
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

We’re officially in the home stretch of the "A Blueprint for Splunk ITSI Alerting" blog series; if you’ve made it this far, I’m going to assume you’re willing to finish out this last step. In this blog post, we’re going to focus on throttling our alerts. From the previous step, we’re now producing actionable alerts, but without throttling, we’re producing them way too often. Ideally we want to alert once per episode or maybe once an hour or day, but certainly not once per notable.
I’m going to come right out and say that I wish the throttling was a little more simple and straightforward to achieve in NEAPs, but it is what it is. So the steps in this blog might feel a little kludgy, and you might have to work a little to understand what’s going on here.
Let me start by using words to describe what we're going to do, and then we’ll actually do it.
We’re going to create one final correlation search in the environment that regularly looks at each episode group and creates a special “Alert Trigger” notable event for any group that has at least one notable whose field alertable = 1. This correlation search will be smart enough to produce just one of these special “Alert Trigger” notables, thus providing throttling. Lastly, we’ll update our NEAP action logic to trigger based on the presence of this special alert trigger notable and voila, we’re done!
This one is a bit ugly, so bear with me…
((index=itsi_grouped_alerts) OR (index=itsi_tracked_alerts alertable=1))
| eventstats values(itsi_group_id) as itsi_group_id by event_id
| search index=itsi_tracked_alerts
| mvexpand itsi_group_id
| lookup itsi_notable_event_group_lookup _key AS itsi_group_id OUTPUT severity AS lookup_severity, status AS lookup_status, owner AS lookup_owner
| eval severity=coalesce(lookup_severity, severity), status=coalesce(lookup_status, status), owner=coalesce(lookup_owner, owner)
| search status < 5
| eventstats count(eval(alertable=1)) as alertable_count count(eval(alert_trigger=1)) as alert_trigger_count by itsi_group_id
| where alertable_count>0 AND alert_trigger_count<1
| dedup itsi_group_id
| eval alert_trigger=1
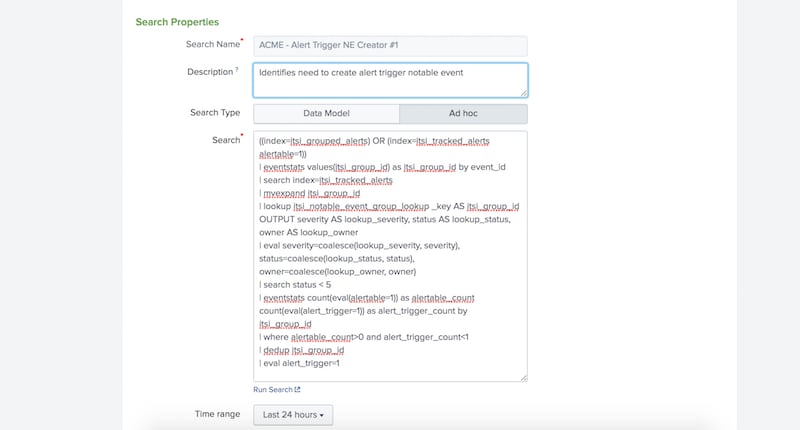
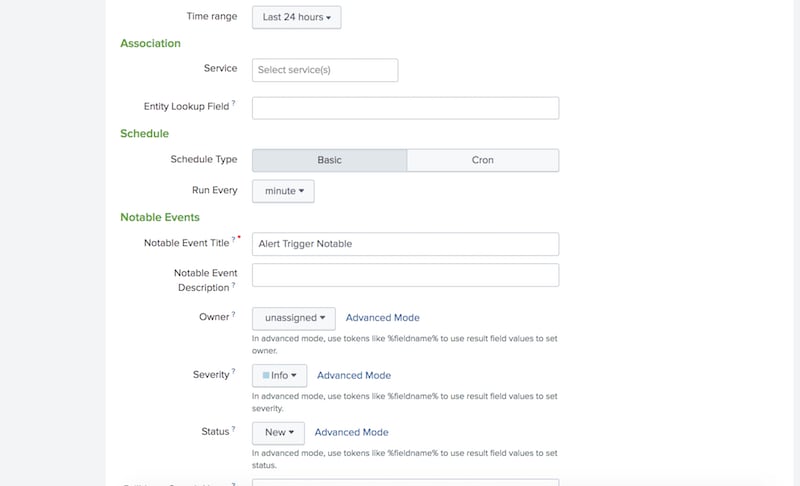
You’ll notice in the images above that this search is configured to run over the last 24h of notable events. This timeframe is critically important because it dictates the throttling duration. If the episode has been open for more than 24h, then the alert_trigger notable event will no longer return in the search and a new one will be created; thus a new alert action will fire. If you want to shorten or lengthen the throttle window, simply run this search over shorter or longer durations to match your desired throttle time.
The correlation search above is wholely responsible for when and how we suppress. As a result, we can continue to evolve the rule logic to make our suppression even smarter. For instance, if my episode has been "open" for more than 24 hours, but the most recent alertable notable is fairly old (let's say 10 hours), we may not want to trigger a new alert. We can embed that type of logic also into the correlation search such that we'll only alert if our most recent notable is fairly new—let's say less than 60 minutes old. Here's how we would update our alert trigger correlation rule to include these:
((index=itsi_grouped_alerts) OR (index=itsi_tracked_alerts alertable=1))
| eventstats values(itsi_group_id) as itsi_group_id by event_id
| search index=itsi_tracked_alerts
| mvexpand itsi_group_id
| lookup itsi_notable_event_group_lookup _key AS itsi_group_id OUTPUT severity AS lookup_severity, status AS lookup_status, owner AS lookup_owner
| eval severity=coalesce(lookup_severity, severity), status=coalesce(lookup_status, status), owner=coalesce(lookup_owner, owner)
| search status < 5
| eventstats count(eval(alertable=1)) as alertable_count count(eval(alert_trigger=1)) as alert_trigger_count max(_time) as latest_alertable_time by itsi_group_id
| eval seconds_since_last_alertable_notable = now() - latest_alertable_time
| where alertable_count>0 AND alert_trigger_count<1 AND seconds_since_last_alertable_notable < 3600
| dedup itsi_group_id
| eval alert_trigger=1
Well, that’s it! No more steps, so you should be rockin’ and rolling now. I hope you see the same benefits in this design as I do. It’s fairly easy to maintain, it’s quite performant, and the alerting design is universal across all services. All goodness to me. Understand that this is a starting point—a design blueprint—and you should alter and augment as this situation dictates for your environment. Again, if you want to connect with me to discuss more, please contact me via the LinkedIn link in my author bio below.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
