format of the _time field and sort chronologically. If you use the convert command in this case, the format of the field is also converted to a string, so you can no longer sort chronologically by time after converting the field.
Because I want to be able to do these kinds of searches on the dashboard itself, I wired up an input token again. Using the dashboard editor, I added an input text box and—again using the token usage in dashboards documentation—I set up a token for the artist, then added the token to the dashboard panel title and the search.
`lastfm` | search artist=$artist$ |stats earliest(_time) AS earliestlisten by artist track_name | fieldformat earliestlisten = strftime(earliestlisten, "%m/%d/%Y %H:%M:%S") |sort earliestlisten
And with a few dashboards, I can now one-up my brother's music recommendations, judge my own lack of listens in my iTunes library, assess which states I've gone to the most concerts in, and identify outliers in my music listening habits.
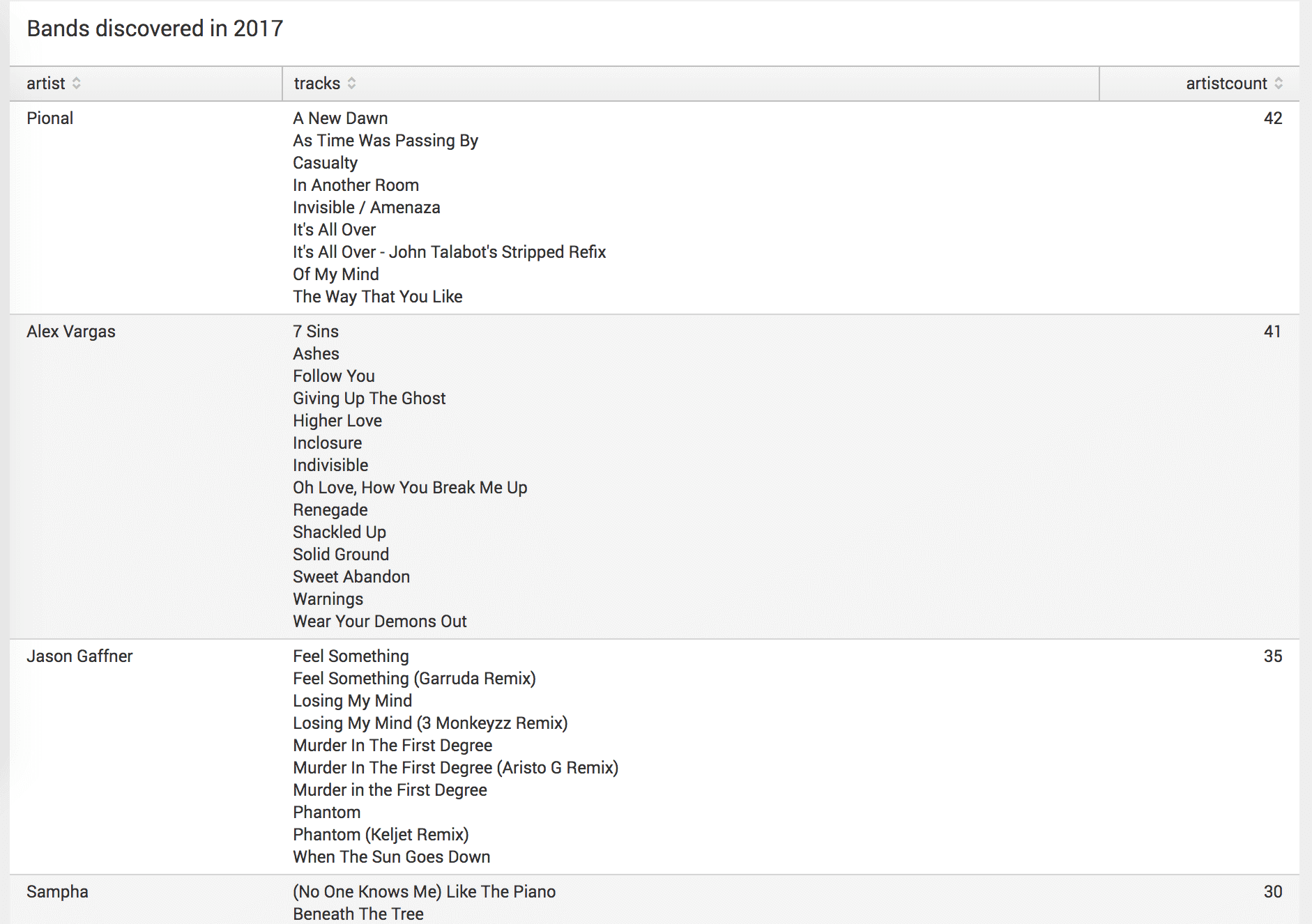
To finish off 2017, I wanted to know which bands I discovered during the year. A relatively simple search later, I sorted out which artists I discovered, listened to more than 10 times, and which tracks I listened to by those artists.
`lastfm` | stats values(artist) earliest(_time) as earliestlisten count(artist) as artistcount values(track_name) as tracks by artist | fieldformat earliestlisten = strftime(earliestlisten, "%Y") | where artistcount > 10 | where earliestlisten>1483228800 | table artist,tracks,artistcount| sort -artistcount
There is still plenty of data to analyze. If you're interested in helping me, or just want to say hi, reach out on Twitter (@smorewithface) or on the Splunk User Groups Slack channel (@smoir).
Special thanks to Robin Pille for helping me build the first LastFM add-on, Elias Haddad and Andrea Longdon for their work on the Splunk Add-on Builder, Luke Murphey for writing the Lookup File Editor, David Hazekamp, and Yann Kherian for their help writing searches, Duane Waddle (@duckfez) and Cary Petterborg (@cp-regex-guru) for their help attempting to extract library.xml data, and Michael Uschmann and Micah Kemp for helping me sort out my timestamp and field extraction issues with later iterations of my Last.fm add-on.
----------------------------------------------------
Thanks!
Sarah Moir

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
