
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

In this step, we’ll focus on taking action on the notable events that have been created thus far. In "A Blueprint for Splunk ITSI Alerting - Overview," I confessed that I believe this design could continue to change over time, and I feel like the concepts addressed in this blog and the next are the most subject to change. I guess what I’m saying is, if you believe you have a better way to achieve the alerting design, I’d love to talk to you about it. Hit me up on LinkedIn and we can connect; otherwise, start with what I lay out here and evolve over time.
In Step 3, we created several correlation searches looking for badness in the environment, and now we need to decide which badness is worthy of producing actionable alerts. When a particular notable event is “so offensive” that we want to proactively alert someone, we’ll flag it with a new field called alertable whose value is 1. Those notables which are not alert-worthy will also get an alertable field whose value is 0. We’ll then build into our NEAP action rules based on the presence of a notable whose field alertable=1.
As an example, we’ll revisit our very first correlation search from the "Step 1" blog post and append some additional alertable field logic. Remember, we’re producing notable events when the service health score is anything other than low, but we’ll only fire an alert when it goes critical. Go back to your first correlation search build which produces notable events for degraded services and update the SPL to the following.
`service_health_data` alert_level>2
| `acme_itsi_summary_to_itsi_tracked_alerts_field_mapping`
| eval alertable = if (alert_level>5,1,0)
Get your test service health to transition from normal to high to critical. If all is working as expected, you’ll see notable events when the service health goes high, and their alertable field should exist and be 0. Once the service goes critical, the subsequent notable events should have alertable=1.
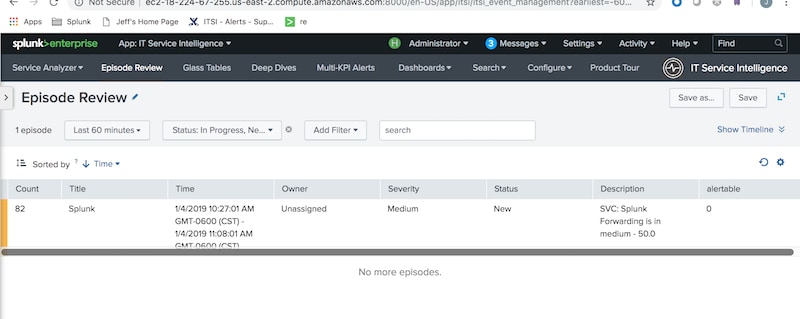
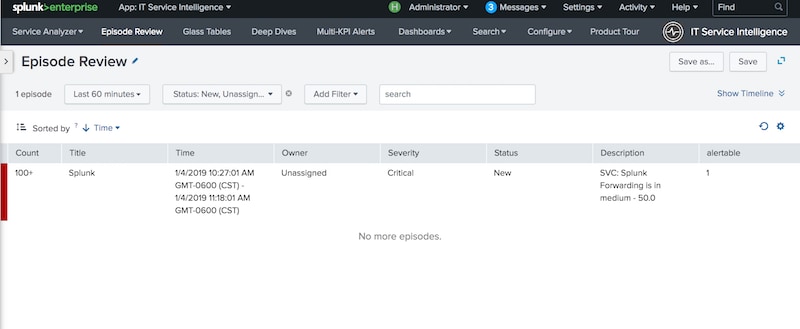
We can now visit the action section of the notable event aggregation policy built in the "Step 2" blog and configure it to take action when alertable=1.
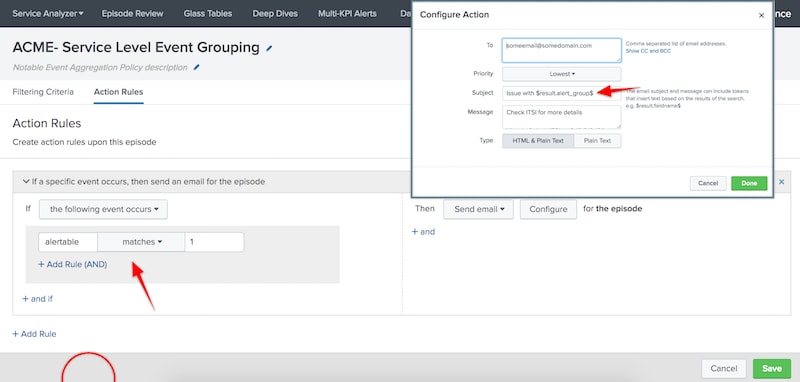
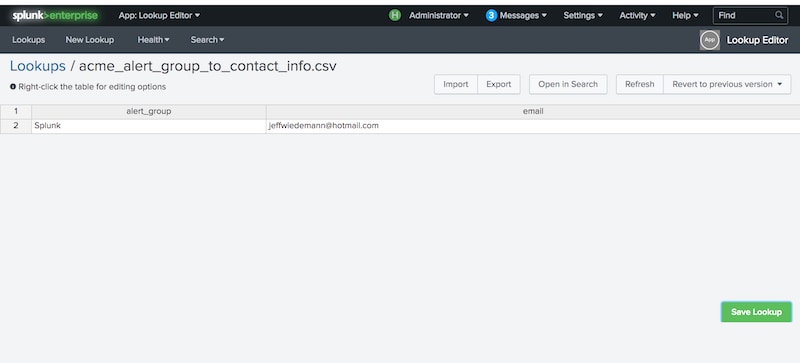
You’ll notice the use of tokens in the action email; this is a critical design feature to understand. We only need to create a single NEAP across the entire environment, so we must leverage tokenization in our action scripts to ensure that the right team or person is paged out for each notable group. Again, there are lots of ways to achieve this, but I’d recommend a second lookup which provides email address or contact information for each alert_group.
Note that we have two automatic lookups running. The first creates the alert_group field and the second provides the correct email address for this alert_group. This means that our automatic lookup definitions must be named in correct lexicographical order to work as intended.
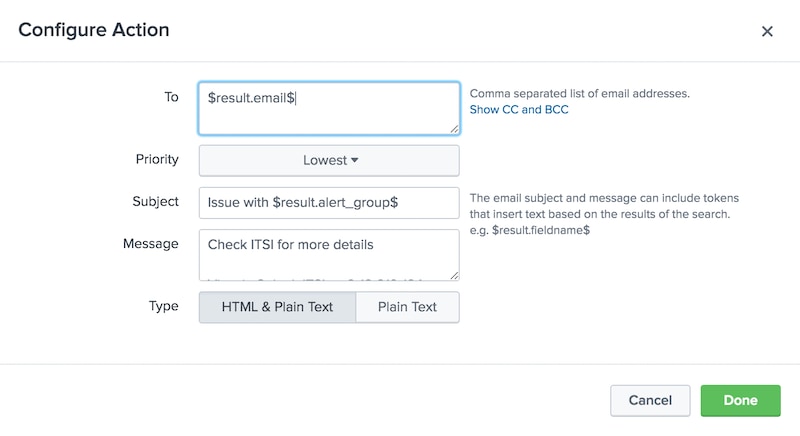
You should now be getting emails (or some other desired action) for notable events with alertable=1. Your job is to go back and revisit your correlation searches and determine which situations are alert-worthy and configure your alertable logic accordingly. Remember, in our example above our alertable logic was dead simple, but it doesn’t have to be. The alertable logic in the SPL can grow as complex as necessary to meet your needs. Maybe some services should alert when they go high and others when they go critical, or perhaps you want to alert when some KPIs go critical but not others—all of this is possible by extending and augmenting the logic which sets alertable to 1 or 0 based on your needs.
Lastly, you may notice that you’re getting a whole lot of emails…that’s not good! We haven’t implemented action throttling yet so every new notable event with alertable=1 is going to take action. This throttling will ensure that actions are taken just once per episode and is the subject of our next and final blog.
I'm lovin' it! Get ready for Step 5...

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
